Hive系列之开窗函数
概述
部分关系型数据库支持开窗函数,大数据查询引擎Hive,想当然也支持。前置学习资料SQL开窗函数。
入门
基本语法:
Function (arg1,..., argn) OVER ([PARTITION BY <...>] [ORDER BY <....>] [<window_expression>])
Function (arg1,..., argn)可以是下面的函数:
- Aggregate Functions:聚合函数,如:
sum(),max(),min(),avg()等 - Sort Functions:数据排序函数,比如:
rank(),row_number()等 - Analytics Functions:统计和比较函数,如:
lead(),lag(),first_value()等
CREATE TABLE IF NOT EXISTS employee (
name string comment '职工姓名',
dept_num int comment '部门编号',
employee_id int comment '职工ID',
salary int comment '工资',
type string comment '岗位类型',
start_date date comment '入职时间'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '|'
STORED as TEXTFILE;
加载数据:load data local inpath '/opt/data/employee.txt' into table employee;
窗口聚合函数
示例:
- 查询姓名、部门编号、工资以及每个部门的总工资,部门总工资按照降序输出
select
name ,
dept_num as deptno,
salary,
sum(salary) over (partition by dept_num order by dept_num) as sum_dept_salary
from employee
order by sum_dept_salary desc;
窗口排序函数
窗口排序函数提供数据的排序信息,比如行号和排名。在一个分组的内部将行号或者排名作为数据的一部分进行返回,最常用的排序函数:
row_number
根据具体的分组和排序,为每行数据生成一个起始值等于1的唯一序列数;应用场景:获取分组内排序TopN的记录、获取一个session中的第一条refer等- rank
对组中的数据进行排名,如果名次相同,则排名也相同,但是下一个名次的排名序号会出现不连续。比如查找具体条件的topN行 dense_rank
功能与rank函数类似,dense_rank函数在生成序号时是连续的,而rank函数生成的序号有可能不连续。当出现名次相同时,则排名序号也相同。而下一个排名的序号与上一个排名序号是连续的。percent_rank
排名计算公式为:(current rank - 1)/(total number of rows - 1)- ntile
将一个有序的数据集划分为多个桶(bucket),并为每行分配一个适当的桶数。它可用于将数据划分为相等的小切片,为每一行分配该小切片的数字序号。
案例
- 查询姓名、部门编号、工资、排名编号(按工资的多少排名)
select
name ,
dept_num as dept_no ,
salary,
row_number() over (order by salary desc ) rnum
from employee;
- 查询每个部门工资最高的两个人的信息(姓名、部门、薪水)
select
name,
dept_num,
salary
from
(
select name ,
dept_num ,
salary,
row_number() over (partition by dept_num order by salary desc ) rnum
from employee) t1
where rnum <= 2;
- 查询每个部门的员工工资排名信息
select
name ,
dept_num as dept_no ,
salary,row_number() over (partition by dept_num order by salary desc ) rnum
from employee;
- 使用rank、dense_rank、percent_rank函数进行排名
select
name,
dept_num,
salary,
rank() over (order by salary desc) rank
from employee;
- 使用ntile进行数据分片排名
SELECT
name,
dept_num as deptno,
salary,
ntile(4) OVER(ORDER BY salary desc) as ntile
FROM employee;
从Hive v2.1.0开始支持在OVER语句里使用聚集函数:
SELECT
dept_num,
row_number() OVER (PARTITION BY dept_num ORDER BY sum(salary)) as rk
FROM employee
GROUP BY dept_num;
窗口分析函数
常用的分析函数主要包括:
cume_dist
如果按升序排列,则统计:小于等于当前值的行数/总行数(number of rows ≤ current row)/(total number of rows)。如果是降序排列,则统计:大于等于当前值的行数/总行数。比如,统计小于等于当前工资的人数占总人数的比例 ,用于累计统计lead(value_expr[,offset[,default]])
用于统计窗口内往下第n行值。第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULLlag(value_expr[,offset[,default]])
与lead相反,用于统计窗口内往上第n行值。第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULLfirst_value
取分组内排序后,截止到当前行,第一个值last_value
取分组内排序后,截止到当前行,最后一个值,默认窗口是RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW,表示当前行永远是最后一个值。
实例:
- 统计小于等于当前工资的人数占总人数的比例,
order by desc即为大于等于:
SELECT
name,
dept_num as deptno,
salary,
cume_dist() OVER (ORDER BY salary) as cume
FROM employee;
- 按照部门统计小于等于当前工资的人数占部门总人数的比例
SELECT
name,
dept_num as deptno,
salary,
cume_dist() OVER (PARTITION BY dept_num ORDER BY salary) as cume
FROM employee;
LAG(col,n,DEFAULT)用于统计窗口内往上第n行值,第一个参数为列名,第二个参数为往上第n行(默认为1),第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL)
LEAD(col,n,DEFAULT)用于统计窗口内往下第n行值,第一个参数为列名,第二个参数为往下第n行(默认为1),第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL)
GROUPING SETS:在一个GROUP BY查询中,根据不同的维度组合进行聚合,等价于将不同维度的GROUP BY结果集进行UNION ALL
GROUPING__ID,表示结果属于哪一个分组集合
CUBE:根据GROUP BY的维度的所有组合进行聚合。
ROLLUP:是CUBE的子集,以最左侧的维度为主,从该维度进行层级聚合。
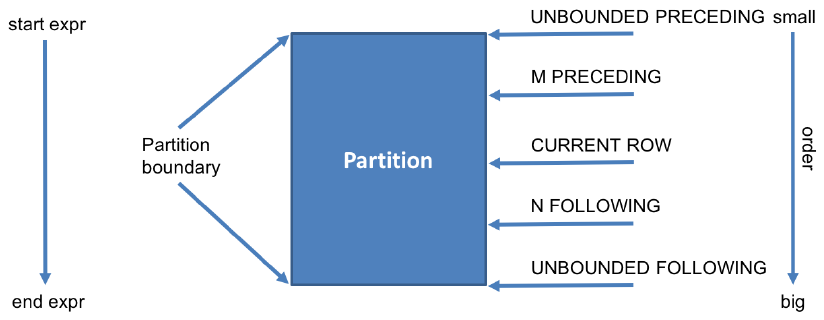
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
为默认值,即当指定ORDER BY从句,而省略window从句 ,表示从开始到当前行。
RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING
表示从当前行到最后一行
RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
表示所有行
n PRECEDING m FOLLOWING
表示窗口的范围是:[(当前行的行数)- n, (当前行的行数)+m] row.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号