

面试必备之负载均衡基础
引言
作为高可用的解决方案其一,负载均衡具备极度的重要性。
定义
负载均衡,Load Balance,指由多台服务器以对称的方式组成一个服务器集合,每台服务器都具有等价的地位,都可以单独对外提供服务而无须其他服务器的辅助。通过某种负载分担技术,将外部发送来的请求均匀分配到对称结构中的某一台服务器上,而接收到请求的服务器独立地回应客户的请求。负载均衡能够平均分配客户请求到服务器阵列,借此提供快速获取重要数据,解决大量并发访问服务问题,这种集群技术可以用最少的投资获得接近于大型主机的性能。本质和「分布式系统」一样,是「分治」。
应用场景
- web集群:将大量的并发访问或数据流量分担到多台节点设备上分别处理,减少用户等待响应的时间。
- MapReduce:单个重负载的运算分担到多台节点设备上做并行处理,每个节点设备处理结束后,将结果汇总,返回给⽤户,系统处理能⼒得到大幅度提高。
分类
软件、硬件
负载均衡分为软件负载均衡和硬件负载均衡,前者的代表是LVS、HAProxy、Nginx,后者则是均衡服务器如F5,价格昂贵。
目前,在线上环境中应用较多的负载均衡器硬件有F5 BIG-IP,负载均衡软件有LVS,Nginx及HAProxy,高可用软件有Heartbeat、Keepalived,成熟的架构有LVS+Keepalived、Nginx+Keepalived、HAProxy+keepalived及DRBD+Heartbeat。
服务端、客户端
按照负载均衡作用的地方,可以分为服务端负载均衡和客户端负载均衡。
大部分都是服务端,客户端如Netflix Ribbon,前置的网关将一个请求发送给某一个服务提供者应用,若此服务为了高可用启动有多个实例时,Ribbon会通过内置的负载均衡策略选择一个服务实例。
OSI模型
根据OSI七层模型,在不同层级实现。主要有以下四种:
- 应用层
Layer 7 Load Balance,L7LB,OSI模型第七层,包括HTTP、HTTPS 和 WebSocket。通过这种技术,能负载均衡数十或上百服务器实例。注意要停用SSL。实现工具:Nginx、HAProxy; - 传输层
Layer 4 Load Balance,L4LB,OSI第四层,包括TCP 和 UDP。从前端过来的请求,先经过L4LB,再分发经过L7LB。由于更靠近底层,能负载均衡的实例更多。实现上,可以组合起来,应用层负载均衡+传输层负载均衡。工具:HAProxy、IPVS; - 网络层
Layer 3 Load Balance,L3LB,OSI第三层,包括 IPv4 和 IPv6,技术实现更复杂。原理:等价路由(ECMP)。当有多条等价链路到达相同地址时,使用等价路由。它允许路由器或交换机通过不同链接发送数据包(支持高吞吐量),最终到达同一地址。每个传输层负载均衡器是相同的。这意味着可以把从网络层负载均衡器到传输层负载均衡器的链接看做相同目的地的链路。如果我们把所有负载均衡器绑定到相同 IP 地址,我们可以使用等价路由在传输层负载均衡器之间分配通信。工具:交换机内部硬件。
其他
DNS 负载均衡
DNS 是将名称转换为 IP 地址的系统。它当然也可以返回多个 IP 地址;
如果返回多个 IP,客户端通常会使用第一个可用的地址(然而一些应用只看第一个返回的 IP)。
目前有很多 DNS 负载均衡技术,比如 GeoDNS 和轮询调度(round-robin)。GeoDNS 基于不同请求者而返回不同响应,可以将客户端路由到其最近的服务器或数据中心。轮询调度会循环所有可用的 IP 地址,对于每个响应会返回不同的 IP。如果多个 IP 可用,这两种技术仅仅改变响应里的 IP 顺序。
DNS负载均衡工作原理:
不同的用户被路由到不同的服务集群(随机或基于地理位置)。
现在这里不再有单点故障的可能性(假设有多台 DNS 服务器)。为了进一步提高可靠性,我们可以在不同数据中心运行多个服务集群。
算法
负载均衡的核心在于其算法实现上。
随机法
最简单的一种,每个请求随机分配到后端服务器。随请求量增大,其实际效果和轮询法一样。
加权随机法
Weight Random,加权和随机的组合。
public class WeightRandom {
public static String getServer() {
// 重建一个Map,避免服务器的上下线导致的并发问题
Map<String, Integer> serverMap = new HashMap<>();
serverMap.putAll(IpMap.serverWeightMap);
// 取得Ip地址List
Set<String> keySet = serverMap.keySet();
Iterator<String> iterator = keySet.iterator();
List<String> serverList = new ArrayList<>();
while (iterator.hasNext()) {
String server = iterator.next();
int weight = serverMap.get(server);
for (int i = 0; i < weight; i++)
serverList.add(server);
}
Random random = new Random();
int randomPos = random.nextInt(serverList.size());
return serverList.get(randomPos);
}
}
轮询法
将请求按顺序轮流地分配到后端服务器上,均衡对待后端所有服务器,而不关心服务器实际的连接数和当前的系统负载。
int globalIndex = 0;//全局变量
try {
return servers[globalIndex];
}
finally {
globalIndex++;
if (globalIndex == 3)
globalIndex = 0;
}
加权轮询法
在轮询的基础上,增加权重的概念。考虑到,每台服务器配置不同,因此应给配置高、负载低的机器配置更高的权重以处理更多的请求。加权轮询算法将请求顺序且按照权重分配到后端。
加权轮询的一种伪代码实现方案:
int matchedIndex = -1;
int total = 0;
for (int i = 0; i < servers.length; i++) {
// 每次循环的时候做自增(步长=权重值)
servers[i].cur_weight += servers[i].weight;
// 将每个节点的权重值累加到汇总值中
total += servers[i].weight;
// 如果当前节点的自增数 > 当前待返回节点的自增数,则覆盖
if (matchedIndex == -1 || servers[matchedIndex].cur_weight < servers[i].cur_weight) {
matchedIndex = i;
}
}
// 被选取的节点减去汇总值total,以降低下一次被选举时的初始权重值
servers[matchedIndex].cur_weight -= total;
return servers[matchedIndex];
加权轮询还有其他不同的实现方式,虽然总体来说,最终多个节点(假如有3个)接收到的请求比例都是Wa:Wb:Wc(分别表示3个节点设置的权重值)。但是在请求送达的先后顺序上可以有所不同。假如有一种加权轮询算法的实现效果是,连续2~3次请求都打到同一个节点,而不是分散均匀,则更容易产生并发问题,导致服务端拥塞,且这个问题随着权重数字越大越严重。
IP哈希法
即Hash法,获取客户端访问的IP地址值,通过哈希函数计算得到一个数值,用该数值对服务器列表的大小进行取模运算,得到的结果便是要访问的服务器的序号。
优点:保证相同客户端IP地址总会被哈希到同一台后端服务器,直到后端服务器列表变更。实现有状态的session会话,即粘性session。
缺点:万一后端服务器挂掉,则路由失败。
最大空闲
Most idle First,基于监控CPU,内存,带宽等综合评估。
最少流量
Least Traffic Scheduling,基于会话的负载均衡,但是严格来说Session(一般用于WEB)不能算是算法。Session实现负载均衡的主要过程为:首次请求记录用户的SessionID,然后再通过轮询等算法选择后端服务器,如果用户后续使用同一SessionID发起请求,则无需再选择服务器,直接转发给前面根据SessionID找到的对应的后端服务器。
最少连接法
Least Connections,又最少请求法,动态调度算法,根据实时的负载情况,进行动态负载均衡的方式。维护好活动中的连接数量,然后取最小的返回即可。
它通过服务器当前所活跃的连接数来估计服务器的负载情况。算法主要逻辑是,调度设备或服务记录后端服务器接受请求的计数,每次请求总是发给计数最小的服务器处理。
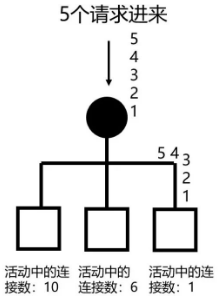
var matchedServer = servers.orderBy(e => e.active_conns).first();
matchedServer.active_conns += 1;
return matchedServer;
//在连接关闭时还需对active_conns做减1的动作。
最快响应
动态,本质是根据每个节点对过去一段时间内的响应情况来分配,响应越快分配的越多。将最近一段时间的请求耗时的平均值记录下来,结合前面的「加权轮询」来处理,所以等价于2:1:3的加权轮询。
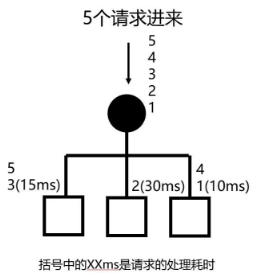
总结
实际使用中,为了获得更优的均衡效果,可以将上面的算法策略加以组合使用、或者通过更多维度的数据采样来综合评估、甚至是基于进行数据挖掘后的预测算法来做。
健康探测保障高可用
不管使用何种策略,都难免会遇到机器故障或程序故障的情况。所以要确保负载均衡能更好的起到效果,还需要结合一些健康探测(health-check)机制。定时探测服务器是否可用,连接是否发生超时。
若节点不可用,需要将这个节点临时从待选取列表中移除,以提高可用性。常用方式如下:
- HTTP探测
使用Get/Post的方式请求服务端的某个固定的URL,判断返回的内容是否符合预期。一般使用Http状态码、Response中的内容来判断。 - TCP探测
基于TCP的三次握手机制来探测指定的IP+端口。可借鉴阿里云的SLB机制:
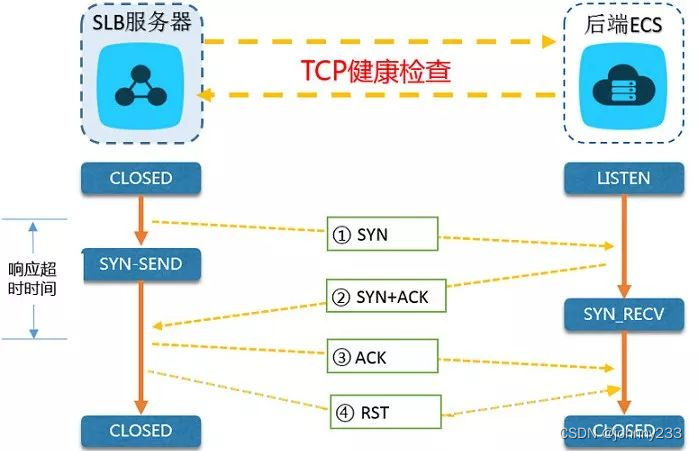
为了尽早释放连接,在三次握手结束后立马跟上RST来中断TCP连接。 - UDP探测
可通过报文来进行探测指定的IP+端口。可借鉴阿里云的SLB机制:
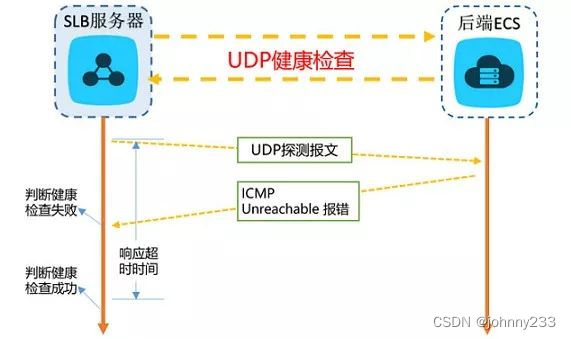
结果的判定方式是:在服务端没有返回任何信息的情况下,默认正常状态;否则会返回一个ICMP的报错信息。
模式
负载均衡模式主要是指在整体方案中选择从服务网络的哪个层次或哪个产品来实现负载均衡方案。
- 外部模式
RR-DNS,即DNS轮询模式,原理是利用DNS服务器支持同一域名配置多个独立IP指向,然后轮询解析指向IP实现多次访问的调度和分发,实现负载均衡。
主要特点:- 负载均衡实现与后端服务完全没有关系,有DNS在本地解析指向实现轮询调度。这个方面来看性能最佳效率最高。
- DNS服务无法检测到后端服务器是否正常,在TTL失效前,会一直指向失效的服务器,这就要求在实践生成中,必须解决后端服务器的高可用问题。
- 一般的第三方DNS服务提供商都支持该功能,但如果更新频率高或附带更新逻辑,一般会在系统内自建DNS服务,然后在注册为公共DNS服务。
- 应用层模式
分正向和反向代理。- 正向代理:用户通过代理服务访问internet,把internet返回的数据转发给用户。正向代理对于整个网络请求,它的角色实际是客户端,代理客户对外的访问请求。
- 反向代理:接受internet上用户的请求,转发给内部的多台服务器处理,完成后转发后端服务器的返回给对应的用户。反向代理对于整个网络请求,它的角色实际是服务器,代理接受(accept)所有用户的请求。
反向代理应用模式:如通过 Apache、Nginx等实现WEB应用的负载均衡和高可用。
利用反向代理软件实现负载均衡是性价比较高的模式。
- 网络层模式
如IP转换,一般在网络的IP层实现,通过报文改写的方式实现VIP到多个内部IP的转发调度,以达到负载均衡的效果。 主要特点:网络层方案,效率较高,稳定性较好;可与操作系统内核结合;工业级模式和方案;大部分商业设备和产品都以该方式为主。LVS的基本原理也类同。LVS(Linux Virtual Server),工业级的负载平衡调度解决方案。LVS也是利用IP转发的原理实现大多数有商业产品实现的能力,并做部分优化,主要有三种模式的应用。- 通过NAT(Network Address Translation)实现虚拟服务器(VS/NAT)
- 通过IP隧道实现虚拟服务器(VS/TUN)
- 通过直接路由实现虚拟服务器(VS/DR)
LVS
官网
LVS,Linux virtual server,LINUX虚拟服务器,是一个虚拟的服务器集群系统。
工作原理
LVS负载均衡调度技术是在Linux内核中实现的,使用配置LVS时,不是直接配置内核中的IPVS,而是通过IPVS的管理工具IPVSADM来管理配置
LVS集群负载均衡器接受所有入站客户端的请求,并根据算法来决定由哪个集群的节点来处理请求
术语
虚拟IP地址(VIP)
用于向客户端提供服务的IP地址(配置于负载均衡器上)
真实的IP地址(RIP)
集群中节点服务器的IP地址
负载均衡器IP地址(DIP)
负载均衡器的IP地址,物理网卡上的IP,用与同外网连接的地址
客户端主机IP地址(CIP)
终端请求用户的主机IP地址
优点:
- 抗负载能力强、工作在第4层仅作分发之用,没有流量的产生,这个特点也决定了它在负载均衡软件里的性能最强的;无流量,同时保证了均衡器IO的性能不会受到大流量的影响;
- 工作稳定,自身有完整的双机热备方案,如LVS+Keepalived和LVS+Heartbeat;
- 应用范围比较广,可以对所有应用做负载均衡;
- 配置性比较低,这是一个缺点也是一个优点,因为没有可太多配置的东西,所以并不需要太多接触,大大减少人为出错的几率;
缺点:
- 软件本身不支持正则处理,不能做动静分离,这就凸显了Nginx/HAProxy+Keepalived的优势。
- 如果网站应用比较庞大,LVS/DR+Keepalived就比较复杂了,特别是后面有Windows Server应用的机器,实施及配置还有维护过程就比较麻烦,相对而言,Nginx/HAProxy+Keepalived简单。
Nginx
本文略加表述,可参考面试必备之Nginx入门学习
- 工作在OSI第7层,可以针对http应用做一些分流的策略。比如针对域名、目录结构。它的正则比HAProxy更为强大和灵活;
- Nginx对网络的依赖非常小,理论上能ping通就就能进行负载功能;
- 可以承担高的负载压力且稳定,一般能支撑超过几万次的并发量;
- Nginx可以通过端口检测到服务器内部的故障,比如根据服务器处理网页返回的状态码、超时等等,并且会把返回错误的请求重新提交到另一个节点;
HAProxy
优点:
- HAProxy是支持虚拟主机的,可以工作在4、7层(支持多网段);
- 能够补充Nginx的一些缺点比如Session的保持,Cookie的引导等工作;
- 支持url检测后端的服务器;
- 跟LVS一样,本身仅仅就只是一款负载均衡软件;单纯从效率上来讲HAProxy更会比Nginx有更出色的负载均衡速度,在并发处理上也是优于Nginx的;
- HAProxy可以对Mysql读进行负载均衡,对后端的MySQL节点进行检测和负载均衡,不过在后端的MySQL slaves数量超过10台时性能不如LVS;
- HAProxy的算法较多,达到8种;
负载均衡方式?
HTTP重定向,DNS域名解析负载均衡,反向代理负载均衡,LVS-NAT, LVS-TUN, LVS-DR。
参考
LVS Nginx HAProxy 三种负载均衡优缺点比较
Facebook 这类网站如何处理数十亿请求并保持高可用性的?


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix