

一文入门缓存技术
注:缓存思想很通用,但本文可能会比较偏后端Java开发人员。
概述
定义:
- 狭义上的缓存,Cache,高速缓冲存储器,一种特殊的存储器子系统,其中复制有频繁使用的数据以利于快速访问。
- 广义上的缓存,凡是位于速度相差较大的两种硬件/软件之间的,用于协调两者数据传输速度差异的结构,均可称之为 Cache。
缓存可以级联使用,可缓解甚至解决性能问题,无处不在:操作系统磁盘缓存(减少磁盘机械操作)、PC电脑中的内存、CPU中的二级缓存、HTTP协议中的缓存控制、CDN加速、Web服务器缓存、浏览器缓存(减少对网站的访问)、数据库缓存(减少文件系统I/O)、应用程序缓存……
缓存适合的场景:热数据,读多写少,一致性要求不高。
常见缓存
操作系统缓存
- 文件系统提供的Disk Cache:操作系统会把经常访问到的文件内容放入到内存当中,由文件系统来管理;
- 当应用程序通过文件系统访问磁盘文件的时候,操作系统从Disk Cache当中读取文件内容,加速文件读取速度;
- Disk Cache由操作系统来自动管理,一般不用人工干预,但应当保证物理内存充足,以便于操作系统可以使用尽量多的内存充当Disk Cache,加速文件读取速度;
- 特殊的应用程序对文件系统Disk Cache有很高的要求,会绕开文件系统Disk Cache,直接访问磁盘分区,自己实现Disk;
- Cache策略
Oracle的raw device(裸设备) – 直接抛弃文件系统
MySQL的InnoDB:innodb_flush_method = O_DIRECT
数据库缓存
- 查询缓存
Query Cache,以SQL作为key值缓存查询结果集,一旦查询涉及的表记录被修改,缓存就会被自动删除,设置合适的Query Cache会极大提高数据库性能,Query Cache并非越大越好,过大的Qquery Cache会浪费内存。MySQL:query_cache_size= 128M - Data Buffer
data buffer是数据库数据在内存中的容器,其命中率直接决定数据库的性能,data buffer越大越好,多多益善。MySQL的InnoDB buffer:innodb_buffer_pool_size = 2G,MySQL建议buffer pool开大到服务器物理内存60-80%。
应用缓存
1、对象缓存
由O/R Mapping框架例如Hibernate提供,透明性访问,细颗粒度缓存数据库查询结果,无需业务代码显式编程,是最省事的缓存策略
当软件结构按照O/R Mapping框架的要求进行针对性设计,使用对象缓存将会极大降低Web系统对于数据库的访问请求
良好的设计数据库结构和利用对象缓存,能够提供极高的性能,对象缓存适合OLTP(联机事务处理)应用
页面缓存
作用:针对页面的缓存技术不但可以减轻数据库服务器压力,还可以减轻应用服务器压力,好的页面缓存可以极大提高页面渲染速度,页面缓存的难点在于如何清理过期的缓存。
分类
动态页面静态化
利用模板技术将访问过一次的动态页面生成静态html,同时修改页面链接,下一次请求直接访问静态链接页面
动态页面静态化技术的广泛应用于互联网CMS/新闻类Web应用,但也有BBS应用使用该技术,例如Discuz!
无法进行权限验证,无法显示个性化信息
可以使用AJAX请求弥补动态页面静态化的某些缺点
II、Servlet缓存
针对URL访问返回的页面结果进行缓存,适用于粗粒度的页面缓存,例如新闻发布
可以进行权限的检查
OScache提供简单的Servlet缓存(通过web.xml中的配置)
也可以自己编程实现Servlet缓存
III、页面内部缓存
针对动态页面的局部片断内容进行缓存,适用于一些个性化但不经常更新的页面(例如博客)
OSCache提供了简单的页面缓存
可以自行扩展JSP Tag实现页面局部缓存
服务器缓存
- 反向代理服务器缓存,如nginx;
- 静态站点Web服务器缓存,如squid/nginx;
- 静态资源内容分发服务器缓存,如CDN;
- servlet服务器缓存,如Tomcat;
浏览器缓存
缓存模式
本质上来讲,缓存策略取决于数据和数据访问模式。即,数据是如何写和读的。如:
- 系统是写多读少的吗?
- 数据是否是只写入一次并被读取多次?
- 返回的数据总是唯一的吗?
选择正确的缓存策略才是提高性能的关键。常用的缓存策略有以下四种:
- Cache-Aside Pattern:旁路缓存模式
- Read Through Cache Pattern:读穿透模式
- Write Through Cache Pattern:写穿透模式
- Write Behind Pattern:又叫Write Back,异步缓存写入模式
上述缓存策略的划分是基于对数据的读写流程来区分的,有的缓存策略下是应用程序仅和缓存交互,有的缓存策略下应用程序同时与缓存和数据库进行交互。
Cache Aside
最常见的缓存模式,应用程序可直接与缓存和数据库对话。Cache Aside可用来读操作和写操作。
读操作:
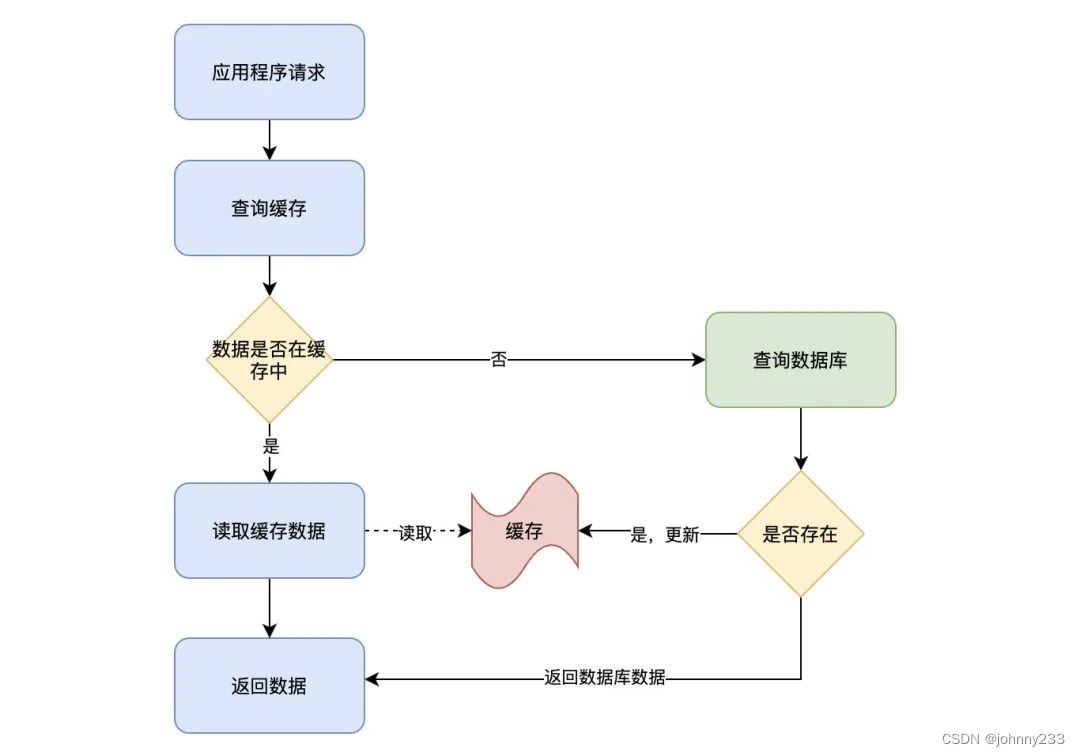
读操作的流程:
- 应用程序接收到数据查询(读)请求;
- 应用程序所需查询的数据是否在缓存上:
- 如果存在(Cache hit),从缓存上查询出数据,直接返回;
- 如果不存在(Cache miss),则从数据库中检索数据,并存入缓存中,返回结果数据;
这里需要留意一个操作的边界,也就是数据库和缓存的操作均由应用程序直接进行操作。
写操作,包括创建、更新和删除。在写操作时,Cache Aside模式是先更新数据库(增、删、改),然后直接删除缓存。
Cache Aside模式可以说适用于大多数的场景,通常为了应对不同类型的数据,还可以有两种策略来加载缓存:
- 使用时加载缓存:当需要使用缓存数据时,从数据库中查询出来,第一次查询之后,后续请求从缓存中获得数据;
- 预加载缓存:在项目启动时或启动后通过程序预加载缓存信息,如用户信息等不是经常变更的数据。
Cache Aside适用于读多写少的场景,一旦写入缓存,几乎不会进行修改。缺点是可能会出现缓存和数据库双写不一致的情况。
Read Through
Read-Through和Cache-Aside很相似,不同点在于程序不需要关注从哪里读取数据(缓存还是数据库),它只需要从缓存中读数据。而缓存中的数据从哪里来是由缓存决定的。
Cache Aside是由调用方负责把数据加载入缓存,而Read Through则用缓存服务自己来加载,从而对应用方是透明的。Read-Through的优势是让程序代码变得更简洁。
流程图:
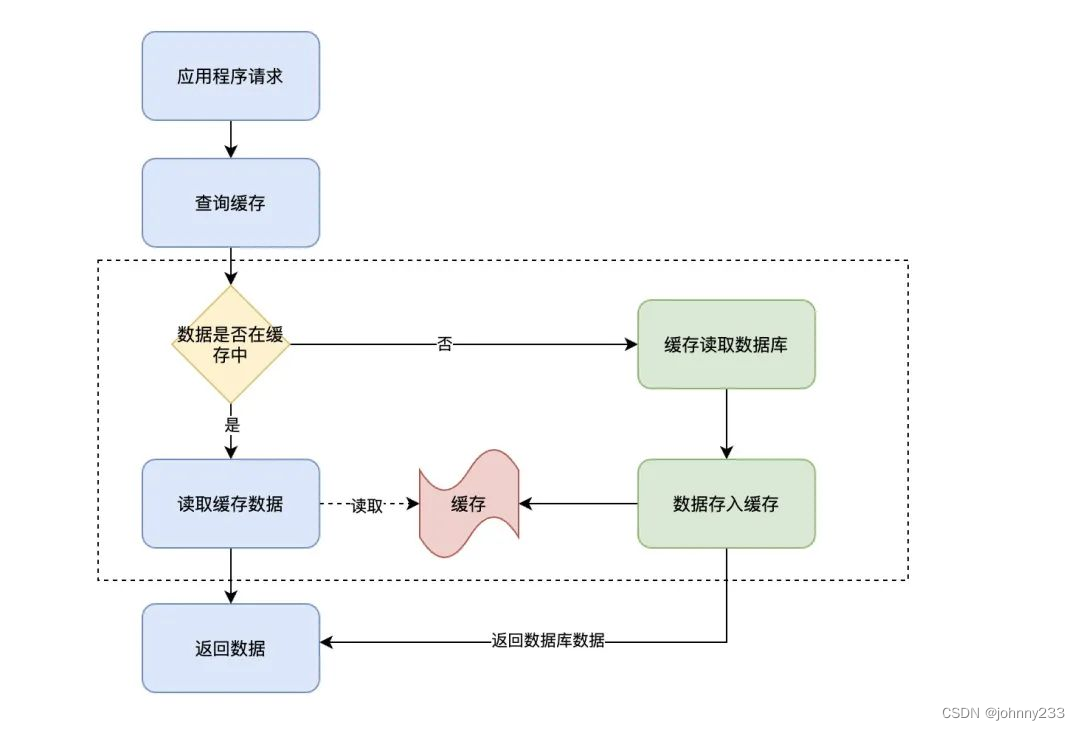
虚线框内的操作,不再由应用程序来处理,而是由缓存自己来处理。即,当应用从缓存中查询某条数据时,如果数据不存在则由缓存来完成数据的加载,最后再由缓存返回数据结果给应用程序。
Write Through
在Cache Aside中,应用程序需要维护两个数据存储:一个缓存,一个数据库。这对于应用程序来说,有一些繁琐。
Write-Through模式下,所有的写操作都经过缓存,每次向缓存中写数据时,缓存会把数据持久化到对应的数据库中去,且这两个操作在一个事务中完成。因此,只有两次都写成功才是最终写成功。坏处是有写延迟,好处是保证数据一致性。
可以理解为,应用程序认为后端就是一个单一的存储,而存储自身维护自己的Cache。
因为程序只和缓存交互,编码会变得更加简单和整洁,当需要在多处复用相同逻辑时这点就变得格外明显。
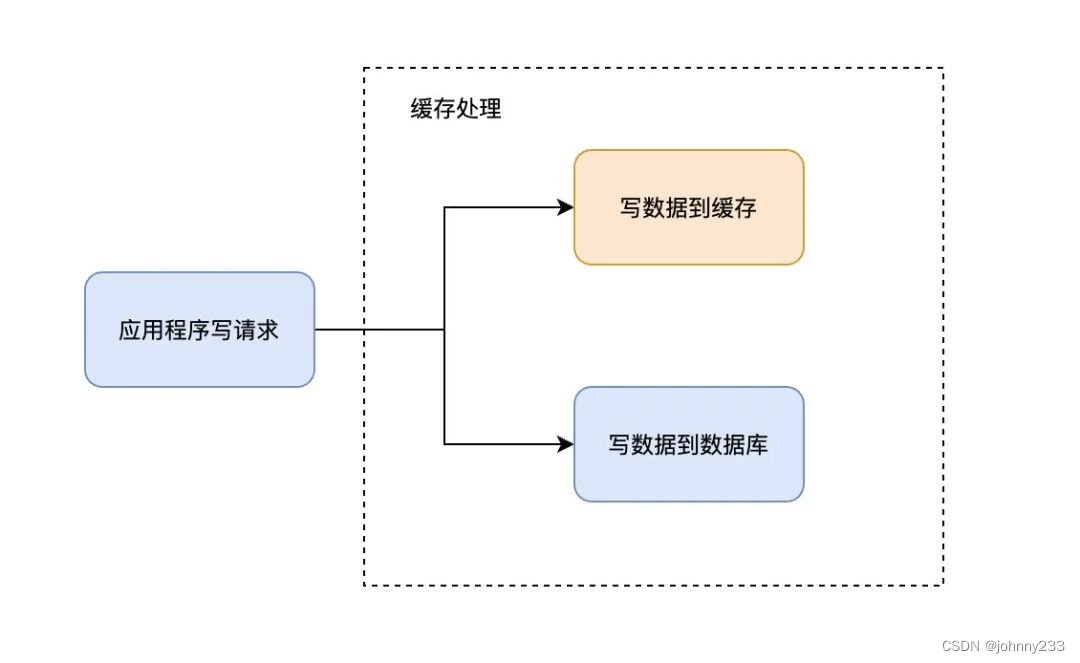
当使用Write-Through时,一般都配合使用Read-Through来使用。Write-Through的潜在使用场景是银行系统。
Write-Through适用情况有:
- 需要频繁读取相同数据
- 不能忍受数据丢失(相对Write-Behind而言)和数据不一致
在使用Write-Through时要特别注意的是缓存的有效性管理,否则会导致大量的缓存占用内存资源。甚至有效的缓存数据被无效的缓存数据给清除掉。
Write-Behind
Write-Behind和Write-Through在 程序只和缓存交互且只能通过缓存写数据 这方面很相似。不同点在于Write-Through会把数据立即写入数据库中,而Write-Behind会在一段时间之后(或是被其他方式触发)把数据一起写入数据库,这个异步写操作是Write-Behind的最大特点。
数据库写操作可以用不同的方式完成,其中一个方式就是收集所有的写操作并在某一时间点(比如数据库负载低的时候)批量写入。另一种方式就是合并几个写操作成为一个小批次操作,接着缓存收集写操作一起批量写入。
异步写操作极大地降低请求延迟并减轻数据库的负担。同时也放大数据不一致的。比如有人此时直接从数据库中查询数据,但是更新的数据还未被写入数据库,此时查询到的数据就不是最新的数据。
缓存分类
- 本地缓存和远程缓存
本地缓存
也叫进程缓存,实现技术:
- guava cache
- ehcache
- Caffeine
远程缓存
也叫分布式缓存,实现技术:
- redis
- memcache
缓存问题
缓存颠簸
也叫缓存抖动,一般是由于缓存节点故障导致,一致性Hash算法。
缓存雪崩
产生原因:高并发请求,缓存在同一时间大量失效,查db进而打垮db。
解决方案:
- 过期时间加随机值;
- 如果Redis是集群部署,将热点数据均匀分布在不同的Redis库中也能避免全部失效。
- 设置热点数据永不过期
缓存击穿
产生原因:超级热点Key,扛着大量的请求,当Key在失效的瞬间,大并发直接落到数据库上,发生Key值的缓存击穿。和缓存雪崩的区别在于这里针对某一key缓存,前者则是很多key。
解决方案:
- 设置热点数据永不过期
- 加上互斥锁:在根据key获得的value值为空时,先锁上,再从数据库加载,加载完毕,释放锁。若其他线程发现获取锁失败,则睡眠50ms后重试。
- 布隆过滤器:BloomFilter能够迅速判断一个元素是否在一个集合中。
缓存穿透
产生原因:查询缓存中必定不存在的数据,缓存查询cache_miss,导致查询走到db层,流量大可能导致db挂掉。
解决方案:
- 在接口层增加校验:用户鉴权,参数做校验,不合法的校验直接 return
- 布隆过滤器(Bloom Filter),利用高效的数据结构和算法快速判断出这个 Key 是否在数据库中存在,不存在则return
- 后台定时任务job,读数据库,写更新到缓存。这种方案比较容易理解,但会增加系统复杂度。比较适合那些key相对固定、cache粒度较大的业务,key比较分散的则不太适合,实现也比较复杂
总结
缓存穿透和缓存击穿,很相似,都是缓存未命中。击穿是刚好key失效,穿透是key不存在。
上面三种问题的通用解决方案:
- 直接缓存NULL值
- 限流、降级、熔断
- 缓存预热
- 分级缓存,多级缓存
- 缓存永远不过期
其他
Buffer & Cache
非常容易混用的概念。
Buffer,缓冲,缓和冲击
Cache,缓存/快取,加快取用的速度
硬盘的读写缓冲/缓存名称是不一样的,write-buffer和read-cache。
一般都是读写混用,CPU里的L2和L3 Cache也都是读写兼用。当然也有读buffer
拿cache做buffer用呢?只要能控制cache淘汰逻辑就没有任何问题。
拿buffer做cache用呢?在很特殊的情况下,能确定访问顺序的时候,也是可以的,但是比较局限


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix