

Redis系列之模糊匹配查询
概述
业务开发与监控中,遇到需要统计、监控符合某个规则(即正则表达式)模式的键的个数和大小,因此学习调研一番。
一般有两种实现方式,keys、scan。两种命令的通配符都是一样的,即keys pattern支持3个通配符*,?,[]:
*:通配任意多个字符?:通配单个字符[]:通配括号内的某一个字符
keys
官方文档:keys
两个缺点:
- 没有 offset、limit 参数,一次性吐出所有满足条件的key;
- keys采用遍历算法,复杂度
O(n),容易导致Redis服务卡顿,所有读写 Redis 的其它指令都会被延后甚至会超时报错。Redis 是单线程程序,顺序执行所有指令,其它指令必须等到当前的 keys 指令执行完才可以继续。
故而DBA(广义上的)在生产环境会屏蔽keys命令,通过rename-command命令:rename-command keys ""。
命令行
下面在RDM里验证三个通配符规则:
1608(10.114.31.113:6408)>keys entity_finalaudit_amount_test_var_add_0324*
1) "entity_finalaudit_amount_test_var_add_0324_700076906"
1608(10.114.31.113:6408)>keys entity?
1608(10.114.31.113:6408)>keys entity[1]
1608(10.114.31.113:6408)>
Jedis
public Set getByKeys(String pattern) {
Jedis jedis = new Jedis("10.114.31.113", 6408);
Set<String> retSet = new HashSet<>();
try {
retSet = jedis.keys(pattern);
} catch (Exception e) {
} finally {
jedis.close();
}
return retSet;
}
restTemplate
scan
官方文档:scan
Redis 2.8版本引入,目标是解决keys命令的一些问题,特点:
- 复杂度
O(n),通过游标分步进行的,不会阻塞线程; - 提供 limit 参数,可以设置每次返回结果的数据量,limit只是对增量式迭代命令的hint,返回的结果可多可少;
- 支持模式匹配功能;
- 服务器不需要为游标保存状态,游标的唯一状态就是 scan 返回给客户端的游标整数;
- 返回的结果可能会有重复,需要客户端去重复;
- 无法提供完整的快照遍历,即遍历过程中若有数据修改,改动后的数据可能遍历不到;每次返回的数据条数不一定,极度依赖内部实现;
- 单次返回的结果是空的并不意味着遍历结束,而要看返回的游标值是否为零
命令:SCAN cursor [MATCH pattern] [COUNT count] [TYPE type]
scan提供4个参数,第一个是 cursor 整数值,第二个是 key 的正则模式,第三个是遍历的 limit hint。第一次遍历时,cursor 值为 0,然后将返回结果中第一个整数值作为下一次遍历的 cursor。一直遍历到返回的 cursor 值为 0 时结束。
注意:type选项是Redis 6版本引入支持的;
即scan采用增量迭代方式查询,使用pipeline减少交互,可提高效率。
拓展
scan 指令是一系列指令:
- zscan 遍历 zset 集合元素,包括元素成员和元素分值
- hscan 遍历 hash 字典的元素
- sscan 遍历 set 集合的元素
除了可以遍历所有的 key 之外,还可以对指定的容器集合进行遍历。SCAN 命令则不需要在第一个参数提供任何数据库键,它迭代的是当前数据库中的所有数据库键。后三个命令的第一个参数总是一个数据库键。
客户端
命令行
RDM演示scan命令的执行,省略部分返回数据,可见设置的count未起作用:
1608(10.114.31.113:6408)>scan 0 match entity_finalaudit_amount_test_var_add_0324* count 20
1) "1568"
2) 1) "entity_finalaudit_amount_test_var_add_0324_700077396"
6) "entity_finalaudit_amount_test_var_add_0324_700074704"
1608(10.114.31.113:6408)>scan 1568 match entity_finalaudit_amount_test_var_add_0324* count 20
1) "864"
2) 1) "entity_finalaudit_amount_test_var_add_0324_700076914"
4) "entity_finalaudit_amount_test_var_add_0324_700078115"
Jedis
public static Set getByScan(String pattern) {
Jedis jedis = new Jedis();
// 去重
Set<String> retSet = new HashSet<>();
String scanRet = "0";
try {
do {
ScanParams scanParams = new ScanParams();
scanParams.match(pattern + "*");
// 可有可无的设置
scanParams.count(20);
ScanResult<String> scanResult = jedis.scan(scanRet, scanParams);
scanRet = scanResult.getCursor();
retSet.addAll(scanResult.getResult());
// 游标值为0表示遍历结束
} while (!"0".equals(scanRet));
} catch (Exception e) {
} finally {
jedis.close();
}
return retSet;
}
restTemplate
原理
字典结构
Redis中所有的 key 都存储在一个很大的字典中,其结构和Java 中的 HashMap 一样,是一维数组 + 二维链表结构,第一维数组的大小总是 2^n(n>=0),扩容一次数组大小空间加倍,也就是 n++。
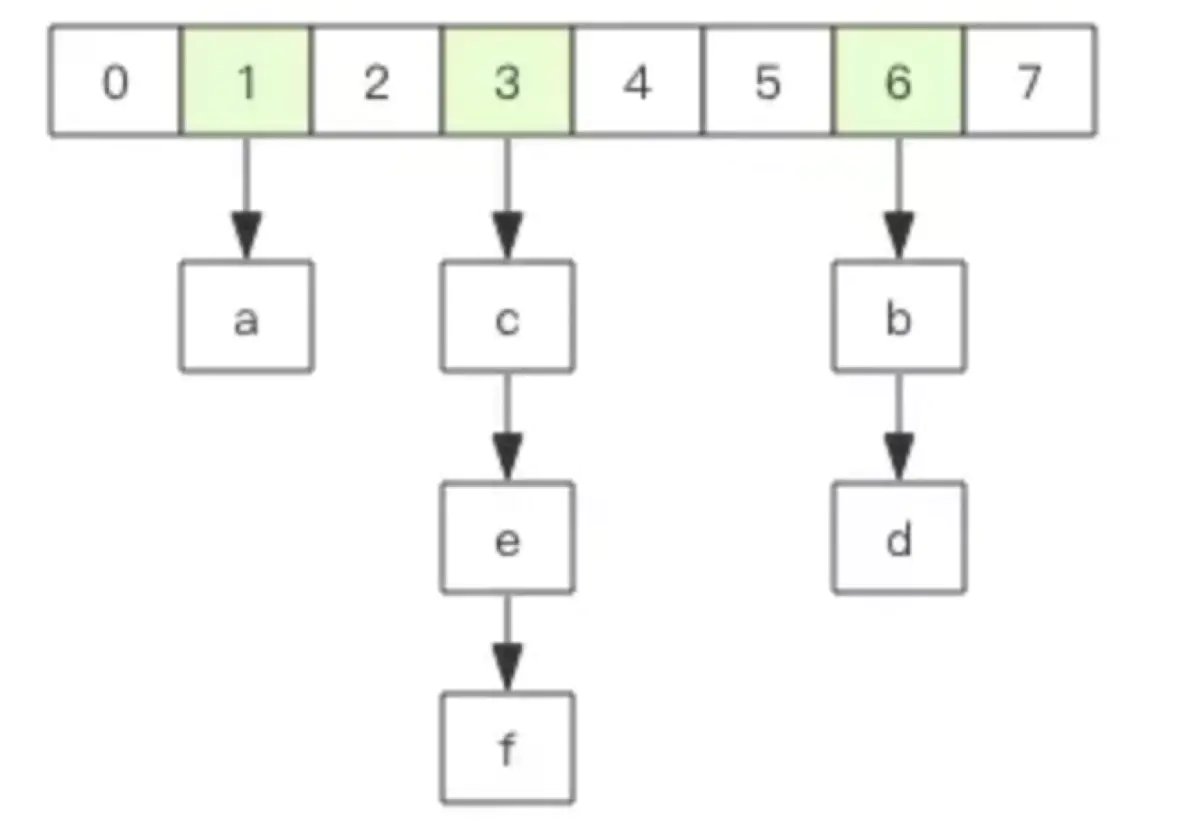
scan 指令返回的游标就是第一维数组的位置索引,将这个位置索引称为槽 (slot)。如果不考虑字典的扩容缩容,直接按数组下标挨个遍历即可。limit 参数就表示需要遍历的槽位数,之所以返回的结果可能多可能少,是因为不是所有的槽位上都会挂接链表,有些槽位可能是空的,还有些槽位上挂接的链表上的元素可能会有多个。每一次遍历都会将 limit 数量的槽位上挂接的所有链表元素进行模式匹配过滤后,一次性返回给客户端。
scan遍历顺序
它不是从第一维数组的第 0 位一直遍历到末尾,而是采用高位进位加法来遍历。之所以使用这样特殊的方式进行遍历,是考虑到字典的扩容和缩容时避免槽位的遍历重复和遗漏。
高位进位法从左边加,进位往右边移动,同普通加法正好相反。但是最终它们都会遍历所有的槽位并且没有重复。
字典扩容
Java 中的 HashMap 有扩容的概念,当 loadFactor 达到阈值时,需要重新分配一个新的 2 倍大小的数组,然后将所有的元素全部 rehash 挂到新的数组下面。rehash 就是将元素的 hash 值对数组长度进行取模运算,因为长度变了,所以每个元素挂接的槽位可能也发生了变化。又因为数组的长度是 2^n 次方,所以取模运算等价于位与操作。
a mod 8 = a & (8-1) = a & 7
a mod 16 = a & (16-1) = a & 15
a mod 32 = a & (32-1) = a & 31
7, 15, 31 称之为字典的 mask 值,作用就是保留 hash 值的低位,高位都被设置为 0。
rehash 前后元素槽位的变化。
假设当前的字典的数组长度由 8 位扩容到 16 位,那么 3 号槽位 011 将会被 rehash 到 3 号槽位和 11 号槽位,也就是说该槽位链表中大约有一半的元素还是 3 号槽位,其它的元素会放到 11 号槽位,11 这个数字的二进制是 1011,就是对 3 的二进制 011 增加了一个高位 1。
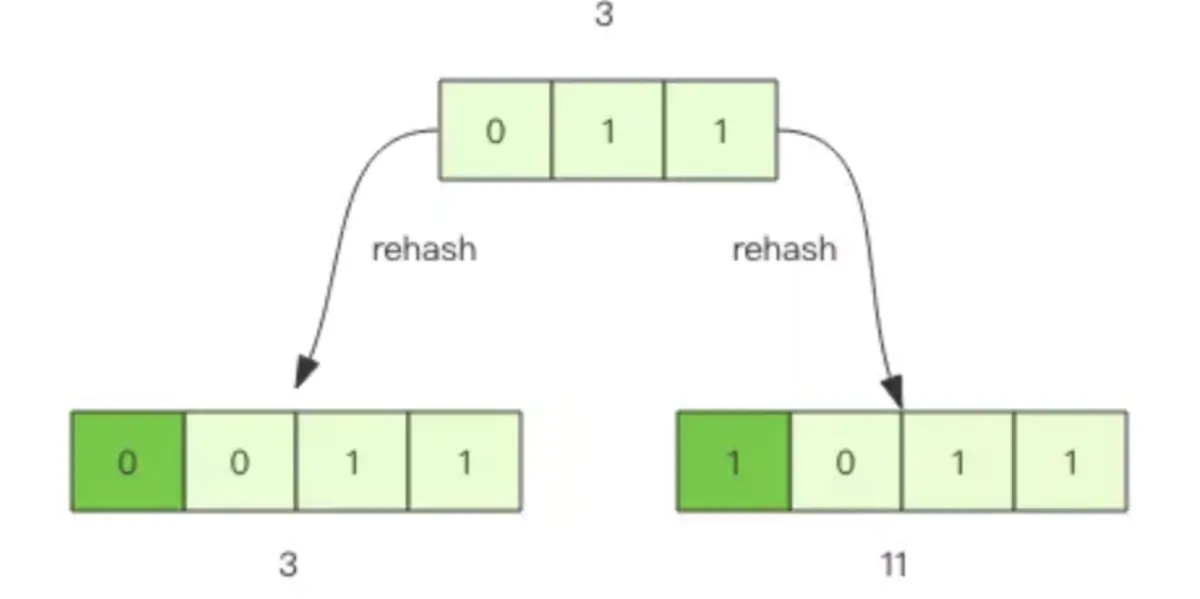
抽象一点说,假设开始槽位的二进制数是 xxx,那么该槽位中的元素将被 rehash 到 0xxx 和 1xxx(xxx+8) 中。 如果字典长度由 16 位扩容到 32 位,那么对于二进制槽位 xxxx 中的元素将被 rehash 到 0xxxx 和 1xxxx(xxxx+16) 中。
对比扩容缩容前后的遍历顺序
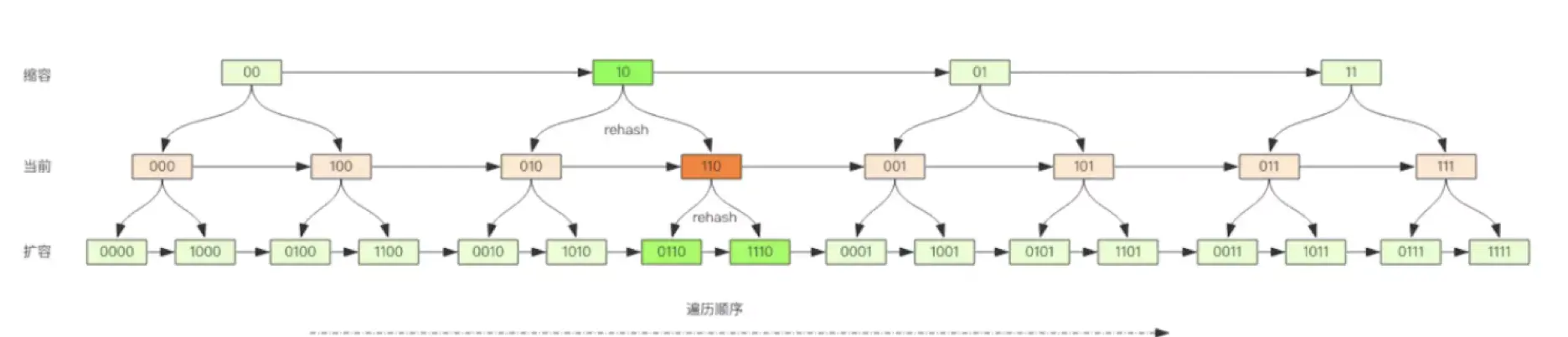
观察这张图,我们发现采用高位进位加法的遍历顺序,rehash 后的槽位在遍历顺序上是相邻的。
假设当前要即将遍历 110 这个位置 (橙色),那么扩容后,当前槽位上所有的元素对应的新槽位是 0110 和 1110(深绿色),也就是在槽位的二进制数增加一个高位 0 或 1。这时我们可以直接从 0110 这个槽位开始往后继续遍历,0110 槽位之前的所有槽位都是已经遍历过的,这样就可以避免扩容后对已经遍历过的槽位进行重复遍历。
再考虑缩容,假设当前即将遍历 110 这个位置 (橙色),那么缩容后,当前槽位所有的元素对应的新槽位是 10(深绿色),也就是去掉槽位二进制最高位。这时我们可以直接从 10 这个槽位继续往后遍历,10 槽位之前的所有槽位都是已经遍历过的,这样就可以避免缩容的重复遍历。不过缩容还是不太一样,它会对图中 010 这个槽位上的元素进行重复遍历,因为缩融后 10 槽位的元素是 010 和 110 上挂接的元素的融合。
渐进式 rehash
Java 的 HashMap 在扩容时会一次性将旧数组下挂接的元素全部转移到新数组下面。如果 HashMap 中元素特别多,线程就会出现卡顿现象。Redis 为了解决这个问题,它采用渐进式 rehash。
它会同时保留旧数组和新数组,然后在定时任务中以及后续对 hash 的指令操作中渐渐地将旧数组中挂接的元素迁移到新数组上。这意味着要操作处于 rehash 中的字典,需要同时访问新旧两个数组结构。如果在旧数组下面找不到元素,还需要去新数组下面去寻找。
scan 也需要考虑这个问题,对与 rehash 中的字典,它需要同时扫描新旧槽位,然后将结果融合后返回给客户端。
问题
aaa*匹配还是*aaa的匹配效率更高?设计key时,选择效率更高的??
参考
https://zhuanlan.zhihu.com/p/50935911
《Redis 深度历险:核心原理与应用实践》大海捞针-Scan


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix