Redis 学习笔记(三)哨兵模式配置高可用和集群
哨兵模式
Redis Sentinel 是社区版本推出的原生高可用解决方案,其部属架构主要包括两部分:Redis Sentinel集群 和 Redis数据集群。
其中 Redis Sentinel集群 是由若干 Sentinel节点组成的分布式集群,可以实现故障发现、故障自动转移、配置中心和客户端通知。Redis Sentinel的节点数量要满足 2n+1(n>=1)的奇数个。
优点:
-
Redis Sentinel集群部署简单;
-
能够解决 Reids 主从模式下的高可用切换问题;
-
很方便实现 Redis 数据节点的线性扩展,轻松突破 Redis 自身单线程平静,可极大满足 Redis 大容量或高性能的业务需求;
-
可以实现一套 Sentinel 监控,一组Redis数据节点 或 多组数据节点。
缺点:
-
部署相对 Redis主从模式较复杂些,原理理解更繁琐;
-
资源浪费,Redis数据节点中 slave节点作为备份节点不提供服务;
-
Redis Sentinel主要针对 Redis数据节点中的主节点的高可用切换,对 Redis的数据节点做失败判定分为主管下线,和客观下线两种,对于 Redis的从节点有对节点做主观下线操作,并不执行故障转移。
-
不能解决读写分离问题,实现起来相对复杂。
Sentinel 哨兵
简要
对于生产环境的需求,Redis单实例远远不能提供稳定高效、具备数据冗余和高可用能力的键值存储服务。
使用Redis的主从复制和持久化可以解决数据冗余备份的问题。但是,如果没有人工干预,当主实例宕机时,整个Redis服务将无法回复。
尽管市面上有多种Redis高可用的解决方案,但Redis原生提供的Sentinel是使用最广泛的高可用架构。
概念
Sentinel(哨兵)充当了Redis主实例和从实例的守卫者。因为单个哨兵本身也可能失效,所以一个哨兵显然不足以保证高可用。对主实例进行故障迁移的决策是基于仲裁系统的,所以至少需要三个哨兵进程才能构成一个健壮的分布式系统来持续地监控Redis主实例的状态。如果有多个哨兵进程检测到主实例下线,其中一个哨兵进程会被选举出来负责推选一个从实例替代原有的主实例。如果配置恰当,上述的整个过程都将是自动化的,无需人工干预。
操作步骤及工作原理
首先,我们要为Sentinel进程准备一个配置文件。由于在Redis源码包中有一个示例文件 sentinel.conf,所以在这里我们需要对文件进行一些简单的修改:
port 26379
dir /temp
sentinel monitor mymaster 192.168.0.31 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
注意,我们必须保证运行Sentinel实例的用户有写入配置文件的权限。
如上所属,因为Sentinel是Redis实例的守护进程,因此它必须监听在与Redis实例不同的端口上。Sentinel的默认端口号是 26379。如果将一个新的主实例添加到Sentinel中进行监控,那么我们可以按照如下格式在配置文件中增加一行:
sentinel monitor <master-name> <ip> <port> <quorum>
在本例中,sentinel monitor mymaster 192.168.0.31 6379 2 表示Sentinel将监控 192.168.0.31:6379 的主实例,该主实例名为 mymaster。
在本例中,如果某个实例超过 30 秒仍未响应 ping 命令,则它被视作下线。当主实例发生故障迁移时,其中的一个从实例将被选为新的主实例,而其他的从实例则将需要从新的主实例那里进行主从复制。parallel-syncs参数表示有几个从实例可以同时从新的主实例进行数据同步。
那么,Sentinel进程是如何检测到从服务器和其他哨兵的呢?我们可以认为,为了获得从实例的信息,Sentinel会向主实例发送 INFO REPLICATION 命令。即使从实例的结构有多级,也可以通过递归的方式找到它们。实际上每个Sentinel进程每10秒钟会向其监控的所有Redis实例发送 INFO REPLICATION 命令,来获取整个主从复制拓扑结构的最新消息。
为了探测其他哨兵及其他哨兵进行通信,每个Sentinel进程每两秒钟会向一个名为__sentinel__:hello 的频道发布一条消息,报告其自身及所监控主实例的状态。因此只要订阅该频道就能发现其他哨兵的消息了。
当从实例和其他哨兵的信息发生改变时,Sentinel的配置文件也将被更新。这就是 Sentinel 进程必须对配置文件有写入权限的原因。
测试案例
手动触发主实例故障迁移
我们手动强制哨兵进行了主实例的故障迁移并重新选出了一个从实例。
具体过程如下:
-
由于故障迁移是手动触发的,所以在执行故障迁移操作之前,Sentinel不需要寻求其他哨兵的同意,直接被选举为leader。
-
接下来,Sentinel挑选了一个从实例将其提升为主实例。
-
Sentinel重新配置老的主实例和另一个从实例,让他们从新的主实例哪里进行主从复制。
-
最后一步,Sentinel更新新主实例的信息,并通过频道__sentinel__:hello 向其他哨兵广播这些信息,从而让所有客户端获得新主实例的信息。
模拟主实例下线
手动关闭主实例下线。哨兵将提升新的主实例并完成了故障转移。
具体过程如下:
-
Sentinel-1发现主实例不可达。正如之前提到的ping包,如果ping命令超时,对应的服务器将被视为下线。不过这仅仅是哨兵的主观看法,即主观下线(subjectively down,Sentinel的 +sdown事件)。
-
为了防止虚假警报,标记主实例 +sdown 的哨兵会向其他哨兵发送请求,要求他们检查主实例的状态。只有多于
个哨兵认为主实例下线时,才会发生故障迁移,这被称为客观下线(objectively down,+odown)。 -
接下来,Sentinel-1 尝试执行故障转移,但是没有被选为 leader。
-
几乎是同一时间,Sentinel-2 也将主实例标记为 +sdown 和 +odown,且被选为执行故障迁移的leader。故障转移的后续与上一例相同。
那么leader是如何被选出来的呢?当一个哨兵标记 +odown后,投票开始;哨兵会开始从其他哨兵那里征集选票。每个哨兵只有一票,当另一个哨兵收到拉票请求时,如果它还没有投过票,则会接受请求并回复拉票哨兵;否则,则拒绝请求,并向其回复“刚刚已经把票投给了其他哨兵”,如果某个哨兵得到了大于等于最大值(quorum,哨兵数/2+1)张选票(包括它自己;哨兵在拉票前会先投给自己),那么这个哨兵则称为leader,如果没有哨兵当选,则再次进行上述步骤。
Cluster 集群
简要
由于Redis中所存储的数据增长速度很快,一个存储了大量数据(通常16GB以上)的Redis实例的处理能力和内存容量都会变成应用的瓶颈。随着Redis中数据集大小的增长,在进行持久化或主从复制时,也会越来越多地出现诸如延迟等问题。对于这种情况,水平扩展,或通过向Redis服务中增加更多节点来实现伸缩就成为了一种迫切的需要。
Redis Cluster 是一种开箱即用的解决方案,可以将数据集通过分区的方式分布到多个 Redis 主从实例中。
具体设计
Redis-cluster采用无中心结构,每个节点保存数据和整个集群状态,每个节点都和其他所有节点连接。
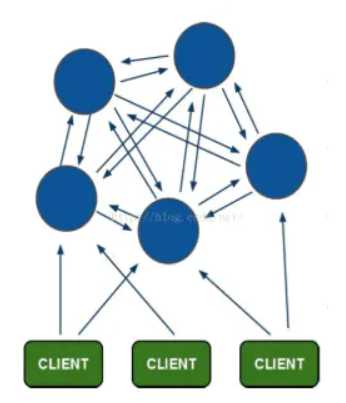
其结构特点:
-
所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
-
节点的fail是通过集群中超过半数的节点检测失效时才生效。
-
客户端与redis节点直连,不需要中间proxy层,客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
-
Redis-Cluster把所有的物理节点映射到[0-16383]slot上(不一定是平均分配),cluster 负责维护 node <-> slot <-> value。
-
Redis集群预分好16384个桶,当需要在 Redis 集群中放置一个 key-value 时,根据 CRC16(key)mod 16384 的值,决定将一个key放到哪个桶中。
a.redis cluster节点分配
现在我们是三个主节点分别是:A, B, C 三个节点,它们可以是一台机器上的三个端口,也可以是三台不同的服务器。那么,采用哈希槽 (hash slot)的方式来分配16384个slot 的话,它们三个节点分别承担的slot 区间是:
-
节点A覆盖0-5460;
-
节点B覆盖5461-10922;
-
节点C覆盖10923-16383.
获取数据:
如果存入一个值,按照redis cluster哈希槽的算法: CRC16('key')384 = 6782。 那么就会把这个key 的存储分配到 B 上了。同样,当我连接(A,B,C)任何一个节点想获取'key'这个key时,也会这样的算法,然后内部跳转到B节点上获取数据
新增一个主节点:
新增一个节点D,redis cluster的这种做法是从各个节点的前面各拿取一部分slot到D上,我会在接下来的实践中实验。大致就会变成这样:
-
节点A覆盖1365-5460
-
节点B覆盖6827-10922
-
节点C覆盖12288-16383
-
节点D覆盖0-1364,5461-6826,10923-12287
同样删除一个节点也是类似,移动完成后就可以删除这个节点了。
b.Redis Cluster主从模式
redis cluster 为了保证数据的高可用性,加入了主从模式,一个主节点对应一个或多个从节点,主节点提供数据存取,从节点则是从主节点拉取数据备份,当这个主节点挂掉后,就会有这个从节点选取一个来充当主节点,从而保证集群不会挂掉
上面那个例子里, 集群有ABC三个主节点, 如果这3个节点都没有加入从节点,如果B挂掉了,我们就无法访问整个集群了。A和C的slot也无法访问。
所以我们在集群建立的时候,一定要为每个主节点都添加了从节点, 比如像这样, 集群包含主节点A、B、C, 以及从节点A1、B1、C1, 那么即使B挂掉系统也可以继续正确工作。
B1节点替代了B节点,所以Redis集群将会选择B1节点作为新的主节点,集群将会继续正确地提供服务。 当B重新开启后,它就会变成B1的从节点。
不过需要注意,如果节点B和B1同时挂了,Redis集群就无法继续正确地提供服务了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号