

《大型网站系统与java中间件实践》读书笔记
As always,福利置顶,pdf下载链接:http://pan.baidu.com/s/1boE2xBp 密码:iu6o
书籍还算不错,把分布式系统各种可能的问题都细致地分析一遍,并给出几种解决方法和最佳的方案,这一点值得肯定。分布式系统最怕的问题就是一致性问题,很多章节都是围绕这个问题去阐述的,给出各种环节/节点可能出现不一致的原因,并给出解决方法。
第1章 分布式系统介绍
初识分布式系统
- 分布式系统的定义:A distributed system is one in which Components located at networked computers communicate and coordinate their actions only by passing messages.
- 分布式系统的意义
分布式系统出现的原因:升级单机处理能力的性价比越来越低;单机处理能力存在瓶颈;处于稳定性和可用性的考虑。
分布式系统的基础知识
- 组成计算机的要素:输入,输出,运算器,控制器和存储器;
- 线程与进程的执行模式:阿姆达尔定律;互不通信的多线程模式,基于共享容器协同的多线程模式,通过事件协同的多线程模式,多进程模式;
- 网络通信基础知识:OSI七层模型,TCP/IP模型;网络IO实现方式:BIO阻塞;NIO,基于事件驱动思想,Reactor模式;AIO异步IO,Proactor模式
- 如何把应用从单机扩展到分布式:5要素的变化
- 分布式系统的难点:缺乏全局时钟;面对故障独立性;处理单点故障,如果不能把单点变为集群,则需要给单点做好备份,降低单点故障影响范围;事务的挑战:2PC、最终一致、BASE、CAP、Paxos等。
Socket 网络通信开发时用到的三种方式:BIO、NIO和AIO
BIO:Blocking IO,采用阻塞的方式实现,一个线程处理一个Socket,发生建立连接、读数据、写数据的操作时,都可能会阻塞。
NIO:Nonblocking IO,基于时间驱动思想,采用Reactor模式,可以在一个线程中处理多个Socket套接字
AIO:AsynchronousIO,异步IO,采用Proactor模式,与NIO的差别是,AIO在进行读写操作时,只需要调用响应的read/write方法,并且需要传入CompletionHandler,在动作完成后会调用。
第2章 大型网站及其架构演进过程
什么是大型网站:
海量数据、高并发访问量、本身业务的系统的复杂度;
大型网站的架构演进
- 用Java技术和单机来构建的网站
- 从一个单机的交易网站说起
- 单机负载告警,数据库与应用分离
- 应用服务器负载告警,如何让应用服务器走向集群
- 数据读压力变大,读写分离吧
- 弥补关系型数据库的不足,引入分布式存储系统(分布式文件系统、分布式KV系统和分布式数据库)
- 读写分离后,数据库又遇到瓶颈:垂直拆分和水平拆分;读写分离解决读压力大的问题,水平拆分解决数据量大或者更新量大的问题;垂直拆分带来的问题:原来单机中跨业务的事务,解决方法:1. 使用分布式事务,性能下降;2. 去掉事务或者不追求强事务支持;水平拆分带来的问题:SQL路由、主键处理、多个数据库源取数据,分页排序处理;
- 数据库问题解决后,应用面对的新挑战
- 初识消息中间件
增加应用服务器后需要解决的问题:
终端用户对多个应用服务器访问的选择问题;解决方法:DNS、负载均衡
Session问题;解决方法:Session sticky,Session replication,Session数据集中存储(引入网络操作),cookie based(问题:cookie长度限制、安全性、带宽消耗、性能影响,不推荐);
读写分离带来的问题:数据复制、应用对数据源的选择问题;
搜索引擎实际上是一个读库,构建搜索用的索引就是一个数据复制的过程。搜索系统构建索引的两个维度:全量/增量;实时/非实时;实时构建索引对数据源服务器有性能影响;
缓存:数据缓存和页面缓存;Apache ESI模块;
第3章 构建Java中间件
Java中间件的定义
构建Java中间件的基础知识
- 跨平台的Java运行环境——JVM
- 垃圾回收与内存堆布局
- Java并发编程的类、接口和方法
- 动态代理
- 反射
- 网络通信实现选择
Java并发编程的类、接口和方法
线程池、synchronized、ReentrantLock(公平锁和非公平锁,公平锁的好处是等待锁的线程不会饿死)、volatile、Atomics、wait/notify/notifyAll(对这个三个方法的调用都必须是在对象的synchronized块中)、CountDownLatch、CyclicBarrier、Semaphore、Exchanger、Future/FutureTask、并发容器(copyOnWrite & Concurrent);
分布式系统中的Java中间件
第4章 服务框架
目录结构:
1、网站功能持续丰富后的困境与应对
2、服务框架的设计与实现
- 应用从集中式走向分布式所遇到的问题
- 透过示例看服务框架原型
- 服务调用端的设计与实现
- 服务提供端的设计与实现
- 服务升级
3、实战中的优化
4、为服务化护航的服务治理
5、服务框架与ESB的对比
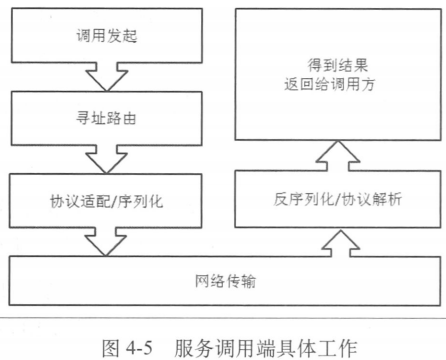
服务调用端的设计与实现
流程:调用发起=>寻址路由=>协议适配和序列化=>网络传输=>反序列化以及协议解析=>得到结果返回给调用方
1、确定服务框架的使用方式
2、服务调用者与服务提供者之间通信方式的选择
3、引入基于接口、方法、参数的路由
4、多机房场景,避免跨机房调用,一是在服务注册中心甄别,二是地址过滤
5、服务调用端的流控处理
6、序列化与反序列化处理,Java本身的序列化性能问题、跨语言问题、序列化后语言长度等
7、网络通信实现选择:BIO、NIO、AIO
8、支持多种异步服务调用方式:Oneway,Callback,Future,可靠异步
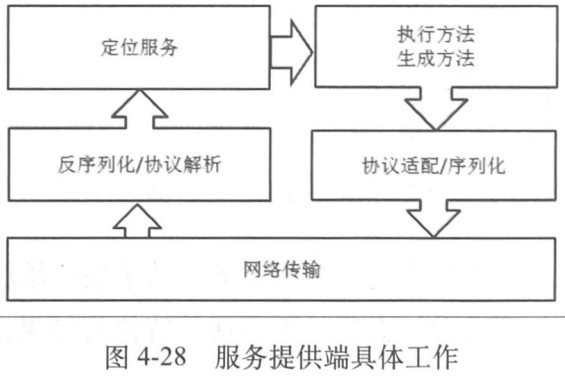
服务提供端的设计与实现
1、如何暴露远程服务
2、服务端对请求处理的流程
3、执行不同服务的线程池隔离
4、服务提供端的流控处理
第5章 数据访问层
数据库从单机到分布式的挑战和应对
- 从应用使用单机数据库开始
- 数据库垂直/水平拆分的困难
- 单机变为多机后,事务如何处理
- 多机的Sequence问题与处理
- 应对多机的数据查询
数据访问层的设计与实现
- 如何对外提供数据访问层的功能
- 按照数据层流程的顺序看数据层设计
- 独立部署的数据访问层实现方式
- 读写分离的挑战和应对
水平拆分和垂直拆分
垂直拆分把一个数据库中不同业务单元的数据分到不同的数据库里,水平拆分是根据一定的规则把同一个业务单元的数据拆分到多个数据库中;
垂直拆分带来的影响:
- 单机的 ACID 被打破;
- Join操作受影响;
- 靠外键进行约束的场景有影响;
水平拆分带来的影响:
- ACID 被打破;
- Join操作受影响;
- 靠外键进行约束的场景有影响;
- 依赖单库的自增序列生成唯一 ID 会受影响;
- 针对单个逻辑意义上的表的查询需要跨库;
分布式事务
- 两阶段提交:2PC
- 一致性理论:CAP、BASE
- Paxos协议
多机自增主键问题
考虑唯一性和连续性,UUID生成方式(IP、MAC、时间等)连续性不好;
实现方案1:把ID集中放在一个地方进行管理,对每个Id序列独立管理,每台机器使用Id时都从这个Id生成器上取。
缺点:
性能问题:每次都去远程取Id会有资源损耗
生成器的稳定性问题,作为一个无状态的集群,保证可用性
存储的问题
实现方案2:舍掉Id生成器,把相关的逻辑放到需要生成Id的应用本身。每个生成器读取可用的Id,然后给应用使用,但是数据的Id并不是严格按照进入数据库顺序而增大的。
应对多机的数据查询
跨库Join
- 在应用层把原来数据库的Join操作分成多次的数据库操作
- 数据冗余,对常用信息进行冗余
- 借助外部系统,如搜索引擎
外键约束:比较难解决,不能完全依赖数据库本身来完成之前的功能了。
跨库查询:一张逻辑表,对应多个数据库的多张数据表,在一些场景下比较复杂,如排序、最大最小求和等函数处理、求平均值、非排序分页、排序后分页。
如何对外提供数据访问层的功能
1、为用户提供专有API
2、通用的方式,数据层JDBC
3、基于ORM或类ORM接口的方式
直接基于JDBC驱动方式较好~
数据层的整体流程
SQL解析=>规则处理=>SQL改写=>数据源选择=>SQL执行=>结果集返回合并处理
1、SQL解析阶段
- SQL解析并不完备
- SQL中不带有分库条件,但实际上是可以明确指定分库的
2、规则处理阶段
- 采用固定哈希算法作为规则,如根据用户id取模,id mod 2分库,再id mod 4分表。实现简单,但是如果扩容的话比较复杂!
- 一致性哈希,节点对应的哈希值为一个范围,分配给现有节点。如果有节点加入,会从原有节点分管一部分范围的哈希值;如果有节点退出,会把哈希值交给下一个节点管理
- 虚拟节点对一致性哈希的改进,引入虚拟节点,如4个物理节点可以变为多个虚拟节点,每个虚拟节点支持连续的哈希环上的一段。
- 映射表与规则自定义计算方式,映射表是根据分库分表字段的值的查表法来确定数据源的方法,一般用于对热点数据的特殊处理。
3、改写SQL
分库分表后,查询就要跨库。分布的不同数据库中的表的结构虽然一样,但是表的名字、索引名字未必一样,所以要修改SQL。
还有需要修改SQL的地方,如跨库计算平均值,必须修改SQL获取数量、总数后再进行计算。
4、如何选择数据源,读写分析
5、执行SQL和结果处理阶段,异常处理和判断
第6章 消息中间件
消息中间件的价值
- 消息中间件的定义
- 透过示例看消息中间件对应用的解耦
通过服务调用让其他系统感知事件发生的方式
通过引入消息中间件解耦服务调用
互联网时代的消息中间件
- 如何解决消息发送一致性
- 如何解决消息中间件与使用者的强依赖问题
- 消息模型对消息接收的影响
- 消息订阅者订阅消息的方式
- 保证消息可靠性的做法
- 订阅者视角的消息重复的产生和应对
- 消息投递的其他属性支持
- 保证顺序的消息队列的设计
- Push和Pull方式的对比
消息中间件的核心特点功能:应用之间的解耦以及操作的异步,其实是:消息的顺序保证、扩展性、可靠性、业务操作与消息发送一致性,以 及多集群订阅者等;
如何解决消息发送一致性
消息发送一致性是指产生消息的业务动作与消息发送一致,即如果业务操作成功了,那么由这个操作产生的消息一定要发送出去。
1、发送消息给消息中间件
2、消息中间件入库消息
3、消息中间件返回结果
4、业务操作
5、发送业务操作结果给消息中间件
6、更改存储中消息状态
第7章 软负载中心与集中配置管理
初识软负载中心
两个最基础的职责:聚合地址信息;生命周期感知;
软负载中心的结构
两部分:服务端和客户端;
内部三类重要数据:聚合数据,订阅关系,连接信息;
内容聚合功能的设计
主要工作:保证数据正确性,高效聚合数据;
注意问题:并发下的数据正确性保证;数据更新、删除的顺序保证;大量数据同时插入/更新时的性能保证;
解决服务上下线的感知
软负载中心的数据分发的特点和设计
- 数据分发与消息订阅的区别
- 提升数据分发性能需要注意的问题
针对服务化的特性支持
- 软负载数据分组
- 提供自动感知以外的上下线开关
- 维护管理路由规则
从单机到集群
- 数据统一管理方案
- 数据对等管理方案
集中配置管理中心
- 客户端实现和容灾策略
- 服务端实现和容灾策略
- 数据库策略
第8章 构建大型网站的其他要素
- 加速静态内容访问速度的CDN
- 大型网站的存储支持
- 分布式文件系统
- NoSQL
- 缓存系统
- 搜索系统
- 爬虫问题
- 倒排索引
- 查询预处理
- 相关度计算
- 数据计算支撑
- 发布系统
- 应用监控系统
- 依赖管理系统
- 多机房问题分析
- 系统容量规划
- 内部私有云
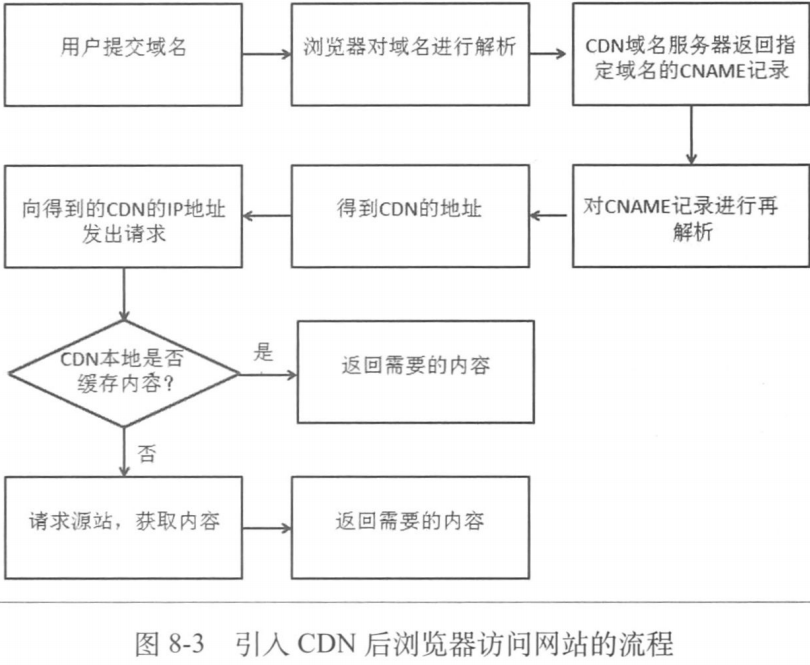
引入CDN后浏览器访问网站的流程


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix