

《Hive性能调优实战》读书笔记
很不错的一本书。章节划分清晰明了,可根据个人需要读相应的章节。Hive各个方面的知识体系都有涉及。可作为工具书,常读常新,值得翻阅。
第2章 Hive问题排查与调优思路
优化方法
PL-SQL和T-SQL经验总结:
- 通过改写SQL,实现对计算引擎执行过程的干预
- 通过SQL-hint语法,实现对计算引擎执行过程的干预
- 通过数据库开放的一些配置开关,实现对计算引擎的干预
hive.vectorized.execution.enabled,默认是false,即关闭状态。设置为true,可将一个普通的查询转化为向量化查询执行。能大大减少扫描、过滤器、聚合和连接等典型查询操作的CPU使用。标准查询执行系统一次处理一行。矢量化查询执行可以一次性处理1024行的数据块,以减少底层操作系统处理数据时的指令和上下文切换。
在支持向量化查询的数据块中,每个列都存储为一个向量(原始数据类型的数组)。像算术和比较这样的简单操作,是通过在一个紧凑的循环中快速迭代向量来完成的,在循环中没有或很少有函数调用或条件判断分支。这些循环以一种简化的方式编译,使用相对较少的指令,通过有效地使用处理器管道和缓存内存,在更少的时钟周期内完成每条指令。简单地说就是,将单条的数据处理,转化为一次1万条数据的批量处理,优化底层硬件资源的利用率。
调优理解
规范分为3类:开发规范、设计规范和命名规范。
开发规范:
- 单条SQL长度不宜超过一屏
- SQL子查询嵌套不宜超过3层
- 少用或者不用Hint,特别是在Hive 2.0后,增强HiveSQL对于成本调优(CBO)的支持,在业务环境变化时可能会导致Hive无法选用最优的执行计划
- 避免SQL 代码的复制、粘贴。如果有多处逻辑一致的代码,可以将执行结果存储到临时表中
- 尽可能使用SQL自带的高级命令做操作。例如,在多维统计分析中使用cube、grouping set和rollup等命令去替代多个SQL子句的union all
- 使用set命令,进行配置属性的更改,要有注释
- 代码里面不允许包含对表/分区/列的DDL语句,除了新增和删除分区
- Hive SQL更加适合处理多条数据组合的数据集,不适合处理单条数据,且单条数据之间存在顺序依赖等逻辑关系。如,有A、B、C 3行数据,当A符合某种条件才能处理B行时,只有A、B符合某种条件,才能处理C行
- 保持一个查询语句所处理的表类型单一。例如,一个SQL语句中的表都是ORC类型的表,或者都是Parquet表
- 关注NULL值的数据处理
- SQL表连接的条件列和查询的过滤列最好要有分区列和分桶列
- 存在多层嵌套,内层嵌套表的过滤条件不要写到外层
设计规范:
- 表结构、列等属性字段要有注释
- 尽量不要使用索引。在传统关系型数据库中,通过索引可以快速获取少部分数据,这个阀值一般是10%以内。但在Hive的运用场景中,经常需要批量处理大量数据,且Hive 索引在表和分区有数据更新时不会自动维护,需要手动触发,使用不便。如果查询的字段不在索引中,则会导致整个作业效率更加低下。索引在Hive 3.0后被废弃,使用物化视图或者数据存储采用ORC格式可以替代索引的功能
- 创建内部表(托管表)不允许指定数据存储路径,一般由集群的管理人员统一规划一个目录并固化在配置中,使用人员只需要使用默认的路径即可
- 创建非接口表,只允许使用Orc 或者Parquet,同一个库内只运行使用一种数据存储格式。接口表指代与其他系统进行交互的数据表,例如从其他系统导入Hive 时暂时存储的表,或者数据计算完成后提供给其他系统使用的输出表
- Hive适合处理宽边(列数多的表),适当的冗余有助于Hive的处理性能
- 表的文件块大小要与HDFS的数据块大小大致相等
- 分区表分桶表的使用
命名规范
库/表/字段命名要自成一套体系:
- 表以tb_开头
- 临时表以tmp_开头
- 视图以v_开头
- 自定义函数以udf_卡头
- 原始数据所在的库以db_org_开头,明细数据所在库以db_detail_开头,数据仓库以db_dw_开头。
Hive 3.0中新增count(distinct)优化,通过配置hive.optimize.countdistinct,即使真的出现数据倾斜也可以自动优化,自动改变SQL执行的逻辑。
第3章 环境搭建
第4章 Hive及其相关大数据组件
YARN提供3种调度器:先来先服务调度器(FIFO Scheduler)、能力调度器(Capacity Scheduler)和公平调度器(Fair Scheduler)。
在Hadoop 3.0中将GPU、FPGA资源也纳入可管理的资源中。内存和CPU资源可以通过下面的配置选项进行调整:
yarn.nodemanager.resource.cpu-vcores,默认值为-1。默认表示集群中每个节点可被分配的虚拟CPU个数为8。为什么这里不是物理CPU个数?因为考虑一个集群中所有的机器配置不可能一样,即使同样是16核心的CPU性能也会有所差异,所以YARN在物理CPU和用户之间加了一层虚拟CPU,一个物理CPU可以被划分成多个虚拟的CPUyarn.nodemanager.resource.detect-hardware-capabilities为true,且该配置还是默认值-1,YARN会进行自动给计算可用虚拟CPUyarn.nodemanager.resource.memory-mb,默认值为-1。当该值为-1时,默认表示集群中每个节点可被分配的物理内存是8GByarn.nodemanager.resource.detect-hardware-capabilities为true,且该配置还是默认值-1,YARN会自动计算可用物理内存yarn.nodemanager.vmem-pmem-ratio,默认值为2.1。该值为可使用的虚拟内存除以物理内存,即YARN 中任务的单位物理内存相对应可使用的虚拟内存。例如,任务每分配1MB的物理内存,虚拟内存最大可使用2.1MByarn.nodemanager.resource.system-reserved-memory-mb, YARN保留的物理内存,给非YARN任务使用,该值一般不生效,只有当yarn.nodemanager.resource.detect-hardware-capabilities为true的状态才会启用,会根据系统的情况自动计算。
第5章 深入MR计算引擎
第6章 SQL执行计划
查看SQL的执行计划
Hive不同版本采用不同的方式生成执行计划:
- 早期版本使用基于规则的方式生成执行计划,这种方式会基于既定的规则来生成执行计划,而不会根据环境变化选择不同的执行计划
- Hive 0.14及之后的版本中,集成Apache Calcite,使得Hive也能够基于成本代价来生成执行计划,能够结合Hive的元数据信息和Hive 运行过程收集的各类统计信息推测出一个更为合理的执行计划。Hive 目前所提供的执行计划都是预估的执行计划。在关系型数据库中,如Oracle,还会提供一种真实的计划,即SQL实际执行完成后才能获得的执行计划
- 在Hive 2.0后加大基于成本优化器(CBO)的支持。
Hive提供的执行计划目前可查看的信息有以下几种:
- 查看执行计划基本信息,即explain
- 查看执行计划扩展信息,即explain extended
- 查看SQL数据输入依赖的信息,即explain dependency
- 查看SQL操作相关权限的信息,即explain authorization
- 查看SQL的向量化描述信息,即explain vectorization
执行计划包含两部分:
- 作业的依赖关系图,即STAGE DEPENDENCIES
- 每个作业的详细信息,即STAGE PLANS
explain extended,打印信息比explain丰富,包含三部分:
- 抽象语法树(Abstract Syntax Tree,AST):是SQL转换成MR或其他计算引擎的任务中的一个过程。Hive 3.0中,AST从explain extended中移除,用explain ast命令
- 作业的依赖关系图,即STAGE DEPENDENCIES,其内容和explain一样
- 每个作业的详细信息,即STAGE PLANS。explain extend输出更多信息,还包括每个表的HDFS读取路径,每个Hive表的表配置信息等。
简单SQL的执行计划解读
简单SQL:不含有列操作、条件过滤、UDF、聚合和连接等操作,即select-from-where型,执行时只会用到Map阶段。
带普通函数/操作符SQL的执行计划解读
普通函数特指除UDTF(表转换函数)、UDAF(聚合函数)和窗口函数之外的函数,如nvl()、cast()、case when的表达式、concat()和year()。即select-function(column)-from-where-function(column)或select-operation-from-where-operation类。
普通函数分类:数学函数、集合函数、类型转换函数、日期函数、条件判断函数、字符串函数、数据脱敏函数、表生成函数UDTF。UDTF包括:explode()、posexplode()、json_tuple()和parse_url_tuple()。
函数也有重载概念,重载函数的参数类型或个数与基本函数不一致。
结论:select-function(column)-from -where-function(column)或select-expression-from-where-expression类SQL和select-from-where基本型SQL的执行计划可以归为同一种类型。
带聚合函数的SQL执行计划解读
归结为select-aggr_function-from-where-group by类型。常见的聚合函数:avg()、sum()、collect_set()、collect_list()、count()、corr()、covar_pop()、covar_samp()、array()()、histogram_numeric()、max()、min()、percentile()、percentile_approx()、regr_avgx()、regr_avgy()、regr_count()、regr_intercept()、regr_r2()、regr_slope()、regr_sxx()、regr_syy()、stddeve_pop()、stddeve_samp()、variance()、var_pop()和var_samp()。
在MR过程中,如果要使用Reduce又没法避免不使用Map,只能使用Combine或者启用数据压缩来减少Map和Reduce之间传输的数据量,以提高效率。Hive提供配置项用于是否启用Map端的聚合,即hive.map.aggr。
高级分组聚合指在聚合时使用GROUPING SETS、cube和rollup的分组聚合,要注意Hive是否开启向量模式。
带窗口/分析函数的SQL执行计划解读
Hive提供的窗口和分析函数,有13个:lead()/lag()/first_value()/count()/sum()/max()/avg()/rank()/row_number()/dense_rank()/cume_dist()/percent_rank()/ntile() over()
表连接的SQL执行计划解读
表连接有6种类型:
- inner join:返回两个表/数据集连接字段的匹配记录
- full outer join:返回左、右两个表/数据集的全部行,不管两边的表/数据集中是否存在相互匹配的行。不匹配的行,以空值代替
- left outer join:返回左表/数据集的所有记录,以及右表/数据集中与左表/数据集匹配的记录,如果没有则用空补齐
- right outer join:返回右表/数据集的所有记录,以及左表/数据集中与右表/数据集匹配的记录,如果没有则用空补齐
- left semi join:返回左表/数据集中与右表/数据集匹配的记录
- cross join:返回左右两表连接字段的笛卡尔积
内连接与外连接唯一的区别在于Reduce阶段的Join Operator。
左半连接(left semi join),用于判断一个表的数据在另外一个表中是否有相同的数据。可用于替代Hive中in/exists类的子查询。
第7章 Hive数据处理模式
Hive SQL语法,本质上可以被分成3种模式,即过滤模式、聚合模式和连接模式。
- 过滤模式,即对数据的过滤,从过滤的粒度来看,分为数据行过滤、数据列过滤、文件过滤和目录过滤4种方式。这4种过滤方式有显式关键字表示,例如where、having等,也有隐式过滤,例如列式文件、物化视图等;
- 聚合模式,即数据的聚合,数据聚合的同时也意味着在处理数据过程中存在Shuffle的过程。Shuffle过程应该是作为每一个Hive开发者需要特别注意的地方;
- 连接模式,即表连接的操作,分为两大类:有Shuffle的连接操作和无Shuffle的连接操作。这两个类型都有优缺点,但只要涉及表连接的都需要特别注意,因为表连接常常是程序性能的瓶颈点。
过滤模式
聚合模式
聚合模式,即将多行的数据缩减成少数几行的计算模式。可以在整个计算流程的前面快速过滤掉作业中传输的数据量,使得计算流程的后续操作中的数据量大为降低,适当提高程序的运行效率。有时会存在两种情况,会导致聚合模式运行效率低下。
常见的关于计算模式的聚合模式有:
- distinct模式;
- count计数的聚合模式;
- 数值相关的聚合模式;
- 行转列的聚合模式。
通常将多行的数据聚合到一行中,该行含有多行的所有明细数据的计算模式称为不可汇总。这种情况要注意某些节点汇总的数据量是否过大,产生数据倾斜。在Hive 中不可计算中间结果的方法有:collect_list()和collect_set()等。
连接模式
两种:
- 发生在Shuffle和Reduce阶段
- 发生在Map阶段,即Map连接
Replication连接在Map阶段完成连接操作,相比发生在Shuffle阶段的Repartition连接,可以减少从HDFS读取表的次数,可以在Map 阶段实现连接时不匹配条件的记录行的过滤,减少下游网络传输的数据量和下游计算节点处理的数据量。
Replication连接根据实现的不同表连接可以分为:
- 普通的MapJoin:对使用的表类型无特殊限制,只需要配置相应的Hive配置
- Bucket MapJoin:要求使用的表为桶表
- Skewed MapJoin:要求使用的表为倾斜表
- Sorted Merge Bucket MapJoin:要求使用的表为桶排序表
第8章 YARN日志
YARN提供两种工具Resource Manager Web UI和Job History Web UI,用于查看集群中运行作业的日志。
查看
界面熟悉,鼠标操作。注意事项:
- Submit Time到Start Time还会经历被集群队列所接受(Accept),最后等待资源分配后才能真正开始运行。Start Time 和Submit Time 间隔时间越长,则代表队列Queue资源利用紧张,应当要注意集群队列的资源分配情况
- Maps Total不一定等于Maps Completed,Map失败导致系统重新分配Map数。有可能是集群节点存在故障, Map的所耗资源过多,Map长期得到错误的资源(读取损坏的文件)
- Reduces Total也不一定等于Reduces Completed,Reduce任务失败,导致系统重新分配Reduce数
集群概况
Cluster中的About链接。GET http://<rmhttpaddress:port>/ws/v1/cluster/metrics
集群节点概况
GET http://<rmhttpaddress:port>/ws/v1/cluster/nodes
GET http://<rmhttpaddress:port>/ws/v1/cluster/nodes/<node_id>
一些信息:
Vmem enforcement enabled:当启动一个线程时,检查任务是否超过可用的虚拟内存。如超过可用内存分配值则将其kill,默认是true
Pmem enforcement enabled:当启动一个线程时,检查任务是否超过可用的物理内存。如超过可用内存分配值则将其kill,默认是true
TotalVCoresNeeded:容器所用虚拟核心数
队列调度情况
队列Queue是所有作业真正提交的地方,YARN是通过队列来进行资源划分的。一个作业所能利用的最大资源数,就是该任务所在队列被集群分配到的最大资源数。
作业运行信息
看一个作业是否正常,需关注3方面信息:集群整体信息、任务运行所在的节点信息,以及任务所在队列的信息。
Hive在YARN集群运行的任务会涉及几个状态:NEW、NEW_SAVING、SUBMITTED、ACCEPTED、RUNNING、FINISHED、FAILED和KILLED。NEW、NEW_SAVING和UBMITED在实际工作中用到的概率极低。实际工作中关注后5个状态即可:
- ACCEPTED:接受状态,已经被队列(Queue)所接受,但在还没开始执行前,作业会暂时变为这个状态。如果作业一直停留在这个状态,需要及时查看队列资源是否充足,并及时调整队列资源或者更换队列
- RUNNING:运行状态,作业已经获取到足够资源,开始在进群中进行计算处理的状态。如果一个作业持续运行时间很长,就需要在这个状态下查看运行的日志
- FINSHED:完成,作业已经正常结束
- FAILED:失败,作业运行失败。根据作业ID来查看日志定位问题
- KILLED:被人为或调度系统关停
作业计数器:counters表示Hive作业在Input、Map、Shuffle、Reduce和Output等各个阶段的定量数据。通过作业计数器,能够直观看到作业处理的数据量、处理耗时和所用资源,这对于平常开发时定位问题点,提升性能瓶颈有直接的作用。
一般分为以下7部分:
- 文件系统计数器(File System Counters)
- 作业计数器(Job Counters)
- MR框架计数器(MR Framework Counters)
- Hive计数器(Hive Counters)
- Shuffle 错误计数器(Shuffle Errors Counters)
- File Input Format Counters
- File Output Format Counters
Uberized:表示是否开启Uber运行模式
第9章 数据存储
支持的格式有文本格式(TextFile)、二进制序列化文件(SequenceFile)、行列式文件(RCFile)、Apache Parquet 和优化的行列式文件(ORCFile)。
ORC
ORC文件是一种带有模式描述的行列式存储文件。会将数据先按行组进行切分,一个行组内部包含若干行,每一行组再按列进行存储。
ORC文件使得Hive支持事务,Hive的事务被设计成每个事务适用于更新大批量的数据,而不建议用事务频繁地更新小批量的数据。
ORC在每个文件中提供3个级别的索引:
- 文件级:这一级的索引信息记录文件中所有stripe的位置信息,以及文件中所存储的每列数据的统计信息
- 条带级别:该级别索引记录每个stripe所存储数据的统计信息
- 行组级别:在stripe中,每10000行构成一个行组,该级别的索引信息就是记录这个行组中存储的数据的统计信息。
ORC表的属性配置项:
- orc.compress:ORC文件的压缩类型,可选类型有NONE、ZLIB和SNAPPY,默认值是ZLIB
- orc.compress.size:表示压缩块(chunk)的大小,默认262144(256KB)
- orc.stripe.size:写stripe,可以使用的内存缓冲池大小,默认67108864(64MB)
- orc.row.index.stride:行组级别索引的数据量大小,默认是10000,必须要设置成大于等于10000的数
- orc.create.index:是否创建行组级别索引,默认true
- orc.bloom.filter.columns:需要创建布隆过滤的组
- orc.bloom.filter.fpp:使用布隆过滤器的假正(False Positive)概率,默认0.05。
Parquet
数据归档
对于HDFS中有大量小文件的表,可以通过Hadoop归档(archive)的方式将文件归并成几个较大的文件。归并后的分区会先创建一个data.har目录,里面包含两部分内容:索引(_index和_masterindex)和数据(part-*)。索引记录归并前的文件在归并后的所在位置。Hive数据归档后并不会对数据进行压缩。
第10章 发现并优化Hive性能问题
监控Hive数据库的状态
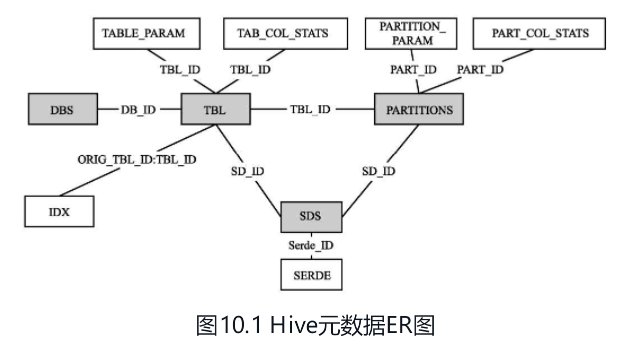
常见的监控:
- 普通表存储的文件的平均大小。文件块偏大造成数据倾斜
- 分区存储的文件平均大小,大于两倍HDFS文件块大小的分区
- 大表不分区的表
- 分区数据不均匀的表
- 采用ORC或者Parquet以外格式的表
- 有使用索引的表
- 表及分区的字段的空值率,和字段重复的占比
监控当前集群状态
获取集群的状态信息:GET http://<rmhttpaddress:port>/ws/v1/cluster/info
获取集群任务的整体状态:GET http://<rmhttpaddress:port>/ws/v1/cluster/metrics
获取提交到集群所有任务的运行信息:GET http://<rmhttpaddress:port>/ws/v1/cluster/apps
获取提交到集群的单个任务的运行信息:GET http://<rmhttpaddress:port>/ws/v1/cluster/apps/任务ID
获取当前资源调度的分配信息:GET http://<rmhttpaddress:port>/ws/v1/cluster/scheduler
定位性能瓶颈
数据倾斜
数据倾斜,即单个节点任务所处理的数据量远大于同类型任务所处理的数据量,导致该节点成为整个作业的瓶颈,这是分布式系统不可能避免的问题。导致数据倾斜有两种原因:
- 任务读取大文件;
- 任务需要处理大量相同键的数据:
- 数据含有大量无意义的数据,如空值NULL、空字符串等
- 含有倾斜数据在进行聚合计算时无法聚合中间结果,大量数据都需要经过Shuffle阶段的处理,引起数据倾斜
- 数据在计算时做多维数据集合,导致维度膨胀引起的数据倾斜
- 两表进行Join,都含有大量相同的倾斜数据键
第11章 知识体系总结
知识体系
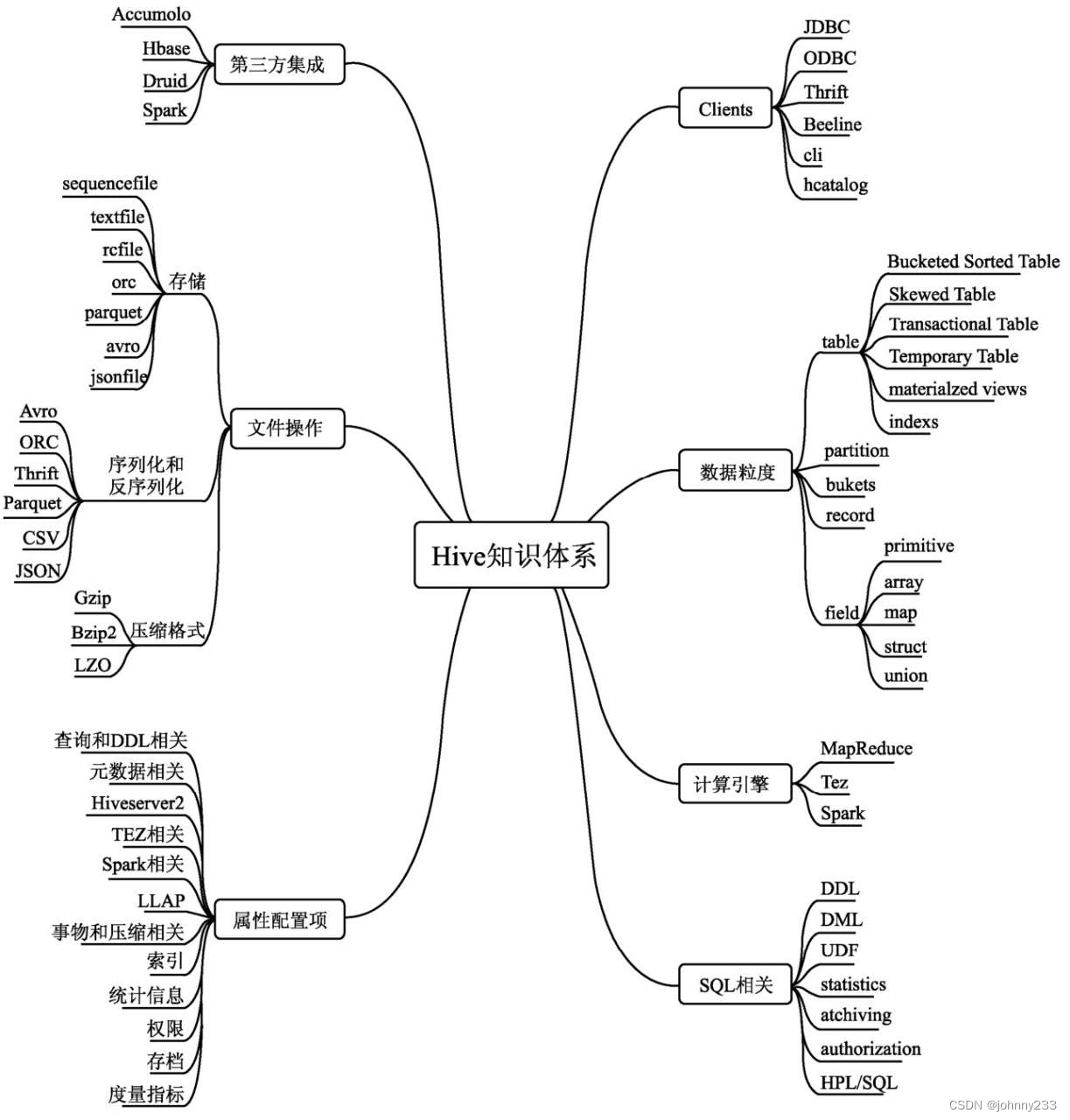
数据粒度
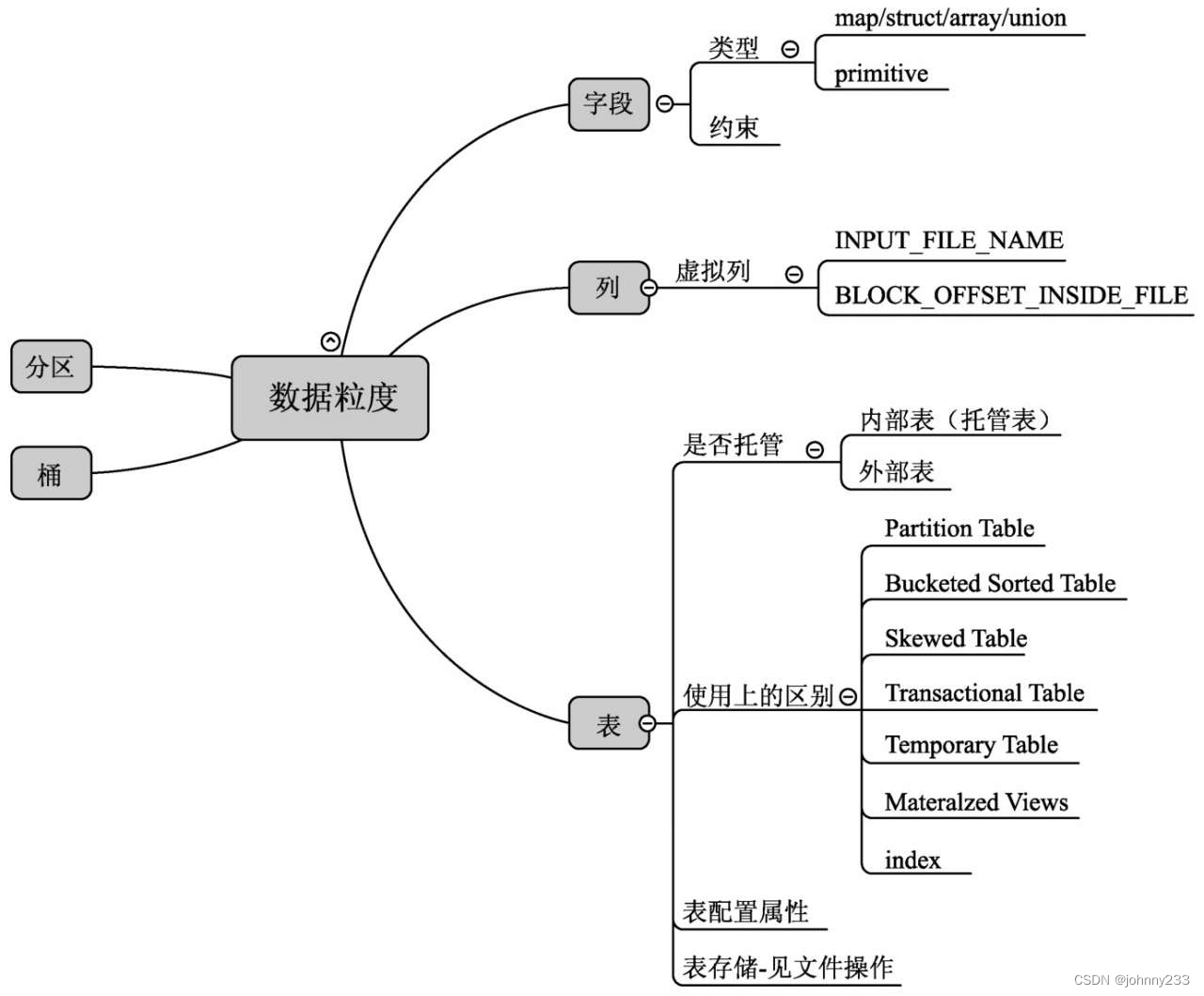
UDF可分为三部分:BIF(Built-in-functions)Hive 内建函数、UDAF (User-Defined Aggregate Functions)聚合函数和UDTF(User-Defined Table-Generating Functions)表生成函数。UDTF,包括explode、posexploed、inline、stack、json_tuple和parse_url_tuple。
权限控制
包括Hive元数据和HDFS数据,有以下4种权限控制方式:
- 基于存储检查的权限控制
- 在HS2上基于SQL 标准的权限控制
- 通过Apache Ranger和Sentry进行权限控制
- 老版本的权限控制
文件操作可以分为三大部分:文件存储类型、序列化/反序列化方式、压缩格式
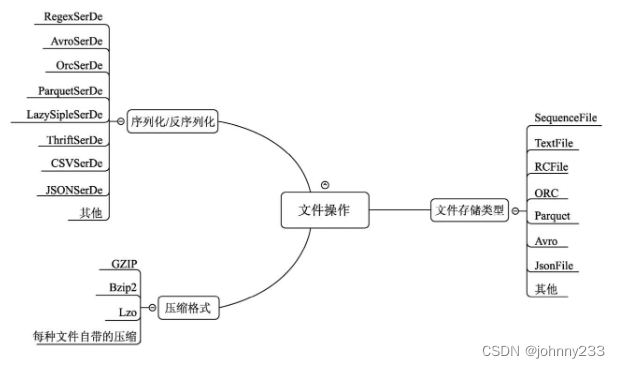
LazySimpleSerDe:Hive 2.1之后出现的新类型,可用于读取与MetadataTyped ColumnsetSerDe和TCTLSeparatedProtocol相同的数据格式。然而,LazySimpleSerDe以一种懒执行的方式创建对象,旨在提供更好的性能。LazySimpleSerDe 也输出类型化的列,而不是像Metadatatypedcolumnsetserde那样将所有列当作字符串处理。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具