回声消除的评价准则
(1)回声返回损耗增益
回声返回损耗增益(Echo Return Loss Enhancement,ERLE)是回声消除特有的评价准则,它表示回声信号$d(n)$与残留回声信号$e(n)$的比值,值越高性能越好。表达式为
$$\mathrm{ERLE}=10 \log _{10}\left\{\frac{\sum_{1}^{L} d^{2}(n)}{\sum_{1}^{L} e^{2}(n)}\right\}$$
(2)语音质量感知评价
语音质量感知评价(Perceptual Evaluation of Speech Quality,PESQ)算法是由ITU在2001年提出的一种新的语音信号质量客观评价算法,用来表达语音信号的频率和响度等物理特征。PESQ应用的是线性评分制,其分值取值范围在-0.5~4.5之间,PESQ的分值越高则代表语音信号的质量越好,在实际情况中,若PESQ的分值小于等于2分,则代表语音信号的质量较差。
(3)SuppFactor(能量衰落因子)
AEC后输出能量与对应麦克风信号能量的比值。
$$\operatorname{SuppFactor}=\frac{\mathrm{E}\left[|\mathrm{e}|^{2}(\mathrm{n})\right]}{\mathrm{E}\left[|\mathrm{x}|^{2}(\mathrm{n})\right]}$$
(4)cohde(输出信号e(n)与麦克风信号d(n)的频谱相关性)
该值越接近1,说明输出信号中保留的麦克风信号频谱越多。考虑到麦克风信号$d(n)$主要由回声信号$y(n)$和近端语音$v(n)$构成,因此只有近端单讲情况下cohde的值才能接近1,双讲情况下cohde的值在0.5~0.9(取决于回声信号在该帧的占比),当cohde接近0时说明输出信号几乎不包含任何近端语音和回声的频谱成分。其计算公式如下:
$$\begin{array}{l}
\mathrm{S}_{\mathrm{d}}=\mathrm{D}(\omega)\mathrm{D}^{*}(\omega) \\
\mathrm{S}_{\mathrm{c}}=\mathrm{E}(\omega) \mathrm{E}^{*}(\omega) \\
\mathrm{S}_{\mathrm{dc}}=\mathrm{D}(\omega) \mathrm{E}^{*}(\omega) \\
\text { Cohde }=\frac{\left|\mathrm{S}_{\mathrm{dc}}\right|^{2}}{\left|\mathrm{~S}_{\mathrm{d}} * \mathrm{~S}_{\mathrm{c}}\right|}
\end{array}$$
(5)cohxe(输出信号e(n)与远端参考信号x(n)的频谱相关性)
该值越接近0,说明输出信号中残留的远端参考信号频谱越少,回声消除越彻底,其计算公式如下
$$\begin{array}{l}
\mathrm{S}_{\mathrm{x}}=\mathrm{X}(\omega) \mathrm{X}^{*}(\omega) \\
\mathrm{S}_{\mathrm{c}}=\mathrm{E}(\omega) \mathrm{E}^{*}(\omega) \\
\mathrm{S}_{\mathrm{xc}}=\mathrm{X}(\omega) \mathrm{E}^{*}(\omega) \\
\text { Cohxe }=\frac{\left|\mathrm{S}_{\mathrm{xe}}\right|^{2}}{\left|\mathrm{~S}_{\mathrm{x}} * \mathrm{~S}_{\mathrm{e}}\right|}
\end{array}$$
(6)不同通话状态对应的参数指标
近端单讲(最大程度保持输出与麦克风信号一致)
远端单讲(最大程度抑制回声)
双讲(尽量抑制回声同时保留近端语音)
(7)语音短时客观可懂度
(8)AECMOS:回声损伤的语音质量评估指标(AECMOS: A SPEECH QUALITY ASSESSMENT METRIC FOR ECHO IMPAIRMENT)
传统上,声学回声消除器的质量是使用侵入式语音质量评估措施来评估的,例如 ERLE和 PESQ,或者通过进行主观实验室测试。前者与人的主观测量没有很好的相关性,而后者则耗费时间和资源来执行。Microsoft团队开发了一个神经网络模型来评估两个不同类别的通话质量下降:回声和其他来源的下降。其与人类主观质量评级的相关性表明,模型是准确的。我们的工具可以有效地用于衡量回声消除效果。 AECMOS 将作为 Azure 服务公开提供。(https://github.com/microsoft/AEC-Challenge/tree/main/AECMOS)
我们的模型称为 AECMOS,直接预测人类对处理后的回声信号的主观评级。它可用于评估 AEC 的端到端性能,并可非常准确地基于(退化)平均意见得分(MOS)估计对不同的 AEC 方法进行排名。模型架构是一个由卷积层、GRU(门控循环单元)层和dense层组成的深度神经网络。AECMOS使用根据ITU-T P.831,ITU-T Rec. P.832和ITU-T Rec. P.808指导获得的真实人类评级进行训练。
ERLE 只能在没有近端语音的安静环境中同时对回声和处理后的回声信号进行对比得到。而PESQ除了降噪后的信号外,还需要干净的语音参考。AECMOS 不需要为近端或远端提供干净的语音参考,也不需要安静的环境。
且ERLE和PESQ等指标通常与人类对回声退化质量的主观评价并没有很好的相关性,在存在背景噪音或双重谈话的情况下尤其如此。
AECMOS模型将三个信号作为输入:近端麦克风信号、远端信号和回波消除器的输出(也称为增强信号)。任务是评估增强信号的质量与人类主观评分量表。需要近端麦克风信号和远端信号来确定增强信号中是否包含回波或一些背景噪声。评估噪声抑制质量,无需近端参考信号。除了三个输入信号,AECMOS还采用可选的场景标记作为输入的一部分。此标记编码我们所处的三种场景中的哪一种:近端单话,远端单次通话或双端通话。对于在线部署,标记不是习惯于对于离线AEC模型评估,当场景信息可用,激活场景标记可改进模型性能。在生成数据集的过程中,我们区分了单通话和双通话场景。对于近端单一通话,我们要求整体质量。对于远端单一通话,我们要求提供回声等级。对于双重谈话,我们在两个单独的问题中询问了回声烦恼度和其他降级的评级.所有损伤均按退化类别等级进行评级(从1:非常恼人到5:难以察觉)。然后使用该等级来获得实施例的MOS标签。对于近端单一通话,回声标签设置为5,而对于远端单一通话,降级标签设置为5。该模型在64013个样本上进行训练,持续时间从3秒到14.5秒,平均8.2秒,总共145.8小时的数据。训练数据包括来自ICASSP 2021 AEC Challenge[13]的17个提交模型,总共14K音频剪辑。训练数据集按场景细分为:45.6%近端单端通话,26.7%远端单端通话,27.7%双端通话。测试集由InterSpeech 2021 AEC挑战赛提交的材料组成。总共有14名参赛者提交了300个双端通话、300个远端单端通话和200个近端单端通话示例的作品。此外,我们还包括4个我们自己的深度模型的增强信号以及4个基于数字信号处理的模型。通过这种方式,我们获得了总共17600个增强语音信号或55小时的数据。真实MOS标签是通过使用工具的众包收集的,其中我们为每个剪辑收集了5个投票。
网络模型
对于模型架构,我们探索了卷积模型。MOS预测相关性的标签合并GRU图层添加到模型中。表1显示了在开发模型时最佳性能的网络结构模型,对于网络而言,双讲情景构成了最严峻的挑战。如图所示在表4中,加入GRU层提高了模型性能,最主要的是提高了双讲下的判定。模型的输入是三个对数功率谱图的叠加,从近端、远端和增强信号获得。频谱图DFT大小为512,跳数大小为256个以16kHz采样的片段。最后,我们计算幂的对数。对于8秒的剪辑,这将导致541×257的输入尺寸。
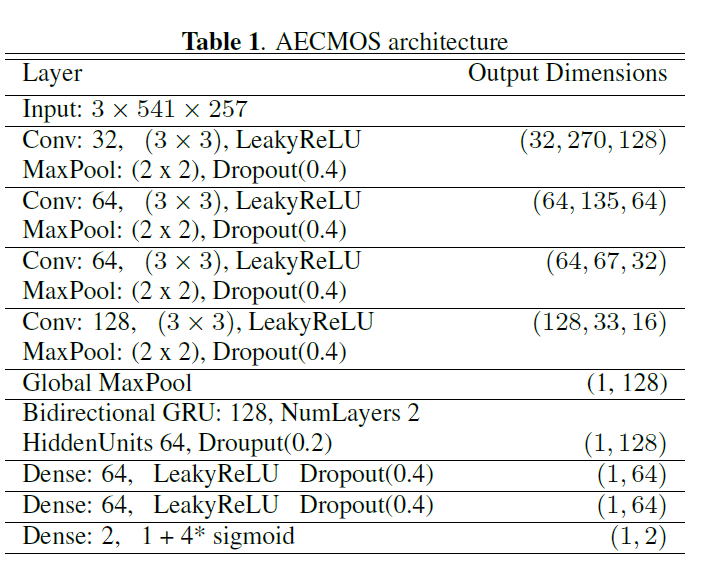
AECMOS网络结构
该模型以1-5的分数输出两个MOS预测:一个用于回声,另一个用于其他MOS,这些输出对应于专家所打的标签。
实验
我们通过测量我们的AECMOS预测和人类评级之间的相关性来评估我们模型的准确性。为了评估我们的模型,我们计算了AECMOS预测相对于真实MOS标签的PCC。对于每个远端单一通话示例,我们还计算ERLE、PESQ和eQUEST分数。如表2所示,在远端单一通话场景中,AECMOS的性能优于ERLE、PESQ和eQUEST(在150个宽带测试条件下进行评估)。对于近端单一通话场景,我们可以将我们的AECMOS与DNSMOS模型进行比较,该模型是为评估噪声抑制模型而开发的。AECMOS有一个比DNSMOS更困难的任务:评估回声和其他退化,并且彼此独立地进行。尽管如此,我们相信AECMOS在近端单一通话类别中具有很好的改进潜力。首先,DNSMOS在大约120000个音频剪辑上进行了训练,而AECMOS在训练中只看到了大约一半的音频剪辑,并且只有四分之一的音频剪辑(大约30000个)是接近结束的单个谈话剪辑。考虑到这一点,AECMOS的性能非常有希望提升。评估最具挑战性的场景是双关语场景。这里,模型需要同时但独立地评估单独的质量、回声和其他退化。
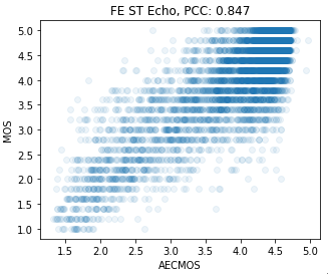
图2 每个剪辑的远端单一通话:AECMOS与MOS
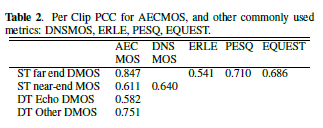
表2 AECMOS和其他常用的DNSMOS、ERLE、PESQ、EQUEST的PCC指标(相关性)
为了评估不同回声消除器的排序,我们计算每个模型的整个测试集的平均评级。我们计算的AECMOS评级也是如此。最后,我们计算了两者之间的斯皮尔曼等级相关系数(SRCC)。结果如表3所示。我们报告的远端单次通话场景中的SRCC为0.969,PCC为0.996,这是回声消除最常见的场景。我们注意到,表现最好的提交模型在比赛中彼此非常接近。
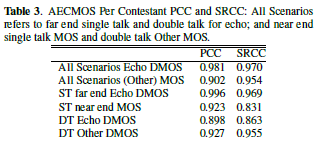
表3 AECMOS每位参赛者PCC和SRCC:所有场景指用于回声的远端单通话和双通话;以及近端单讲MOS和双讲其他MOS。
结论
我们的AECMOS模型提供了语音质量评估指标,这是准确、方便和可扩展的。可用于堆叠以非常好的精度对回波消除器进行排序,从而加速回波消除研究。在未来,我们希望进一步通过探索额外的数据扩充和学习自定义过滤器组。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号