

《Offer来了:Java面试核心知识点精讲(框架篇)》读书笔记
第1章 Spring原理及应用
第2章 Spring Cloud原理及应用
第3章 Netty网络编程原理及应用
第4章 ZooKeeper原理及应用
角色
zab协议
第5章 Kafka原理及应用
第6章 Hadoop原理及应用
第7章 HBase原理及应用
第8章 Cassandra原理及应用
特点
Cassandra的特点包括基于列式存储、P2P去中心化设计、可扩展、多数据中心识别和异地容灾、二级索引、支持分布式写操作:
- 基于列式存储:Cassandra和HBase一样,都是基于列式存储的数据库,由于查询中的选择规则是通过列来定义的,因此整个数据库是自动索引的,查询效率很高
- P2P去中心化设计:Cassandra采用的是P2P去中心化的设计思想,在整个集群中没有主节点,因此不存在主节点宕机则集群不可用的问题,也不存在主节点性能瓶颈,Cassandra会自动将数据和请求均衡地分配到每个节点上
- 可扩展:Cassandra是完全水平扩展的。当需要给集群添加更多容量时,动态增加节点即可,Cassandra内部会自动做数据迁移,因此不必重启任何进程或手动迁移任何数据
- 多数据中心识别和异地容灾:Cassandra支持机架和数据中心的识别,当需要做异地容灾的时候,只需要将数据库配置设置为不同的数据中心即可,Cassandra会保障每个数据中心都有全量数据。因此,当主数据中心宕机时,备数据中心能够完全支持业务请求。同时,当由于地震、火灾等不可抗因素导致主数据中心丢失时,可以基于备数据中心很快地在主数据中心重建集群并完成数据的自动恢复
- 二级索引:除支持键值查询和根据键的范围查询,Cassandra还支持二级索引,在二级索引上可以方便地进行Group By和Count操作
- 支持分布式写操作:P2P架构设计,用户可以在任何地方任何时间集中读或写任何数据,不用担心单点失败的问题
数据模型
由Key Space、Column Family、Key和Column组成:
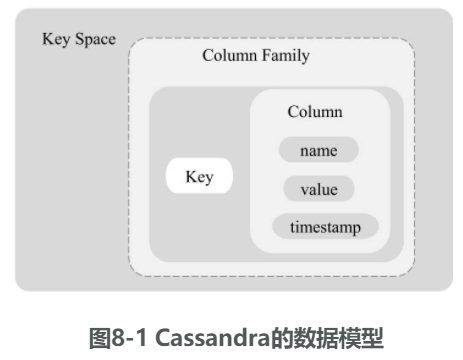
- Key Space
一个Key Space可包含若干Column Family。创建Key Space需设置的核心参数包括复制因子和副本存储策略。复制因子是集群中同一个数据的副本数。副本存储策略指把副本以何种策略分布在集群的服务器上。副本存储策略有简单策略(单数据中心存储策略)、旧网络拓扑策略(机架感知策略)和网络拓扑策略(数据中心共享策略)。KeySpace的创建命令:
CREATE KEYSPACE Keyspace loginlog WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 3}; - Key
在Cassandra中,每一行数据记录都是以Key-Value的形式存储的,其中Key是唯一标识。 - Column
Column与关系型数据库中的列类似。在Cassandra中,每个Key-Value中的Value又称为Column,是Cassandra中最小的数据单元。它是一个三元的数据类型,包含name、value和timestamp。name和value都是byte[]类型的,长度不限。 - Super Column
Super Column允许Key-Value中的Value是一个Map<Key,Value List>,Super Column中的Column可以有多个子列 - Column Family
一个包含许多Row的结构,与RDBMS中的Table类似。每个Row都包含为Client提供的Key及与该Key关联的一系列Column。Column Family的类型可以是Standard/Super Column Family类型 - Standard Column Family
与关系型数据库中的Table类似,每个Column Family都由一系列Row组成,每个Row都包含一个Key及其对应的若干Columns,Columns是Column类型。 - Super Column Family
每个Super Column Family都由一系列Row组成,每个Row都包含一个Key及其对应的若干SuperColumn。
Gossip协议
反熵(Anti-Entropy),不要求节点知道所有其他节点的状态,去中心化,各节点之间的角色完全对等,集群不需要中心节点,常用于能接受最终一致性的领域,如失败检测、路由同步、发布订阅、动态负载均衡等。
在A、B两个节点之间存在3种通信方式:pull、push、pull & push。
收敛性:指Gossip协议中的消息以指数级的速度在网络中快速传播,所有状态的不一致都可以在很短的时间内收敛到一致,收敛速度为logn。Pull/Push通信方式最快,其收敛速度也最快。
问题:
多数据中心,即数据分区。
解决:
Cassandra在集群的所有节点中都使用相同的Seed List(描述集群中有多少个节点)指定,种子节点配置集群的Seed List,其他节点在启动时首先和种子节点相互通信交换集群的信息,防止数据分区问题,保障新加入的节点快速学习到整个集群的信息。
NWR理论
- N(Number):在分布式存储系统中,有N份备份数据
- W(Write):在一次成功的更新操作中要求至少有W份数据被成功写入
- R(Read):在一次成功的读数据操作中要求至少有R份数据被成功读取
NWR的不同组合会产生不同的一致性效果,当W+R>N时,整个系统对于客户端来讲都能保证强一致性;R+W<=N,则无法保证数据的强一致性
一致性Hash
数据副本策略
数据存储
数据写入
数据读取
数据删除机制
删除数据时,只是插入一个关于这个数据的删除墓碑(Tombstone),并不直接删除原有的数据。该墓碑被作为对该数据的一次修改记录。在MemTable和SSTable中,墓碑的内容是执行删除请求的时间。当客户端再次查询被删除的数据时,Cassandra找到并发现该数据已被标记为删除,则认为该数据已经被删除,返回客户端的查询结果将为空。被删除的数据并不会立刻被从磁盘中删除,短时间内会占用磁盘空间;Major Compaction,垃圾回收机制定期删除被标记墓碑的数据。
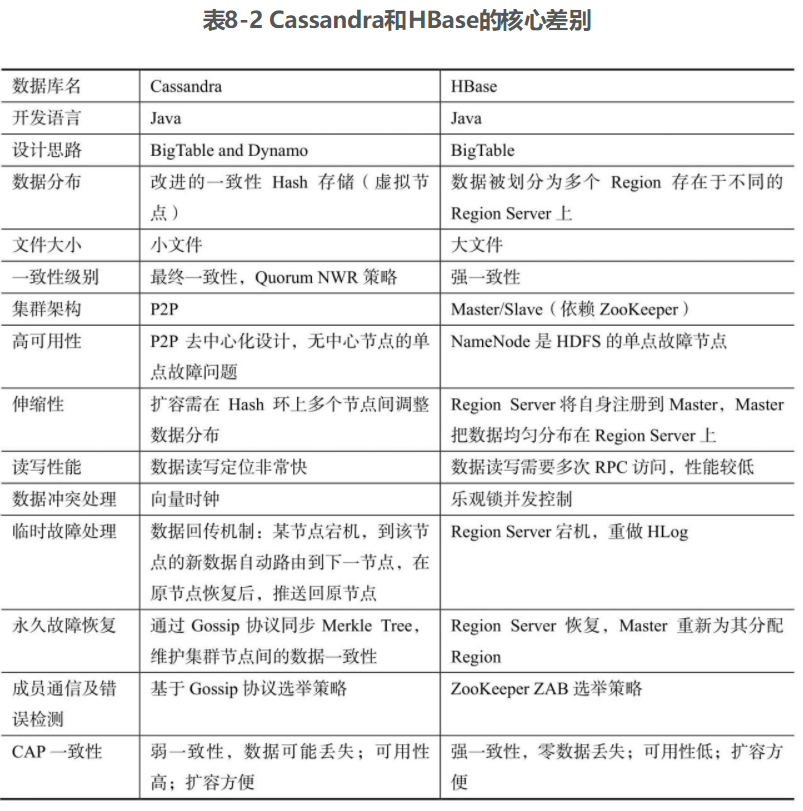
和HBase的对比
安装,略
Spring Boot集成Cassandra,简单,略
spring-boot-starterdata-cassandra是SpringBoot针对Spring在cassandra-driver-core的基础上对Cassandra客户端操作的二次封装
第9章 ElasticSearch原理及应用
第10章 Spark原理及应用
第11章 Flink原理及应用
Flink将数据抽象为有界数据流和无界数据流。
核心概念
- Flink Cluster:集群是用于运行Flink应用程序的分布式系统,一个Flink集群由ZooKeeper、JobManager和Task Manager 3个角色组成。高可用模式下,一般ZooKeeper为至少3个节点的集群;Job Manager为至少2个节点的集群,Job Manager高可用模式为一主多备。在正常情况下,主节点提供服务,当主节点宕机时,一个备节点会升级为主节点对外提供服务。Task Manager为具体的计算节点,一个集群中有一个或多个Task Manager。
- Flink Master,指集群的管理节点,一个Flink Master由Flink Resource Manager(资源管理)、FlinkDispatcher(分发)和Flink Job Manager 3个角色组成。
- Flink Job Manager:Flink的任务管理节点,用于任务的提交、分发和运行状态的监控。一个集群可以有一个或多个(高可用模式下)Job Manager。
- Flink Task Manager:Flink集群的计算节点,Flink的任务被Job Manager调度在多个TaskManager上执行。多个Task Manager上的Task相互交换计算结果以完成数据流的计算。
- Job:指一个运行中的Flink应用程序,Job可通过Job Manager以命令行的方式提交到集群,或Flink监控页面提交到集群。
- Flink Graph:图,指Flink流式计算程序所组成的数据流程图。分Logical Graph和Physical Graph。前者描述是应用程序(通常指基于Java或者Scala实现的Flink程序)定义的数据流之间的逻辑关系,与之对应的是逻辑上的Operator(算子)、Input、Output、DataStream和DataSet。后者是Logical Graph基于分布式运行环境转换后物理上的计算逻辑图,与之对应的是物理计算上的Task、Input、Output、DataStream和DataSet。
- Flink Operator和Operator Chain:Flink Operator是Flink Logical Graph中的一个节点,用于执行一个Flink Function。一个完整的数据流通常包含一个Source Operator(数据摄取)、Process Function(数据计算)和Sink Operator(数据输出)。多个相邻Operator相互连接组成一个Operator Chain,在一个Operator Chain内部,Operator的数据可以相互直接访问,不需要经过Flink集群的序列化和网络传输。
- Flink Task和SubTask:Flink Task是Physical Graph的一个节点,对应物理上的一个计算单元,一个Task由多个SubTask组成,每个SubTask都对应数据流上的一个处理函数。
- Event:指Flink运行时数据模型的状态变化,Event在流式计算和批量计算接口中被输入、输出以完成状态的记录和传递。
- Function:由应用程序实现的逻辑计算单元,Function一般通过实现Flink的Function接口或继承Function类来定义。常用的Function有MapFunction、ReduceFunction、ProcessFunction、RichFunction等。
- Flink Record:指数据流中的元素。
- Flink State Backend:定义Task Manager上运行的Job的状态存储方式(如JVM堆内存存储、RocksDB、FileSystem),SavePoint和CheckPoint的存储规则和存储方式。
框架
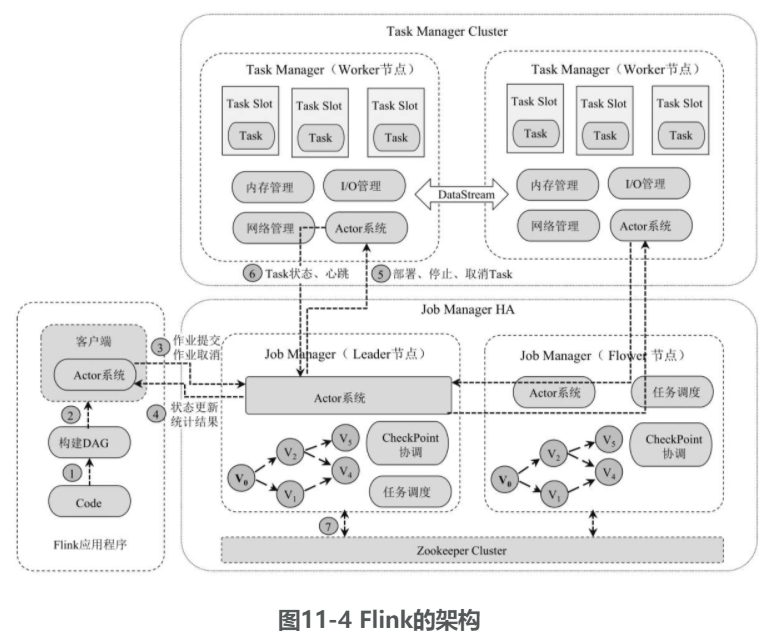
Flink由Job Manager、Task Manager和客户端组成。Job Manager是管理节点,负责集群任务的提交、分配和资源管理;Task Manager是具体执行任务的计算节点;客户端用于作业的提交。
- Job Manager的职责
Job Manager负责协调分布式计算节点,也被称为Master节点。它负责调度任务、协调CheckPoint、故障恢复等。Job Manager将一个作业分为多个Task,并通过Actor系统与TaskManager进行相互通信,用于Task的部署、停止、取消。在高可用部署下会有多个Job Manager,其中有一个Leader、多个Flower。Leader总是处于Active状态,为集群提供服务;Flower处于Standby状态,在Leader宕机后会从Flower中选出一个作为Leader继续为集群提供服务。Job Manager选举通过ZooKeeper实现。 - Task Manager的职责
Task Manager也被称为Worker节点,用于执行Job Manager分配的Task(SubTask)。Task Manager将系统资源(CPU、网络、内存)分为多个Task Slot(计算槽),Task运行在具体的Task Slot上,Task Manager通过Actor系统与Job Manager进行相互通信,定期将Task的运行状态和Task Manager的运行状态提交给Job Manager。多个Task Manager上的Task通过DataStream进行状态计算和结果交互。 - 客户端
客户端不是运行时环境的一部分,它主要用于提交作业给Job Manager。在作业提交完成后,客户端可以断开连接,也可以保持连接来接收作业的运行状态。 - 应用程序的运行流程
- 编写应用程序数据流作业,可以基于Java或者Scala
- 构建DAG和优化流程
- 通过客户端命令提交作业到集群的Job Manager Leader节点
- Job Manager将任务提交的结果和运行状态反馈给客户端
- Job Manager根据每个Task Manager上资源的使用情况,将作业拆分为多个Task,并通过Actor系统将Task部署到具体的Task Manager节点上
- Task Manager在Task Slot上运行Task,并定时将Task Manager的运行状态和Task的运行状态发送给Job Manager,Job Manager根据Task Manager上资源的使用情况和Task的运行状态对集群进行调度
- Job Manager和ZooKeeper进行交互,以完成Job Manager的选举和故障恢复
- Task Slot资源分配
- 任务和算子
- 状态存储
- 运行模式

事件驱动模型
定义
事件驱动模型是基于事件流的有状态的计算模型。它接收源源不断的事件,并根据事件的不同类型更新不同状态来触发不同计算。事件驱动模型和一般的计算存储分离模型的最大差别在于,计算存储分离模型需要将数据存储在远程对象存储系统(如S3、OSS、OBS)、事务型/关系型数据库、分布式内存系统(LeverDB)中。即计算存储分离模型的所有数据计算都基于本地内存和磁盘,而数据均被存储在远程存储系统中,好处是计算和存储分离,以便计算和存储可以各自扩展而相互不影响。计算存储分离模型的架构
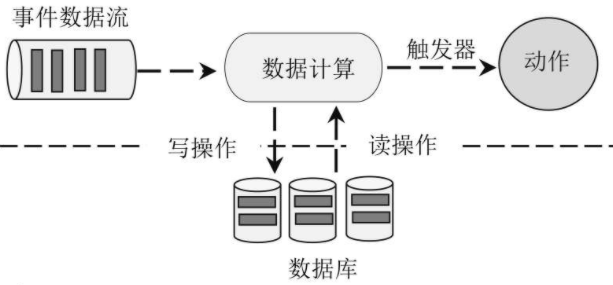
事件驱动模型是基于状态化流处理完成的,它并未将计算和存储分离,而是在计算过程中通过访问本地存储(操作系统内存或磁盘)获取数据以便尽可能快地完成计算。事件驱动模型系统通过定期向远程持久化存储写入CheckPoint和SavePoint来实现状态回滚、故障恢复和程序升级,架构如图:
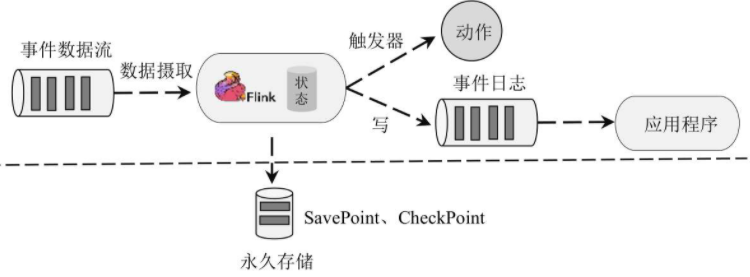
特点
事情驱动模型的特点是高效。事件驱动模型由于不需要频繁访问远程数据,大部分数据操作在本地内存中完成,少部分数据操作在磁盘上完成,因此具有更高的吞吐量和更低的延迟。同时,事件驱动模型会定期增量地将数据处理的状态以CheckPoint的形式存储在远程持久化存储中,以便程序状态回滚和故障恢复。
Flink的事件驱动模型的特点
Flink底层基于有状态的事件数据处理而设计,提供丰富的状态操作,及Exactly-Once数据一致性保障和海量规模(至少TB级)的状态数据计算。且Flink提供多种窗口计算,灵活性极高。
数据分析应用
数据清洗和数据管道
数据流处理基本概念
以数据流、状态(State)、时间(Time)3个核心组件为基础构建整个框架。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2018-03-12 Java 枚举总结