
Hibernate缓存分类:
一、Session缓存(又称作事务缓存):Hibernate内置的,不能卸除。
缓存范围:缓存只能被当前Session对象访问。缓存的生命周期依赖于Session的生命周期,当Session被关闭后,缓存也就结束生命周期。
二、SessionFactory缓存(又称作应用缓存):使用第三方插件,可插拔。
缓存范围:缓存被应用范围内的所有session共享,不同的Session可以共享。这些session有可能是并发访问缓存,因此必须对缓存进行更新。缓存的生命周期依赖于应用的生命周期,应用结束时,缓存也就结束了生命周期,二级缓存存在于应用程序范围。
缓存:但是一般人的理解在内存中的一块空间,可以将二级缓存配置到硬盘。用白话来说,就是一个存储数据的容器。我们关注的是,哪些数据需要被放入二级缓存。
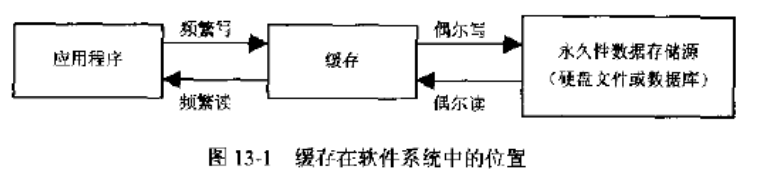
缓存:是计算机领域的概念,它介于应用程序和永久性数据存储源之间。
作用:降低应用程序直接读写数据库的频率,从而提高程序的运行性能。缓存中的数据是数据存储源中数据的拷贝。缓存的物理介质通常是内存。
Hibernate的缓存一般分为3类:
一级缓存
二级缓存
查询缓存
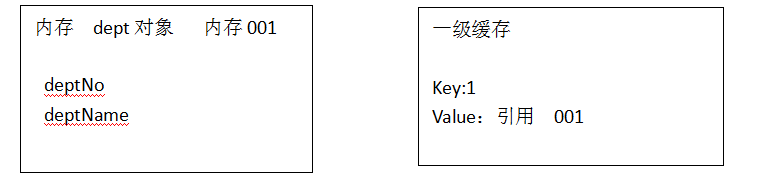
如果希望一个Java对象一直处于声明周期中,就必须保证至少有一个变量引用它,或者在一个Java集合中存放了这个对象的引用。在Session接口的实现咧SessionImpl中定义了一系列的Java集合,这些Java集合构成了Session的缓存。

以下方法支持一级缓存:金牌结论
* get()
* load()
* iterate(查询实体对象)
其中 Query 和Criteria的list() 只会缓存,但不会使用缓存(除非结合查询缓存)。
一级缓存
01.Session内的缓存即一级缓存,内置且不能被卸载,一个事务内有效。
02.Session为应用程序提供了管理缓存的方法:
evict(Object o)
clear()
03.金牌讲解一级缓存
一级缓存的生命周期和session的生命周期一致,当前session一旦关闭,一级缓存就消失了,因此一级缓存也叫session级的缓存或事务级缓存,一级缓存只存实体对象,它不会缓存一般的对象属性(查询缓存可以),即当获得对象后,就将该对象缓存起来,如果在同一session中再去获取这个对象时,它会先判断在缓存中有没有该对象的id,如果有则直接从缓存中获取此对象,反之才去数据库中取,取的同时再将此对象作为一级缓存处理。
二级缓存
开发中的用于没有面试带来作用大。
二级缓存是进程或集群范围内的缓存,可以被所有的Session共享
二级缓存是可配置的插件
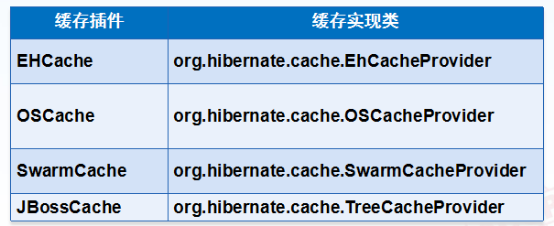
二级缓存的配置使用(ehcache缓存)
*1.引入如下jar包。
ehcache-1.2.3.jar 核心库
backport-util-concurrent.jar
commons-logging.jar
*2.配置Hibernate.cfg.xml开启二级缓存
<property name="hibernate.cache.use_second_level_cache">true</property>
*3.配置二级缓存的供应商
<property name="hibernate.cache.provider_class">org.hibernate.cache.EhCacheProvider</property>
*4.指定使用二级缓存的类
方案一:在*.hbm.xml中配置
在<class元素的子元素下添加chche子节点,但该配置仅会缓存对象的简单属性,若希望缓存集合属性中的元素,必须在set元素中添加<cache>子元素
<class name="Student" table="STUDENT">
<cache usage="read-write"/>
在大配置文件(hibernate.cfg.xml)中配置
<class-cache usage="read-write" class="cn.happy.entity.Student"/>
<collection-cache usage="read-write" collection=""/>
*5.在src下添加ehcache.xml文件,从etc获取文件即可。
测试: 二级缓存 数据散装 的特点
1 Session session = HibernateUtil.getSession(); 2 Transaction tx=session.beginTransaction(); 3 Dept dept = (Dept)session.get(Dept.class,1); 4 System.out.println(dept); 5 6 Dept dept2 = (Dept)session.get(Dept.class,1); 7 System.out.println(dept2); 8 tx.commit(); 9 10 Session session2 = HibernateUtil.getSession(); 11 Transaction tx2=session2.beginTransaction(); 12 Dept dept3 = (Dept)session2.get(Dept.class,1); 13 System.out.println(dept3); 14 tx2.commit();
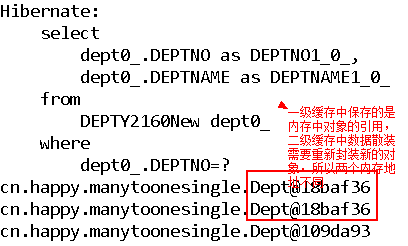
解析:每次从二级缓存中取出的对象,都是一个新的对象。、
测试: 使用list 将数据存储到二级缓存中(只能往二级缓存中存数据 不能取出数据) 在从二级缓存中取出数据时 会重新从数据库取数据(重新生成sql)
List<Carport> list = session.createQuery("from Carport").list(); System.out.println(list.get(0).getLocation()); HibernateUtil.closeSession(); System.out.println("=========="); Session session2 = (Session) HibernateUtil.getSession(); List<Carport> list2 = session2.createQuery("from Carport").list(); System.out.println(list.get(0).getLocation());
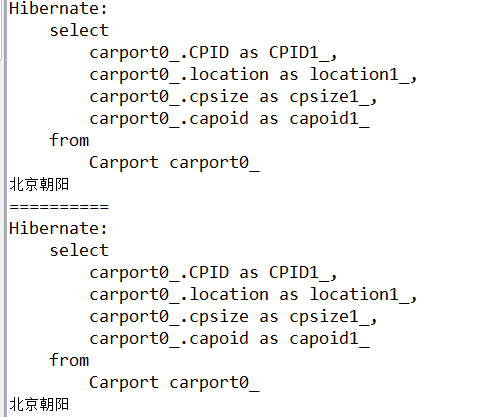
解析: 可以看到 我们上面的list()操作仅仅是将数据存储到了缓存中 却不能从内存中取出数据(生成了第二道sql查询语句)。
测试:iterator()方法可以读取二级缓存中的数据
首先说明:
iterator()会先到数据库中把id都取出来,然后真正要遍历某个对象的时候先到缓存中找,如果找不到,以id为条件再发一条sql到数据库,
这样如果缓存中没有数据,则查询数据库的次数为n+1。 iterate中返回的对象是代理对象
1 Query query = session.createQuery("from Carport"); 2 Iterator iterate = query.iterate(); 3 while (iterate.hasNext()) { 4 System.out.println(((Carport)iterate.next()).getLocation()); 5 } 6 7 HibernateUtil.closeSession(); 8 System.out.println("=========="); 9 10 Session session2 = (Session) HibernateUtil.getSession(); 11 Query query2 = session2.createQuery("from Carport"); 12 Iterator iterate2 = query2.iterate(); 13 while (iterate2.hasNext()) { 14 System.out.println(((Carport)iterate2.next()).getLocation()); 15 }
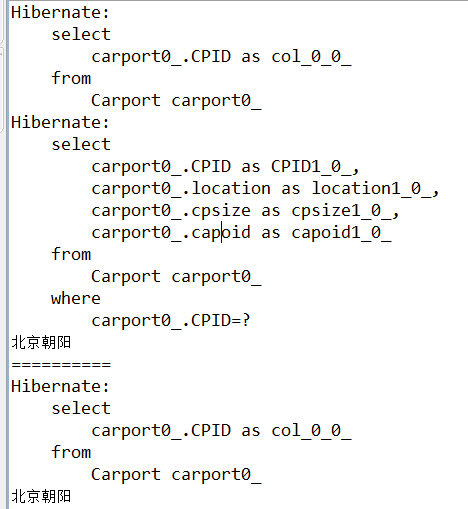
解析:要遍历某个对象的时候先到缓存中找,如果找不到,以id为条件再发一条sql到数据库。(iterator()可以从缓存中取出数据来)
测试: 集合级别缓冲区
二级缓存的策略
当多个并发的事务同时访问持久化层的缓存中的相同数据时,会引起并发问题,必须采用必要的事务隔离措施。
在进程范围或集群范围的缓存,即第二级缓存,会出现并发问题。因此可以设定以下4种类型的并发访问策略,每一种策略对应一种事务隔离级别。
● 只读缓存(read-only)
如果应用程序需要读取一个持久化类的实例,但是并不打算修改它们,可以使用read-only缓存。这是最简单,也是实用性最好的策略。
对于从来不会修改的数据,如参考数据,可以使用这种并发访问策略。
● 读/写缓存(read-write)
如果应用程序需要更新数据,可能read-write缓存比较合适。如果需要序列化事务隔离级别,那么就不能使用这种缓存策略。
对于经常被读但很少修改的数据,可以采用这种隔离类型,因为它可以防止脏读这类的并发问题。
● 不严格的读/写缓存(nonstrict-read-write)
如果程序偶尔需要更新数据(也就是说,出现两个事务同时更新同一个条目的现象很不常见),也不需要十分严格的事务隔离,可能适用nonstrict-read-write缓存。
对于极少被修改,并且允许偶尔脏读的数据,可以采用这种并发访问策略。
● 事务缓存(transactional)
transactional缓存策略提供了对全事务的缓存,仅仅在受管理环境中使用。它提供了Repeatable Read事务隔离级别。对于经常被读但很少修改的数据,可以采用这种隔离类型,因为它可以防止脏读和不可重复读这类的并发问题。
在上面所介绍的隔离级别中,事务型并发访问策略的隔离级别最高,然后依次是读/写型和不严格读写型,只读型的隔离级别最低。事务的隔离级别越高,并发性能就越低。

查询缓存
1,查询是数据库技术中最常用的操作,Hibernate为查询提供了缓存,用来提高查询速度,优化查询性能
相同HQL语句检索结果的缓存!
2,查询缓存依赖于二级缓存
查询缓存是针对普通属性结果集的缓存,对实体对象的结果集只缓存id(其id不是对象的真正id,可以看成是HQL或者SQL语句,它与查询的条件相关即where后的条件相关,不同的查询条件,其缓存的id也不一样)。查询缓存的生命周期,当前关联的表发生修改或是查询条件改变时,那么查询缓存生命周期结束,它不受一级缓存和二级缓存生命周期的影响,要想使用查询缓存需要手动配置如下:
1 * 在hibernate.cfg.xml文件中启用查询缓存,如:
2 <property name="hibernate.cache.use_query_cache">true</property>
3 * 在程序中必须手动启用查询缓存,如:
4 query.setCacheable(true);
5 其中 Query 和Criteria的list() 就可利用到查询缓存了。

注意:
不要想当然的以为缓存可以提高性能,仅仅在你能够驾驭它并且条件合适的情况下才是这样的。hibernate的二级缓存限制还是比较多的。在不了解原理的情况下乱用,可能会有1+N的问题。不当的使用还可能导致读出脏数据。 如果受不了hibernate的诸多限制,那么还是自己在应用程序的层面上做缓存吧。
在越高的层面上做缓存,效果就会越好。就好像尽管磁盘有缓存,数据库还是要实现自己的缓存,尽管数据库有缓存,咱们的应用程序还是要做缓存。因为底层的缓存它并不知道高层要用这些数据干什么,只能做的比较通用,而高层可以有针对性的实现缓存,所以在更高的级别上做缓存,效果也要好些吧。
缓存是位于应用程序与物理数据源之间,用于临时存放复制数据的内存区域,目的是为了减少应用程序对物理数据源访问的次数,从而提高应用程序的运行性能.
Hibernate在查询数据时,首先到缓存中去查找,如果找到就直接使用,找不到的时候就会从物理数据源中检索,所以,把频繁使用的数据加载到缓存区后,就可以大大减少应用程序对物理数据源的访问,使得程序的运行性能明显的提升.
后续更新。。。
