chapter8 流计算系统Spark Streaming
Spark Streaming实际是Spark核心API的一个扩展,可实现高吞吐量、具有容错机制的实时流数据处理。
Spark Streaming将连续的流数据进行离散化后交给Spark批处理系统,实现了利用批处理系统来支持流计算。
1 设计思想
Storm是一个纯粹的流计算系统,Spark Streaming是一个将流计算转换为批处理的流计算系统。
1.1 微批处理
微批处理方式:针对批处理系统进行一定改造,将流计算作业转化为一组微小的批处理作业。
- 微批处理方式中,将一定时间间隔内的数据视为一批静态数据,交给批处理系统处理
- 批处理系统可以是MapReduce、Spark等任意可执行批处理的引擎
- 批处理系统能够较快地执行这些微小的批处理作业,从而满足流计算应用低延迟的需求

微批处理方式 🆚 连续处理方式
- 微批处理方式中,批处理引擎处理完某一批数据后,负责处理该批数据的任务就结束了
- 连续处理方式中,执行计算任务的线程/进程是长期驻留在系统中的
1.2 数据模型
Storm采用连续处理方式,它的数据模型将流数据看作一系列连续的元组;
流数据的离散化:Spark Streaming将连续的流数据切片,即离散化,生成一系列小块数据。
DStream数据模型:按照数据到来的时间间隔将连续的数据流离散化,得到的每一小批数据都是独立的RDD,一组RDD序列抽象为流数据的DStream。

1.3 计算模型
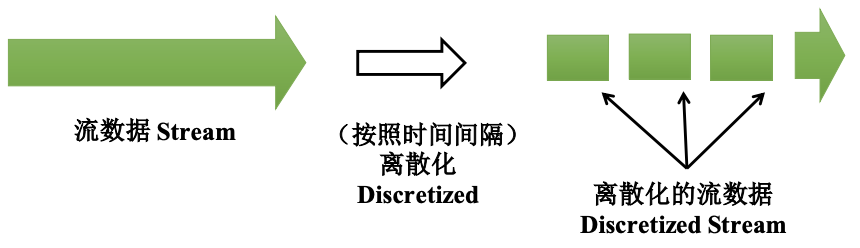
Operator DAG:从操作算子的角度描述计算过程
RDD Lineage:从RDD变换的角度描述计算过程
逻辑计算模型、物理计算模型
DStream C中在不同批次间的RDD也存在一根连线,说明某些计算在语义上是跨批次的。(此处是窗口操作)
2 体系架构
2.1 架构图
严格来说,Spark Streaming不是一个独立的系统,而是依赖于Spark系统的实时流计算工具库。
从物理架构看,Spark Streaming和Spark相同,Spark Streaming对Driver和Executor部件进行了扩充。
- Driver:Spark Streaming对SparkContext进行扩充,构造了StreamingContext,包含用于管理流计算的元数据
- Executor: Executor中作为Receiver的某些Task,负责从外部数据源源源不断的获取流数据(这和spark批处理读取数据的方式不同)
2.2 应用程序执行流程
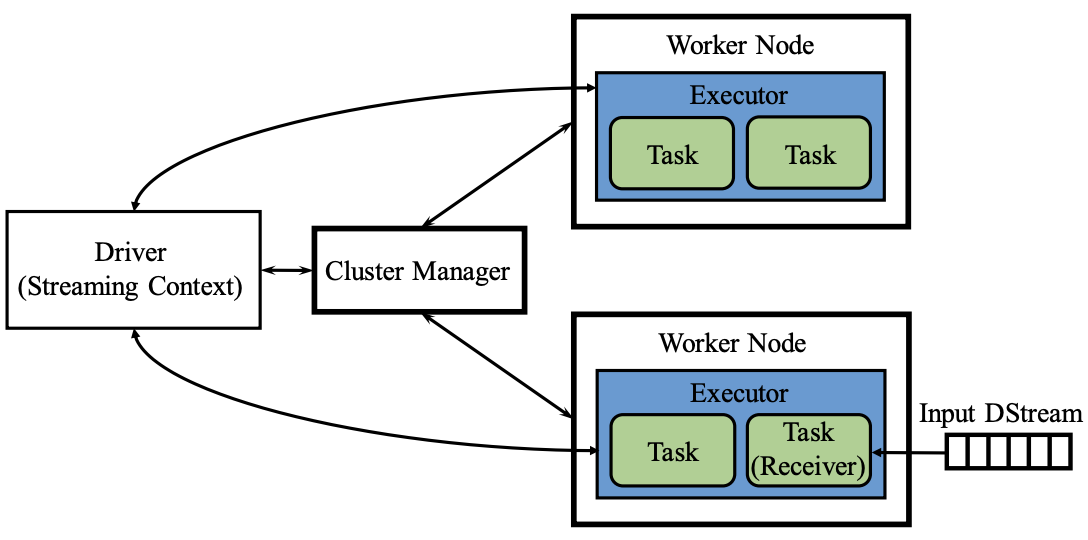
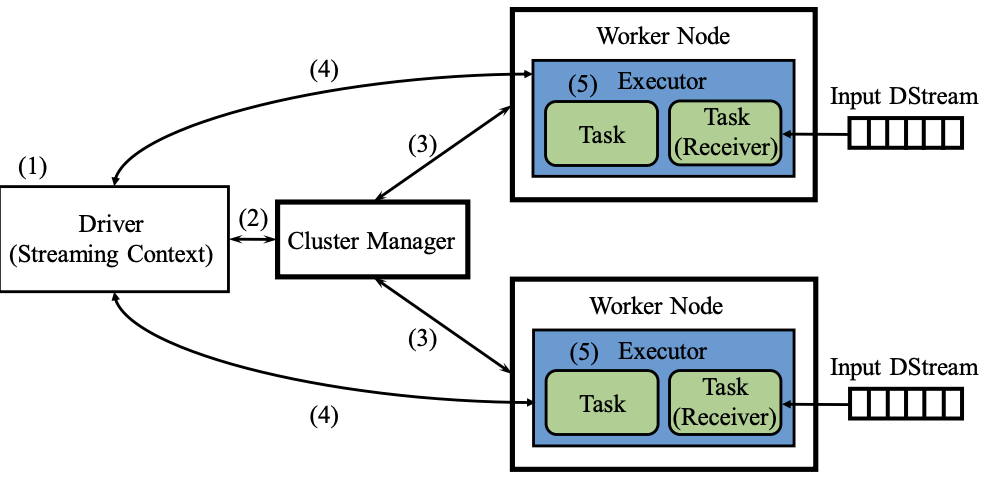
- 启动Driver,以Standalone模式为例
- 如果使用Client部署方式,客户端直接启动Driver,并向Master注册
- 如果使用Cluster部署方式,客户端将应用程序提交给Master,由Master选择一个Worker启动Driver进程(DriverWrapper)
- 构建基本运行环境,即由Driver创建StreamingContext,向Cluster Manager进行资源申请,并由Driver进行任务分配和监控
- Cluster Manager分配资源,通知工作节点启动Executor进程(该进程内部以多线程方式运行任务)
- Executor进程向Driver注册
- StreamingContext构建关于RDD转换的DAG,从而交给Executor进程中的线程来执行任务
3 工作原理
3.1 数据输入
对于一个Spark Streaming应用程序来说,输入数据可来自一个或多个流。
流数据读取:
- 从外部数据源直接获取数据
- Spark Streaming确保输入数据在两个工作节点进行备份后,才向Client发送确认消息
- 从外部存储系统周期性读取数据
- Spark Streaming不对输入数据进行备份,因为HDFS等存储系统本身具有相应容错机制
3.2 数据转换
DStream转换操作,根据含义可分为四类:
- 类似RDD转换的操作
- 使用RDD转换的操作
- 窗口操作
- 状态操作
DStream的转换操作是由RDD转换操作封装而成,可由Spark Streaming翻译为一个或多个RDD转换操作。
Spark Streaming将 描述DStream转换的Operator DAG 转为 描述RDD转换的Operator DAG,交给底层的Spark批处理引擎,进而针对不断到达的小批数据生成一系列作业。
窗口(Window)可以将流动的数据指定一定的计算范围,并且每隔一定间隔指定一次。
- 基于时间:Time-based window
- 基于计数:Count-based window
Spark Streaming的微批处理是按照时间间隔进行划分的,因此Spark Streaming支持 time-based window。
窗口操作:将原始的DStream转化为一个新的DStream,新的DStream按照窗口的语义进行“分组”。
- 窗口操作容许用户指定窗口的大小和间隔。根据窗口的大小和间隔关系,可将窗口分类:
- 滑动窗口(Sliding Window):窗口大小 > 间隔
- 固定窗口(Fixed Window):窗口大小 = 间隔
- 跳跃窗口(Tumbling Window):窗口大小 < 间隔
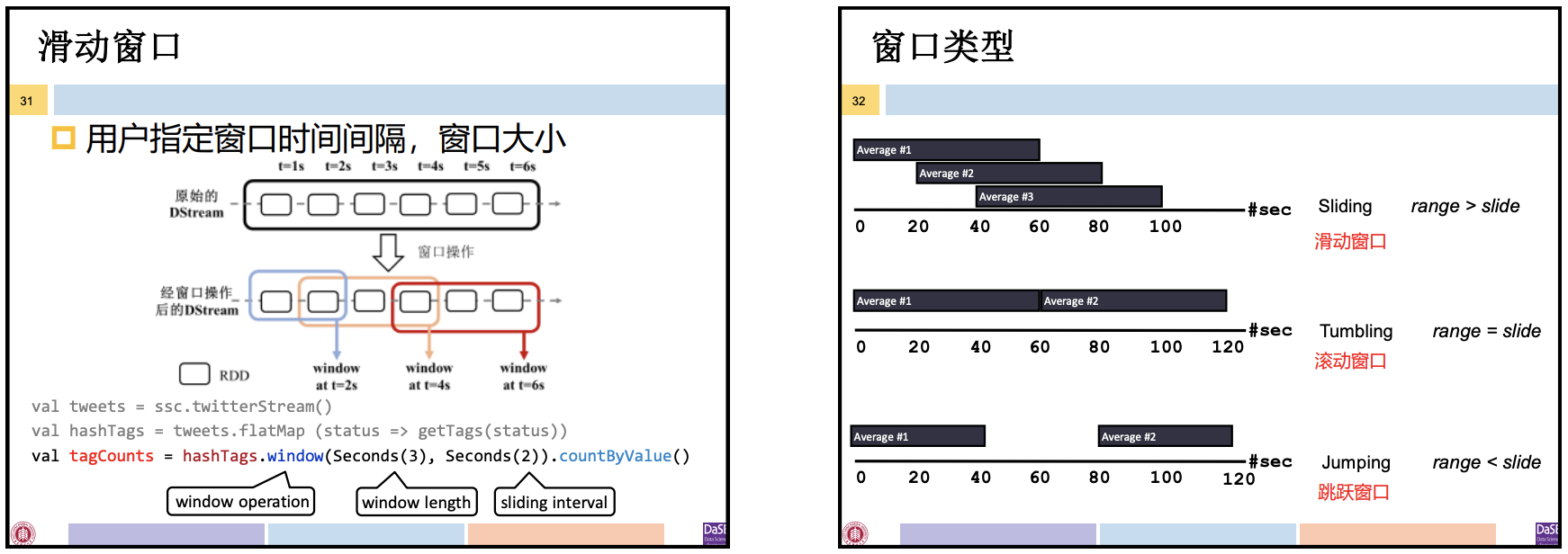
窗口操作只限定需计算的数据的范围,本身不进行计算。因此窗口操作需和其他类似RDD转换的操作同时使用。
非增量式窗口操作:reduceByKeyAndWindow(func, windowDuration, slideDuration)- 参数为:聚合函数func、窗口长度、间隔
增量式窗口操作:reduceByKeyAndWindow(func, invFunc, windowDuration, slideDuration)- 参数:聚合函数func、逆函数invFunc、窗口长度、间隔
当窗口长度 > 滑动间隔(滑动窗口)时,使用非增量式窗口会造成大量计算,引入逆函数invFunc实现增量式计算能提高计算效率。(⚠️ func与invFunc是相反操作,若一种操作相反的操作无法定义,则不能使用增量式窗口操作)

状态:本质上是系统运行中产生的,将参与后续批次计算的RDD。
有状态的操作:DStream中需要涉及多个小批次数据的转换操作,计算跨越批次
- UpdateStateByKey:针对状态RDD进行用户定义的转换的操作
Storm系统中状态管理是由应用程序负责,系统不进行状态管理;
Spark Streaming中状态是系统运行过程中产生的RDD,系统可通过底层的Spark批处理引擎管理RDD

3.3 数据输出
Spark Streaming翻译用户编写的程序时,一旦遇到输出操作则触发产生由DStream操作构成的DAG。再翻译DStream的操作为RDD的操作,底层Spark引擎执行的是由RDD操作组成的DAG。
Spark Streaming 没有action操作,依据输出操作生成DAG。
🆚 Spark中action操作包含输出操作、count等操作,标志转换结束,触发DAG生成。
⚠️ DStream的count操作是转换操作,不是输出操作,不能触发DAG生成。
说明DStream操作与RDD操作并不是从名称上一一对应的。
4 容错机制
- Cluster Manager故障:重启或使用ZooKeeper实现高可用(本节不讨论)
- 不含Receiver的Executor故障:利用RDD Lineage进行恢复
- 含Receiver的Executor故障:利用日志进行恢复
- Driver故障:利用检查点进行恢复
4.1 基于RDD Lineage的容错
不含Receiver的Executor故障:意味着只有负责数据处理的任务受到了影响,系统只需要重启这个Executor再次处理数据就行。
- 由于Spark Streaming系统底层依赖的是Spark批处理引擎,那么Executor里运行的任务实际上是底层Spark批处理引擎的任务。
- 因Executor故障受到影响的负责数据处理的任务可使用Spark批处理引擎的容错机制进行恢复。
Spark批处理容错:RDD持久化、RDD Lineage、检查点:数据检查点
因此 Spark Streaming 中不含Receiver的Executor故障,可利用RDD Lineage机制进行容错。
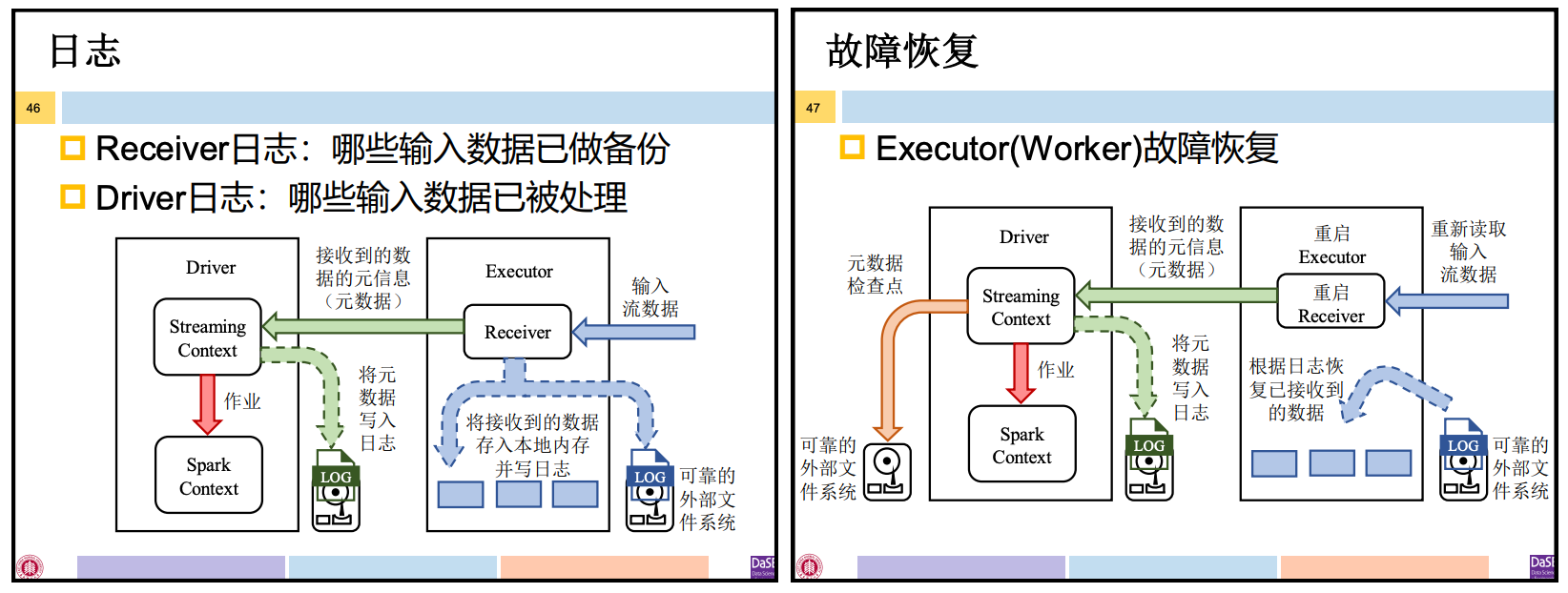
4.2 基于日志的容错
使用RDD Lineage的前提是可获取输入数据,若含有Receiver的Executor发生故障,则意味着接收到的输入数据丢失了。Spark Streaming的Receiver需使用日志记录已获取了哪些数据。
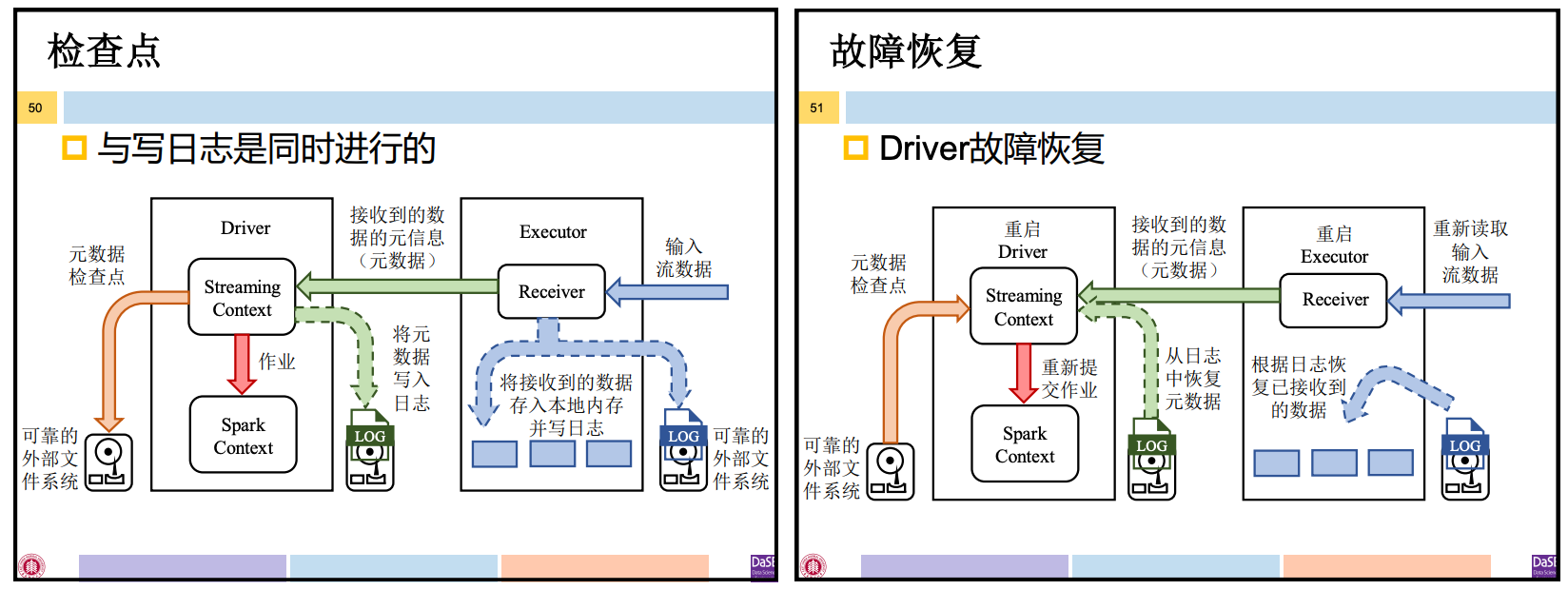
4.3 基于检查点的容错
Spark的检查点机制,作用是防止因RDD Lineage过长导致恢复过 程中重计算的开销过大
类似的,Spark Streaming基于RDD Lineage的容错也可结合检查点使用——数据检查点。
- 本质就是RDD 检查点
元数据检查点:支持Driver的故障恢复。包括内容:
- 配置信息:创建spark streaming应用程序的配置信息
- DStream操作信息:定义了应用程序计算逻辑的DStream操作的信息
- 未处理的batch信息:那些正在排队的作业中还没处理的batch信息
综上:Spark Streaming的检查点包括:数据检查点、元数据检查点。数据检查点是为了加快Executor的故障恢复;元数据检查点是为了保证Driver的故障恢复。
写检查点与写日志是同时进行的。
4.4 端到端的容错语义
流计算系统的容错语义:至少一次、至多一次、准确一次。
Storm能达到至少一次的容错语义,Spark Streaming在上述容错机制上能保证准确一次。
但一个完整的流计算处理流程不仅涉及流计算系统本身,还涉及提供数据源和接收处理结果的系统,即端到端的过程。
端到端的容错语义:
- 接收数据: at-least or exactly once
- 取决于数据是使用Receiver或其它方式从数据源接收的
- 转换数据: exactly once
- 接收到的数据是用Dstream和RDD做转换的
- 输出数据: at-least or exactly once
- 取决于最终的转换结果被推出到外部系统如文件系统,数据库,仪表盘等
从流计算处理整个流程角度看,为使端到端容错语义达到准确一次,还需提供数据源、接受处理结果的系统都能支持准确一次的容错语义。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号