结对编程,快乐你我 #3
| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | 2021春季软件工程(罗杰 任健) |
| 这个作业的要求在哪里 | 结对编程第三次作业 |
| 这个作业的GitLab项目地址在哪里 | 项目地址 |
| 参与结对编程的是哪两位 | 3808 3050 |
一、前言
为什么要结对编程?怎么样才能做到1+1>2?我们认为最关键的一点是向对方解释自己的想法和做法,这也许会使结对编程完成任务的整体时间变长,但是这对于减少程序中的bug是有帮助的,至少明确了自己在干什么以及为什么要这么做,和费曼技巧有异曲同工之妙(?
thinking out loud and explaining the problem or a solution to someone is the simplest way to tackle a problem. —— Richard Feynman
二、结对项目实践反思
1.实践中出现的问题
针对前面两个阶段中出现的问题,分析问题的特征、产生的根源和对质量的影响程度
本次结对主要出现以下几个问题:
-
对于编程中潜在假设的记录与删除
在大规模程序中,对可读性影响最大的就是大量的“隐藏假设”,所谓潜在假设就是指,从这一处的代码中看不出来,但是其实这段代码能正常运行是有前提条件的,是我们“假设”了某个条件的结果。比如在Issue没有Close之前,我们预判他可能是什么结果,并依据这个假设去写代码。此时我们往往直接在代码里加上一个
Todo: Check issue xxx,并且根据假设往下写(这里其实又有另一个问题)。但当Issue真的解决之后,我们却很少去检查这些潜在假设,也没有删除不需要的注释,这直接导致了代码和注释的不一致性,严重影响了我们的开发。
通过阅读博客,我们发现,我们没有利用好GitLab的项目管理功能,现在看来,这些假设就该统统丢到issue区,这才是一个工程项目应有的开发方式。而我们目前的Todo记录则有一种工业革命前原始手工作坊(x)的感觉,更像是做作业而不是做工程。
这一条极大的影响了后期Debug和检查代码的时间 -
结对编程遇到问题讨论时的把控能力
此问题在第二阶段表现的较为明显,基本情况是,正在编程过程中,驾驶员(特别是某W姓同学驾驶时)突然想起某个Issue和自己正在写的代码有关,遂与领航员讨论,领航员也去看Issue,工作暂停,两人开始商议,商议良久无果,最终作出结论等Issue出来结果再说。期间可能会产生多个Issue的连环反应,极大耽误了进程。
问题的根源其实不能简单的怪指导书,而是W姓同学太容易被分散注意力了,而领航员可能也没有意识到这个问题,因为领航员的工作可以允许同时对项目的大体架构进行思考,因此延误了进程,导致工作时间延长,极大的影响了项目质量。
对于这种问题,首先W姓同学不能开小差,在写一个功能块时就不要去想别的。二来是两人的沟通其实也有一定的问题,Q姓同学和W姓同学都倾向于采用“说服”和“桥梁”两种沟通方式,导致在关键时刻难以直接拍板,反而造成了时间的延误。
2.需求分析实践体会
总结结对项目中的需求分析实践体会,并分析哪些bug是因为需求分析不足而带来的
W姓同学认为,本次软工结对编程项目其实是对标准的解读与实现,因此需求分析其实是对标准的解读。而我们经常把这一“需求分析”过程和“架构设计”过程混在一起进行,经常边读指导书边考虑程序的整体结构。这固然有指导书比起需求更像标准的原因,但更多的是我们的阶段划分不明确,带来的问题就是对指导书的理解不足,在实际实现中与标准产生偏差。
本次作业过程中最大的Bug,就是对标准解读不足产生的。由于没有深究“覆盖”的定义,想当然的按照自己的想法进行实现,导致后期为了修复引入了大量问题,如果本次作业有第三次,那么想必代码是要经历一次局部的重构的。虽然指导书没有事先明确“覆盖”的定义也是原因之一,但是客户的需求也是模糊不清的,还正好就和软工的目的对上了——应对客户突然提出的在某个地方的不一致理解。实测这点做的不太好,还拿这个覆盖为例,反应过来后没有根据客户的新理解进一步揣测圣意(x),错误判断了不同类型文件覆盖时的预期行为,为了满足我们自己的理解,实现这个错误的预期行为,导致新老系统并行使用,加了很多特判。
此外,还有很多问题是“想当然”导致的,W姓同学因为曾经使用过Ubuntu系统,下意识的在某些指令是否进行重定向的时候没有紧贴指导书。而Q姓同学在一开始也没有注意到这一点,导致了很多不必要的讨论,延误了项目的进程。直到后来W姓同学在和其某紧贴指导书的D姓室友交流中才发现这一问题,Q姓同学后期也对指导书更加了解,能很好地指出W姓同学的思维误区。
3.架构设计实践体会
总结结对中的架构设计实践体会,描述通过改进设计来提高程序的性能改进的思路和方法,并分析哪些bug是因为架构设计不足(特别的,需求变化)而触发的bug
一个好的架构设计只是开始,不断的重构才能让架构保持活力。我们结对编程项目的架构一开始就没有走歪,分为文件系统实体类、路径类和文件系统功能三大类。将File和Directory作为抽象类Statable的子类,已经对后来的软硬链接作出了自己的预判。抽象出“属性”实体EntryProps也为硬链接的实现简化了代码。
接下来是出现问题的地方,getEntry方法是为了屏蔽掉路径和预判中链接文件的差异,但在后期为了Issue区一个不测的命令紧急适配时,同样试图屏蔽/的差异性而在获取文件对象的时候直接进行路径中/的检测。
这一决定在阶段一看来没什么问题,但是直接导致了后面新需求引入时,我们习惯性地试图在获取文件对象的过程中直接进行处理,以屏蔽掉这种差异性。在此时,我们没能及时意识到重构的必要性。文件系统的上层功能其实是需要这一差异性的,原有的架构不能满足这一需求,导致后面的实现中Bug频发,需要在每次调用时加上大量特判。
试图过度简化,这是问题的表象;但根源是代码重构相对于需求的变化进行的不够及时。上文所述的简化,在第一次作业中没有任何问题,但在第二次作业中就不是那么合适。这就要求及时重构。一个好的架构不是在任何情况下都不用重构而塞上大量特判,那样的得到的结果仍然是不可维护的代码。一个好的架构应该能方便的进行重构,同时及时用功能实现的复杂程度警示开发者需要重构。可惜在这次结对项目中,我们并没能及时发现这一趋势。
4.进度、质量和沟通管理实践体会
总结结对过程中的进度、质量和沟通管理实践体会,并分析哪些哪些bug是因为两个人的理解不一致而导致
进度管理
两次作业的进度安排大致为一天设计,两天实现,两天测试(每一天的实际工作时间大约为4~10小时之间),当然明晰需求(对第二次作业而言)贯穿作业始终。当发现问题时,会通过TODO的标记提示待完成,并在gitlab的每次commit记录上尽可能地标注修复的bug,保证两人明确当前作业进展,共同完成任务。
质量管理
我们通过单元测试、针对测试、回归测试、压力测试等保证软件的质量,尤其是在第一次任务结束后,我们把第一次任务公开的强测数据根据第二次作业的指导书做出相应修改后,添加到回归测试中。
回归测试最好要自动化,因为这样就可以对于每一个构建快速运行所有回归测试,以保证尽早发现问题 —— 《构建之法》
通过CI/CD的部署保证了测试的自动化进行,每次commit自动触发测试,保证软件的质量。
沟通管理
我们虽然之前有过交流,但是没有线下见过,所以完成第一次作业时还需要熟络一段时间,不过两人熟悉后很快投入状态,开发过程中利用Code with me内置语音进行交流,也会在线下同时同地进行开发直接交流。
由于实际开发均是两人共同商量分析需求后进行,所以不存在因为两个人理解不一致导致的bug(bug也是两个人同时理解错误)
5.结对项目实践建议
提出建议:根据三个阶段的结对项目的实践经验,对如何更好的实施和管理结对项目提出自己的建议
- 及时的沟通交流是必要的
- 最好事先规定某一角色在对某一问题出现分歧时拍板做决定,避免浪费时间
- 不用拘泥于两人、一台电脑、一个键盘的开发模式,关键在于两人要同步进行编程
三、CI体验感想
这次结对编程,我们使用CI进行一系列测试和提交自动化,感谢牟哥分享的办法,我们在其基础上构建了覆盖率的测试,对自定义样例的测试(阶段2使用阶段1的强测进行自动回归测试),然后利用GitLab的选项允许手动控制提交,利用变量控制提交目标和结果获取,极大的优化了代码提交部分的体验。
允许手动运行的pipeline效果图:
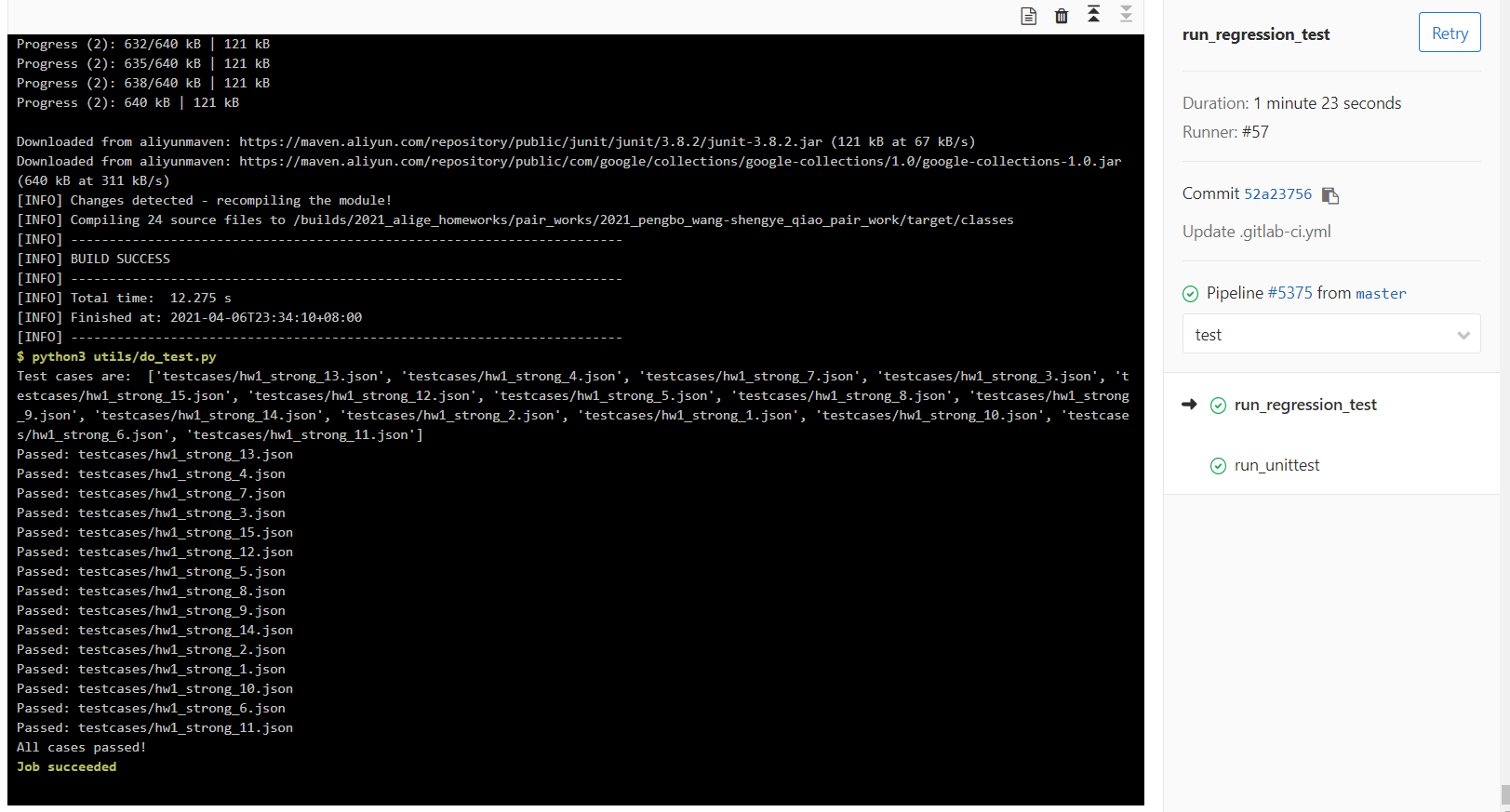
自定义样例测试输出结果图:
gitlab-ci流水线配置:
# to make sure pjcourse cli's availability and java environment's consistency, PLEASE USE THIS IMAGE!!!
image: local-registry.inner.buaaoo.top/library/java:8u201-edu
stages:
- test
- submit_and_result
- result
variables:
CI: 'true'
before_script:
- java -version
- javac -version
- mvn -v
run_unittest:
stage: test
script:
- apt-get install zip -y
- curl ${ZIP_URL} --output ${ZIP_NAME}
- unzip -P ${UNZIP_SPEC_PASSWORD} ${ZIP_NAME} -d ${ZIP_DIRECTORY}
- mv ${ZIP_DIRECTORY}/*.jar ${JAR_NAME}
- mvn install:install-file -Dfile=${JAR_NAME} -DgroupId=${SPEC_GROUP_ID} -DartifactId=${SPEC_ARTIFACT_ID} -Dversion=${SPEC_VERSION} -Dpackaging=jar
- mvn compile
- mvn cobertura:cobertura
- mvn cobertura:dump-datafile
artifacts:
paths: [target/site/cobertura]
expire_in: 365 days
coverage: '/coverage line-rate="\d+/'
run_regression_test:
stage: test
script:
- apt-get install zip -y
- curl ${ZIP_URL} --output ${ZIP_NAME}
- unzip -P ${UNZIP_SPEC_PASSWORD} ${ZIP_NAME} -d ${ZIP_DIRECTORY}
- mv ${ZIP_DIRECTORY}/*.jar ${JAR_NAME}
- mvn install:install-file -Dfile=${JAR_NAME} -DgroupId=${SPEC_GROUP_ID} -DartifactId=${SPEC_ARTIFACT_ID} -Dversion=${SPEC_VERSION} -Dpackaging=jar
- mvn compile
- python3 utils/do_test.py
do_submit_code:
stage: submit_and_result
when: manual
allow_failure: false
script:
- git clean -df
- pjcourse config add judge # register the judge service
- pjcourse config info judge # try connect to the judge service
- pjcourse homework list judge # get to know all the available homeworks
- pjcourse homework submit judge homework_$HOMEWORK_ROUND --failure-exitcode 3 4 # submit your homework (homework_1 is the name of homework, may be changed when 2st, 3rd homeworks)
- pjcourse homework history judge homework_$HOMEWORK_ROUND # get your submit history
get_final_result:
stage: submit_and_result
when: manual
script:
- pjcourse config add judge # register the judge service
- pjcourse judge result judge "homework_${HOMEWORK_ROUND}_final" # 查看详细信息
- pjcourse judge result judge "homework_${HOMEWORK_ROUND}_final" -a # 查看摘要信息
测试用python脚本:
import os
import json
import difflib
# mvn install:install-file -Dfile="lib/specs-homework-1-1.1-raw-jar-with-dependencies.jar" -DgroupId="buaase2021" -DartifactId="spec1" -Dversion="1.1" -Dpackaging=jar
def get_java_out():
COMMAND = 'mvn -q compile exec:java -Dexec.mainClass="$MAIN_CLASS_NAME" < stdin.txt > stdout.txt'
os.system(COMMAND)
with open("stdout.txt", "r") as f:
out_txt = f.read()
out_list = out_txt.splitlines()
return out_list
def handle_case(path: str):
with open(path, "r") as f:
case = json.load(f)
with open("stdin.txt", "w", encoding="utf-8") as f:
f.write(case['stdin'])
ans_list = case['answer'].splitlines()
out_list = get_java_out()
d = difflib.unified_diff(ans_list, out_list)
d = list(d)
if len(d) != 0:
print("ERROR in " + path +"!!!\nDiff:\n")
d = difflib.ndiff(ans_list, out_list)
print('\n'.join(list(d)))
exit(2)
else:
print("Passed: " + path)
def main():
# get case list
case_list = list(map(lambda x: x.path, os.scandir("testcases")))
print("Test cases are: ", case_list)
for path in case_list:
handle_case(path)
print("All cases passed!")
if __name__ == "__main__":
main()
P.S. 对自定义样例的测试这部分在课程进行时没有分享,因为担心会因为测试数据点的重复影响查重
四、结对编程感想
1.结对方法
主要通过Code with me线上编程和线下在同一地点同时开发两种方式完成结对编程的任务。Code with me虽然支持在线同步编程,内置语音通话,但是总会把IDEA的自动补全和提示弄崩,影响了共同开发效率,相比之下,线下同时同地开发效率更高一些,而且还可以互相监督,避免摸鱼。
每一次的结对编程任务大致分为析-码-测三阶段完成,首先针对指导书和issue中的需求进行分析与讨论,再根据需求逐个实现方法,最后再针对需求依次对方法构造测试样例进行测试和整体实现的压力测试。因此需求分析是任务完成的重中之重,在实现之前对某个需求进行充分的讨论是必要的;对需求的可能体现形式的各种联想是必要的;发现问题及时通过issue向课程组反馈是必要的;和其他组进一步沟通交流是必要的。
我们在测试环节投入的时间大约是编码环节的2-3倍,首先要编写最基础的单元测试,对每个方法进行覆盖性的测试,再根据issue实现针对性的测试,为issue中描述的各种场景分别构造测试样例,最后再构造复杂数据进行压力测试,主要考察运行时间、内存耗用等情况。
结对编程的好处正如前言部分所提到的那样,可以向对方阐述自己的想法和做法;可以头脑风暴考虑各种情况;驾驶员和领航员的角色互换也可以提升开发效率;可以一起肝到凌晨,共同欣赏北京的早霞(误)。
缺点的话,可能完成任务的时间更长了?不过这可以保证程序的鲁棒性能尽可能地高,所以还是值得的。
Code with me还是值得推广的,自动补全弄崩了就重启IDEA嘛,更何况Code with me开启时,大多数情况下IDEA还是正常的,相信未来Code with me的开发团队会fix这个问题。
2.评价队友
PB脑子灵,见识广,反应快,想的全,脾气好,能力强,结对编程首选伙伴。
可能还需要再锻炼一下心态,不能总绷不住了(虽然第二次作业确实很折磨人),是吧。
当然最后必须要说的是:PB,YYDS。
Q佬为人细致耐心,善于发现代码中的问题,代码整体逻辑也非常清晰,命名规范,专业能力一流。有一点小小的想法是,感觉Q佬可以更主动的去交流下自己的想法,说明自己的理由。很多时候我都没能完全理解Q佬的意思,导致有时候按我的思路写下去,后来才发现Q佬当时的思路提醒过这一点。当然,能有Q佬作为结对编程伙伴绝对是一大幸事,结对编程让我收获颇丰(挥动双手打Call.jpg)
3.软件工具
- 沟通:主要使用Code with me的内置语音和微信
- 代码实现:使用既成熟又好用的IDEA,也会用VSCode编写配置文件等
- 测试:主要使用Junit和Jprofiler,前者用来实现单元测试,后者用来实现压力测试(测试极端数据下方法调用,运行时间和内存消耗等情况)
- 博客:Typora(小巧而精致,流畅且完善),markdown编辑工具首选
- 其他:利用gitlab进行版本控制和代码存储,gitlab-ci进行持续集成测试
4.感想和吐槽
From 3808
虽然在第一次作业指导书发布的时候,就已经想好了后续的拓展方向,但是却没有很好地估计第二次作业设计实现的复杂度;
需求分析真的很重要,把一个需求弄清再着手实现才是上上策,如果不以需求为导向进行设计实现,最后也是事倍功半;
当然如果指导书最开始的时候能更明确一点就更好啦,毕竟一次作业只有不足6天时间,第二次作业周的周五晚上八点还在为助教的最新issue回复修改一个方法的实现,不过好在后续顺利通过强测(好耶!
From 3050
最大的槽点应该就是指导书了吧,这里直接引用我在其他文章下的讨论内容
真正的软件工程中,用户不可能对每个细节都规定。而在我们的结对项目中,我们需要和一个标准输出对齐,才能完成评测这一任务。而对于一个细节问题的要求,不同架构的处理难度差别甚大。但在课程中,这些细节问题的重要性和其他部分几乎是相同的(一个不过就有可能是强测某一部分不过)。这样一来,其实是在引导大家在向某种架构靠拢,给大家实现细节留得空间较小。
指导书在本次作业中的作用,更类似于一个Spec,一种标准文档,如果让我类比,我会将其比作POSIX标准中抽出文件系统部分的命令(其实助教如果想继续做这个题目,可以参考一下POSIX标准,在我看来非常清晰)。一般的标准都会有UB,Undefined Behavior。或是为了降低编程的难度,也或者是为了方便性能的优化。但我们的指导书却要求没有UB,UB就是和Ubuntu 18.04对齐,这极大地增加了开发的复杂度。
较小的实现自由度,导致了实现过程中的耗时,不再赘述的表述,也给实现带来了困难。且指导书经常有覆盖不到的地方,需要多次确认,甚至发生需求的更改
但是援引助教的话
因为他烂,所以他不烂,反而有点妙!🤣
需求的改变无处不在,确实是真实软件的情况。唯一的缺点是时间上的花费实在是太大,除此之外,作为第一年的指导书,我认为是可以理解的。
五、总结
感谢课程组对结对编程项目的设计与打磨,恰如《构建之法》中有言:
在产品交到用户的手中后,学习才刚刚开始 —— 《构建之法》
当指导书(尤其是第二次作业的指导书)发布到学生手中后,可以从各类issue中看出指导书确实存在需要迭代完善的地方,从初版指导书中设置的约束可以看出课程组在降低作业难度,但是确实也因此处理不了一些边际情况,感谢课程组对问题的及时反馈,让我们得以顺利完成两次作业。
结合自身助教经历来谈,题目的设计与修订确实是十分耗费心血的,与其说我们作为学生在完成任务,不如说我们和课程团队在共同经营一份愿景:学有所得。弱测强测机制确实可以让我们为自己的程序构造更全面更丰富的测试样例;CI/CD的部署确实可以让我们享受到自动化集成测试的便利;结对编程确实可以让我们大开脑洞,互相督促,携手共进。
学到就是赚到,尽管过程中会焦头烂额,尽管羡慕隔壁软工摸鱼水文档,但是三周下来,结对编程的快乐是我们的;逐字逐句需求分析的充实感是我们的;绞尽脑汁构造测试样例最后完美通过弱测强测的满足感是我们的;一周一总结,一次一反思的脚踏实地感是我们的;以上,足矣。
希望在未来的团队项目中,拥有更多的收获,更深的体会以及对软件工程更全面的认知。
最后还有一个小问题,想请教课程组,究竟应当如何更优雅地更新时间戳呢?(因为我们觉得这个需求在官方包里实现会更合理一些,课程团队关于这一点的设计是如何考量的呢?)望解答。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号