

面试必备之HashMap和ConcurrentHashMap
HashMap
概述
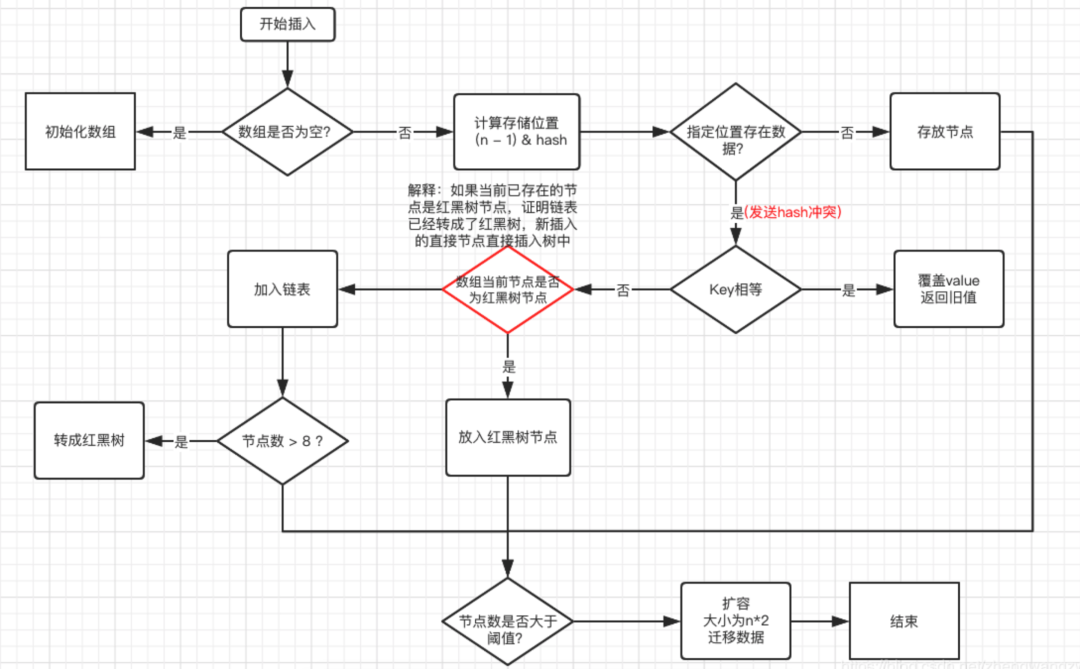
在Java 8中,HashMap的数据结构是由Node<k,v>作为元素组成的数组:(1)如果有多个值hash到同一个桶中,则组织成一个链表,当链表的节点个数超过某个阈值(TREEIFY_THRESHOLD = 8)时,链表重构为一个红黑树。
初始化
HashMap容量默认是16;如果通过构造函数指定一个数字作为容量,Hash会选择大于该数字的第一个2的幂作为容量。且强烈建议在初始化时指定容量大小。
事实上,通过JMH基准测试或简单的对比测试代码,能够发现初始化时不指定容量,比初始化时指定容量耗时多,且指定一个合适的大小(基于业务数据量估算)比不合适的大小耗时要少。代码略。
扩容机制:当达到扩容条件时会进行扩容。扩容条件:当HashMap中的元素个数(size)超过临界值(threshold)时就会自动扩容。threshold = loadFactor * capacity。每次扩容,都需要重建hash表。
在JDK1.7和1.8中,初始化容量的时机不同。1.8中,在调用HashMap构造函数定义HashMap时,就会进行容量的设定。而在JDK1.7中,要等到第一次put操作时才进行这一操作。
上面提到估算合适的初始化容量大小。那如何得到这个值呢?计算公式:initialCapacity = expectedSize / 0.75F + 1.0F,参考putAll方法源码。这样设置,可减少rehash的概率,虽然会牺牲些许内存。如果使用guava的话,则无需此计算过程,直接使用Maps.newHashMapWithExpectedSize(10);即可:
static int capacity(int expectedSize) {
if (expectedSize < 3) {
CollectPreconditions.checkNonnegative(expectedSize, "expectedSize");
return expectedSize + 1;
} else {
return expectedSize < 1073741824 ? (int)((float)expectedSize / 0.75F + 1.0F) : 2147483647;
}
}
HashMap中的key若Object类型,则需实现哪些方法
hashcode和equals方法;
hashcode:重写此方法的目的:计算需要存储数据的存储位置。如果Hash函数实现得不好,会产生严重的Hash碰撞;
equals:重写此方法的目的:保证key在哈希表中的唯一性。比较存储位置上是否存在需要存储数据的key,如果存在,则直接替换更新值value;不存在则插入数据。
put方法
调用哈希函数获取Key对应的hash值,再计算其数组下标;
如果没有出现哈希冲突,则直接放入数组;如果出现哈希冲突,则以链表的方式放在链表后面;
如果链表长度超过阀值,即TREEIFY_THRESHOLD==8,链表转成红黑树;链表长度低于6,就把红黑树转回链表;即红黑树节点数目小于6,转为链表;
如果结点的key已经存在,则替换其value即可;
如果集合中的键值对大于12,调用resize方法进行数组扩容。
异或运算符
保证对象的 hashCode 的 32 位值只要有一位发生改变,整个 hash() 返回值就会改变。尽可能的减少碰撞。
数据结构
哈希表结构(链表散列:数组+链表)实现,结合数组和链表的优点。当链表长度超过8时,链表转换为红黑树。
扩容
map中的元素个数超过threshold(默认值0.75),创建一个新的数组,其容量为旧数组的两倍,并重新计算旧数组中结点的存储位置。结点在新数组中的位置只有两种,原下标位置或原下标+旧数组的大小。
Hash冲突
hash:
JDK 1.8 中,通过hashCode()的高 16 位异或低16位实现:(h = k.hashCode()) ^ (h >>>16),主要是从速度,功效和质量来考虑的,减少系统开销,也不会造成因为高位没有参与下标的计算,从而引起的碰撞。
Hash冲突,即hashCode相同,两个对象所在数组的下标相同,即碰撞。HashMap使用链表存储对象,这个 Node 会存储到链表中,然后用equals来决定在链表中的位置。
解决Hash冲突的三种方案:
- 链地址法
- 红黑树
HashMap & ConcurrentHashMap
除了加锁,原理上无太大区别。HashMap 的键值对允许有null,但是ConcurrentHashMap都不允许。
HashMap vs HashTable
同:数据结构和操作基本相同
异:
- HashMap非线程安全,HashTable是线程安全
- HashMap 需要重新计算 hash 值,而 HashTable 直接使用对象的 hashCode
- 为保证线程安全,HashTable效率比不上HashMap
- HashMap最多只允许一条记录的键为null,允许多条记录的值为null,而HashTable不允许
- HashMap默认初始化数组大小为16,HashTable 为 11,前者扩容时,扩大两倍,后者扩大两倍+1;
HashMap、TreeMap和LinkedHashMap
一般情况下,使用最多的是 HashMap。
HashMap:在 Map 中插入、删除和定位元素时;
TreeMap:TreeMap 实现 SortMap 接口,能够把它保存的记录根据键排序(默认按键值升序排序,也可以指定排序的比较器),在需要按自然顺序或自定义顺序遍历键的情况下;
LinkedHashMap:保存记录的插入顺序,在用 Iterator 遍历时,先取到的记录肯定是先插入的;遍历比 HashMap 慢;在需要输出的顺序和输入的顺序相同的情况下。
如何使HashMap变得线程安全
为什么红黑树而不是二叉查找树
二叉查找树在特殊情况下会退化为线性链表结构,其时间复杂度O(n),遍历查找速度慢。
红黑树在插入新数据后可能需要通过左旋,右旋、变色这些操作来保持平衡,引入红黑树就是为了查找数据快,解决链表查询深度的问题。红黑树属于平衡二叉树,但是为了保持“平衡”是需要付出代价的,但是该代价所损耗的资源要比遍历线性链表要少,所以当长度大于8的时候,会使用红黑树,如果链表长度很短的话,根本不需要引入红黑树,引入反而会慢。
红黑树
即红黑树的特性:
- 每个节点非红即黑
- 根节点总是黑色的
- 如果节点是红色的,则它的子节点必须是黑色的(反之不一定)
- 每个叶子节点都是黑色的空节点(NIL节点)
- 从根节点到叶节点或空子节点的每条路径,必须包含相同数目的黑色节点(即相同的黑色高度)
版本变更
- 在JDK1.8中,如果链表的长度超过8,链表将转换为红黑树。(桶的数量必须大于64,小于64的时候只会扩容)
- 发生hash碰撞时,JDK1.7 会在链表的头部插入,而JDK1.8会在链表的尾部插入
- Entry被Node替代
死锁
JDK1.7 数组+链表,链表是单向不闭合
Entry数组来存储key-value对,
https://www.jianshu.com/p/1e9cf0ac07f4
public class HashMapStu {
public static void main(String[] args) throws Exception {
final HashMap<String, String> map = new HashMap<>();
for (int i = 0; i < 10000; i++) {
new Thread(new Runnable() {
@Override
public void run() {
map.put(UUID.randomUUID().toString(), "");
}
}, "mythread-" + i).start();
}
System.out.println("ok!");
}
}
ConcurrentHashMap
概述
- 核心属性:
private transient volatile int sizeCtl;
当为负数时,-1 表示正在初始化,-N 表示 N - 1 个线程正在进行扩容;
当为 0 时,表示 table 还没有初始化;
当为其他正数时,表示初始化或者下一次进行扩容的大小。 - 数据结构:
Node 是存储结构的基本单元,继承 HashMap 中的 Entry,用于存储数据;
TreeNode 继承 Node,但是数据结构换成二叉树结构,是红黑树的存储结构;
TreeBin 是封装 TreeNode 的容器,提供转换红黑树的一些条件和锁的控制。 - 存储对象时(put() 方法):
如果没有初始化,就调用 initTable() 方法来进行初始化;
如果没有 hash 冲突就直接 CAS 无锁插入;
如果需要扩容,就先进行扩容;
如果存在 hash 冲突,就加锁来保证线程安全,两种情况:一种是链表形式就直接遍历
到尾端插入,一种是红黑树就按照红黑树结构插入;
如果该链表的数量大于阀值 8,就要先转换成红黑树的结构,break 再一次进入循环
如果添加成功就调用 addCount() 方法统计 size,并且检查是否需要扩容。 - 扩容方法 transfer():默认容量为 16,两倍扩容。
helpTransfer():调用多个工作线程一起帮助进行扩容,这样的效率就会更高。 - 获取对象时(get()方法):
计算 hash 值,定位到该 table 索引位置,如果是首结点符合就返回;
如果遇到扩容时,会调用标记正在扩容结点 ForwardingNode.find()方法,查找该结点,匹配就返回;
以上都不符合的话,就往下遍历结点,匹配就返回,否则最后就返回 null。
ConcurrentHashMap和HashTable
HashTable 使用一把锁(锁住整个链表结构)处理并发问题,多个线程竞争一把锁,容易阻塞;
ConcurrentHashMap
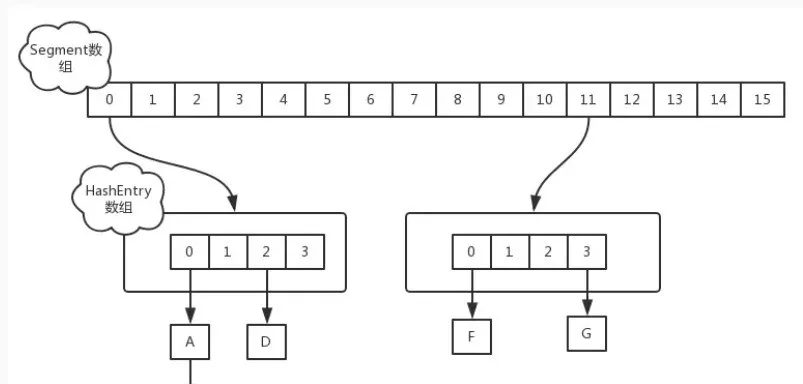
JDK 1.7 中使用分段锁(ReentrantLock + Segment + HashEntry),相当于把一个 HashMap 分成多个段,每段分配一把锁,这样支持多线程访问。锁粒度:基于 Segment,包含多个 HashEntry。
JDK 1.8 中使用 CAS + synchronized + Node + 红黑树。锁粒度:Node(首结点)(实现 Map.Entry)。锁粒度降低。
并发度
程序运行时能够同时更新 ConccurentHashMap且不产生锁竞争的最大线程数。默认为 16,且可以在构造函数中设置。
当用户设置并发度时,ConcurrentHashMap 会使用大于等于该值的最小2幂指数作为实际并发度(假如用户设置并发度为17,实际并发度则为32)
版本
JDK 1.7 中,采用分段锁的思想减小锁的粒度,实现并发的更新操作,提升性能,底层采用数组+链表的存储结构,包括两个核心静态内部类 Segment 和 HashEntry。
- Segment 继承 ReentrantLock(重入锁) 用来充当锁的角色,每个 Segment 对象守护每个散列映射表的若干个桶;
- HashEntry 用来封装映射表的键-值对;
- 每个桶是由若干个 HashEntry 对象链接起来的链表
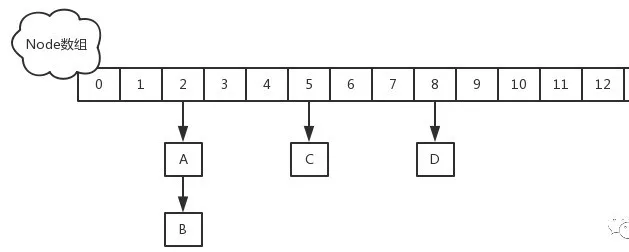
JDK 1.8 中,采用Node + CAS + Synchronized来保证并发安全。移除类Segment,直接用 table 数组存储键值对;当 HashEntry 对象组成的链表长度超过TREEIFY_THRESHOLD时,链表转换为红黑树,提升性能。底层变更为数组 + 链表 + 红黑树。
1.8相对于1.7的改进:
- 加入红黑树,当链表的数量超过8并且当前capacity大于64时,将链表转为红黑树,时间复杂度
O(N)→O(logN),红黑树利用读写锁保证添加修复和删除修复时候的线程安全。 - 去掉Segment,去除分段锁?分段锁的在扩充并发度以及整个map容量扩展时需要锁住所有的段。1.8中对ConcurrentHashMap做更细粒度的优化,只在put、resize以及扩容是加锁,来做优化。table每个元素作为一个桶,锁的粒度更细,用synchronized关键字锁住
table[i]。 - 扩容优化
JDK1.8,synchronized代替ReentrantLock
原因:
- 降低锁粒度;
- JDK1.6版本后,JVM对synchronized进行性能方面的大大优化;


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix