chapter11 图处理系统Giraph
Giraph利用MapReduce框架,不是基于MapReduce API计算。
1 设计思想
已有的图算法库或MapReduce系统不具备下列特点:
- 对图处理算法通用
- 支持大规模图处理
- 自身具备容错能力
- 为图处理进行优化
1.1 数据模型
数据结构中通常使用邻接矩阵/邻接表表示图顶点与边的关系:
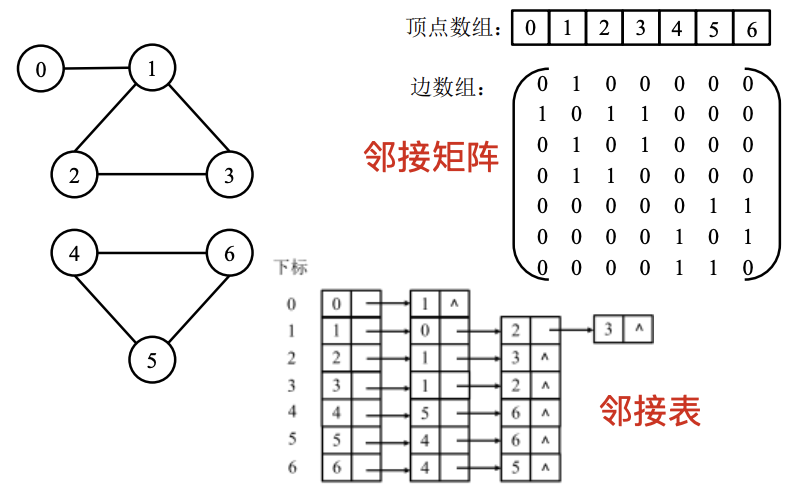
Giraph的图数据模型:由顶点(Vertex)和边(Edge)组成
- vertexID:顶点具有的唯一的标识
- value:与顶点关联的一个自定义的计算值,用于存储计算过程中所需保持的数值
- weight:指图中由某一顶点与其邻居顶点确定的边上用户自定义的权值
图中的某一顶点及以其为起点的边可以抽象地表示为:[vertexID, value, {[neighborID,weight], …}]
- <vertexID, neighborID>表示一条边,该边的权值为weight
1.2 计算模型
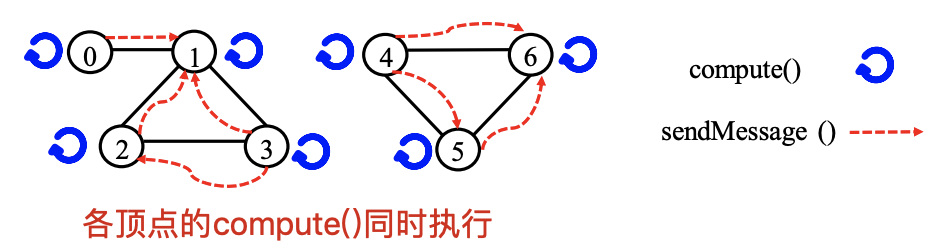
Giraph以顶点为主进行数据表示,采用以顶点为中心(Vertex-centric)的计算模型。
顶点执行用户自定义函数进行相应计算:
- compute( ):计算并更新顶点的计算值(value)
- sendMessage ( ):将消息传递给指定顶点。e.g.,邻居节点
1.3 迭代模型
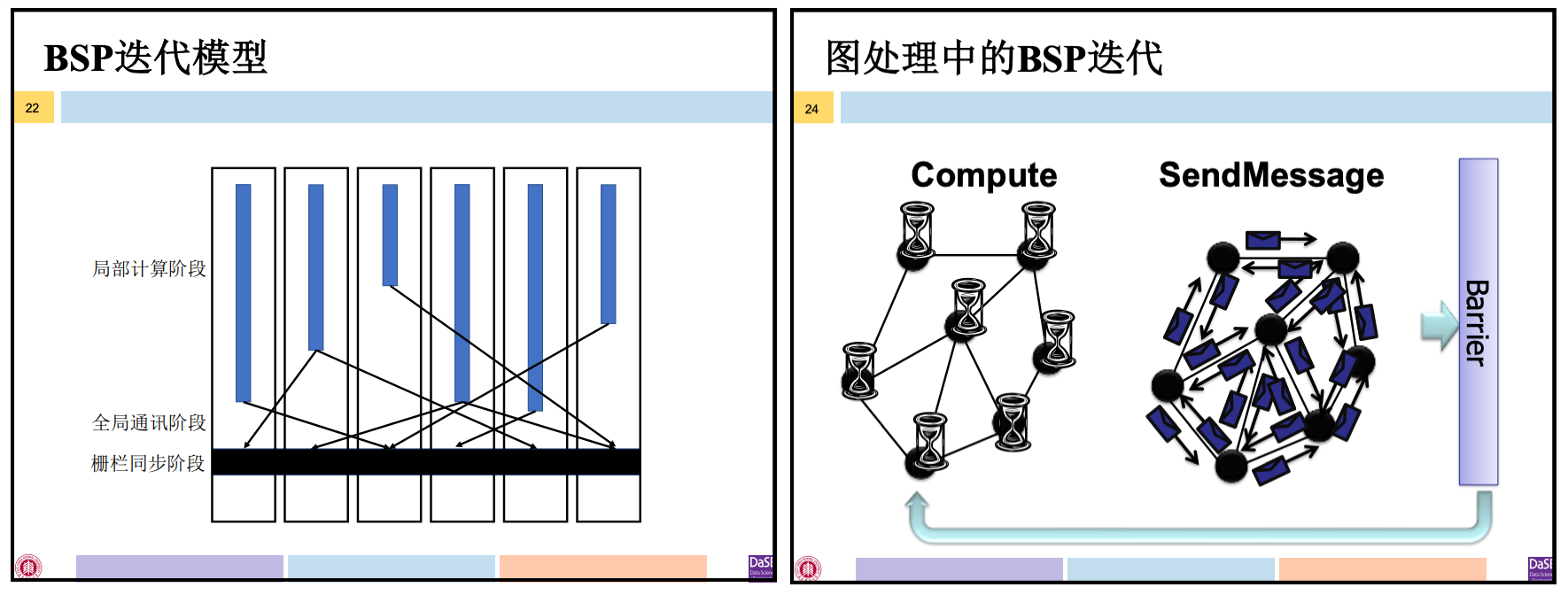
图算法一般都是由若干迭代组成的过程,某一顶点的计算值在本轮迭代更新后,而其它顶点的计算值可能尚未完成该轮计算,则此顶点不能立即进入下一轮迭代。——因为Giraph采用BSP迭代模型
一个BSP程序由一系列串行的超步组成,超步内并行。一个超步分为三个阶段:
- 局部计算阶段,每个处理器只对存储本地内存中的数据进行本地计算
- 全局通信阶段,对任何非本地数据进行操作
- 栅栏同步阶段,等待所有通信行为的结束
图处理中的BSP迭代:
- 局部计算阶段,各个处理器对每个顶点调用用户自定义的compute()方法,完成顶点计算值的更新
- 全局通信阶段,针对每个顶点调用SendMessage()方法,完成顶点之间的信息的交换
- 栅栏同步阶段,每个顶点都要等待其它所有顶点完成计算并发出消息

2 体系架构
先介绍Pregel的架构图,再介绍如何参考该架构图基于MapReduce实现Giraph,最后结合架构图讲述执行Giraph应用程序的一般流程。(Pregel是基于BSP模型实现的并行图处理系统)
2.1 架构图
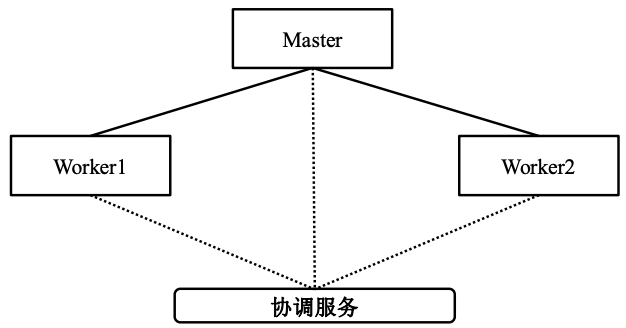
Pregel架构
- Master:负责给各个Worker分配任务
- Worker:系统将图进行了划分,形成若干个分区,每个Worker负责一个或多个分区并负责针对该分区的计算任务
- 协调服务:协调Master与worker以及worker之间
Worker管辖分区的顶点描述信息保存在内存中:
- 顶点与边的值:顶点的当前计算值,以该顶点为起点的出射边列表,每条出射边包含了目标顶点ID和边的值
- 消息:所有接收到的、发送给该顶点的消息
- 标志位:用来标记顶点是否处于活跃状态
- 如果一个顶点V在超步S接收到消息,那么V将参与下一个超步的计算,意味着在下一个超步S+1中(而不是当前超步S中)处于“活跃”状态
Master负责协调各Worker执行任务,每个Worker均向Master发送自己的注册信息, Master会为Worker分配一个唯一的ID。
- Master维护所有Worker的各种信息,包括每个Worker的ID和地址信息,以及每个Worker被分配到的分区信息
- Master维护的数据信息的大小,只与分区的数量有关,而与顶点和边的数量无关
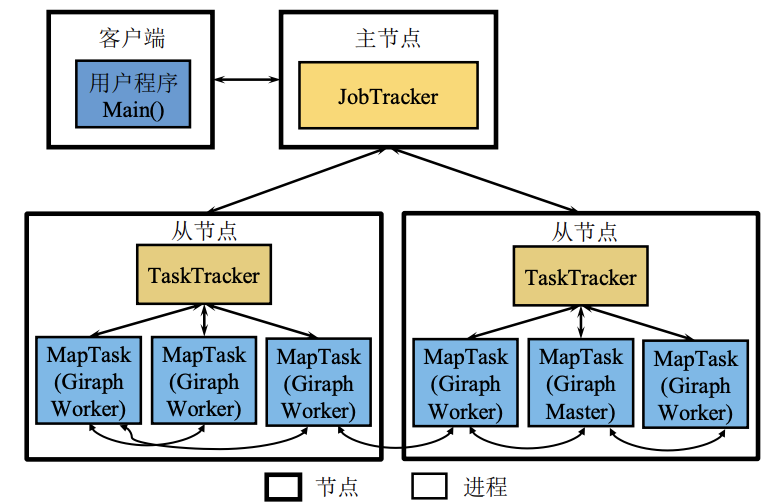
Giraph架构
Giraph参考了Pregel体系架构,但在实现时借用了MapReduce框架启动Master和Worker这些进程。
- Giraph并没有像普通MapReduce程序那样编写Map和Reduce方法,而是将所有的图处理逻辑都在启动Map任务的run方法中实现。
- 从MapReduce框架的角度来看,执行Giraph作业仅启动了Map任务,在这些Map中有一个作为Giraph的Master,其余作为Worker。——使用ZooKeeper的协调服务功能进行分布式选主(Zookeeper还能实现BSP模型的栅栏同步功能)
⚠️ Worker之间可相互传输数据,MapReduce中Map任务间不会进行数据传输。
2.2 应用程序执行流程
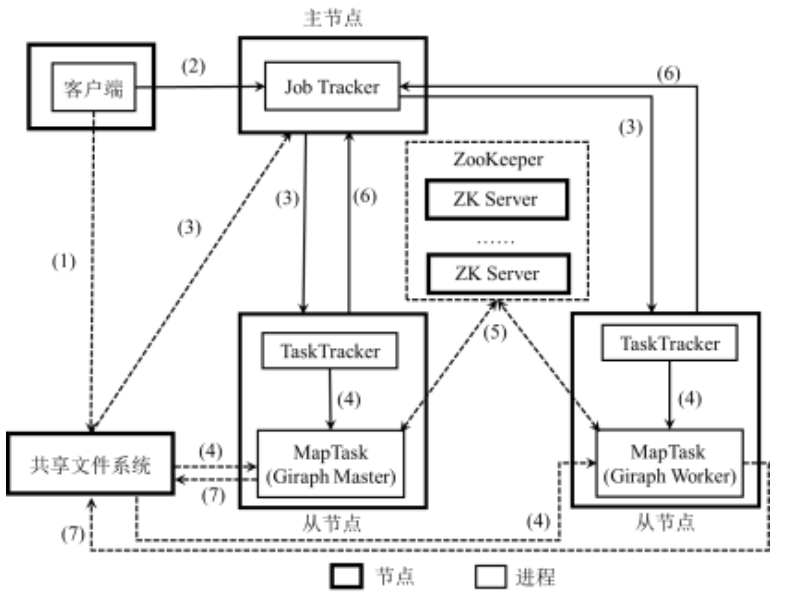
- Client将用户编写的Giraph作业配置信息、jar包等上传到共享的文件系统(例如:HDFS)
- Client提交作业给JobTracker,告诉JobTracker作业信息的位置
- JobTracker读取作业的信息,生成一系列Map任务,调度给有空闲slot的TaskTracker
- TaskTracker根据JobTacker的指令启动Child进程执行Map任务,Map任务将从诸如HDFS等共享文件系统或其它存储图数据的存储系统读取输入数据
- 多个Map任务通过ZooKeeper进行选主,其中一个Map任务作为Giraph的Master,其它作为Giraph的Worker,并且Master和Worker通过 Zookeeper协调执行Giraph作业
- JobTracker从TaskTracker处获得Giraph的Master和Worker进度信息
- 任务完成计算后将结果写入共享文件系统,则意味着整个作业执行完毕
3 工作原理
Giraph读入数据经过一系列超步计算后将结果输出,大体划分为三个阶段:
- 数据输入阶段:对输入的图数据进行划分
- 迭代计算阶段:进行超步计算以及同步控制
- 数据输出阶段:各Worker对自己负责分区的计算结果写入HDFS等持久化存储系统
3.1 数据划分
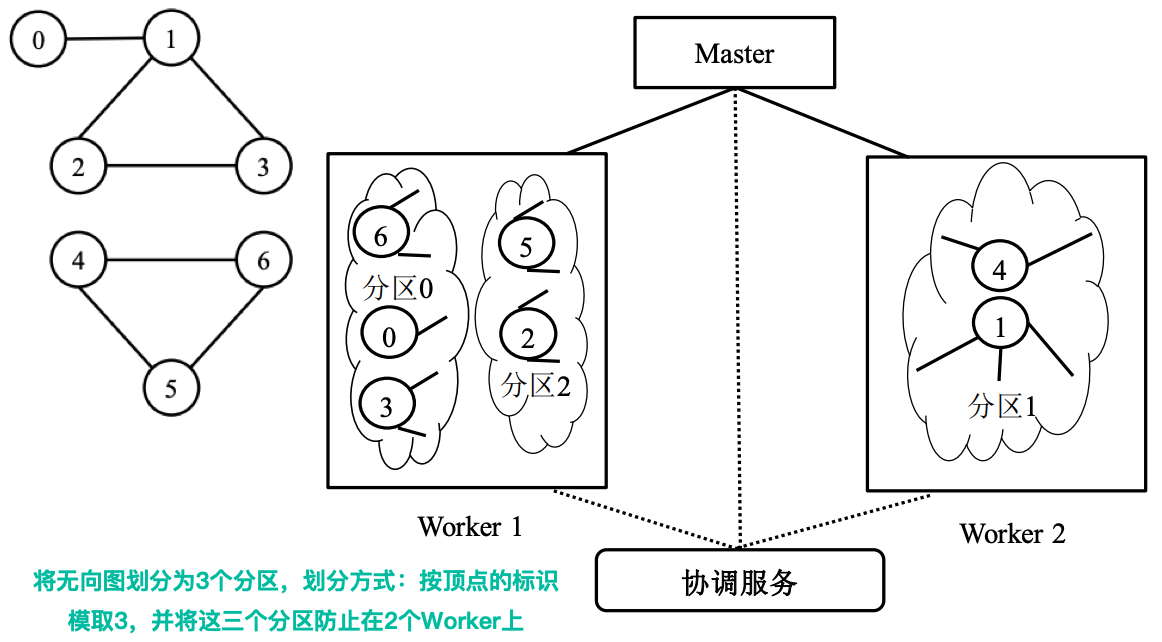
为了后续的图处理,Giraph需将一张图根据顶点划分为多个分区。
分区:一组顶点和以这些顶点为起点的边
- 按照顶点的标识(vertexID)决定该顶点属于哪一个分区
- 默认的划分方法:hash(vertexID) mod N,N为所有分区总数
- 输入数据的分区与Giraph需要的分区往往不一致。
数据划分实际上要完成输入数据到Giraph期望分区的调整,这一过程由Master、Worker共同完成
边加载边划分:
- Master:将输入的图数据根据Worker数量初始分解为多个部分,为每个Worker分配一部分数据
- Worker:读取初始分配的部分,并根据划分方法计算该顶点是否属于当前Worker负责的分区
- 若不属于,那么当前Worker将该顶点发给其所属分区所在的Worker
3.2 超步计算
基本步骤:
- 当超步开始时,Worker针对每个顶点调用compute方法,并根据获取的前一个超步的消息更新该顶点的计算值
- 计算过程中, Worker将更新后的计算值以消息形式发送给邻居顶点
- 在超步结束的时候,Worker需要进行同步控制,保证所有的消息都已经发送并接收成功
一个Worker进行一次超步t的计算过程:
- VertexStore:存储顶点标识、计算值以及边的信息
- MsgStore:存储两份顶点消息
- MsgStore(t):存储在 超步 t-1 全局通信阶段各顶点获取的消息,用于超步t中顶点的计算
- MsgStore(t+1):存储在 超步 t 全局通信阶段各顶点获取的消息,用于超步t+1中顶点的计算
- StatStore:存储两份标志位信息
- StatStore(t):指示当前 超步 t 中处于活跃状态的顶点
- StatStore(t+1):指示 超步 t+1 中处于活跃状态的顶点
顶点的状态:
- 活跃:该顶点参与计算
- 非活跃:顶点不参与计算
超步t中某一顶点的处理过程:
- 对于StatStore(t)中的某一活跃顶点,从 MsgStore(t)读取属于该顶点的消息,并调用compute方法更新VertexStore
- 将更新后的计算值以消息形式发送给邻居顶点
- 若无其它顶点发来的消息,则将StatStore(t+1)中该顶点的状态设置为非活跃顶点, 意味着该顶点不参与下一个超步。否则, 将消息存入MsgStore(t+1),用于下一个超步,并将顶点的状态设置为活跃顶点
3.3 同步控制
Giraph中多个Worker同时进行超步计算, 而多个Worker之间需要进行同步。
根据BSP模型,同步控制需要确保即所有Worker都完成超步t后再进入超步t+1。
Giraph中的Master和Worker通过ZooKeeper来完成同步。
迭代的结束(收敛):
- 超步同步完成后,Worker根据StatStore(t+1)信息把在下一个超步还处于活跃状态的顶点数量报告给Master
- 如果Master收集到所有Worker中活跃顶点数量之和为0,意味着迭代过程可以结束
- Master给所有Worker发送指令,通知每个 Worker对自己的计算结果进行持久化存储
4 容错机制
- Master故障:意味着主控节点丢失,整个作业将失败
- Worker故障:该Worker维护的计算信息丢失。
- 设置检查点
4.1 检查点
Giraph允许用户设置写检查点的间隔(每隔多少超步写检查点)
- 默认情况下,该间隔的值为0,即不写检查点
- 如果该间隔值不为0,则每隔的一定超步将进行写检查点
e.g.,检查点间隔为4,则第0、4、8......超步将写检查点
在需要写检查点的超步开始时,Master通知所有Worker把管辖的分区信息(顶点、边、接收到的消息、标志位等)写入到持久化存储系统。
- Master也保存Aggregator的值。
4.2 故障恢复
Giraph的实现中,若一个或多个Worker发生故障,则分配到这些Worker的分区信息都会丢失。
Giraph中Worker是MapReduce的Map任务,则Worker对MapReduce来说是Map任务故障。
故障恢复:
- MapReduce的容错机制将重启新的Map任务,因而Giraph中有新的Worker产生
- Giraph中的Master将给所有的Worker重新分配分区
- 若未设置检查点:Worker重新载入输入数据,从头开始计算
- 若设置了检查点:Worker回滚到最近的检查点所在的超步S,在超步S开始时,从检查点中重新加载信息并继续执行计算
问题:即使仅有一个Worker发生故障,所有的Worker都需重检查点中重新加载分区信息。——造成存活Worker中分区信息的重复计算
解决:Pregel论文提出局部恢复策略——除检查点外,Worker还将其发送出的消息以日志形式记录。
- 仅新启动的Worker从检查点中恢复丢失的分区
- 其余Worker回放日志使新Worker重新计算到发生故障的超步
- 具体实现中,也可不启动新Worker,而由存活的Worker分担新Worker的工作。
问题:Giraph中Worker蕴含在Map Task中,为什么不直接利用MapReduce的容错机制?
- Map Task仅用于启动Giraph Worker,不执行Map函数
- 如果类似MapReduce在Map计算结束时写入磁盘,Giraph的计算也结束了
- 如果每个超步像Map那样写磁盘,那么得到的是本地的备份

 浙公网安备 33010602011771号
浙公网安备 33010602011771号