
4week-3字符串和字符
一.十六进制,十进制,在ASCII中的表示对应关系

1. 0
| 十进制 | 十六进制 | 字符 |
|---|---|---|
| 0 | 0 | NULL |
0x01 //数值表达方式
'\x00' //十六进制字符表达
"\x00" //十六进制字符串
2.tab
* 字符表示
十六进制 '\x09'
或者 '\t'
* 字符串表达
"\x09\t" 2个字符
3.\n 换行符,新的一行
* 字符表示
'\n' 或者十六进制 'x0a'
4. \r 回车
也支持换行.看在哪种操作系统上
* 字符表达
或者 '\r' 或者十六进制 '\x0d'
* 字符串表达
windows 回车换行
"\r\n" 2个字符,必须用字符串
或者
十六进制表达 "\x0d\x0a"
linux
'\n' //换行
mac
'\r' //换行
二.字符的宽度不是展示的宽度
- 我们看到的字符和字符之间的宽度和,存储在磁盘的宽度是2回事
- 比如内存中存储的是
0x61 0A 61编辑器打开后,把0x61翻译成a,把0A翻译成tab,把61翻译成b----> a换行b
1. "a\tb" 字节问题
len3,占用都是3个字节
"a空格b" 内存中 "0x61 20 61 "
"atabb" 内存中 "0x61 0A 61 "
"a\tb" 内存中 "0x61 0A 61 " \t是一个字节
2.有的编辑器不支持键盘上的"tab键"编程时候保险的方式 用\t
func main() {
s1 := "a b" //a和b中间按的是键盘上的"tab键".有的编辑器不支持
s2 := "a\tb" //保险做法:\t
s3 := "a\x09b" //不要看表面,要看内存
s4 := "a\tb" //如果要显示"",用\转义
fmt.Println(s1, s2, s3, s4)
}
3.明确长度,换行符要,写清楚,由于编辑器的问题,否则不准确
s4 := "a\nb"
fmt.Println(s4, len(s4), []byte(s4))
}
三.字符串笔记大小
*字符串笔记,比较的是ascii
//字符串比较大小.比较的是ascii里的十六进制
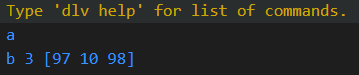
fmt.Println('A' > 'a')
fmt.Println("a" > "A")
fmt.Println("AA" > "Aa")
fmt.Println("AAa" > "AaA")

四.字符

1.字符定义:
func main() {
s := 'a' //默认:rune 4byte 查unicode
var s1 byte = 'a' //字节.查ascii 1个byte
fmt.Printf("%T %T", s, s1)
}

五.字符串
1.字符串定义
func main() {
s := '测'
//1.rune 4byte unicode 不是容器,不能len
fmt.Println(s)
s1 := "abc"
//1.3byte 616263
//2.字节是怎么读出来的: utf-8兼容ASCII码.3x1=3个byte
fmt.Println(len(s1))
s2 := "测试"
//1.s2是字符串.utf-8,每个中文3个字节长度6byte;
//2.字节是怎么读出来的: "测试"在内存中展开成utf-8的2个字符,2x3=6个byte
fmt.Println(len(s2)) //len只看字节数,其他语言是看字符数的,len只能用在内建
s3 := "测"
//1.一个的字符串,utf-8.一个汉字占3byte
fmt.Println(len(s3))
}
2.string 转切片
- 线性数据结构,类似slice,有header,有底层字符数组,但是用起来为了不增加go的难度,go设计者把它的使用方式和其他语言统一了,使用上感觉和int类型一样
1. 把字符串强制转为 ---> 1字节的字符串转byte和rune切片
func main() {
s1 := "abc"
t1 := []byte(s1)
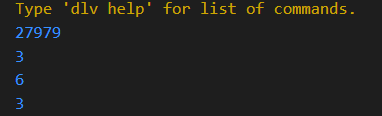
fmt.Println(t1, len(t1), cap(t1), &t1[0], &t1[1]) //[97 98 99] 3 8 0xc000128058 0xc000128059 偏移1个byte
t2 := []rune(s1)
fmt.Println(t2, len(t2), cap(t2), &t2[0], &t2[1]) //[97 98 99] 3 4 0xc0001280a0 0xc0001280a4 偏移4个byte
}
- 结果

2. 把多字符串转为byte和rune切片
func main() {
t3 := []byte(s2) //utf8的字节序列
//把s2 := "测试" 拆成`字节`放入byte切片
fmt.Println(t3, len(t3)) //[230 181 139 232 175 149] 6 //像是utf-8编码字符序列 是utf-8编码
t4 := []rune(s2) //s2是 [230 181 139 232 175 149] 6 是utf-8编码
//把 utf8转成unicode双字节2byte unicode是4字节,前2个字节空着,用后2个字节测字
fmt.Println(t4, len(t4))
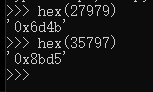
//2个rune类型 [27979 35797] 2 //牵扯到utf-8映射成unicode// [230 181 139 232 175 149 utf8]把2个3字节转成2个字节双字节
//utf8的字节序列-->unicode序列
}
- 结果

为什么是2个字节呢?
3.把rune序列转为字符串
func main() {
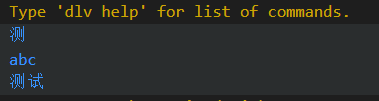
fmt.Println(string([]rune{27979})) //unicode序列转为utf-8 string
fmt.Println(string([]byte{0x61, '\x62', 0x63})) //byte sequence 转为 utf-8 string sequence
fmt.Println(string([]byte{230, 181, 139, 232, 175, 149}))
}
- 结果
4.println直接打印索引
func main() {
s1 := "abc"
s2 := "测试"
fmt.Println(s1[0], s1[1], s1[2]) //通过索引取值,是字符序列,如同放在[]byte里一样,其中的1个byte uint8,所以显示是整数
fmt.Println(s2[0], s2[1], s2[2]) //通过索引取值,是字符序列,如同放在[]byte里一样,其中的1个byte uint8,所以显示是整数
}
- 结果:

3.字符串遍历
1.按照字节遍历
s1 := "abc"
for i := 0; i < len(s1); i++ { //len 把abc拆成字节
fmt.Println(i, s1[i])
}
2.按照字符遍历

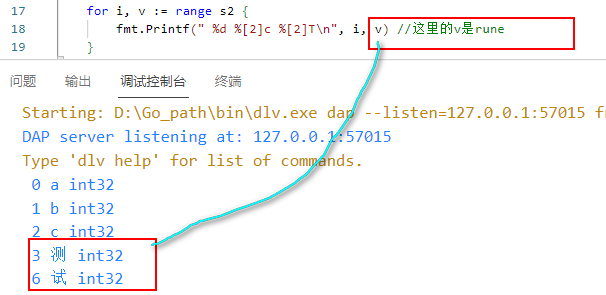
s2 := "abc测试"
for i, v := range s2 {
fmt.Printf("%d %[2]c\n", i, v) //这里的v是rune
}
- 结果
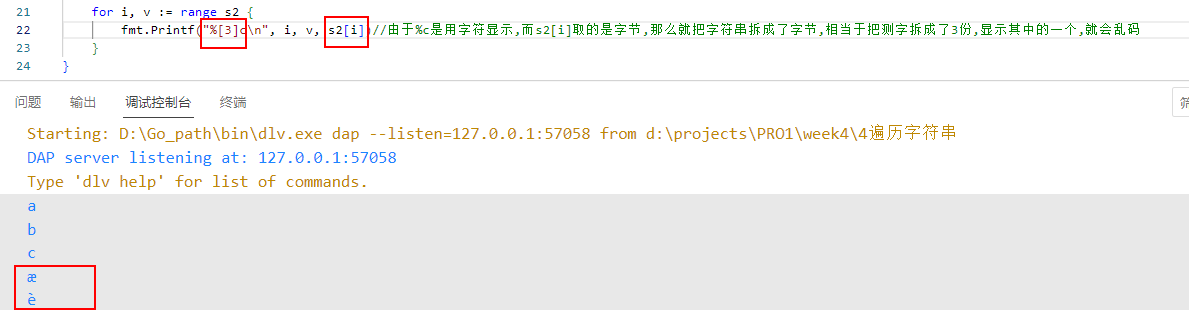
3.按照字符遍历.但是按照字节显示
for i, v := range s2 {
fmt.Printf("%[3]c\n", i, v, s2[i])//由于%c是用字符显示,而s2[i]取的是字节,那么就把字符串拆成了字节,相当于把测字拆成了3份,显示其中的一个,就会乱码
}
- 结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号