AI回声消除(毕业论文篇)
1.《智能音箱中回声消除算法的研究与实现》
非线性声学模型
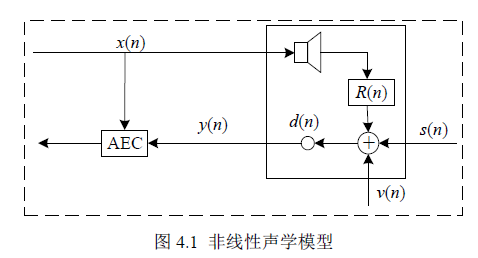
如图4.1中扬声器播放信号(远端信号)为$x(n)$,目标语音信号(*端说话人信号)为$s(n)$,背景噪声(*端噪声)为$v(n)$,麦克风接收信号(麦克风输出信号)$y(n)$由非线性回声信号$d(n)$($d(n)$为远端信号$x(n)$与房间冲激响应$h(n)$的卷积)、背景噪声和目标语音信号混合而成,即
$$y(n)=s(n)+d(n)+v(n)$$
在线性情况下,回声信号$d_{e}(n)$表示$x(n)$与智能音箱声学冲激响应$h_{R}(n)$的卷积,即
$$d_{e}(n)=h_{R}(n) * x(n)$$
通过以下两个步骤对$x(n)$引入非线性失真。首先,对$x(n)$采用硬限幅来模拟功率放大器的特性,表达式为
$$x_{\text {hard }}(n)=\left\{\begin{array}{ll}
-x_{\max } & x(n)<-x_{\max } \\
x(n) & |x(n)| \leq x_{\max } \\
x_{\max } & x(n)>x_{\max }
\end{array}\right.$$
然后采用无记忆sigmoid 函数模拟扬声器的非线性特性,表达式为
$$x_{\mathrm{NL}}(n)=\gamma\left(\frac{2}{1+\exp (-a \cdot b(n))}-1\right)$$
式中,$b(n)$的表达式为
$$b(n)=1.5 \times x_{\text {hard }}(n)-0.3 \times x_{\text {hard }}^{2}(n)$$
则非线性回声信号$d(n)$表示为$x_{\mathrm{NL}}(n)$与$R(n)$的卷积,即
$$d(n)=R(n) * x_{\mathrm{NL}}(n)$$
算法原理
从语音分离的角度来看,AEC 可以被认为是语音分离的问题,其研究目的是将麦克风接收的混合语音分别分离出来。有监督深度学*语音分离算法包括训练与分离两个阶段,其分离框图如图所示。
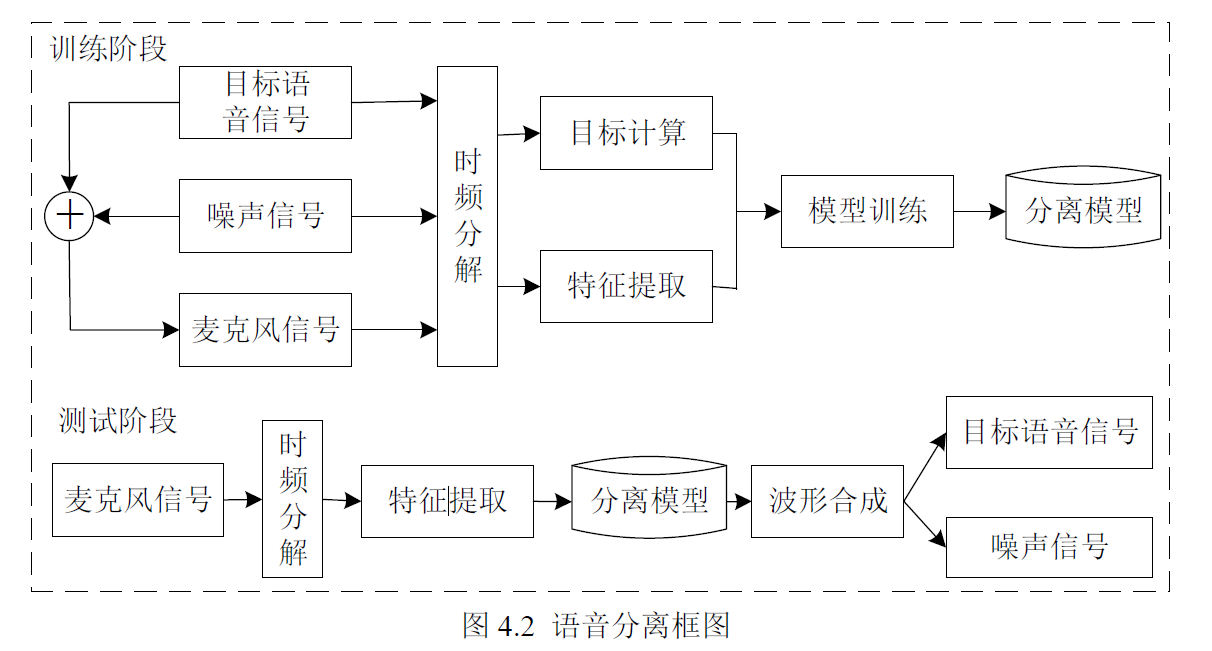
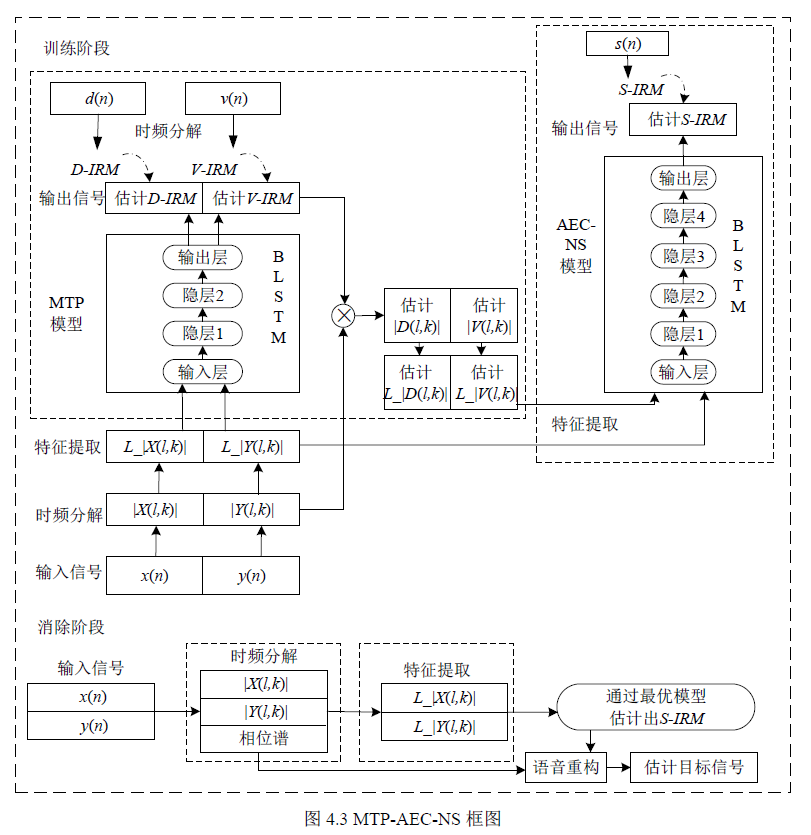
图4.3 为论文提出的MTP-AEC-NS 算法原理框图,该算法分为训练阶段与消除阶段,其中训练阶段包括多目标预处理模型(简记为MTP 模型)与回声消除和噪声抑制模型(简记为AEC-NS 模型)。该算法首先采用MTP 模型,同步估计出回声和噪声信号的幅度谱;然后将其作为AEC-NS 模型的输入特征,进而估计出目标语音信号的理想比例掩模;最后通过联合训练两个模型得到最优回声和噪声抑制模型。该算法不再需要单独的双端检测器、噪声抑制器和残留回声抑制模块,有效避免了非线性回声和非平稳噪声对智能音箱回声消除算法的影响。
1 训练数据
将麦克风接收信号作为输入数据。训练目标数据是目标语音信号或时频掩蔽,这些训练目标数据均属于先验知识,无法仅从麦克风接收信号中得到真实的目标语音信号与背景噪声信号,因此训练数据均是由纯净的目标语音信号和背景噪声信号在不同信噪比条件下人工混合而成的。
论文算法首先需要挑选纯净的目标语音数据与噪声数据,然后由这两种数据生成训练阶段需要的目标语音信号$s(n)$、扬声器播放信号$x(n)$、非线性回声信号$d(n)$、噪声信号$v(n)$和麦克风接收信号$y(n)$五种数据。
2 时频分解
采用STFT时频分解,它是模型的前端处理模块。在训练阶段,将全部信号首先分帧加窗处理,然后对信号每帧进行320 点STFT,进而计算出其幅度谱,由于STFT的对称特性,通常取161 个频点即可。
3 MTP 模型
有监督训练模型需要考虑输入特征、训练目标与学*器三个方面,下面对MTP 模型这三个方面进行详细介绍
(1)输入特征
有监督语音分离常用的特征为语音STFT变换后的幅度谱或对数幅度谱,由于语音本身既可以用时域波形表示,也可以用频域频谱来表示,两者之间的相互转换没有损失,因此通常不将STFT 视为特征提取过程,即选择幅度谱或对数幅度谱作为输入特征,可认为是直接使用语音的原始数据。
相对于语音分离系统,回声消除系统不仅可以采集到$y(n)$,还可以得到$x(n)$,且这两个信号均包含$d(n)$的成分,因此论文分别提取出这两个信号的对数幅度谱$L_|X(l,k)|$和$L_|Y(l,k)|,将其串联作为该模型的输入特征,进而输入的维数是161×2=322。
(2)训练目标
语音前端处理中的训练目标可以分为时频掩蔽和频谱映射两个大类。时频掩蔽的训练目标又分为两类,前一类是根据目标语音信号与背景噪声之间的联系构建一个幅度谱增益函数,将麦克风接收信号乘上这个时频掩蔽便可得到目标语音信号幅度谱;后一类是构建一个幅度—相位谱增益函数,通过乘上麦克风接收信号直接得到目标语音信号频谱。所以时频掩蔽训练目标算法不是直接估计出目标语音信号,而是通过模型来估计出时频掩蔽,再通过这个时频掩蔽得到目标语音信号。常用的时频掩蔽训练目标有:理想比例掩模(Ideal Ratio Mask,IRM)、理想二值掩模、频谱振幅掩模、相位敏感掩模和复数域的理想比例掩模等;频谱映射训练目标是直接将目标语音信号映射到目标语音信号幅度谱或频谱。
采用IRM作为训练目标,它表示训练目标的能量在混合的$s(n)$、$d(n)$和$v(n)$中所占的比例。则回声信号理想比例掩模$D_IRM(l, k)$和噪声信号理想比例掩模$V_IRM(l, k)$分别表示为
$$\begin{array}{l}
D_{-} \operatorname{IRM}(l, k)=\sqrt{\frac{D^{2}(l, k)}{S^{2}(l, k)+D^{2}(l, k)+V^{2}(l, k)}} \\
V_{-} \operatorname{IRM}(l, k)=\sqrt{\frac{V^{2}(l, k)}{S^{2}(l, k)+D^{2}(l, k)+V^{2}(l, k)}}
\end{array}$$
式中,$S^{2}(l, k)$、$D^{2}(l, k)$和$V^{2}(l, k)$分别表示$s(n)$、$d(n)$和$v(n)$的短时谱能量。
(3)学*器
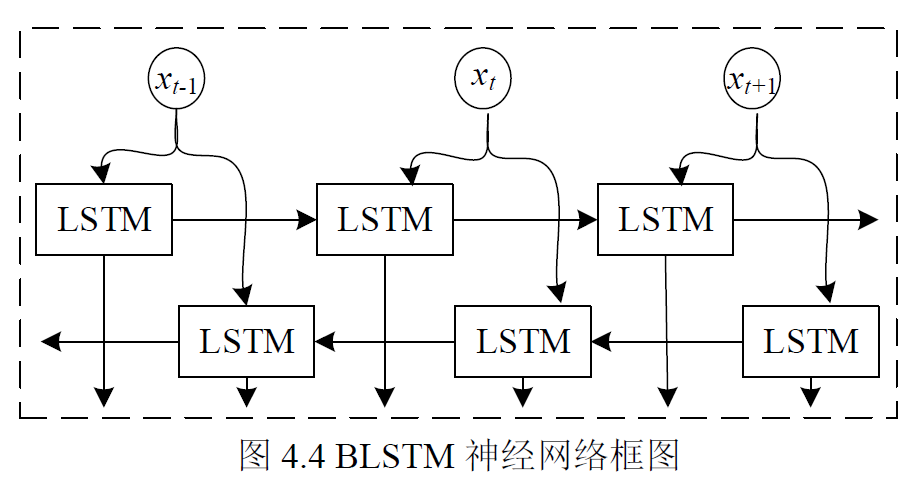
论文采用BLSTM神经网络作为学*器,如图4.4 所示,它包含两个单向长短时记忆(Long Short Term Memory,LSTM)神经网络,LSTM 是循环神经网络(RecurrentNeural Network,RNN)的一种变体,可以解决传统RNN 梯度消失和爆炸的缺陷,它通过在记忆单元中引入门控机制,进而可以选择性地保留上下文的记忆数量,减少网络深度和缓解梯度消失现象。
该算法通过MTP 模型,将输入的声学特征共享底层网络,同步估计出回声信号理想比例掩模$\hat{D}_{-} \operatorname{IRM}(l, k)$和噪声信号理想比例掩模$\hat{V}_{-} \operatorname{IRM}(l, k)$,即
$$\begin{array}{l}
\hat{D}_{-} \operatorname{IRM}(l, k)=f\left(\alpha\left(L_{-}|X(l, k)|, L_{-}|Y(l, k)|\right), \theta\right) \\
\hat{V}_{-} \operatorname{IRM}(l, k)=f\left(\alpha\left(L_{-}|X(l, k)|, L_{-}|Y(l, k)|\right), \theta\right)
\end{array}$$
式中,$α$ ,$θ$表示学*器参数,$f$表示学*器。并将其分别与$y(n)$的幅度谱逐点相乘,进而估计出回声信号幅度谱$|\hat{D}(l, k)|$和噪声信号幅度谱$|\hat{V}(l, k)|$,即
$$\begin{array}{l}
|\hat{D}(l, k)|=\hat{D}_{-} \operatorname{IRM}(l, k) \cdot *|Y(l, k)| \\
|\hat{V}(l, k)|=\hat{V}_{-} \operatorname{IRM}(l, k) .^{*}|Y(l, k)|
\end{array}$$
4 AEC-NS 模型
AEC-NS 模型同样包括输入特征、训练目标和学*器。
该模型首先将 MTP 模型输出的$|\hat{D}(l, k)|$与$|\hat{V}(l, k)|$归一化后提取对数幅度谱$L_|\hat{D}(l, k)|$与$L_|\hat{V}(l, k)|$;再与MTP模型提取的特征$L_|X(l,k)|$与$L_|Y(l,k)|$串联起来作为该模型的输入特征,因此其输入维数是161×4=644;然后采用目标语音信号理想比率掩模$S_IRM(l, k)$作为该模型的训练目标,表示为
$$S_{-} \operatorname{IRM}(l, k)=\sqrt{\frac{S^{2}(l, k)}{S^{2}(l, k)+D^{2}(l, k)+V^{2}(l, k)}}$$
最后采用BLSTM 作为学*器。该模型通过输入的声学特征直接得到估计的目标语音信号理想比率掩模$\hat{S}_{-} \operatorname{IRM}(l, k)$,实现联合抑制回声和噪声。
5 模型训练
论文将两个模型看作一个整体神经网络,首先通过联合训练两个模型使其向着一个方向优化,并消除模型分别训练过程中产生的不一致问题,进而得到最优回声和噪声抑制模型;然后对网络的中间层也添加训练目标约束,使计算速度加快,并且避免梯度消失现象;最后采用自适应冲量估计(Adaptive Moment Estimation,Adam)优化器和均方误差损失函数训练网络,损失函数表示为
$$J_{\mathrm{MSE}}=\frac{1}{N} \sum_{n=1}^{N} \sum_{l, k}\begin{array}{l}
\left(\left(D_{-} \operatorname{IRM}(l, k)-\hat{D}_{n} \operatorname{IRM}(l, k)\right)^{2}+\right. \\
\left(V_{-} \operatorname{IRM} M_{n}(l, k)-\hat{V}_{-} \operatorname{IRM}(l, k)\right)^{2}+ \\
\left.\left(S_{-} \operatorname{IRM}(l, k)-\hat{S}_{n} \operatorname{IRM_{n}}(l, k)\right)^{2}\right)
\end{array}$$
式中,N是训练样本的个数。
6 消除阶段
将扬声器播放信号$x_{c}(n)$和麦克风接收信号$y_{c}(n)$进行STFT,得到幅度谱$\left|X_{c}(l, k)\right|$和$\left|Y_{c}(l, k)\right|$,并提取$y_{c}(n)$的相位信息$e^{j \angle Y_{c}(l, k)}$;再分别提取对数幅度谱$L_{-}\left|X_{c}(l, k)\right|$和$L_{-}\left|Y_{c}(l, k)\right|$作为特征输入到训练好的模型中,进而得到估计的目标语音信号理想比率掩模$L_{-}\left|S_{c}(l, k)\right|$,即
$$\hat{S}_{c-} \operatorname{IRM}(l, k)=f\left(\alpha\left(L_{-}\left|X_{c}(l, k)\right|, L_{-}\left|Y_{c}(l, k)\right|\right), \theta\right)$$
通过与$\left|Y_{c}(l, k)\right|$逐点相乘来获得估计的目标语音信号幅度谱
$$\left|\hat{S}_{c}(l, k)\right|=\hat{S}_{c-} \operatorname{IRM}(l, k) . *\left|Y_{c}(l, k)\right|$$
采用麦克风接收信号的相位谱$e^{j \angle Y_{c}(l, k)}$*似目标语音信号的相位谱,进而得到估计的目标语音信号频谱为
$$\hat{S}_{c}(l, k)=\left|\hat{S}_{c}(l, k)\right|.* e^{j \angle Y_{c}(l, k)}$$
最后,应用逆短时傅里叶变换重新合成估计的时域目标语音信号$\hat{s}(n)$。
2.基于WebRTC 回声消除的音频系统研究与实现(水文)
WebRTC 整体架构
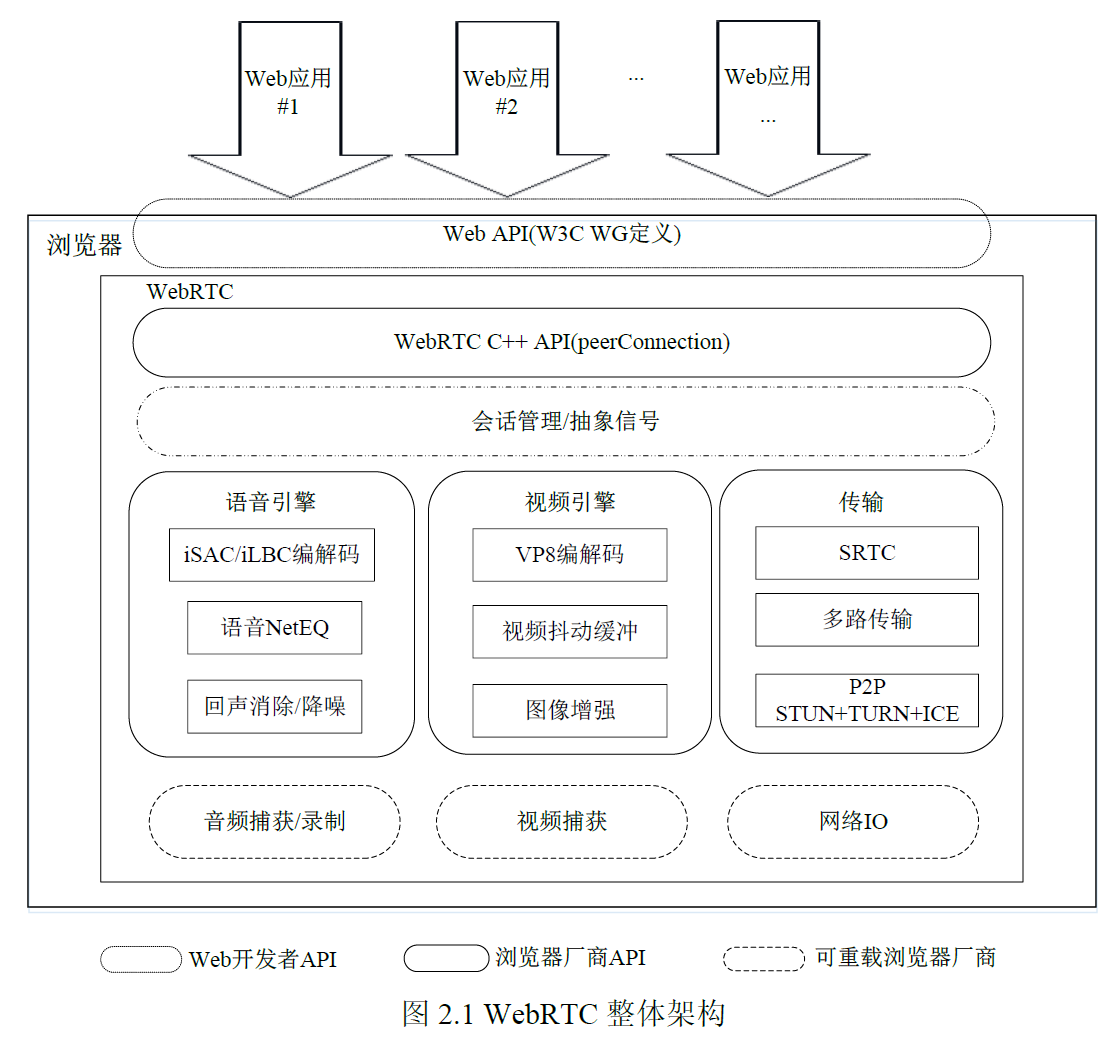
WebRTC 架构模型包括Web 应用、浏览器和Web API 三大模块。
1. Web 应用(Your Web App)
开发人员可以直接调用Web API 开发某些应用,如音视频应用、电子商务应用及娱乐资讯运用等。
2. Web API
包含用于在网络上进行实时通信的基本组件。有了这些组件,开发人员就可以通过访问需要的API 对应地创建Web 应用程序。
3. WebRTC C++ API
WebRTC C++ API 是面向浏览器厂商的本地C++ API。虽然各个浏览器厂商的实现方式不同,但都是严格按照W3C 标准执行。
4. 会话管理/抽象信号
会话管理/抽象信号是一个抽象的会话层,用来提供建立会话和会话管理,以便把协议的会话实现留给应用开发者。由于WebRTC 提供实时的音视频传输,采用了RTP(Real-time Transport Protocol)协议栈,即RTP/RTCP(Real-time TransportControl Protocol)等相关的协议,从而提供实时传输功能和流量控制作用。
5. 语音引擎
语音引擎的主要任务是回声消除(Acoustic Echo Cancceler,AEC)和降噪(Noise Reduction,NR)。回声消除是一种改善声音质量,消除产生的回声或防止其发生的方法。降噪是从信号中去除噪声的过程。音频机制主要分为iSAC 和iLBC 两大类编解码器。iSAC 编解码器代表由Global IP Solutions 开发的宽带音频编解码器。该编解码器适用于音频流,并于2011 年6 月成为WebRTC 技术的一部分。Global IPSolutions 还是iLBC 编解码器的创建者。该窄带音频编解码器适用于IP 上的语音通信。
6. 视频引擎
视频引擎负责图像增强和视频抖动缓冲。VP8 编解码器是视频引擎的主要视频压缩格式,目前得到Chrome,Mozilla 和Opera 的支持。图像增强是通过使用某种软件进行操作来提高数字图像质量的过程,包括明暗度检测、降噪处理等功能。视频抖动缓冲器分为抖动和缓冲两部分。抖动模块主要提供稳定渲染视频并显示的效果。缓冲模块主要处理异常情况,如媒体流出现丢包、乱序、延迟到达的情况。
7. 传输机制
传输机制负责SRTP(Secure Real-time Transport Protocol,安全实时传输协议),P2P(Peer-to-Peer)和ICE 交互式连接建立。
WebRTC 回声消除技术
语音引擎模块,它的主要处理过程是音频数据采集->编码->发送->接收->解码->播放。在此过程中,回声是影响通话质量的重要因素。
WebRTC 的回声消除算法AEC主要包括三个重要模块,分别是回声延迟估计模块、线性自适应滤波器模块以及非线性处理(NonLinearProcessing,NLP)模块。如图3.1是WebRTC 回声消除模块框架图。
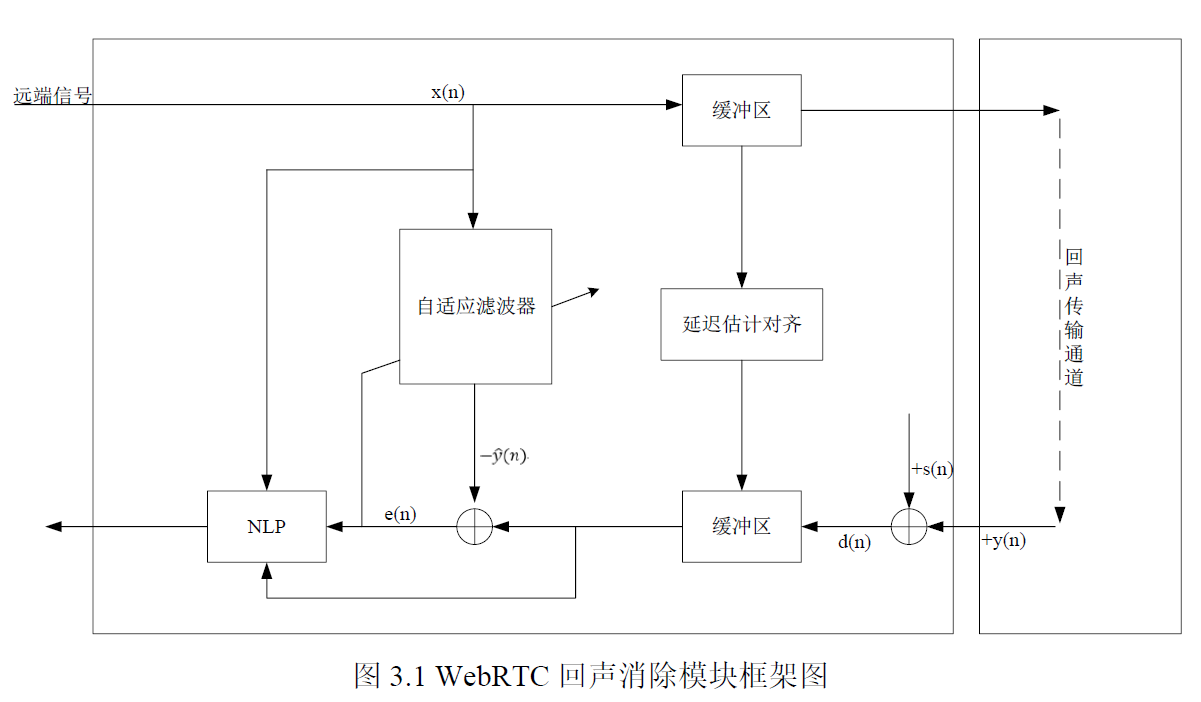
1. 回声延迟估计
在AEC 处理前,需确保多路信号延时同步,例如*端信号中包含的回声信号和模拟输入信号,否则无法进一步进行回声消除工作。由于系统差异性,各个终端用户的延时是不一样的,如手机用户和PC 用户,有的系统延时相对固定,有的则是变化的,因此回声延时估计模块是AEC 的组成部分之一。
2. 线性自适应滤波器
缓冲区将处理的语音信号进行延迟估计对齐后,接下来回声消除器中的线性自适应滤波器就可以进一步处理包含对应回声的*端语音信号。WebRTC 自适算法通过在频域自适应滤波器上对此信号进行分块处理,得到估计的回声信号。
3. 非线性处理
随着自适应线性声回波的发散性,在双端说话过程中会产生非线性声回波。由于*端语音与残余的非线性回声混合在一起,对非线性回声的抑制降低了*端语音的质量,有时还会导致部分语音失真。传统的线性AEC 算法难以消除非线性回声,因此一些学者开始研究基于非线性模型的AEC 算法。在频域使用非线性函数的方法计算不同频率下的抑制系数,实现对非线性回波抵消的精确调整。可采用一种变步长分块频域自适应滤波(VSS-PBFDAF)方案来消除免提语音通信设备的声回波。具体来讲是为了减小双向通话过程期间的非线性回波,引入一组针对不同频率的不同步长,根据通话双方的发散程度来调整收敛速度。然后采用频域非线性回波处理(frequency-domain nonlinear echoprocessing,FNLP)抑制残余的非线性回波,保证*端语音的质量。可使用二阶Volterra 级数展开式建模的非线性均衡器设计。在实时性方面,基于频谱校正的非线性声回波抑制算法以其计算复杂度低、效果好等优点被广泛应用。
3.会议电话中的实时回声消除算法研究与实现
基于DNNs 的回声消除算法(效果较差)
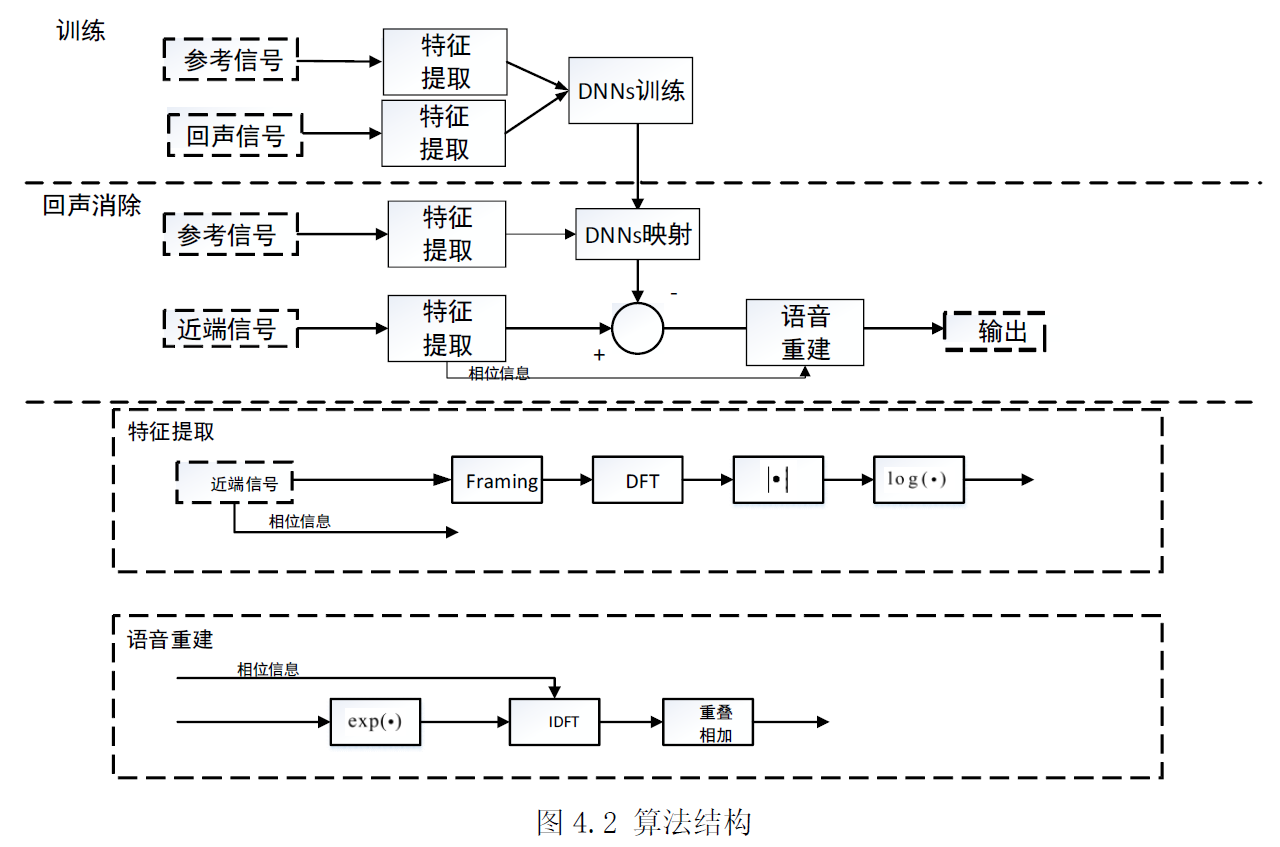
训练阶段,利用DNNs 的学*能力学*参考信号特征到回声信号特征之间的映射关系。处理阶段,网络依据输入的参考信号,构建出对应的回声信号,将其从*端信号中消除。特征可选择时域能量、log 频谱等方便重构信号的特征。对时域能量和log 频谱特征都进行过试验测试,结果表明,两者都能够使网络充分学*参考信号和回声信号之间的映射关系,最后的结果从指标上看,相差不大,但是利用时域能量作为特征学*出的网络映射出的回声,经过消除后,残余回声的毛刺相对大一些,故后续的实验使用的是log 频谱特征。分帧时帧长取512,使用效率最高的1/2重叠,使用汉宁窗,这三个参数是语音信号处理中较为常用的一组预处理参数,在本章的模型中,根据回声尾长来相应的确定帧长和帧移,但受限于研究时间等因素,本文没有对这一块进行深入研究、验证,直接使用了一组常用参数。
特征提取阶段。先对信号进行分帧、加窗预处理,用$X(k,l)$表示参考信号$x(n)$经过分帧、DFT 变换后的频域对应值,$l$为帧索引,$k$为频率索引。一帧的信号log谱可以表示为:
$$\mathbf{X}(l)=[\log (|X(1, l)|), \log (|X(2, l)|), \ldots, \log (\mid X(\text { len }, l) \mid)]^{T}$$
len 为频点数,本文中,DFT 为512 点,利用频域数据的共轭对称性减少计算量,len为512/2+1=257。
房间冲激会导致回声信号特征的时间变化,考虑到临*帧之间的信息相关性,需要将相邻帧的log 谱特征包含到用于训练的特征向量中。经过实验验证,若不用临*帧,只用当前帧特征进行映射,最后的效果确实相对较差。因此,用于DNNs 网络映射的输入特征矩阵为:
$$\tilde{\mathbf{X}}(l)=[\mathbf{X}(l-d), \ldots, \mathbf{X}(l), \ldots, \mathbf{X}(l+d)]^{T}$$
$d$表示每一边包含的相邻帧数,本章中,$d$取2,若按照回声尾长来算,当路径冲击为4096 阶时,$d$应为4096/512=8,但经过反复测试,$d$为8 时效果并不是最好,故d 的具体取值依情况而定,本章的$d$值是多次测试后取得一个经验值。此时,输入特征的维度为:257*5=1285。尽管根据声学回声的生成过程来看,当前帧回声信号主要由先前帧参考信号引起,但当前帧之后的参考信号为频谱映射提供了有用信息,故仍是需要的。经过验证,使用两侧相邻帧特征进行映射的效果确实要好于只使用一侧相邻帧特征进行映射的效果。
网络输出为257 维的当前帧回声log 谱:
$$\hat{\mathbf{Y}}(l)=[\log (|\hat{\mathbf{Y}}(1, l)|), \log (|\hat{\mathbf{Y}}(2, l)|), \ldots, \log (\mid \hat{\mathbf{Y}}(\text { len }, l) \mid)]^{T}$$
在经典算法中,自适应滤波器主要在单远端模式下对路径冲击进行辨识,双端情况下由于*端干净语音的干扰,滤波器不能进行自适应更新。本章的网络同样如此,训练只能在单远端模式下即输入输出分别为参考信号和回声时进行。
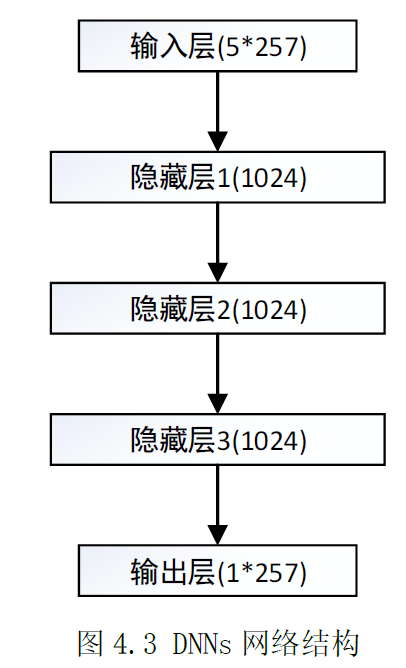
神经网络结构
DNNs 网络包括三个隐藏层,如图4.3 所示。每个训练样本的输入是5帧257 维特征数据,共1285 个输入单位,输出是一帧中257 维特征,对应257 个输出单元。每个隐藏层包括1024 个隐藏单元。DNNs 网络的层数和每层的单元数均为多次测试后确定的经验值,在不同场景下,可能会有差异,在本章的结构中,经过多次测试发现,刻意增加单元层数或每层单元数,不会有显著的性能提升,本章使用的这组网络参数是使得各组测试数据的测试结果相对平稳的一组数据,各组测试数据的处理效果大致相*。
目标函数基于均方误差,为实际回声log 谱和估计回声log谱的误差平方和。
实验结果
(1)单远端模式
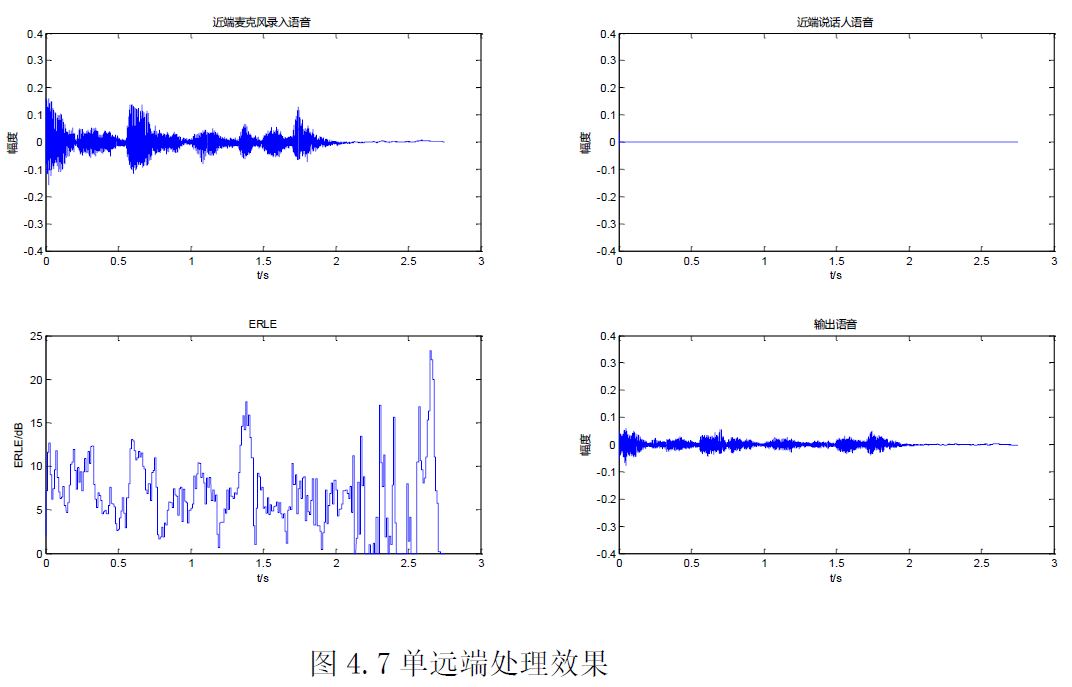
处理后的输出语音有明显的回声残留,实际听感方面,也可以明显的听到,但残留回声幅度相对原始的*端语音已小了很多,说明该模型在单远端模式下可以对回声进行较大的消除,虽然消除的不是很干净,但是效果还是比较明显的。
(2)双端模式

双端模式下,模型能够在保持*端说话人语音失真较小的前提下,对回声进行一定程度的消除。
基于LSTM-RNNs 的回声消除算法(建议看原文)
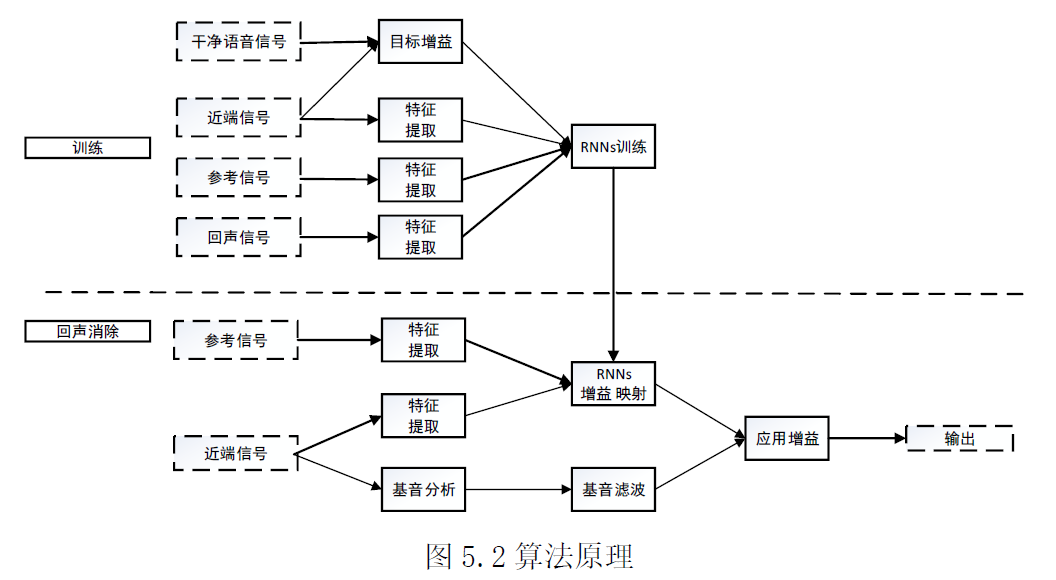
干净语音信号为*端说话人信号,*端信号为麦克风输出信号,参考信号为远端信号,回声信号为远端信号与房间冲激响应的卷积
算法原理
算法原理如图5.2 所示,训练阶段,利用构建的RNNs网络学**端信号特征、回声信号特征与目标增益之间的非线性关系。回声消除阶段,根据输入信号的特征,映射出对应的增益,然后将增益应用在*端信号上,进行回声消除。大部分抑制是在低分辨率频谱包络上使用循环神经网络映射出的增益进行的。这些增益是理想比值掩模(IRM)的平方根。为降低低分辨率频谱包络的不利影响,使用一个基音梳状滤波器来衰减基音谐波之间的回声。
算法并不直接估计*端干净语音信号,而是估计理想的临界频带增益,它具有在 0 ~1 之间有界的显著优势。选择将频谱划分为与Opus 编解码器相同的Bark尺度*似值。也就是说,频带在高频时遵循Bark 标度,但在低频时始终至少为 4 个频点。使用三角形带而不是矩形带,峰值响应位于频带之间的边界。这产生总共18 个频带。因此,网络在[0,1]范围内仅需要 18 个增益输出值。
令%w_{b}(k)%表示频带b在频点k的幅度,则$\sum_{b} w_{b}(k)=1$。对于频域信号$X(k)$,一个频带内的能量为:
$$E(b)=\sum_{k} w_{b}(k)|X(k)|^{2}$$
每个频带的对应增益$g_{b}$定义为:
$$g_{b}=\sqrt{\frac{E_{s}(b)}{E_{x}(b)}}$$
其中,$E_{s}(b)$表示*端干净语音的能量,$E_{x}(b)$表示*端语音(*端干净语音+回声)的能量。下式所示的内插增益被应用于每个频点k:
$$\mathrm{r}(k)=\sum_{b} w_{b}(k) g_{b}$$
特征提取
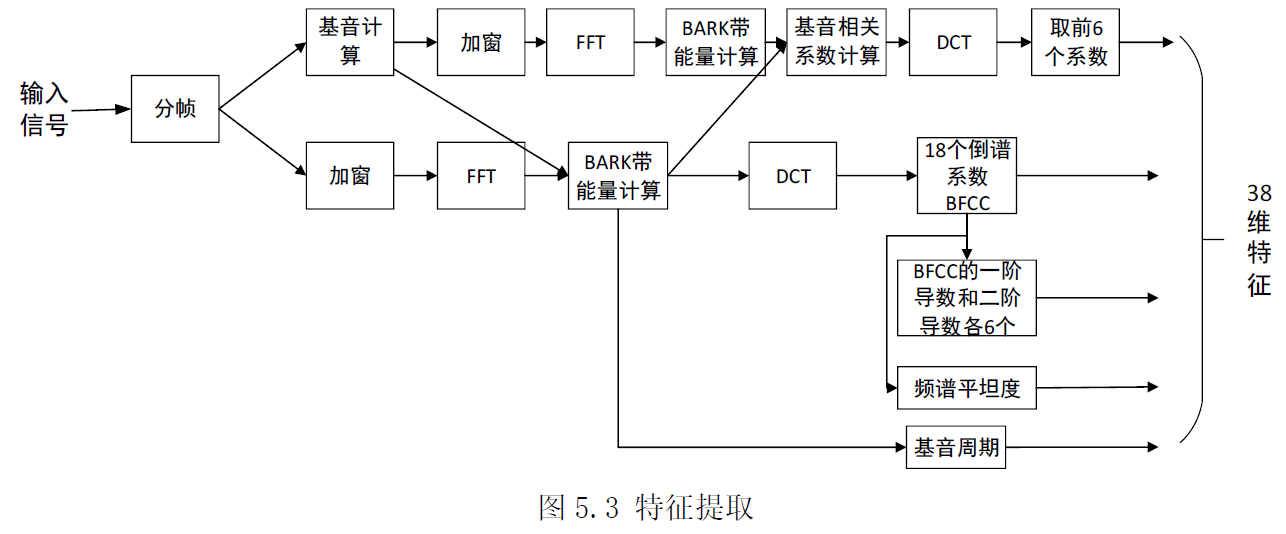
对于每帧信号,按上图所示步骤提取38 维特征。处理过程中,帧长取10ms,使用1/2 重叠,使用Vorbis 窗
输入信号经过分帧、加窗、FFT,求得对数谱,并应用DCT,求得18 个Bark 频率倒谱系数(BFCC)并据此计算6 个BFCC 的一阶导数和二阶导数。除此之外,在频带间计算基音相关系数的DCT,并将前 6 个系数包括进特征集中。最后,将基音周期以及可以帮助进行语音活性检测的频谱非平稳性度量包含进特征集中。最终提取的38 维特征向量依次为:18 维BFCC 参数,6 维BFCC 一阶导数,6 维BFCC 二阶导数,6 维基因相关系数,基音周期,频谱非平稳性度量。
神经网络结构
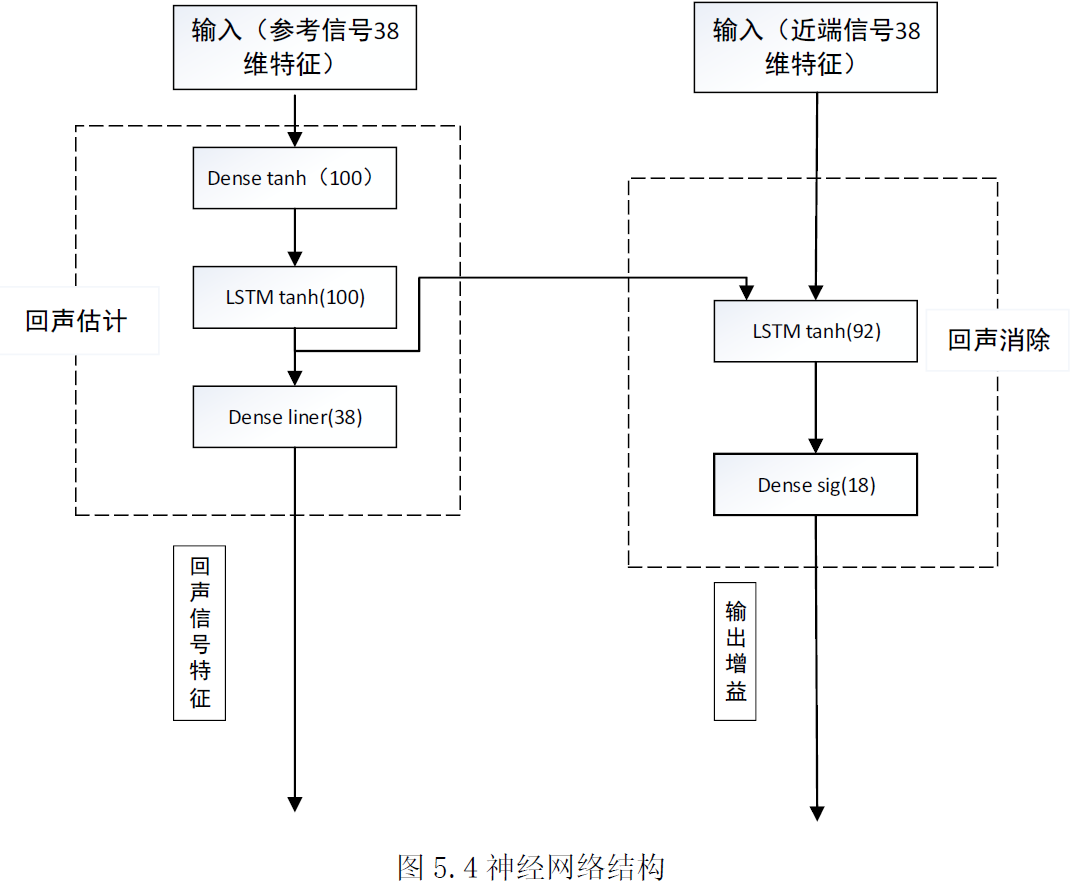
对于增益估计值$\hat{\mathrm{g}}_{b}$和实际增益$\mathrm{g}_{b}$,使用以下损失函数进行训练:
$$\operatorname{loss} 1=\sum_{\mathrm{b}}\left(\mathrm{g}_{b}^{\gamma}-\hat{\mathrm{g}}_{b}^{\gamma}\right)^{2}$$
其中,指数$\gamma$是一个感知参数,它控制如何积极地抑制回声。取$\gamma=1/2$提供了良好的折衷,并且相当于最小化能量均方误差。有时,在特定频带可能没有语音和回声。这常发生在当*端无说话语音或当信号被低通滤波后的高频处。当发生这种情况时,忽略该增益的损失函数以避免损害训练过程。
对于网络的回声输出$\hat{y}_{i}$,记实际值为$y_{i}$,使用如下函数作为回声估计部分的损失函数:
$$\operatorname{loss} 2=\sum_{\mathrm{i}}\left(y_{i}-\hat{y}_{i}\right)^{2}$$
其中,$i$为特征参数索引,网络最终的误差为两部分损失之和:
$$\operatorname{loss}=\operatorname{loss} 1+\lambda \operatorname{loss} 2$$
其中,$\lambda$为权重系数,本实验中取0.05。
实验结果
(1)单远端模式
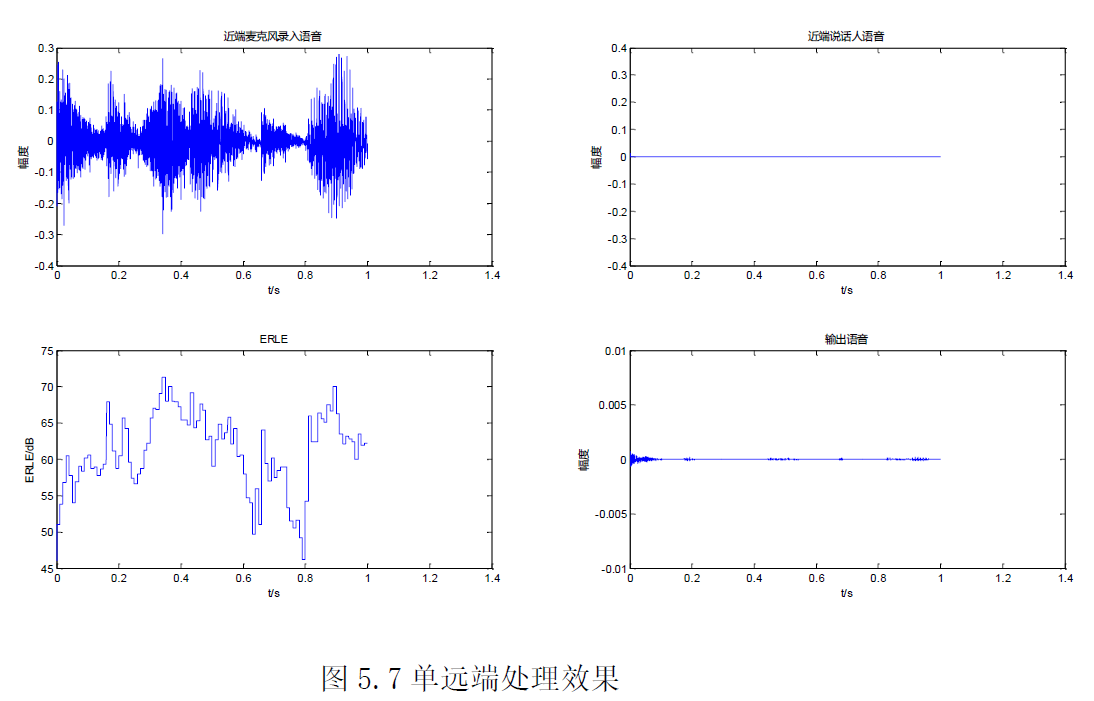
回声消除的效果都是相当好的,回声残余很小,几乎可以忽略。实际听感上也是如此,几乎听不到有回声残留。说明,该模型在单远端下的消除效果是较好的,可以将回声消除的较为干净。
(2)双端模式
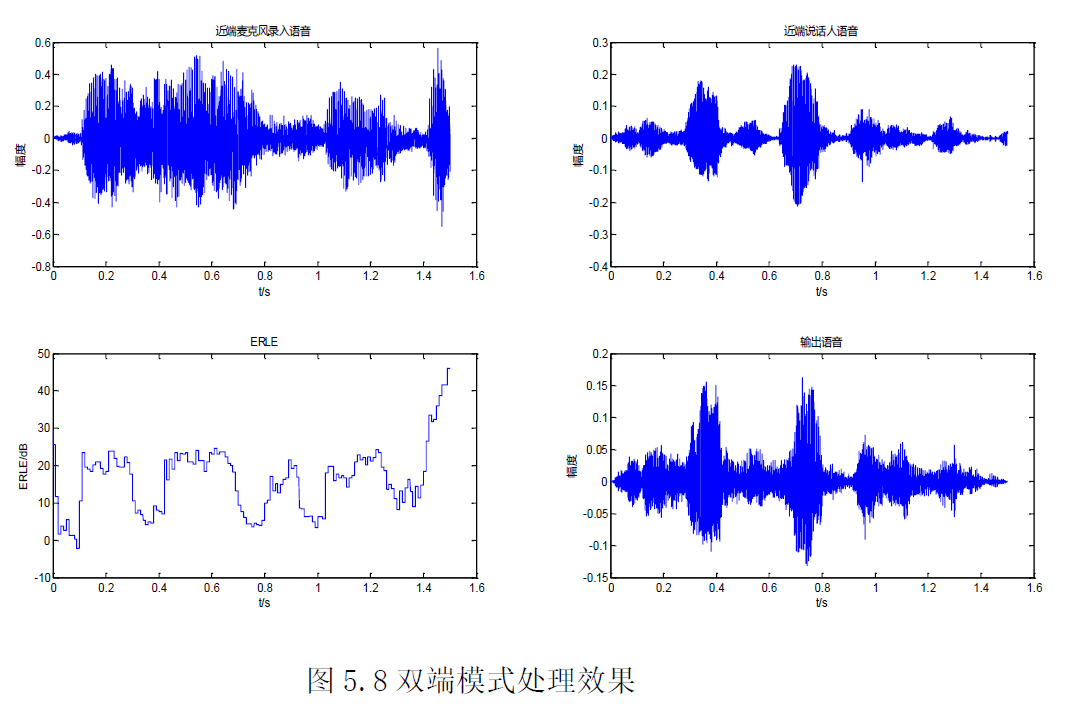
双端模式下,回声的消除效果不及单远端模式下的效果,回声的残留相对单远端模式下要大一些,但其幅度相对原始回声要小很多,在*端说话人声音较大的地方,几乎被淹没,*端说话人语音有失真,但不大。实际听感方面,可以感受到一点*端说话人的失真,但程度较低,残留回声可以听到,但较小,不影响*端说话人语音的可懂度。总体而言,双端模式下,模型可以在对*端语音造成较小失真的前提下,对回声进行较大的消除。
参考文献:
[1] 张伟. 智能音箱中回声消除算法的研究与实现[D]. 辽宁工业大学, 2020.
[2] 基于WebRTC回声消除的音频系统研究与实现_沈励芝
[3] 陈林. 会议电话中的实时回声消除算法研究与实现[D]. 东南大学, 2019.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号