

一文总结pipeline
pipeline
综述
流水线,亦称管线,现代计算机处理器中必不可少的部分,是指将计算机指令处理过程拆分为多个步骤,并通过多个硬件处理单元并行执行来加快指令执行速度。——from 流水线 Wikipedia
在类Unix等操作系统中,管道(Pipeline)是一系列将标准输入输出链接起来的进程,其中每一个进程的输出被直接作为下一个进程的输入。 每一个链接都由匿名管道实现。管道中的组成元素也被称作过滤程序。——from 管道 Wikipedia
概念:
- 匿名管道:?
- 具名管道:?
优势:效率提高
管线危障
pipeline hazards,一个指令在执行时,需要等待流水线上前一个指令先执行完毕,则这两个指令相互之间彼此有依赖关系。这可能导致流水线冲突的现象发生。可能出现冲突的三种情况:
- 资源冲突:流水线上的一个指令需要使用已经被另一个指令占据的资源
- 数据冲突
- 指令层的数据冲突:指令需要的数据还没有计算出来
- 传输层的数据冲突:指令需要的寄存器(register)内容还没有被存入寄存器
- 控制流冲突:流水线必须等待一个有条件Goto指令是否会被执行。
如何避免
- 通过增加功能单位可以解决资源冲突。通过把流水线后面的计算结果立刻向前传可以避免许多数据冲突。
- 通过分支预测器可以避免控制冲突。在这里处理器预测性地继续运算,直到正式预测是正确为止。假如预测错误的话那么在其中已经执行的指令要被推翻。尤其流水线非常长的处理器(比如英特尔的奔腾4或者IBM的PowerPC)在这种情况下要浪费许多时间。因此这些处理器拥有非常高级的分支预测技术,只有百分之一的分支预测会发生错误,其流水线需要清除。
Linux
管道命令操作符是:|,仅能处理经由前面一个指令传出的正确输出信息,即 standard output,对于 standard
error 信息没有直接处理能力。然后传递给下一个命令,作为标准的输入 standard input。
注意:
- 管道命令只处理前一个命令正确输出,不处理错误输出
- 管道命令右边命令,必须能够接收标准输入流命令才行
常用来作为接收数据管道命令:sed,awk,cut,head,top,less,more,wc,join,sort,split等,都是些文本处理命令。
shell脚本接收管道输入:将命令写成shell脚本,实现管道功能;
管道与重定向
区别:
- 管道:
左边的命令应该有标准输出 | 右边的命令应该接受标准输入
重定向:
左边的命令应该有标准输出 > 右边只能是文件
左边的命令应该需要标准输入 < 右边只能是文件 - 管道触发两个子进程执行
|两边的程序;而重定向是在一个进程内执行
如果是命令间传递参数,推荐使用管道;如果处理后的输出结果需要重定向到文件,推荐用重定向。
Tee
tee是一个常见的指令,将某个指令的标准输出,导向、存入某个档案中

如上示意,tee同时将数据流分送到文件与屏幕(screen,即标准输出stdout)。
语法:tee [-ai][--help][--version][文件...]
参数:
-a, --append:追加,默认是覆盖模式
-i, --ignore-interrupts:忽略中断信号。
Java
JDK的API里面也有很多pipeline思想的具体实现。
文件流
PipedInputStream与PipedOutputStream可以实现线程之间的数据通信;
public class PipedStreamDemo {
public static void main(String[] args) {
PipedInputStream pin = new PipedInputStream();
PipedOutputStream pout = new PipedOutputStream();
try {
// 输入流与输出流链接
pin.connect(pout);
} catch (Exception e) {
}
new Thread(new ReadThread(pin)).start();
new Thread(new WriteThread(pout)).start();
}
}
/**
* 读取数据的线程
*/
class ReadThread implements Runnable {
private PipedInputStream pin;
ReadThread(PipedInputStream pin) {
this.pin = pin;
}
@Override
public void run() {
try {
byte[] buf = new byte[1024];
// read阻塞
int len = pin.read(buf);
String s = new String(buf, 0, len);
System.out.println("reading:" + s);
pin.close();
} catch (IOException e) {
}
}
}
/**
* 写入数据的线程
*/
class WriteThread implements Runnable {
private PipedOutputStream pout;
WriteThread(PipedOutputStream pout) {
this.pout = pout;
}
@Override
public void run() {
try {
// 管道输出流
pout.write("java pipeline testing".getBytes());
pout.close();
} catch (Exception e) {
}
}
}
Collectors.teeing
JDK12提供的工具类方法Collectors.teeing,根据 merger 来 merge 两个 downstream collector 的输入,并输出。
public static Collector teeing(Collectorsuper T, ?, R1> downstream1,
Collectorsuper T, ?, R2> downstream2, BiFunctionsuper R1, ? super R2, R> merger) {
return teeing0(downstream1, downstream2, merger);
}
Every element passed to the resulting collector is processed by both downstream collectors
集合中每一个要被传入 merger 的元素都会经过 downstream1 和 downstream2 的加工处理
merger类型是BiFunction,接收两个参数,并输出一个值,其apply方法:
@FunctionalInterface
public interface BiFunction<T, U, R> {
/**
* Applies this function to the given arguments.
*/
R apply(T t, U u);
}
例子
- 计数和累加
@AllArgsConstructor
@ToString
class CountSum {
private final Long count;
private final Integer sum;
}
@Test
public void test1() {
CountSum countsum = Stream.of(2, 11, 1, 5, 7, 8, 12)
.collect(Collectors.teeing(counting(), summingInt(e -> e), CountSum::new));
System.out.println(countsum.toString());
}
downstream1 通过 Collectors 的静态方法 counting 进行集合计数
downstream2 通过 Collectors 的静态方法 summingInt 进行集合元素值的累加
merger 通过 CountSum 构造器收集结果
运行结果:CountSum{count=7, sum=46}
- 预约人员列表和预约人数
@Data
@AllArgsConstructor
private class Guest {
private String name;
private boolean participating;
private Integer participantsNumber;
}
@Data
@AllArgsConstructor
private class EventParticipation {
private List guestNameList;
private Integer totalNumberOfParticipants;
}
@Test
public void test2() {
var result = Stream.of(
new Guest("Marco", true, 3),
new Guest("David", false, 2),
new Guest("Roger", true, 6))
.collect(Collectors.teeing(
Collectors.filtering(Guest::isParticipating,
mapping(Guest::getName, toList())),
Collectors.summingInt(Guest::getParticipantsNumber),
EventParticipation::new
));
System.out.println(result);
}
downstream1 通过 filtering 方法过滤出确定参加的人,并 mapping 出他们的姓名,最终放到 toList 集合中
downstream2 通过 summingInt 方法计数累加
merger 通过 EventParticipation 构造器收集结果
定义 var result 来收集结果,并没有指定类型,新版本的JDK的语法糖也可以加速编程效率
运行结果:EventParticipation { guests = [Marco, Roger], total number of participants = 11 }
tomcat
以9.0.31版本来讲解。
public interface Contained {
Container getContainer();
void setContainer(Container container);
}
public interface Pipeline extends Contained {
Valve getBasic();
void setBasic(Valve var1);
void addValve(Valve var1);
Valve[] getValves();
void removeValve(Valve var1);
Valve getFirst();
boolean isAsyncSupported();
void findNonAsyncValves(Set<String> var1);
}
Pipeline主要提供对Valve的增删查改操作,StandardPipeline是其实现类。两个核心方法:
- setBasic:最核心逻辑,basic实际上就是Pipeline维护的Valve链里最末尾的一个Valve
- addValve:被添加的Valve被加在basic的前一个,也就是说basic永远指向Valve链里的最后一个Valve,不会被轻易替代
Valve扮演着业务实际执行者的角色,源码:
public interface Valve {
Valve getNext();
void setNext(Valve valve);
void backgroundProcess();
void invoke(Request request, Response response) throws IOException, ServletException;
boolean isAsyncSupported();
}
invoke():最核心方法,用来执行具体的逻辑setNext(Valve valve);:用来构造一条Valve链
ValveBase抽象类实现Valve:
Valve接口的实现类非常多:
可以看到诸如负载均衡、单点登录、SSL加密等逻辑。这些Valve的invoke方法主要做两件事情
- 自身逻辑
- 通过
getNext().invoke(request, response)调用下一个Valve的逻辑
实际上就是责任链设计模式,一个valve就是一个逻辑体。
Pipeline管道,则是若干Valve的集合,内部会对这个集合进行遍历,调用每个元素的业务逻辑方法invoke()。
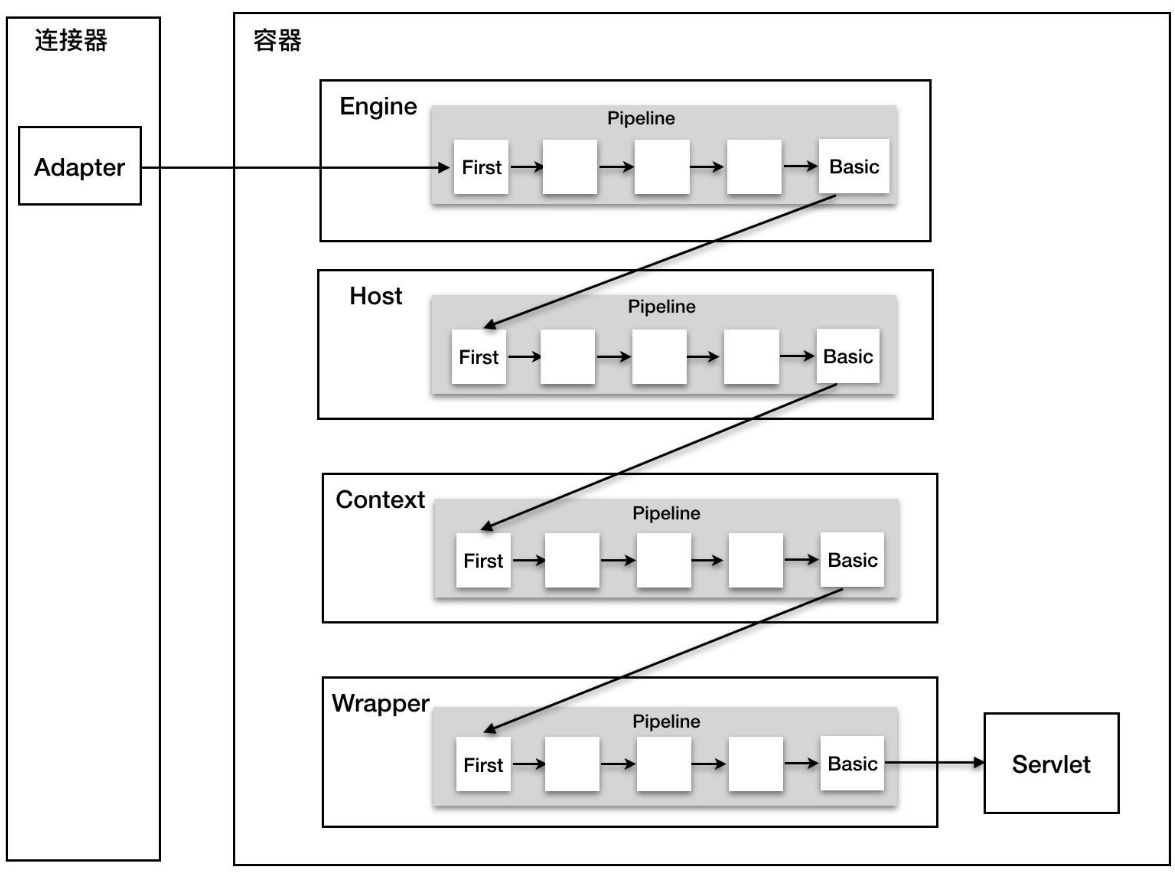
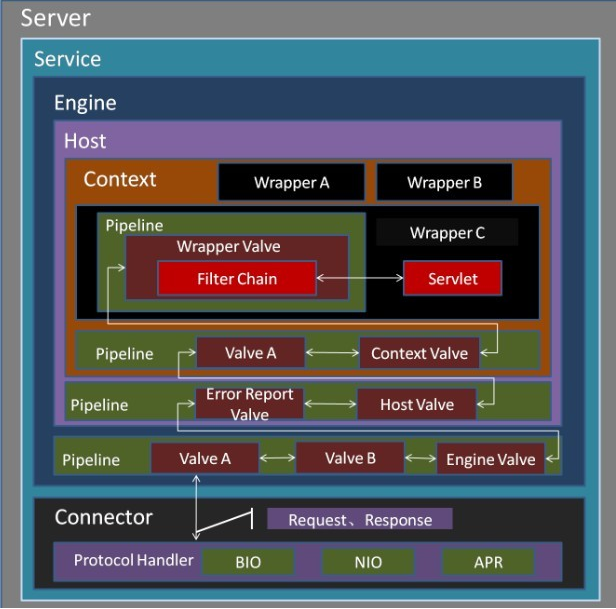
最后再来看看Pipeline在Tomcat里面的定位:
Redis
Redis基于Request/Response协议,即客户端每发送一个命令,需等待Redis server接收命令、处理并返回响应结果。其中发送命令加上返回结果的时间称为Round Trip Time,RTT,往返时间。如果客户端发送大量的命令给Redis,那就是等待上一条命令应答后再执行再执行下一条命令,这中间不仅仅多RTT,而且还频繁的调用系统IO,发送网络请求。
客户端发起一次Redis请求主要有如下开销:
- socket IO导致的上下文切换开销
- 指令执行开销
- (高并发下)资源竞争和系统调度调度开销
pipeline
Pipeline,流水线,可以极大改善这个缺点。Pipeline能将一组Redis命令进行组装,然后一次性传输给Redis,再将Redis执行这组命令的结果按照顺序返回给客户端。
前提是pipeline执行的指令之间没有因果相关性。使用redis-benchmark进行压测的时候可以发现影响redis的QPS峰值的一个重要因素是pipeline批次指令的数目,即Pipeline组装的命令个数不能没有限制,否则一次组装数据量过大,一方面增加客户端的等待时间,另一方面会造成网络阻塞,需要批量组装。用pipeline方式打包命令发送,redis必须在处理完所有命令前先缓存起所有命令的处理结果。打包的命令越多,缓存消耗内存也越多。
没有任何事务保证,其他client的命令可能会在本pipeline的中间被执行。
部分客户端,如Jedis会将命令打包,并控制每个包的大小。每个包大小大约为8K,大量命令会被分为多个包,以包为单位逐批发送到redis服务器执行。
批量
pipeline实际上是批量处理的一种实现形式。批量处理指令包括:
- 批量get/set(multi get/set)
- 管道(pipelining)
- 事务(transaction)
- 基于事务的管道(transaction in pipelining)
mget/mset(适用于string类型),hmget/hmset(适用于hash类型),严格来说不属于批量操作,而是在一个指令中处理多个key。
缺点:
批量命令不保证原子性,存在部分成功部分失败的情况,需要应用程序解析返回的结果并做相应处理。
批量命令在key数目巨大时存在RRT与key数目成比例放大的性能衰减,会导致单实例响应性能(RRT)严重下降。
集群行为
集群场景下,批量处理的行为会变得很复杂。原生的Redis Cluster不支持多节点的批处理,对于阿里云、codis的Cluster尽管支持批处理,其性能相对非集群下,有一定下降,其中来自多节点数据遍历和最终汇集返回到client。
批量的集群行为和管道的集群行为又不尽相同。待学习。
Jenkins
Jenkins-pipeline
Jenkins-pipeline-中文版
Jenkins pipeline的定义形成Jenkinsfile,可以做版本控制,实现pipeline as code(流水线即代码);
声明式和脚本式流水线都是 DSL 语言,脚本式流水线是用一种限制形式的 Groovy 语法编写的。
流水线可以通过以下任一方式来创建:
- Blue Ocean:插件,在 Blue Ocean 中设置一个流水线项目后,Blue Ocean UI 会帮你编写流水线的 Jenkinsfile 文件并提交到源代码管理系统
- 经典UI:在 Jenkins 中直接输入基本的流水线
- Jenkinsfile:手写DSL脚本文件,也方便进行源码版本化管理
参考
Wikipedia-流水线
Wikipedia-管道
Wikipedia-Tee
初识pipeline
Redis批量操作详解及性能分析
鸟哥Linux私房菜
jenkins-pipeline
jdk12-collectors-teeing
Tomcat之Pipeline-Valve


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix