chapter4 批处理系统Spark
Spark最初的设计目标是基于内存计算的大数据批处理系统,用于构建大型的、低延迟的数据分析应用程序。
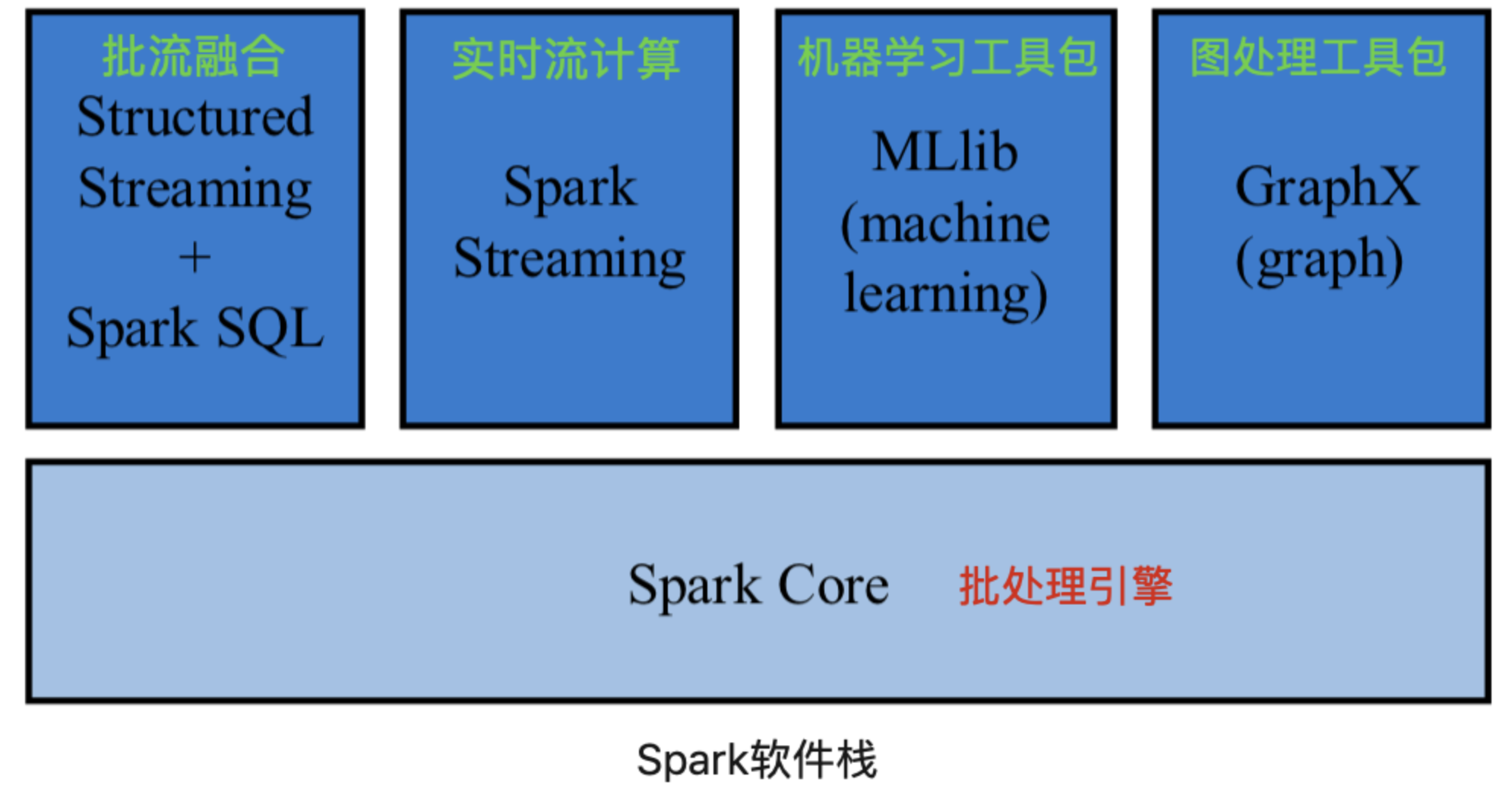
Spark从最初仅使用内存的批处理系统,转为内外存同时使用的批处理系统,增加 Spark Streaming 支持实时流计算,Structured Streaming 支持批流融合,也提供机器学习工具包 MLlib 和图处理工具包 GraphX。因而 Spark 已形成较完整的软件栈。
本章讲述的 Spark 实际上是指 Spark Core 内容。
1 设计思想
1.1 MapReduce的局限性
- MapReduce仅提供map和reduce两个编程算子,编程框架的表达能力有限,用户编程复杂。
- 单个作业中,需要Shuffle的数据以阻塞方式传输,磁盘I/O开销大,延迟高。
- 需要Shuffle的数据先由Map任务将计算结果写入本地磁盘,之后Reduce任务才能读取该计算结果。
- 多个作业之间衔接涉及I/O开销,应用程序的延迟高。
- 特别是延迟计算,迭代中间结果的反复读写,使得整个应用程序的延迟非常高
- 资源管理和作业管理紧耦合。
1.2 数据模型
Spark 将数据抽象为弹性分布式数据集 RDD,具有3个特性:
- Resilient:具有可恢复的容错特性
- Distributed:每个RDD分为多个分区,不同分区存在集群不同节点,每个分区是一个数据集片段
- Dataset:Spark 操作对象是抽象的数据集,而不是文件
1.3 计算模型
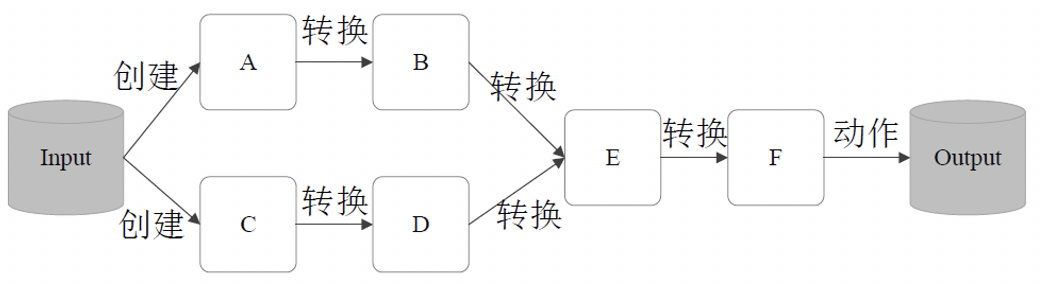
Spark提供丰富的操作算子对RDD进行变换。操作算子分为:
- 创建:从本地内存或外部数据源创建RDD,提供数据输入的功能。
- 转换 Transformation:描述RDD的转换逻辑,提供对RDD进行变换的功能。
- 行动 Action:标志转换结束,触发
DAG生成。- 行动操作包含数据输出类、count、collect等操作算子
RDD是只读的,不可变。RDD转换/行动操作会不断生成新的RDD,而不改变原有的RDD。
—— 遵循函数式编程的特性(变量值是不可变的)
为什么这样设计?
对RDD进行并行转换操作时,RDD的不变性能简化设计,也能保证容错恢复
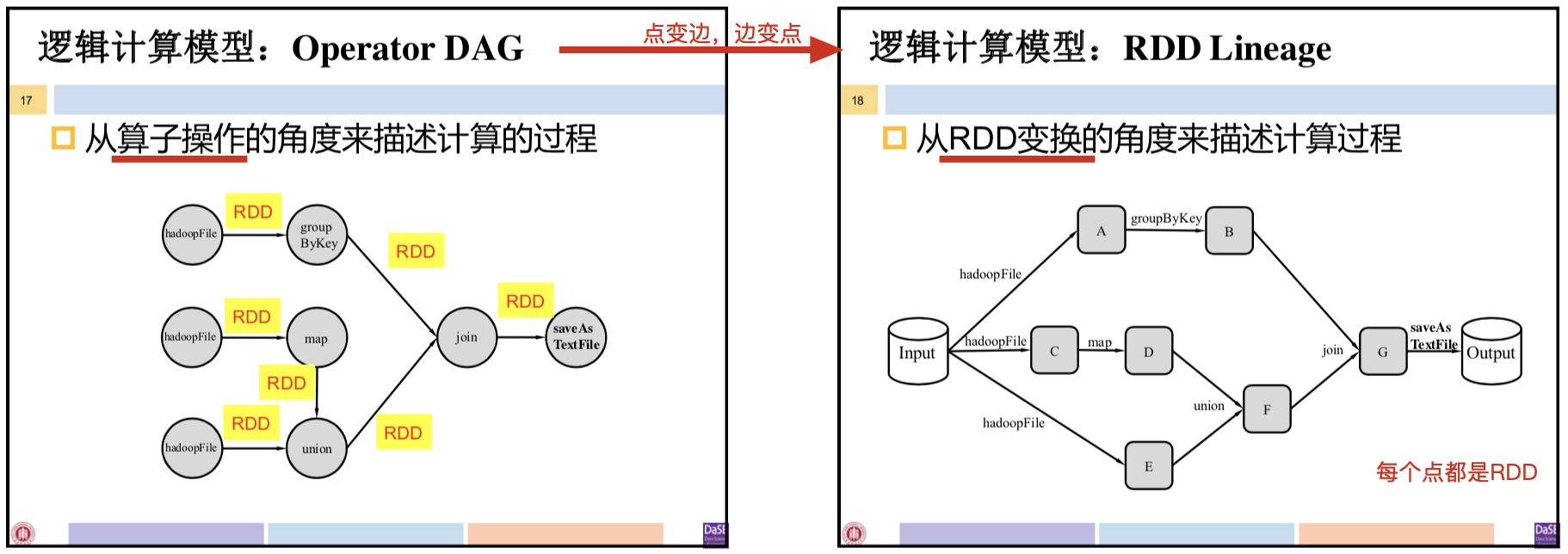
Spark的逻辑计算模型:Operator DAG、RDD Lineage
- Operator DAG 描述的主体是算子,RDD Lineage 描述的主体是数据
- RDD Lineage中,通过读入外部数据源进行RDD创建,经过一系列转换操作,每次都产生不同的RDD供下一个转换操作使用,最后一个RDD经过“行动”操作进行转换并输出到外部数据源。
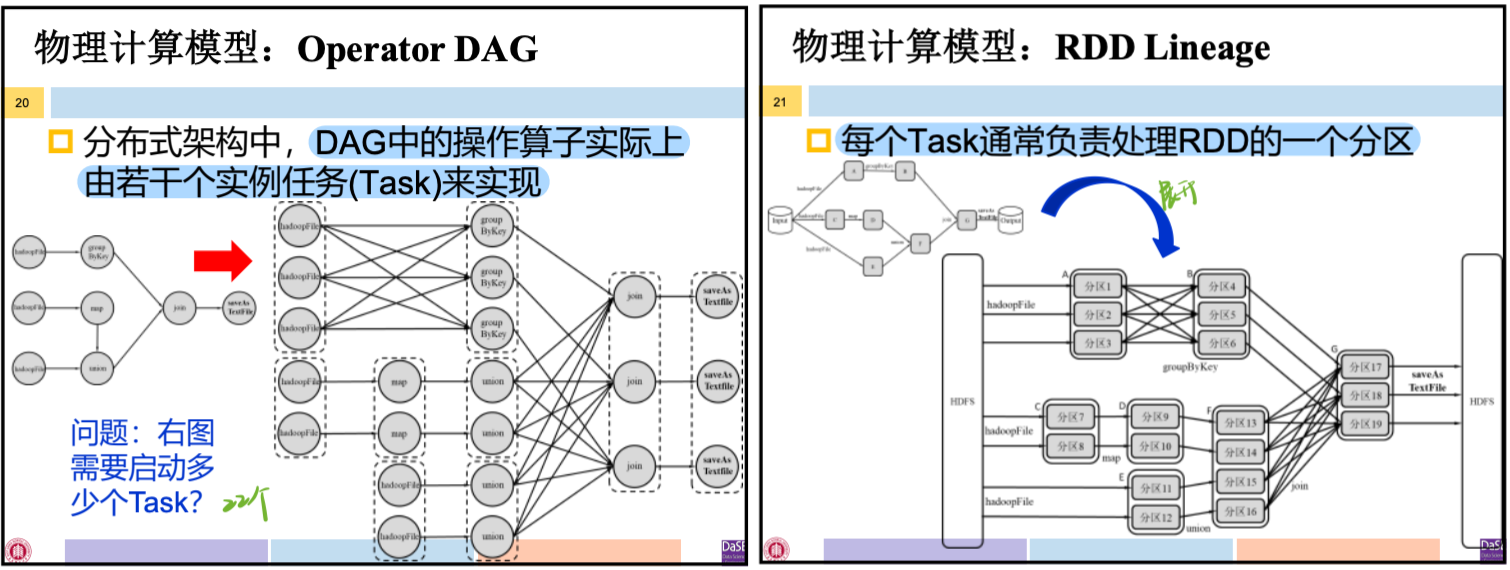
Spark的物理计算模型
2 体系架构
2.1 架构图
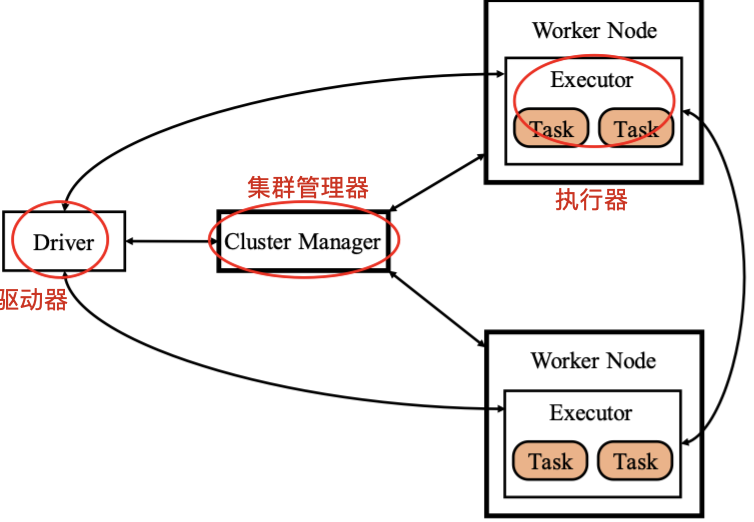
抽象的Spark架构图,包含:集群管理器、执行器、驱动器。
- Cluster Manager:集群管理器,负责管理整个系统的资源,监控工作节点。
- 根据Spark部署方式的不同,Spark可分为:
- Standalone模式:不使用Yarn等其他资源管理系统,该模式的集群管理器包含Master、Worker
- Yarn模式:将Spark与Yarn一起部署,该模式的集群管理器包含ResourceManager、NodeManager
- 根据Spark部署方式的不同,Spark可分为:
- Executor:执行器,负责任务执行。
- 本身是运行在工作节点上的一个进程,启动若干线程Task或线程组TaskSet执行任务
- 在Standalone部署方式下,Executor进程名称为Coarse Grained Executor Backend
- Driver:驱动器,负责启动应用程序的主方法并管理作业运行。
⚠️MapReduce中Task是进程,Spark中Task是线程。
Spark架构实现资源管理、作业管理的分离:Cluster Manager负责集群资源管理、Driver负责作业管理。
Standalone模式下Spark的架构图(没画Driver)
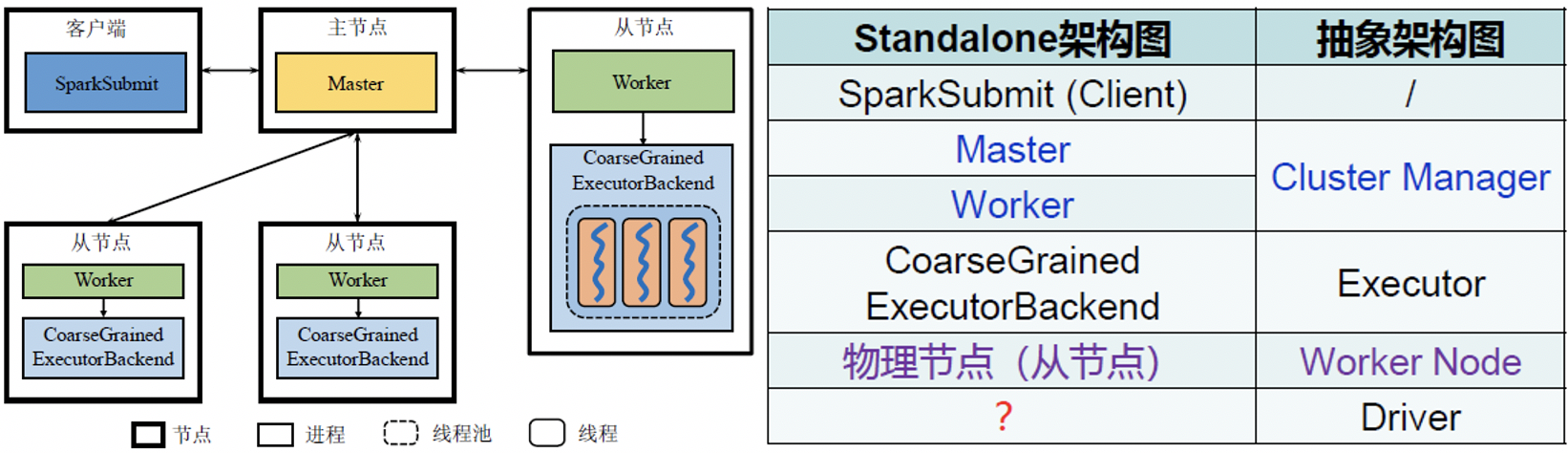
Standalone中的Driver:
- 逻辑上,Driver独立于主节点、从节点以及客户端
- 但根据应用程序的不同运行方式,Driver可以不同形式存在
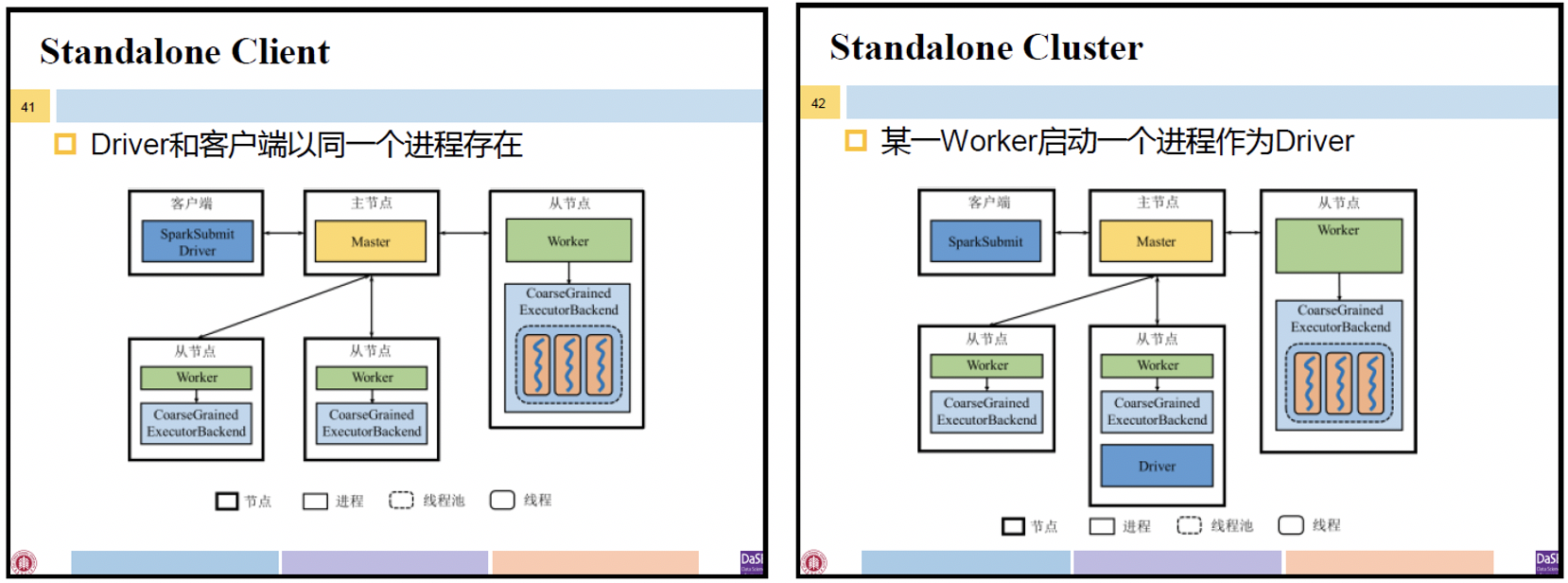
- Client方式:Driver和客户端同一个进程
- Cluster方式:系统将由某一Worker启动一个进程作为Driver(DriverWrapper)
客户端提交应用程序时可以选择Client或Cluster。
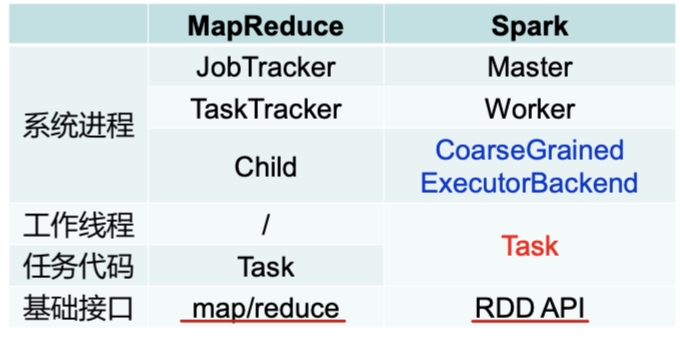
Spark系统🆚MapReduce系统
- 系统进程角度:均由位于主节点负责整个系统管理的进程(JobTracker 🆚 Master)、位于从结点负责该结点管理的进程(TaskTracker 🆚 Worker)、负责任务执行的进程构成(Child 🆚 CoarseGrainedExecutorBackend)。
- 任务执行角度:MapReduce采用多进程执行模型,Child进程执行任务代码Task;Spark采用多线程执行模型,Task任务代码同时以工作线程的形式存在。
- 基础接口角度:MapReduce只提供map、reduce两个操作算子作为编程接口,Spark提供基于RDD的编程接口
Why 要把MapReduce中的Task由进程改为线程?
进程是资源分配的基本单位,线程是CPU调度的最小单位。
使用线程负载量级下降,创建和销毁的代价更低,更节省资源。但两个线程若位于同一进程会互相干扰。
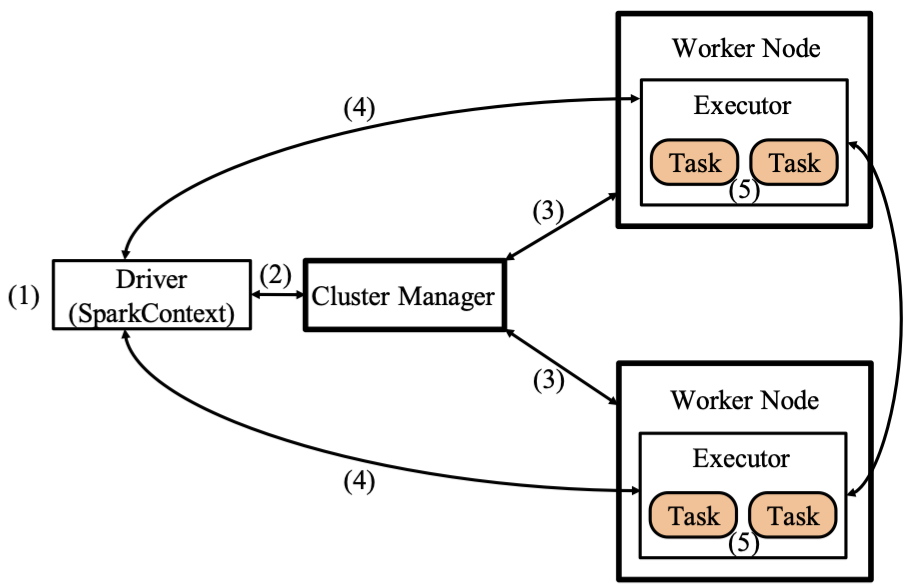
2.2 应用程序执行流程
- 启动Driver以Standalone模式为例
- 如果使用Client部署方式,客户端直接启动 Driver,并向Master注册
- 如果使用Cluster部署方式,客户端将应用程序提交给Master,由Master选择一个Worker启动 Driver进程(DriverWrapper)
- 构建基本运行环境,即由Driver创建SparkContext,向Cluster Manager进行资源申请,由Driver进行任务分配和监控
- Cluster Manager分配资源,通知工作节点启动Executor进程(该进程内部以多线程方式运行任务)
- Executor进程向Driver注册
- SparkContext构建DAG并进行任务划分,交给Executor进程中的线程来执行任务
- 所有Task运行完毕后写入数据并释放资源
3 工作原理
Driver创建的SparkContext维护了应用程序的基本运行信息
- SparkContext根据RDD的依赖关系构建DAG图
- DAG Scheduler将DAG图分解为多个Stage,一个Stage作为一个TaskSet(一组任务的集合)交给Task Scheduler
- Task Scheduler将Task分发给各个Worker节点上的Executor执行
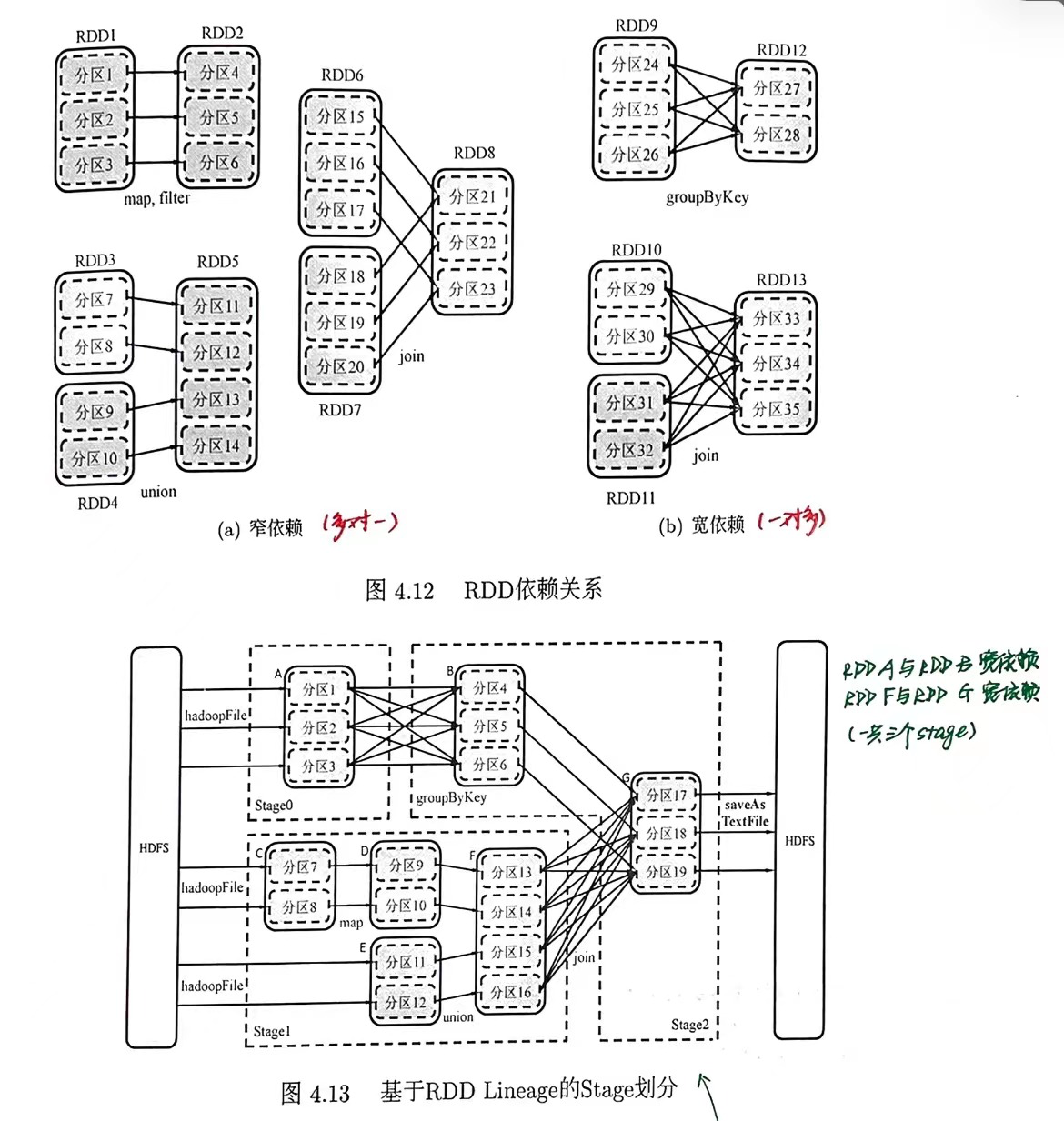
3.1 Stage划分
RDD的依赖关系:
窄依赖:父RDD的每个分区最多被一个子RDD的分区所用(多对一)宽依赖:存在一个父RDD的一个分区对应一个子RDD的多个分区(一对多)- DAG Scheduler 通过分析各个RDD中分区间的依赖关系划分Stage:
- 在DAG中进行反向解析,遇到宽依赖就生成新的Stage
- 遇到窄依赖就将当前RDD加入到Stage
Stage内部生成的RDD之间是窄依赖,Stage输出RDD和下一个Stage输入RDD之间是宽依赖。只有Stage之间的数据传输需要Shuffle。
Stage类型:(二者都能从外部数据源/ShuffleMapStage的输出获取输入数据)
ShuffleMapStage:输出可作为另一个Stage的输入- 特点:不是最终的Stage;输出必须经过Shuffle过程,并作为后续Stage的输入;在一个DAG中可有可无
ResultStage:输出直接产生最终结果- 特点:是最终的Stage,输出就是结果;在一个DAG中必须有
上图中 stage0、stage1是ShuffleMapStage,stage2是ResultStage
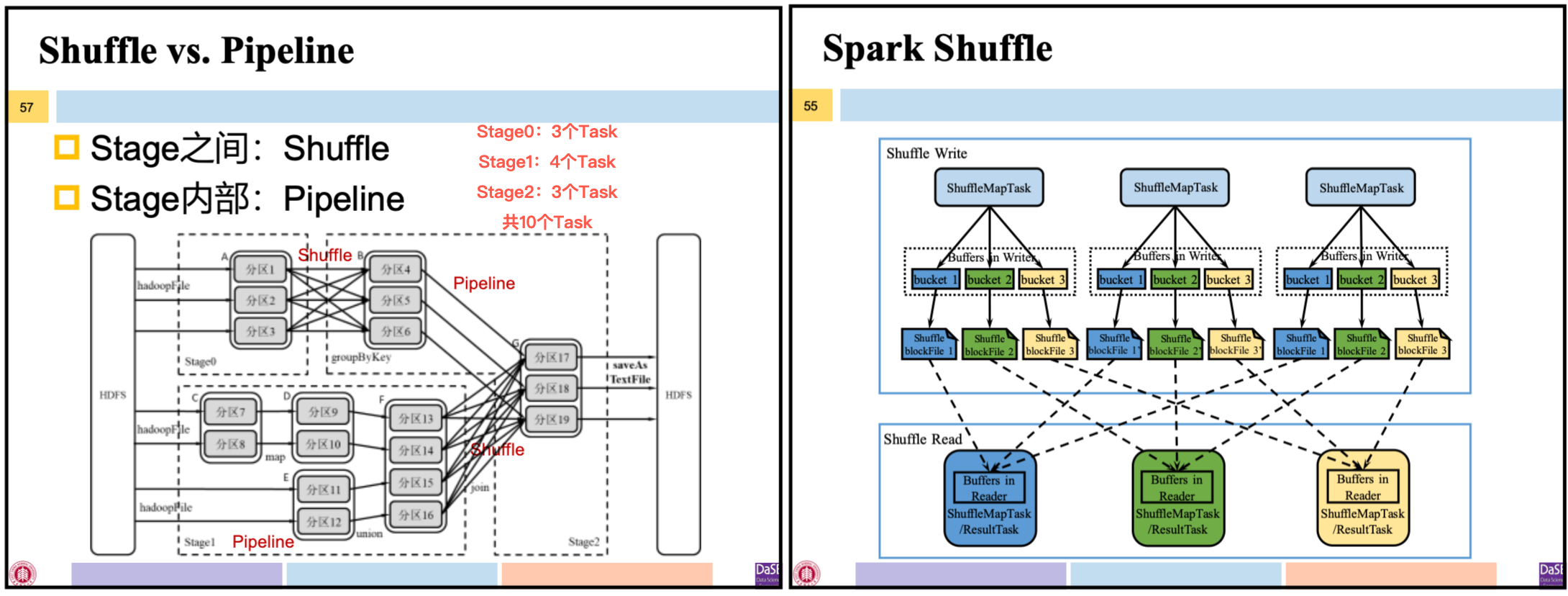
3.2 Stage内部数据传输
Stage内所有依赖关系都是窄依赖,可以实现pipline方式的数据传输。
- 与MapReduce的Shuffle方式不同,pipline方式不要求物化前序算子的所有计算结果
- Spark根据每个Stage输出RDD中分区个数决定启动多少个Task,执行该Stage中的操作。上图中stage1启动4个Task并以流水线方式执行操作
ShuffleMapStage中的Task称为ShuffleMapTask,ResultStage中的Task称为ResultTask。
3.3 Stage之间数据传输
Stage间所有依赖关系都是宽依赖,不能进行pipline传输,只能shuffle。
- Shuffle过程可能发生在两个ShuffleMapStage之间或ShuffleMapStage与ResultStage之间
- Task层面看,Shuffle发生在两组ShuffleMapTask之间或ShufflMapTask与ResultTask之间
将Shuffle阶段分为:
Shuffle Write阶段:ShuffleMapTask将输出RDD的记录按分区函数partition,划分到bucket中物化到本地磁盘形成ShuffleblockFile,之后才能在Shuffle Read阶段被拉取Shuffle Read阶段:ShuffleMapTask或ResultTask读取相应ShuffleblockFile,存入缓冲区进行后续计算
3.4 应用与作业
Application:用户编写的Spark应用程序,指一个SparkContext从创建到关闭
逻辑执行角度看:一个Application由多个DAG构成,一个DAG由多个Stage构成,一个Stage由多个窄依赖的RDD构成
物理执行角度:一个Application由多个Job构成,一个Job由多个TaskSet构成,一个TaskSet由多个没有Shuffle关系的Task构成
MapReduce 🆚 Spark:
MapReduce中一个应用就是一个作业 application = Job
Spark中一个应用可由多个作业构成(Job/DAG)
4 容错机制
故障类型:
- Master故障:重启系统 or 借助ZooKeeper实现高可用
- Worker故障/Executor故障:重启发生故障的进程 or 将这些进程负责的任务交给新的Worker/Executor
- Driver故障:重启系统
4.1 RDD持久化
计算过程中会不断地产生新的RDD, 一旦达到内存相应存储空间的阈值,Spark会使用置换算法(e.g.,LRU) 将部分RDD的内存空间腾出。若不做任何声明,这些RDD会被直接丢弃。但某些RDD在后续很可能会被再次使用。
实现RDD持久化
- 调用RDD的
persist(Storagelevel)方法,接收Storagelevel参数可配置各种持久化级别 - 调用
cache()方法,相当于persist(MEMORY_ONLY),在内存中缓存对象,若内存不足直接丢弃
系统的RDD计算过程中也会进行自动(隐式)持久化,即自动保存一些Shuffle操作的中间结果
4.2 故障恢复
结合计算过程中某些持久化的RDD和Lineage信息可进行故障恢复
- 重新计算丢失分区
- 重算过程在不同节点之间可以并行
利用RDD Lineage的故障恢复 🆚 数据库恢复:
- RDD Lineage:记录粗粒度的特定数据Transformation操作
- 数据复制或日志:记录细粒度的操作
4.3 检查点
RDD持久化机制不足:
- Lineage可能过长或宽依赖过多,会造成恢复成本过高
- RDD持久化机制保存到集群内机器的磁盘,并不完全可靠
检查点机制:将RDD写入外部可靠的(本身具有容错机制)分布式文件系统,如HDFS。
- 检查点之后的节点出现故障,则从做检查点的RDD开始按Lineage重新进行,可加快恢复过程
- 在实现层面,写检查点的过程是一个独立的作业,在用户作业结束后运行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号