

MySQL分区Partition
概述
随着MySQL单表的数据量越来越大,即使有加索引,查询速度也会越来越慢。如果历史数据无用,可以使用硬删除,但即使把这些数据删除,但底层的数据文件并没有变小。面对这类问题,最有效的方法就是在使用分区表。最常见就是按照时间进行分区,可以非常高效的进行历史数据的清理。
MySQL有一种早期的简单的分区实现 - 合并表(merge table),限制较多且缺乏优化,不建议使用,应该用新的分区机制来替代。
InnoDB逻辑存储结构
InnoDB逻辑存储结构和区的概念,它的所有数据都被逻辑地存放在表空间,表空间又由段,区,页组成。
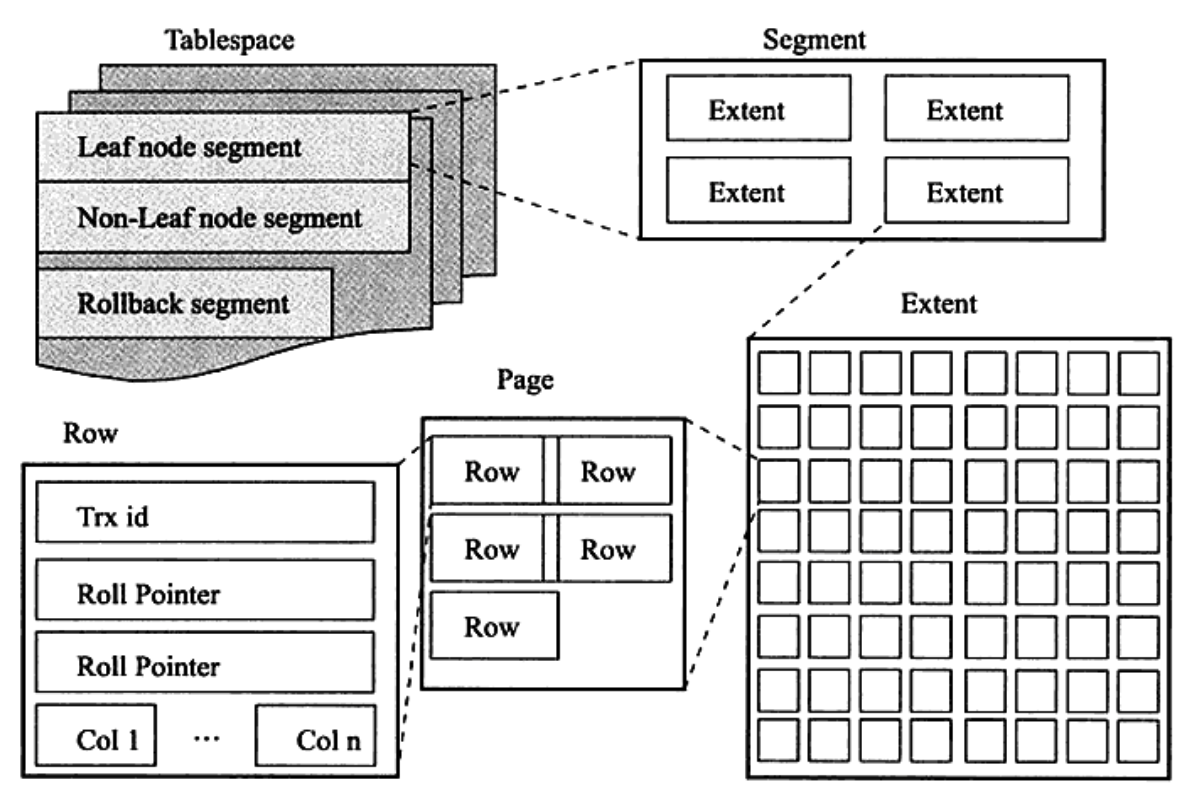
段
段就是segment区域,常见的段有数据段、索引段、回滚段等,在InnoDB存储引擎中,对段的管理都是由引擎自身所完成的。
区
区就是extent区域,区是由连续的页组成的空间,无论页的大小怎么变,区的大小默认总是为1MB。
为了保证区中的页的连续性,InnoDB存储引擎一次从磁盘申请4-5个区,InnoDB页的大小默认为16kb,即一个区一共有64(1MB/16kb=16)个连续的页。
每个段开始,先用32页(page)大小的碎片页来存放数据,在使用完这些页之后才是64个连续页的申请。这样做的目的是,对于一些小表或者是undo类的段,可以开始申请较小的空间,节约磁盘开销。
页
页就是page区域,也可以叫块。页是InnoDB磁盘管理的最小单位。默认大小为16KB,可以通过参数innodb_page_size来设置。
常见的页类型有:数据页,undo页,系统页,事务数据页,插入缓冲位图页,插入缓冲空闲列表页,未压缩的二进制大对象页,压缩的二进制大对象页等。
介绍
MySQL在5.1时添加对水平分区的支持,用户需要在建表的时候加上分区参数,对应用是透明的无需修改代码。分区,指将同一表中不同行的记录分配到不同的物理文件中,几个分区就有几个.idb文件。分区将一个表或索引分解成多个更小,更可管理的部分。每个区都是独立的,可以独立处理,也可以作为一个更大对象的一部分进行处理。
MySQL是面向OLTP的数据库。那么对于分区的使用应该非常小心,如果不清楚如何使用分区可能会对性能产生负面的影响。
MySQL数据库的分区是局部分区索引,一个分区中既存数据,又放索引。也就是说,每个区的聚集索引和非聚集索引都放在各自区的(不同的物理文件)。目前MySQL数据库还不支持全局分区。
无论哪种类型的分区,如果表中存在主键或唯一索引时,分区列必须是唯一索引的一个组成部分。
数据库分区是一种物理数据库设计技术。其主要目的是为了在特定的SQL操作中减少数据读写的总量以缩减SQL语句响应时间,同时对于应用来说分区完全是透明的。
数据库性能的提升和简化数据管理,在扫描操作中MySQL优化器只扫描数据的那个分区以减少扫描范围获得性能的提高。分区技术使得数据管理变得简单,删除某个分区不会对另外的分区造成影响。同个表中的分区表名称要唯一。
可用show variables like '%parts%'命令查询当前的MySQL数据库版本是否支持分区:
innodb_adaptive_hash_index_parts,8
数据库应用分为2类,一类是OLTP(在线事务处理),一类是OLAP(在线分析处理)。
- 对于OLAP应用,分区的确可以很好的提高查询性能,因为一般分析都需要返回大量的数据。如果按时间分区,比如一个月用户行为等数据,则只需扫描响应的分区即可。
- 在OLTP应用中,分区更加要小心,通常不会获取一张大表的10%的数据,大部分是通过索引返回几条数据即可。如果1000w的B+树的高度是3,现在有10个分区。那么不是要(3+3)*10次的逻辑IO?(3次聚集索引,3次辅助索引,10个分区)。所以在OLTP应用中请小心使用分区表
分区形式
主要有两种形式
- 水平分区
这种形式的分区是根据表的行进行分区,通过这样的方式不同分组里面的物理列分割的数据集得以组合,从而进行个体分割(单分区)或集体分割(1个或多个分区)。所有在表中定义的列在每个数据集中都能找到,所以表的特性依然得以保持。水平分区一定要通过某个属性列来分割。常见的比如年份,日期等。 - 垂直分区(Vertical Partitioning)
这种分区方式一般来说是通过对表的垂直划分来减少目标表的宽度,使某些特定的列被划分到特定的分区,每个分区都包含其中的列所对应所有行。
类型
目前MySQL支持范围分区(RANGE),列表分区(LIST),哈希分区(HASH)以及KEY分区四种,当然通过组合还有复合分区:基于RANGE/LIST类型的分区表中每个分区的再次分割。子分区可以是 HASH/KEY等类型。
RANGE分区
基于属于一个给定连续区间的列值,把多行分配给分区。最常见的是基于时间字段,基于分区的列最好是整型,如果日期型的可以使用函数转换为整型,如to_days函数:
CREATE TABLE my_range_datetime (
id INT,
hiredate DATETIME
)
PARTITION BY RANGE (TO_DAYS(hiredate) ) (
PARTITION p1 VALUES LESS THAN (TO_DAYS('20210110') ),
PARTITION p2 VALUES LESS THAN (TO_DAYS('20210111') ),
PARTITION p3 VALUES LESS THAN (MAXVALUE)
);
p3是一个默认分区,所有大于20210111的记录都会在这个分区。MAXVALUE是一个无穷大的值。p3是一个可选分区。如果在定义表时没有指定这个分区,当插入大于20210111的数据时会收到一个错误。在执行查询时,必须带上分区字段,使用分区剪裁功能
在5.7版本之前,对于DATA和DATETIME类型的列,如果要实现分区裁剪,只能使用YEAR() 和TO_DAYS()函数,在5.7版本中新增TO_SECONDS()函数。
如果是timestamp类型呢?
LIST分区
LIST分区和RANGE分区类似,区别在于LIST是枚举值列表的集合,RANGE是连续的区间值的集合。二者在语法方面非常的相似。同样建议LIST分区列是非null列,否则插入null值如果枚举列表里面不存在null值会插入失败,这点和其它的分区不一样,RANGE分区会将其作为最小分区值存储,HASH\KEY分为会将其转换成0存储,主要LIST分区只支持整形,非整形字段需要通过函数转换成整形。
Hash
在实际工作中经常遇到像会员表的这种表。并没有明显可以分区的特征字段,但表数据有非常庞大。为了把这类的数据进行分区打散MySQL提供hash分区。基于给定的分区个数,将数据分配到不同的分区,HASH分区只能针对整数进行HASH,对于非整形的字段只能通过表达式将其转换成整数。表达式可以是MySQL中任意有效的函数或者表达式,对于非整形的HASH往表插入数据的过程中会多一步表达式的计算操作,所以不建议使用复杂的表达式这样会影响性能。
Hash分区表的基本语句如下:
CREATE TABLE my_member (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
created DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY HASH(id)
PARTITIONS 4;
注意:
- HASH分区可以不用指定PARTITIONS子句,如上文中的PARTITIONS 4,则默认分区数为1。
- 不允许只写PARTITIONS,而不指定分区数。
- 同RANGE分区和LIST分区一样,
PARTITION BY HASH (expr)子句中的expr返回的必须是整数值。 - HASH分区的底层实现其实是基于MOD函数。譬如,对于下表
CREATE TABLE t1 (col1 INT, col2 CHAR(5), col3 DATE) PARTITION BY HASH( YEAR(col3) ) PARTITIONS 4;如果你要插入一个col3为“2017-09-15”的记录,则分区的选择是根据以下值决定的:MOD(YEAR(‘2017-09-01’),4) = MOD(2017,4) = 1
LINEAR HASH
LINEAR HASH分区是HASH分区的一种特殊类型,HASH分区基于MOD函数,它基于的是另外一种算法。
格式:
CREATE TABLE my_members (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY LINEAR HASH( id )
PARTITIONS 4;
优点:在数据量大的场景,譬如TB级,增加、删除、合并和拆分分区会更快;
缺点:相对于HASH分区,它数据分布不均匀的概率更大。
KEY
KEY分区其实跟HASH分区差不多,不同点如下:
- KEY分区允许多列,而HASH分区只允许一列。
- 如果在有主键或者唯一键的情况下,key中分区列可不指定,默认为主键或者唯一键,如果没有,则必须显性指定列。
- KEY分区对象必须为列,而不能是基于列的表达式。
- KEY分区和HASH分区的算法不一样,PARTITION BY HASH (expr),MOD取值的对象是expr返回的值,而PARTITION BY KEY (column_list),基于的是列的MD5值。
格式如下:
CREATE TABLE k1 (
id INT NOT NULL PRIMARY KEY,
name VARCHAR(20)
)
PARTITION BY KEY()
PARTITIONS 2;
在没有主键或者唯一键的情况下,格式如下:
CREATE TABLE tm1 (
s1 CHAR(32)
)
PARTITION BY KEY(s1)
PARTITIONS 10;
总结:
- MySQL分区中如果存在主键或唯一键,则分区列必须包含在其中
- 对于原生的RANGE分区,LIST分区,HASH分区,分区对象返回的只能是整数值
- 分区字段不能为NULL
分区操作
创建
创建range分区
CREATE TABLE cxy7_product (
id BIGINT NOT NULL,
NAME VARCHAR (20),
price INT
) PARTITION BY RANGE (price)(
PARTITION less_1000 -- 小于 1000
VALUES
less than (1000),
PARTITION b_1000_2000 -- 1000~2000
VALUES
less than (2000),
PARTITION greater_2000 -- >2000
VALUES
less than MAXVALUE
);
以价格为依据做范围分区,表达式必须有返回值。
创建list分区
CREATE TABLE cxy7_book (
id BIGINT NOT NULL,
NAME VARCHAR (20),
category INT
) PARTITION BY LIST (category)(
PARTITION edu
VALUES
IN (1, 3),
PARTITION com
VALUES
IN (2, 4)
);
以分类作为分区依据,每个分类做一分区。
创建hash分区
HASH分区主要用来确保数据在预先确定数目的分区中平均分布。在RANGE和LIST分区中,必须明确指定一个给定的列值或列值集合应该保存在哪个分区中;而在HASH分区中,MySQL自动完成这些工作,你所要做的只是为将要被哈希的列值指定一个列值或表达式,以及指定被分区的表将要被分割成的分区数量。
CREATE TABLE cxy7_order (
id BIGINT NOT NULL,
NAME VARCHAR (20),
create_date date NOT NULL
) PARTITION BY HASH (YEAR(create_date))
创建key分区
按照KEY进行分区类似于按照HASH分区,除了HASH分区使用的用户定义的表达式,而KEY分区的哈希函数是由MySQL服务器提供。KEY分区只采用一个或多个列名。
CREATE TABLE cxy7_user (
id BIGINT NOT NULL,
NAME VARCHAR (20),
birthday date NOT NULL
) PARTITION BY KEY (birthday)
创建复合分区
- range - hash(范围哈希)复合分区
CREATE TABLE cxy7_sales (
user_id INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
prod_id BIGINT NOT NULL,
num INT NOT NULL
) PARTITION BY RANGE (user_id) SUBPARTITION BY HASH (user_id % 2) SUBPARTITIONS 2 (
PARTITION less_1000
VALUES
LESS THAN (1000),
PARTITION greater_1000
VALUES
LESS THAN MAXVALUE
)
- range- key复合分区
CREATE TABLE cxy7_user_1 (
id BIGINT NOT NULL,
NAME VARCHAR (20),
birthday date NOT NULL
) PARTITION BY RANGE (id) subpartition BY KEY (birthday) SUBPARTITIONS 2 (
PARTITION less_1000
VALUES
LESS THAN (1000),
PARTITION greater_1000
VALUES
LESS THAN MAXVALUE
)
- list-hash复合分区
CREATE TABLE cxy7_user_2 (
id BIGINT NOT NULL,
dep_no BIGINT NOT NULL,
NAME VARCHAR (20),
birthday date NOT NULL
) PARTITION BY list (dep_no) subpartition BY HASH (YEAR(birthday)) subpartitions 2 (
PARTITION p1
VALUES
IN (10),
PARTITION p2
VALUES
IN (20)
);
- list - key 复合分区
CREATE TABLE cxy7_user_3 (
id BIGINT NOT NULL,
dep_no BIGINT NOT NULL,
NAME VARCHAR (20),
birthday date NOT NULL
) PARTITION BY list (dep_no) subpartition BY KEY (birthday) subpartitions 2 (
PARTITION p1 VALUES IN (10),
PARTITION p2 VALUES IN (20)
);
查看
方式有很多:
SHOW CREATE TABLE cxy7_user_3;SHOW TABLE STATUS LIKE '%cxy7_user_3%';- 查看
information_schema.partitions表:
SELECT
partition_name part,
partition_expression expr,
partition_description descr,
table_rows
FROM
information_schema.PARTITIONS
WHERE
table_schema = SCHEMA ()
AND table_name = 'cxy7_user_2';
explain partitions select * FROM cxy7_user_2;
增加
ALTER TABLE cxy7_book ADD PARTITION (
PARTITION less_4000 VALUES IN (5, 6)
);
拆分
reorganize partition关键字可以对表的部分分区或全部分区进行修改,并且不会丢失数据。分解前后分区的整体范围应该一致。
ALTER TABLE cxy7_book REORGANIZE PARTITION edu INTO (
PARTITION edu_1 VALUES IN (1),
PARTITION edu_3 VALUES IN (3)
);
删除
不可以删除hash或者key分区:
ALTER TABLE cxy7_user_3 DROP PARTITION p1;
ALTER TABLE cxy7_user_3 DROP PARTITION p1, p2; #一次性删除多个分区
删除表的所有分区:
ALTER TABLE cxy7_user_2 REMOVE PARTITIONING;
合并
ALTER TABLE cxy7_book REORGANIZE PARTITION edu_1, edu_3 INTO (PARTITION edu VALUES IN(1, 3));
重新定义分区表
ALTER TABLE cxy7_order PARTITION BY HASH (id) PARTITIONS 10;
一个表,可以有多种分区方式和分区键,互不影响?
重建分区
这和先删除保存在分区中的所有记录,然后重新插入它们,具有同样的效果。它可用于整理分区碎片。
ALTER TABLE cxy7_user_3 optimize partition p2;
分析分区
优化分区
如果从分区中删除大量的行,或对一个带有可变长度的行(即有VARCHAR,BLOB,或TEXT类型的列)作许多修改,可使用"ALTER TABLE ... OPTIMIZE PARTITION"来收回没有使用的空间,并整理分区数据文件的碎片:ALTER TABLE cxy7_user_3 ANALYZE PARTITION p2;
分析分区
读取并保存分区的键分布:ALTER TABLE cxy7_user_3 ANALYZE PARTITION p2;
修补分区
修补被破坏的分区:ALTER TABLE cxy7_user_3 REPAIR PARTITION p2;
检查分区
可以使用几乎与对非分区表使用CHECK TABLE 相同的方式检查分区:ALTER TABLE cxy7_user_3 CHECK PARTITION p2;,返回表的分区p2中的数据或索引是否已经被破坏。如果损坏,可使用"ALTER TABLE ... REPAIR PARTITION"来修补分区。
优势与局限
好处:
- 可以让单表存储更多的数据
- 分区表的数据更容易维护,可以通过清楚整个分区批量删除大量数据,也可以增加新的分区来支持新插入的数据。另外,还可以对一个独立分区进行优化、检查、修复等操作
- 部分查询能够从查询条件确定只落在少数分区上,速度会很快
- 分区表的数据还可以分布在不同的物理设备上,从而搞笑利用多个硬件设备
- 可以使用分区表赖避免某些特殊瓶颈,例如InnoDB单个索引的互斥访问、ext3文件系统的inode锁竞争
- 可以备份和恢复单个分区
局限:
- MySQL分区处理NULL值的方式
- 一个表最多只能有1024个分区
- 如果分区字段中有主键或者唯一索引的列,那么所有主键列和唯一索引列都必须包含进来
- 分区表无法使用外键约束
- NULL值会使分区过滤无效
- 所有分区必须使用相同的存储引擎
- 如果分区键所在列没有not null约束
- 如果是range分区表,那么null行将被保存在范围最小的分区
- 如果是list分区表,那么null行将被保存到list为0的分区
- 在按HASH和KEY分区的情况下,任何产生NULL值的表达式MySQL都视同它的返回值为0
- 为了避免这种情况的产生,建议分区键设置成NOT NULL
- 分区键必须是INT类型,或者通过表达式返回INT类型,可以为NULL。唯一的例外是当分区类型为KEY分区的时候,可以使用其他类型的列作为分区键( BLOB or TEXT 列除外)
- 对分区表的分区键创建索引,那么这个索引也将被分区,分区键没有全局索引一说
- 只有RANG和LIST分区能进行子分区,HASH和KEY分区不能进行子分区
- 临时表不能被分区


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2020-09-21 Java解析cron表达式