chapter6 协调服务系统 Zookeeper
ZooKeeper:轻量级的分布式系统,用于解决分布式应用中通用的协作问题。
1 设计思想
- MapReduce1.0 架构的 JobTracker 故障:
- 重新启动 JobTracker,所有作业需要重新执行
- MapReduce1.0 没有处理 JobTracker 故障的机制——单点瓶颈
- Standalone 模式下 Spark 架构的 Master 故障:
- 重启系统 or 借助 ZooKeeper 配置多个 Master 实现高可用
- Yarn 架构的 ResourceManager 故障:
- 从持久化存储系统中恢复状态信息,所有应用将会重新执行
- 可部署多个 RM 并通过 ZooKeeper 协调,保证 RM 的高可用性
ZooKeeper 设计目标:将实现复杂的分布式一致性服务封装起来,构建高效可靠的原语集,并给用户提供一系列简单易用的接口。ZooKeeper 不存储大量数据,而存储元数据或配置信息等,以便进行协调服务。
1.1 数据模型
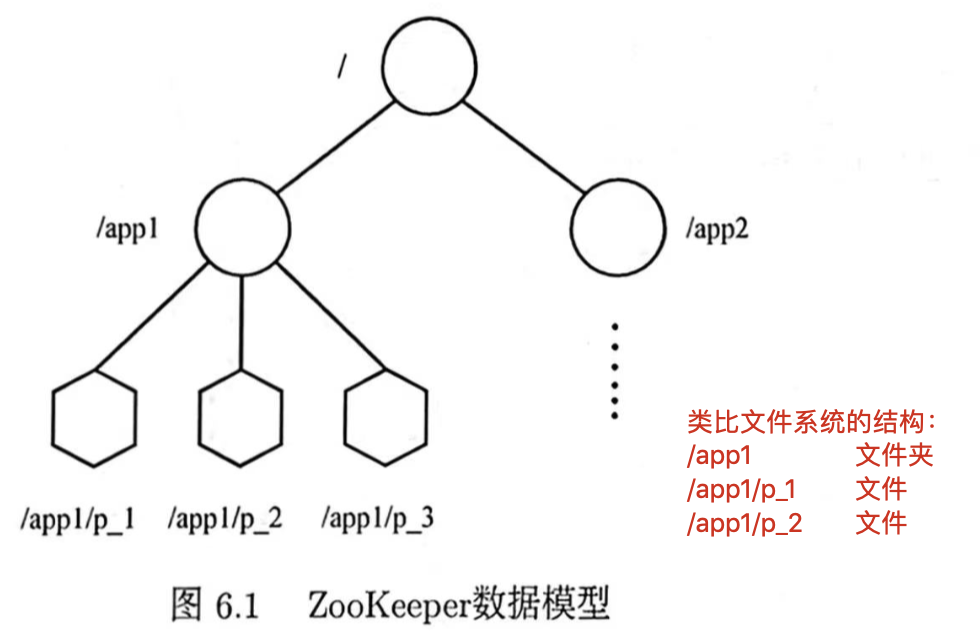
ZooKeeper 维护类似文件系统的层次数据结构。
只是类比文件系统的结构
但文件系统中文件夹不存放数据,只在文件中存放数据 🆚 ZooKeeper 中 Znode 都能存放数据
数据模型是一棵树,树上每个数据节点称为Znode,用于保存信息。
持久Znode:一旦 Znode 被创建,除非主动进行 Znode 的移除操作,否则此 Znode 将一直存在 ZooKeeper 系统中临时Znode:Znode 生命周期和客户端会话(Session)绑定,一旦会话失效则此客户端创建的所有临时 Znode 都会被移除
用户可为 Znode 添加顺序(Sequential)属性:ZooKeeper 创建该 Znode 时会自动在 Znode 名字后追加一个整型数字(由该 Znode 的父 Znode 维护的自增数字)
Znode 的四种类型:
- Persistent(持久 Znode):客户端与 Zookeeper 断开连接后,Znode 依然存在
- Persistent_Sequential(持久顺序编号 Znode):客户端断开连接后依然存在,有顺序号
- Ephemeral(临时 Znode):客户端断开连接后被删除
- Ephemeral_Sequential(临时顺序编号 ZNode):客户端断开连接后被删除,有顺序号
1.2 Client API
- create:在树中某一位置添加一个 Znode
- delete:删除某一 Znode
- exists:判断某一位置是否存在 Znode
- get data:从某一 Znode 读取数据
- set data:向某一 Znode 写入数据
- get children:查找某一 Znode 的子节点
- sync:用于等待数据同步
2 体系架构
ZooKeeper 节点包含一组服务器(Server)用于存储 ZooKeeper 的数据。
服务器 Server:都维护一份树形结构数据的备份。根据功能不同,分为三种角色:
- 领导者 Leader:服务器选定节点作为 Leader,为客户端直接提供读写服务
- 追随者 Follower:仅直接提供读服务,客户端的写请求要转发给 Leader
- 观察者 Observer:不参与选举 Leader 过程,可以没有 Observer
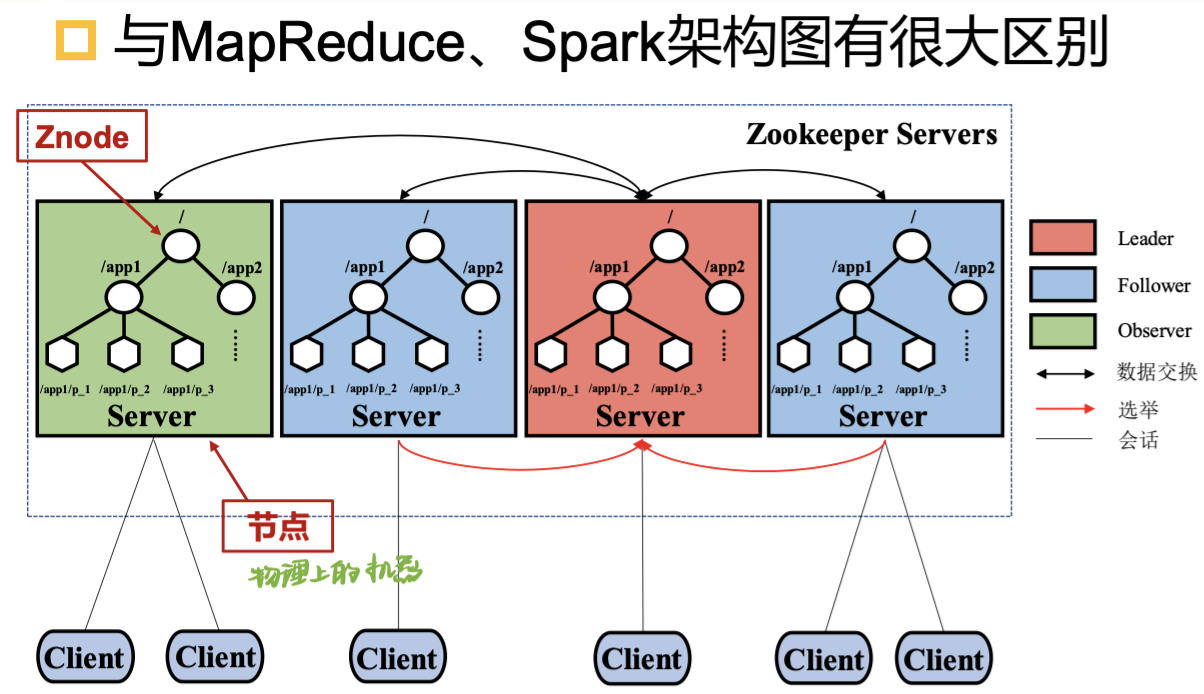
客户端(Client):通过执行前述 API 操作 ZooKeeper 中维护的数据。
由于分布式计算系统普遍采用 ZooKeeper 进行分布式协调,所以ZooKeeper 的客户端往往指这些系统中的进程。
会话(Session):客户端与服务器之间建立的连接。心跳和超时机制。
- 客户端启动时会与服务器建立连接,客户端会话的生命周期开始,在会话的声明周期内客户端通过心跳与服务器保持有效连接,一旦连接断开则会话结束。
- 客户端:在 Znode 设置 Watcher,跟踪 Znode 上的变化
- 服务器:一旦该 Znode 发生变化,服务器会通知设置 Watcher 的客户端
3 工作原理
3.1 领导者选举
- 为什么需要 Leader:
- 写操作会改变数据,必须要保证节点执行相同操作序列,以达到副本之间的一致性
- Leader 保证各节点执行相同写操作序列,否则难以保证一致性
- 如何选择 Leader:
- 分布式一致性协议:由某些节点发出提议,其他节点投票表决,最终所有节点达成一致 e.g., Paxos
3.2 读写请求流程
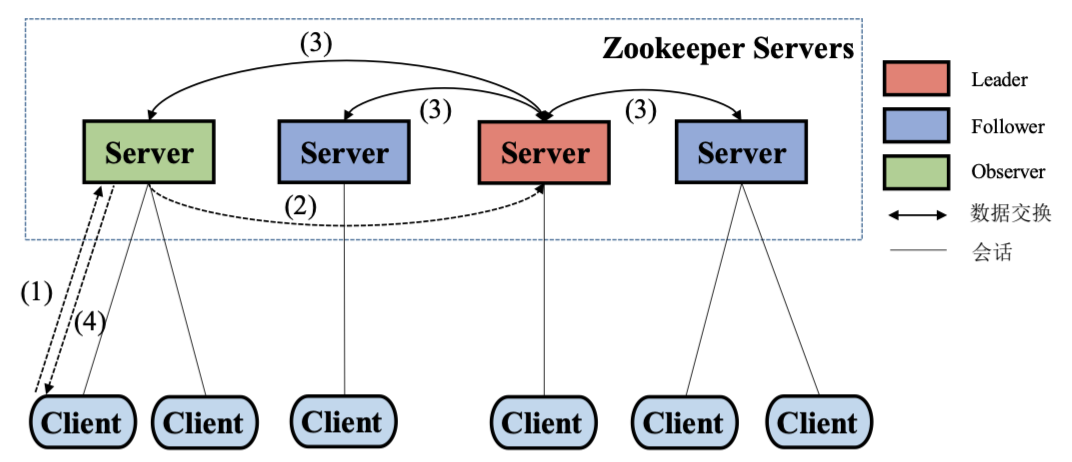
写请求流程:
- 客户端与某服务器建立连接,发起写请求
- 服务器是 Leader 则直接处理,是 Observer 或 Follower,接受写请求转发给 Leader
- 数据同步:理论上 Leader 将写请求发给所有服务器,直到所有服务器都成功执行写操作,该写请求才算完成;事实上,保证半数以上节点写操作成功就可认为写请求完成。—— Follower、Observer 与 Leader 进行数据同步的过程,需使用分布式一致性协议
- 数据返回
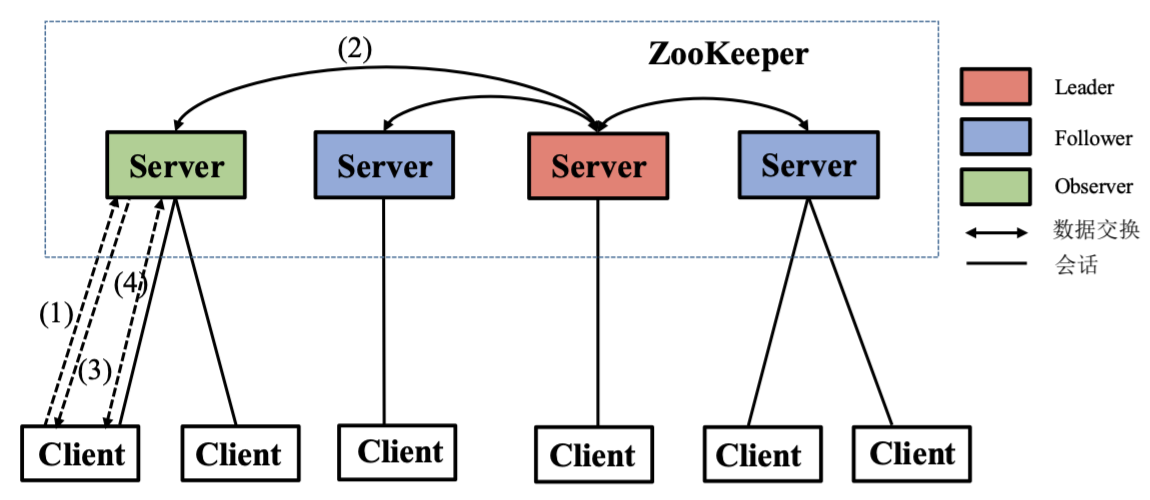
读请求流程:
- 客户端与某服务器建立连接,发起
sync()请求,所有服务器都可以响应:- 如果是 Leader 响应,则返回数据一定是最新的
- 如果是 Follower 或 Observer 响应,返回的数据可能不是最新的,需要执行数据同步(因为实际的写操作中半数以上 Server 成功就算写请求完成)
- 服务器向客户端返回同步成功的消息
- 客户端从服务器读取数据
4 容错机制
- Leader 节点故障:ZooKeeper 重新进行 Leader 选举
- Follower/Observer 节点故障:该节点无法正常服务,其他节点正常,不影响 ZooKeeper 的服务
- 若 Follower 或 Observer 节点发生故障后重启,其可从 Leader 或其他节点恢复数据
5 典型示例
5.1 命名服务
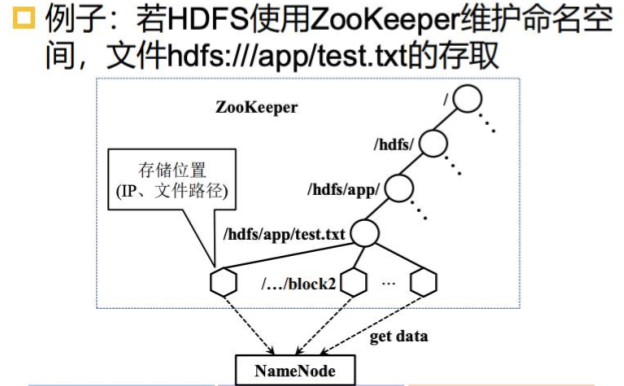
统一命名服务:树形的名称结构
- 域名解析:某一域名的 IP 地址是多少?
- HDFS 目录与文件:某一文件存储在哪里?
命名服务是 ZooKeeper 内置的功能,只要调用 ZooKeeper 的 API 就能实现
- 调用 create 接口就可以创建一个 Znode
- 利用 Znode 存储信息,用于实现相应功能
5.2 集群管理
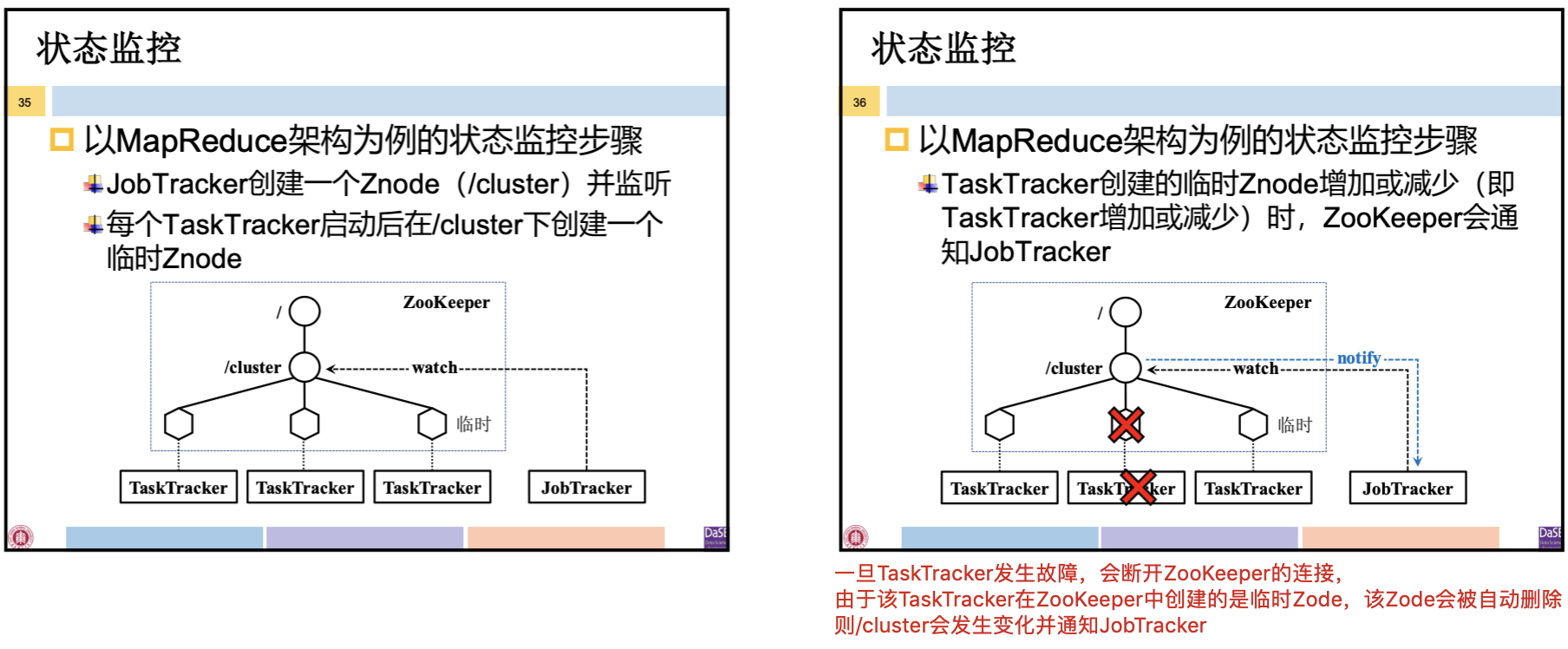
在分布式环境下从节点故障时有发生,因而存在如下需求:
状态监控:主节点需要实时监控集群中的从节点的状态(存活还是宕机)是否发生变化
MapReduce 架构中,JobTracker 需监控 TaskTracker 的状态
选主:为了支持分布式计算系统的高可用,需要配置多个主节点
- 依赖复杂的一致性协议(如Paxos、Raft等)的选主,工程实现复杂
- ZooKeeper 提供了便捷的选主方式
🆚 ZooKeeper 自身 Leader 选举
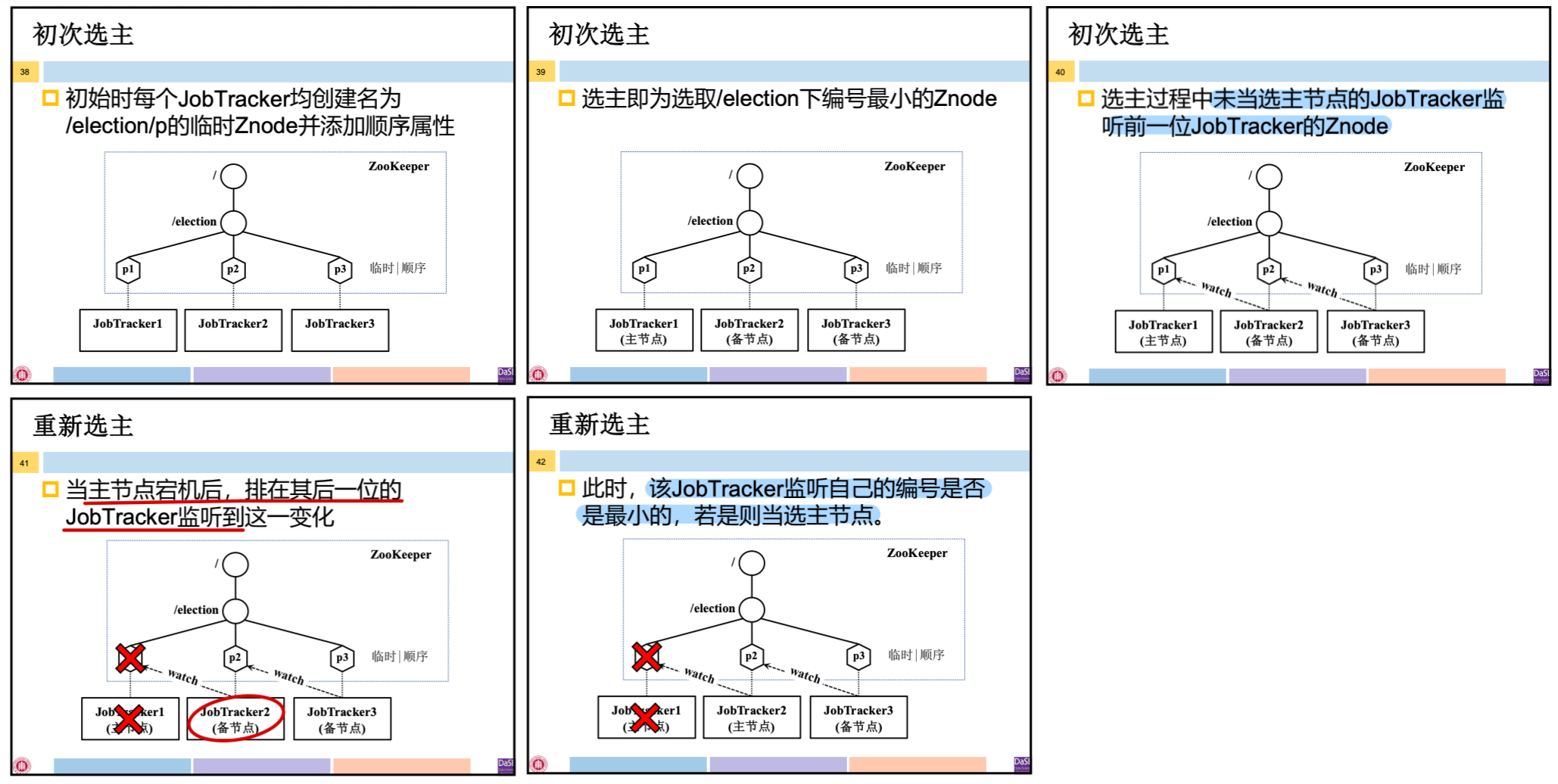
MapReduce1.0 中存在 JobTracker 单点故障问题,需要配置多个 JobTracker 实现高可用
- 初次选主:系统启动时在多个 JobTracker 中选择一个作为主节点
- 创建一个名为 /election 的 Znode
- 在临时顺序编号模式下每个进程在 /election 中创建 Znode
- 监控 /election 并选择编号最小的 Znode 作为主节点
- 选主过程中未当选主节点的 JobTracker 监听(watch)前—位 JobTracker 的 Znode
- 重新选主:当主节点宕机时选取新的 JobTracker 作为主节点
- 当主节点宕机后,排在其后一位的 JobTracker 监听到这一变化
- 该 JobTracker 监听自己的编号是否是最小的,若是则当选主节点
5.3 配置更新
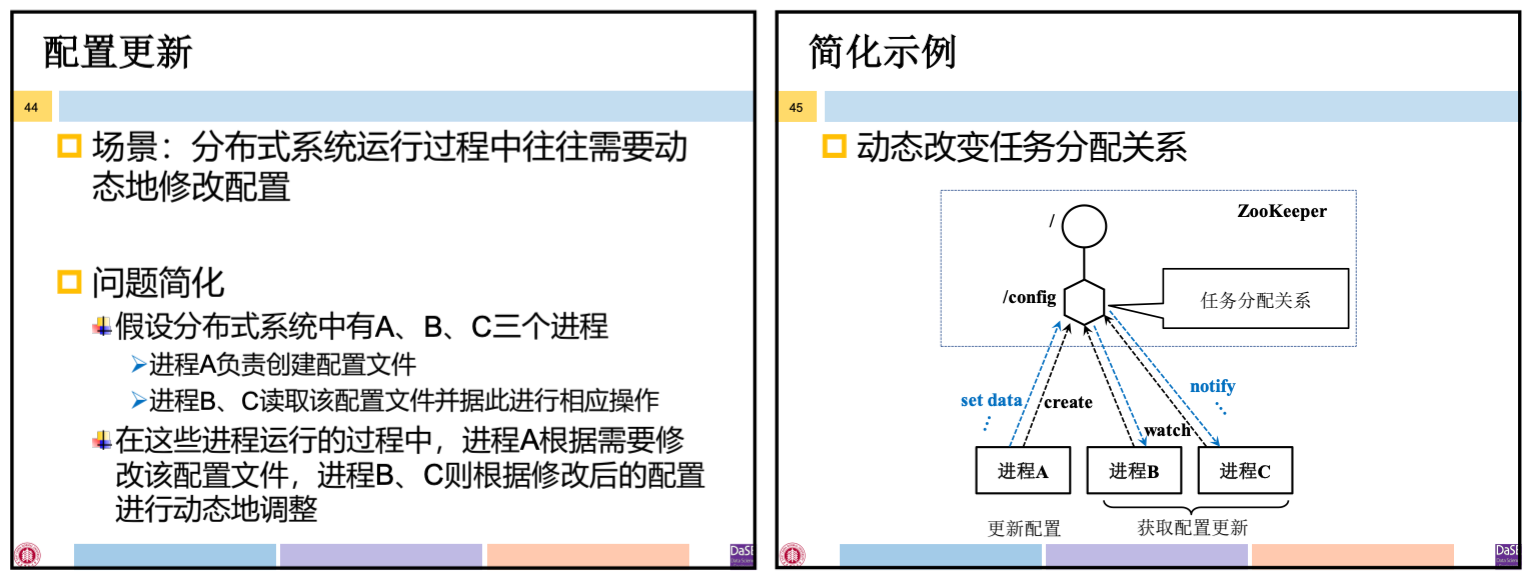
场景:分布式系统运行过程中往往需要动态修改配置
一般方法:
- 配置信息存放在 ZooKeeper 某个 Znode, 所有需要获取配置更新的进程监听(watch)该 Znode
- —但配置信息发生变化.毎个监听的进程收到通知,然后从 ZooKeeper 获取新的配置信息并应用
5.4 同步控制
同步:各进程按某一特定顺序完成相应操作
互斥:各进程对临界资源的互斥访问
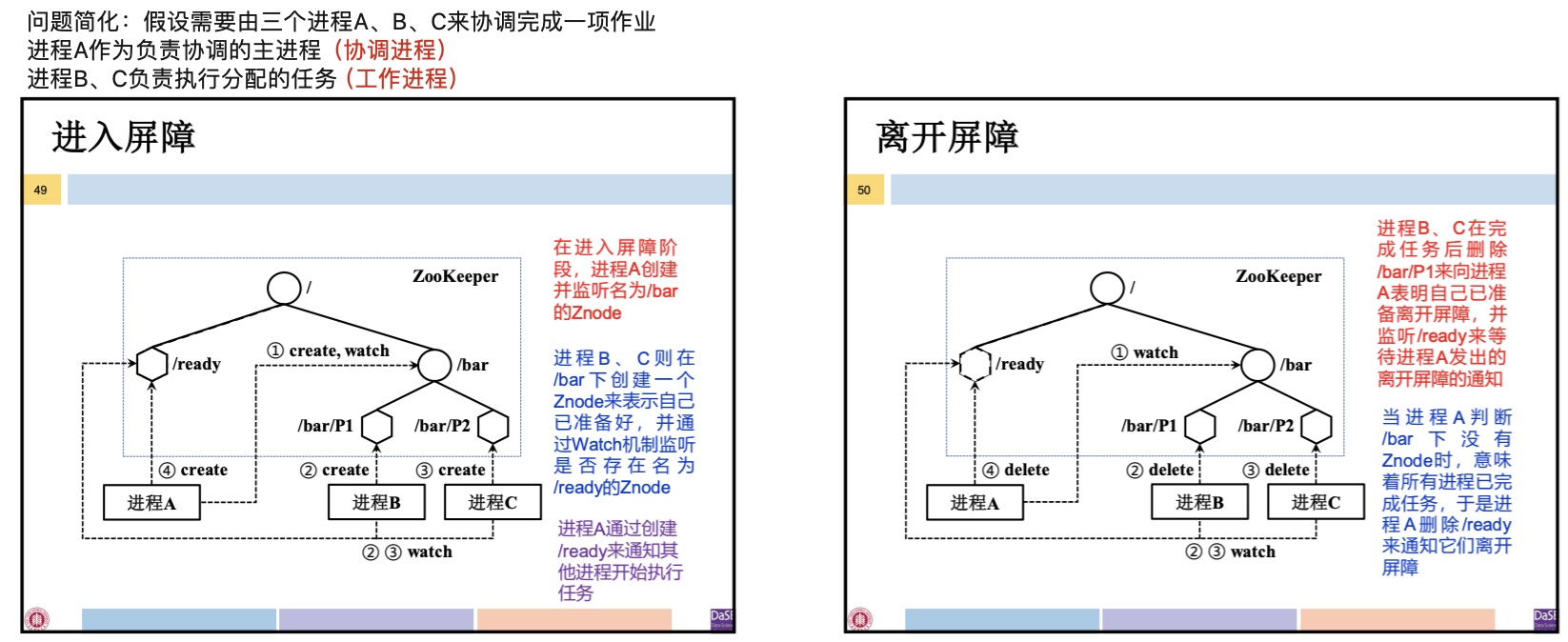
场景:BSP 模型要求在每一轮迭代计算的开始和结束时同步所有参与的进程。
“双屏障”机制:进入屏障时,需要足够多的进程准备好;当所有进程执行完任务时,才可离开屏障。
“双屏障”机制的实现:
- 进入屏障
- 协调进程创建名为 /bar 的 Znode,每个工作进程都到 /bar 下注册,并监听是否存在 /ready Znode
- /bar 下注册的进程数达到要求后,协调进程创建 /ready Znode,通知工作进程开始执行任务
- 离开屏障
- 每个工作进程完成任务后删除其在 /bar 下注册的 Znode
- /bar 下无 Znode 时,协调进程删除 /ready,通知工作进程离开屏障

 浙公网安备 33010602011771号
浙公网安备 33010602011771号