chapter3 批处理系统MapReduce
MapReduce指Hadoop项目中的MapReduce。
MapReduce 主要用于处理大批量的静态数据。——批处理系统
静态数据指计算开始前这些数据就已经确定。
1 设计思想
1.1 MPI与MapReduce
MapReduce出现前,程序员使用MPI并行处理数据。MPI是一个信息传递接口,包括协议和语义说明。MPI并行编程是用标准串行语言书写的代码加上用于消息接收和发送的库函数调用。
MPI局限性:
-
用户编程角度:程序员要考虑进程之间的并行问题,且进程间的通信需要用户在程序中显示表达,增加编程复杂性
-
系统实现角度:MPI本身没有容错能力,除非编写程序时添加故障恢复功能
MapReduce和MPI的重要区别:分布式计算系统本身需具备容错能力
1.2 数据模型
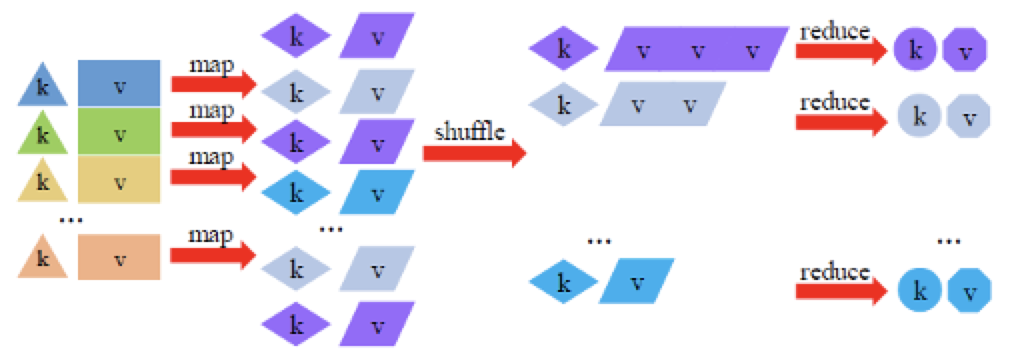
MapReduce 将数据抽象为键值对,处理过程中对键值对进行转换
| 函数 | 输入 | 输出 | 说明 |
|---|---|---|---|
| Map | [k1,v1] | List([k2,v2]) | 将输入键值对做变换,产生若干新的键值对 |
| Shuffle | List([k2,v2]) | [k2,List(v2)] | 将键相同的键值对发送给同一个Reduce任务 |
| Reduce | [k2,List(v2)] | [k3,v3] | 对相同键的键值进行计算,根据需要将计算结果进行一次键值对转换并输出 |
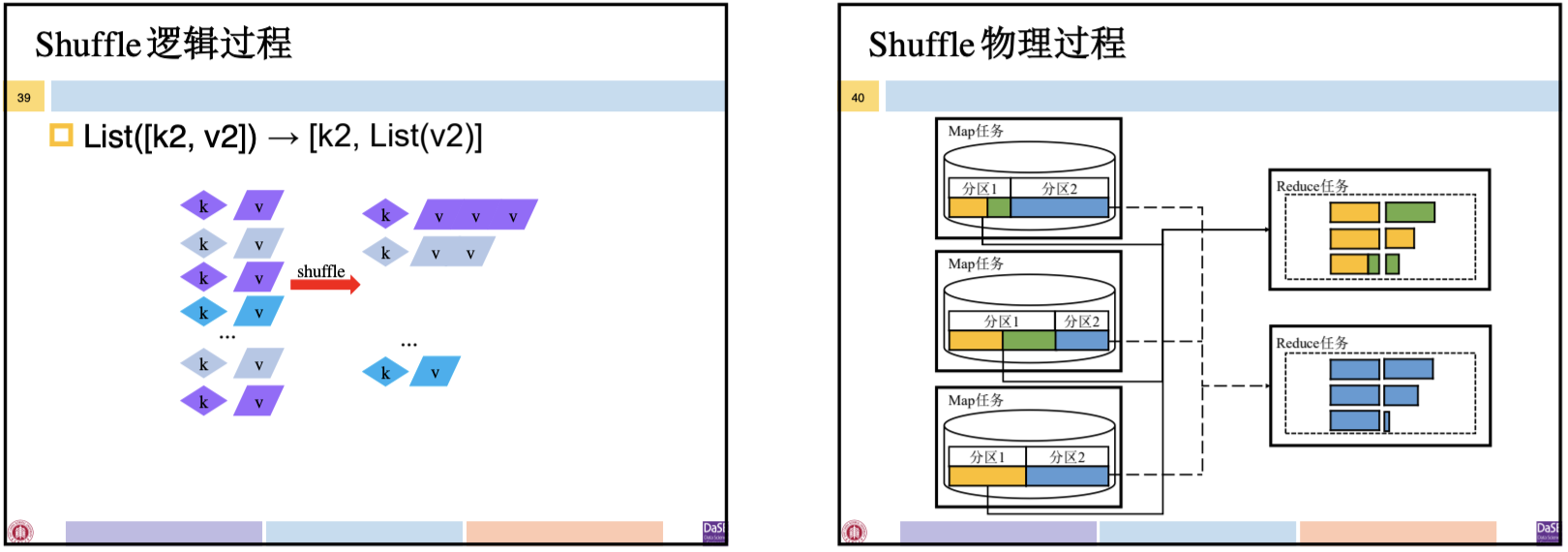
Shuffle:将Map转换得到的键值对按照键进行分组
1.3 计算模型
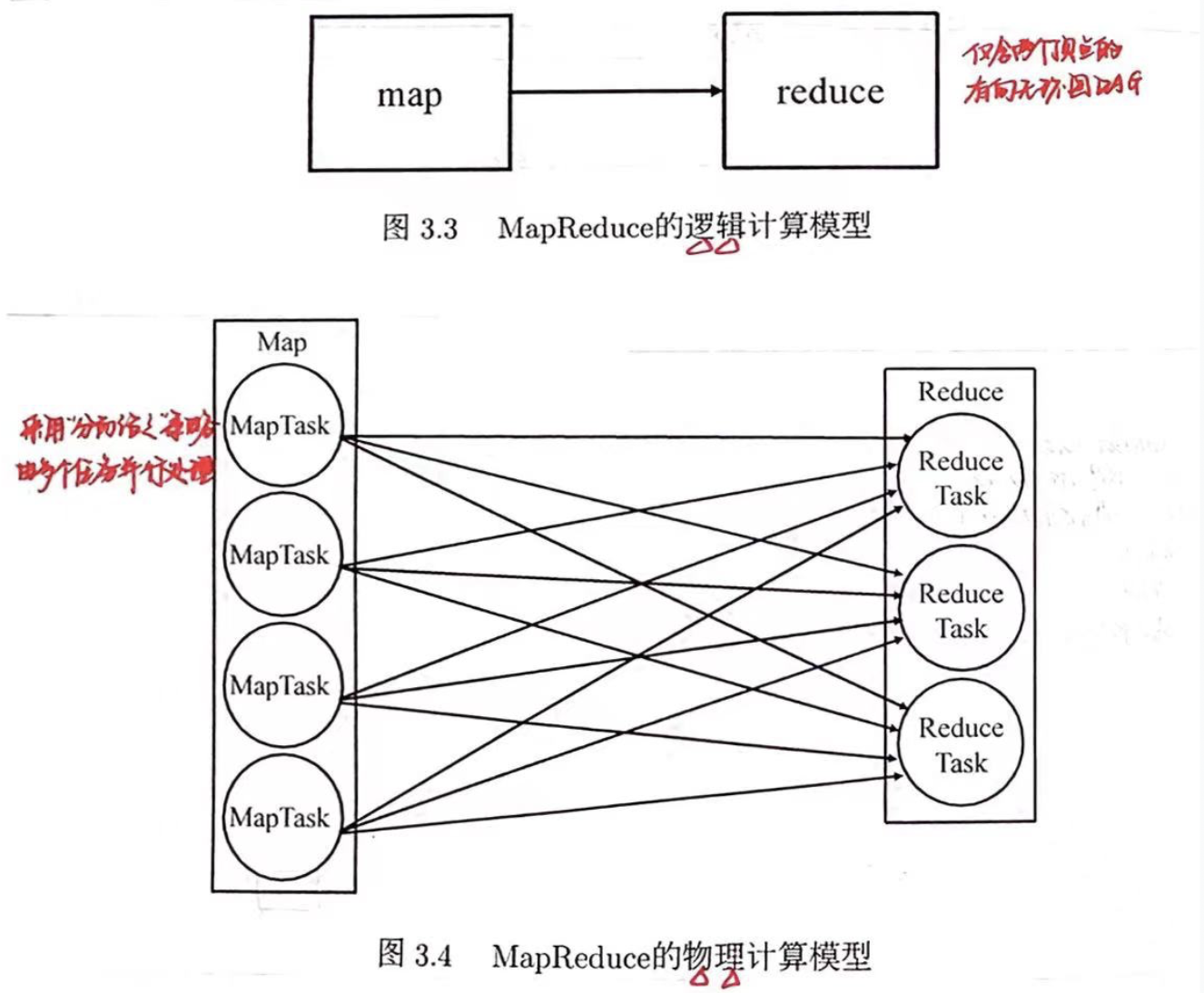
MapReduce将复杂的、运行于大规模集群上的并行计算过程高度抽象为Map和Reduce两个过程,采用“分而治之”的策略对这些数据进行并行处理。
逻辑计算模型:仅含两个顶点的有向无环图(DAG)
物理计算模型:map、reduce两个算子在物理上需要由若干个实例(进程/线程)来实现
MapReduce相较于MPI的优点:
-
用户编程角度:用户不需要掌握分布式并行编程细节
-
系统实现角度:进程出现故障时,MapReduce框架可自动进行容错处理,无需用户参与
2 体系架构
2.1 架构图
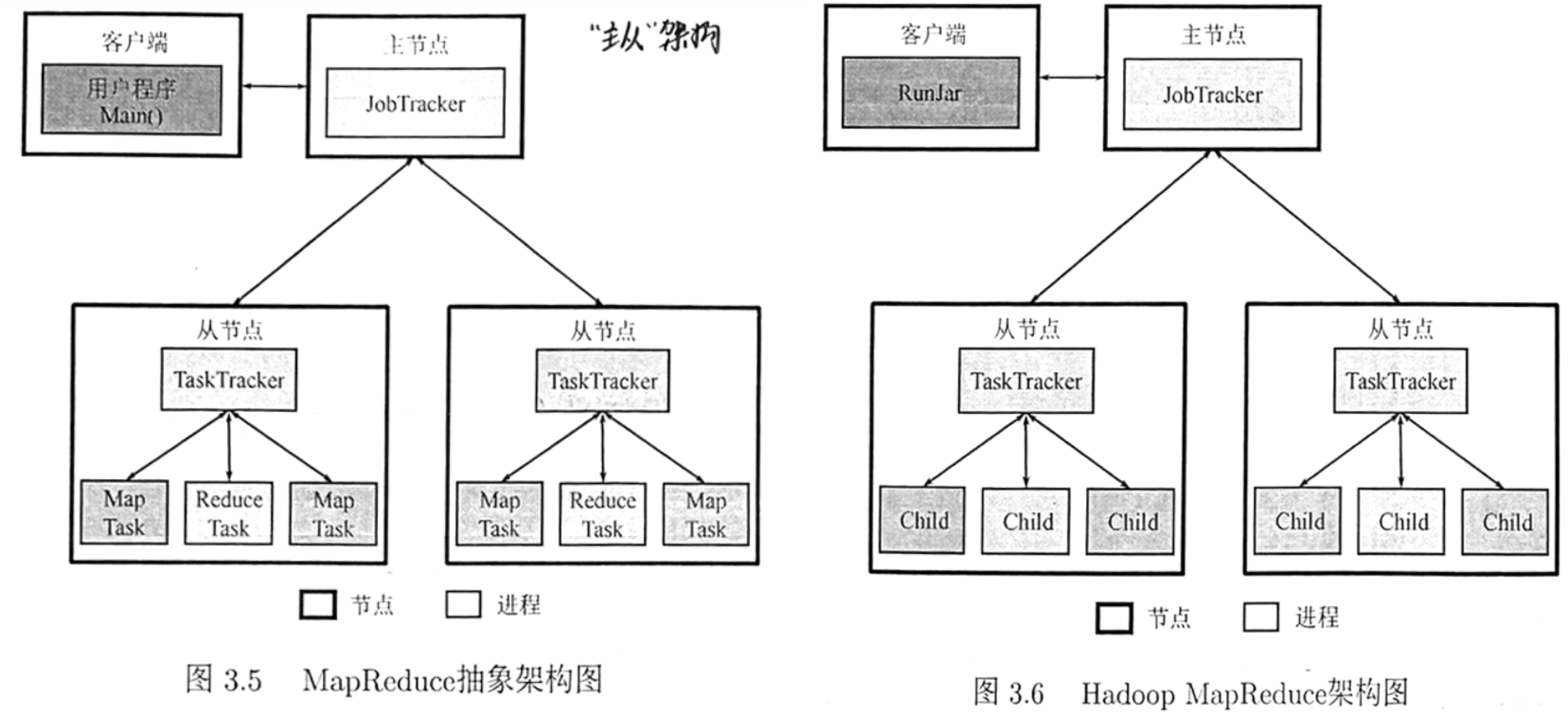
MapReduce 采用“主从”架构,主要工作部件有 JobTracker、TaskTracker、Task、客户端。
-
JobTracker:
-
集群资源管理:通过监控TaskTracker来管理系统拥有的计算资源
-
集群作业管理:将作业Job拆分为任务Task,进行Task调度、跟踪Task的运行进度、资源使用量等信息
-
-
TaskTracker:节点任务管理。
-
执行命令:接受Job Tracker发送过来的命令并执行
-
资源划分:使用slot等量划分本节点上的资源量,Task获取到slot后才能运行
-
汇报信息:通过心跳将本节点上的资源使用情况和任务运行进度汇报给JobTracker
-
-
Task:负责任务执行。
- JobTracker根据TaskTracker汇报的信息进行调度,命令存在空闲slot的TaskTracker启动Task进程执行map/reduce任务
(在Hadoop MapReduce的实现中,该进程称为Child)
-
Client:
-
提交作业:用户编写MapReduce程序通过Client提交到 JobTracker
-
作业查看:用户可通过Client提供的接口查看作业运行状态
(在Hadoop MapReduce的实现中,该进程的名称为 RunJar)
-
MapReduce与HDFS关系:
- 计算与存储分离
- 计算向数据靠拢,而不是数据向计算靠拢(避免通过网络读写输入输出数据的高代价)
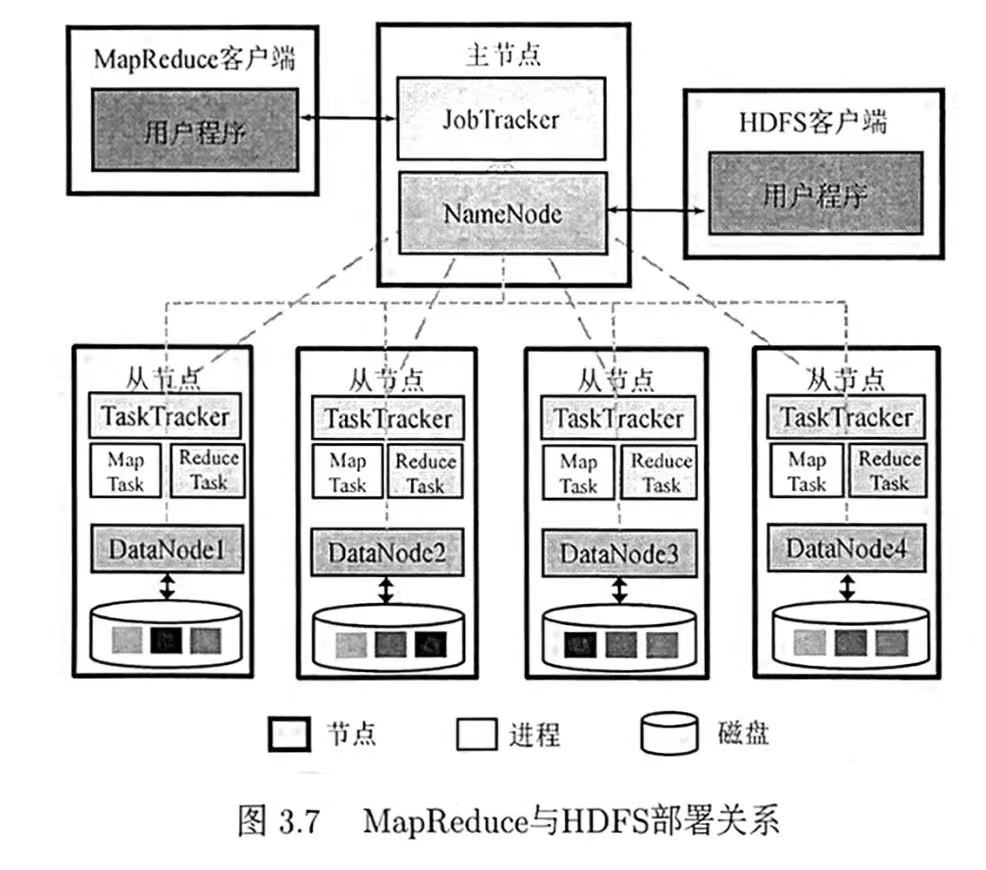
JobTracker、NameNode部署在同一物理节点,TaskTracker、DataNode部署在同一物理节点。
这种部署方式下,MapReduce可选择存有输入数据的DataNode所在节点启动MapTask,ReduceTask的输出数据可存入所在节点的DataNode。
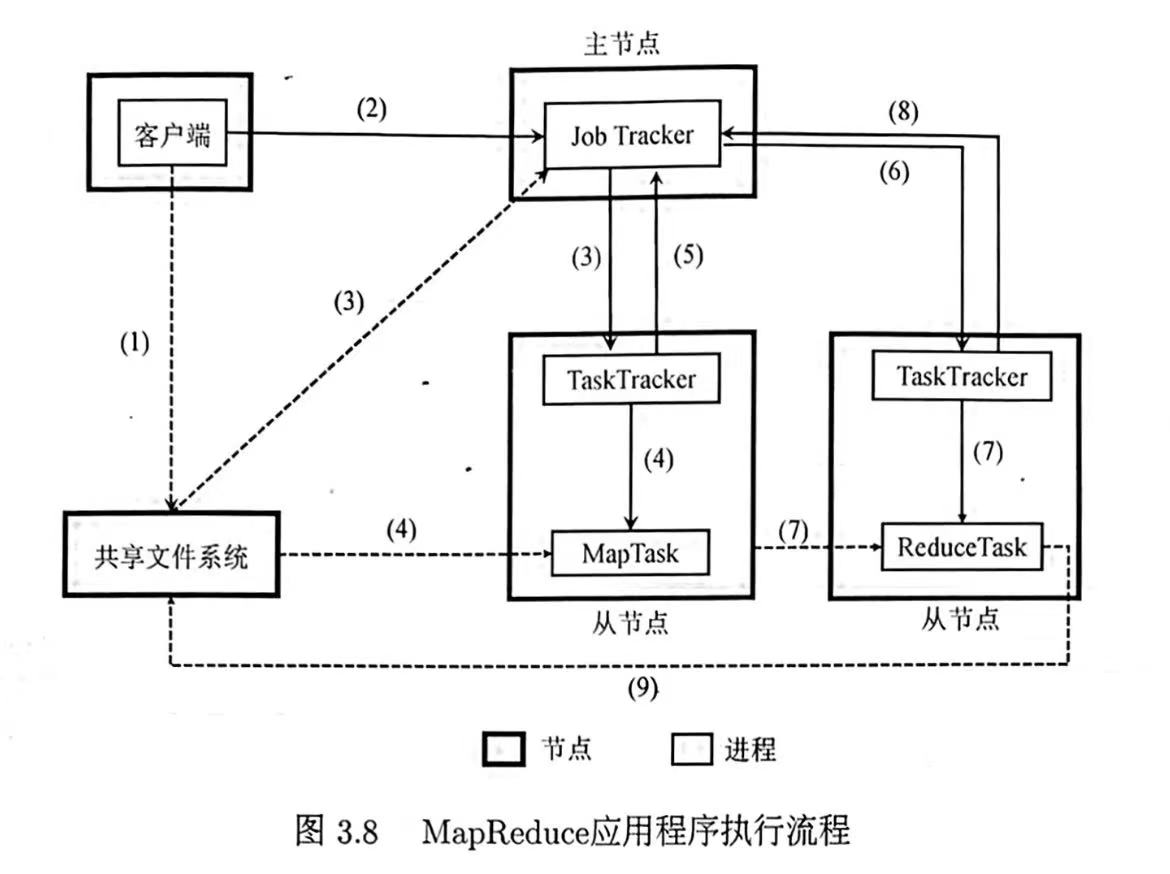
2.2 应用程序执行流程
- Client将用户编写的MapReduce作业信息上传到共享文件系统HDFS
- Client提交作业给JobTracker
- JobTracker读取作业信息,生成MR任务,调度给有空闲slot的TaskTracker
- TaskTracker根据JobTracker的指令启动Child进程执行Map任务,Map任务从文件系统中读取输入数据
- JobTracker从TaskTracker处获得Map任务进度信息
- Map完成后,JobTracker将Reduce任务分发给TaskTracker
- TaskTracker根据JobTracker的指令启动Child进程执行Reduce任务,Reduce任务从Map端读取数据
- JobTracker从TaskTracker处获得Reduce任务进度信息
- Reduce完成计算后将结果写入文件系统,作业执行完毕
3 工作原理
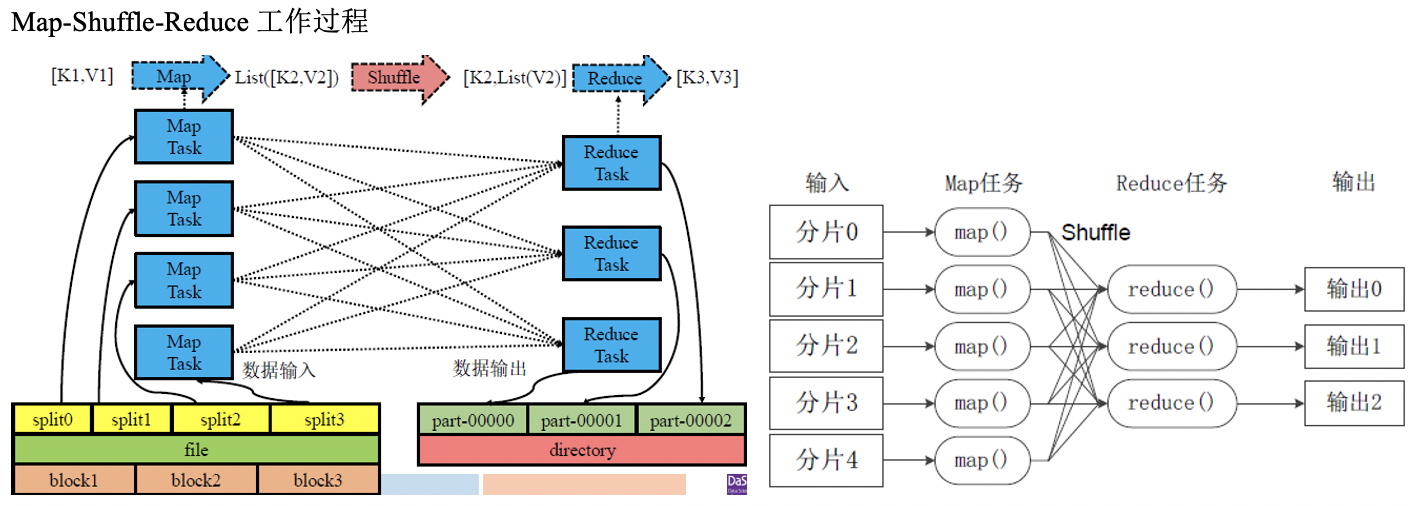
工作原理:
- Map任务从共享文件系统HDFS读取需处理的数据,解析出键值对;
- 经过Shuffle键相同的键值对会发送给相同的Reduce任务;
- Reduce任务对这些键值对进行计算后将结果以新的键值对写入HDFS。
只有Map任务和Reduce任务之间才发生数据交换(不同Map任务间不会通信,不同Reduce任务间不发生信息交换)
所有数据交换都通过MapReduce框架的Shuffle实现,用户不能显式地从一台机器向另一台机器发送消息
——MapReduce与MPI的区别
一般将MapReduce过程划分为3阶段:Map、Shuffle、Reduce。若考虑数据输入与输出,共有5阶段。
数据输入:文件到Map任务可处理的键值对的映射
数据输出:从Reduce任务计算得到的键值对到文件的映射
⚠️Shuffle 阶段指 Map任务和Reduce任务之间数据交换的过程,并没有专门的Task进程用于Shuffle。
3.1 数据输入
(完成从存储系统中待读取的文件到Map任务可处理的键值对记录之间的映射)
问题:文件分块存储,可能出现跨块记录
解决:定义输入格式InputFromat——通过定义分片、键值对解析完成物理存储(HDFS文件块)到MapReduce可处理的逻辑数据的映射
- 数据逻辑划分
- InputFormat根据预定义的格式,将输入数据逻辑上划分为若干个切片(Split)
- Map任务读取的单位为Split,而不是物理的文件块Block
- 切片数量决定Map任务的个数,一个切片数据一般由一个Map任务处理
- 键值对解析
- 给定切片,InputFormat将根据元信息将切片的数据解析为键值对
3.2 Map阶段
Map逻辑过程:将一个键值对转为多个键值对:[k1, v1]——>List([k2, v2])
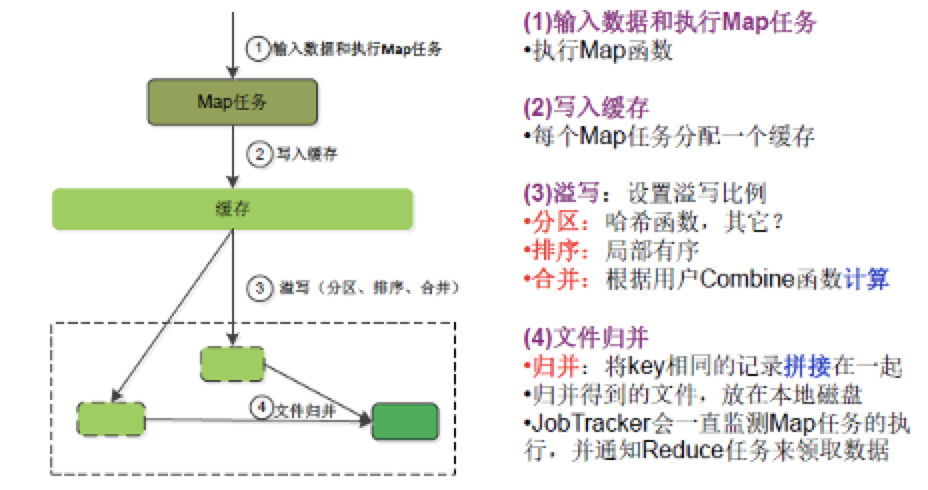
Map物理过程:
- 系统根据Map方法将输入映射为 [k2,v2] 键值对
- 根据partition方式,确定 [k2,v2] 键值对所属分区,将得到的 ([k2,v2], partitionID) 并写入缓冲区
- 总分区数 = Reduce任务数
- 每个 Map 任务都有一个缓冲区
- 排序:当缓冲区数据达到阈值时,Map任务会锁定当前阈值内的缓冲区,缓冲区内按 partitionID排序,同一分区内按键排序
- 合并:若编写的MapReduce程序定义了
combine方法,将执行该方法将键相同的键值对进行合并
- 合并:若编写的MapReduce程序定义了
- 溢写:Map任务将排序后结果溢写到磁盘形成文件
- 同一Map任务会产生多个磁盘文件,故同一分区的键值对将分布在多个磁盘文件中
- 文件归并:当磁盘中溢出文件达到阈值时,Map 任务会将其归并为一个文件,使 属于同一分区的所有键值对连续存储
⚠️ 排序及溢写过程不妨碍新的键值对写入缓冲区。
Map任务的输出以一个大文件形式存在Map任务所在节点的本地磁盘中。

3.3 Shuffle阶段
将键相同的键值对发送给同一个Reduce任务:List([k2, v2])——>[k2, List(v2)]
何时Shuffle:
- 系统中Map任务完成率达到设定的阈值时,系统启动Reduce任务
- Reduce不会等到所有Map完成才拉取Map的输出结果,但拉取的数据一定是已完成了Map任务的数据,即已保存在磁盘上的文件
3.4 Reduce阶段
Reduce逻辑过程:对键相同的若干键值对转为一个键值对:[k2, List(v2)]——>[k3, v3]
Reduce物理过程:
- Reduce任务将拉取的数据放入内存缓冲区
- 排序:当缓存中存储的数据到达阈值时,Reduce对其按键进行归并排序
- 合并:若编写的MapReduce程序定义了
combine方法,将执行该方法将键相同的键值对进行合并
- 合并:若编写的MapReduce程序定义了
- 溢写:将缓存中的数据溢写到磁盘文件
- 文件归并:当磁盘中溢出文件达到阈值时,Reduce执行归并操作形成大文件,文件中键值对按键排序
- 最后一次归并操作的结果无需再写入磁盘,可直接执行Reduce方法处理(省去一次磁盘读写操作)
⚠️ 排序及溢写过程不妨碍Reduce拉取新的数据到缓存。

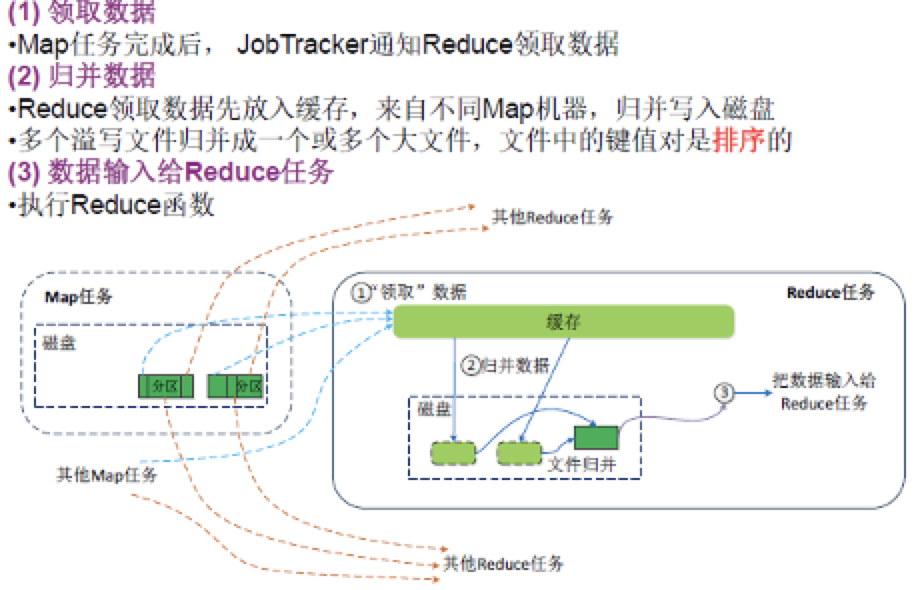
Reduce任务数量:
- 程序指定
- 最优的Reduce任务数量取决于集群中可用的Reduce任务槽(slot)数目
- 通常设置比slot数目小的Reduce任务个数
每个Reduce任务的输出结果将以一个文件的形式保存到指定的目录中,也就是说MapReduce输出结果是一组文件。
3.5 数据输出
完成从Reduce任务计算得到的键值对数据到物理存储之间的映射——输出格式OutputFormat
- 包括分隔符等元信息
- 系统将Reduce任务结果按OutputFormat格式写入HDFS
4 容错机制
-
主节点故障: JobTracker故障(宕机引起):重新启动JobTracker,所有作业需要重新执行
- MapReduce 中JobTracker的单点故障是该架构设计的缺点
-
从节点故障
- TaskTracker故障(宕机引起):JobTracker不会接收到TaskTracker的“心跳“,将失败的任务调度到其他TaskTracker重新执行
- Task故障(JVM内存不够退出):TaskTracker在下一次心跳里向JobTracker汇报任务故障,JobTracker将调度该任务到其他节点重试,若任务经过最大尝试次数后仍失败,则整个作业标记为失败
- 重试的Map任务:从输入路径(HDFS)重新读入数据
- 重试的Reduce任务:重新拉取Map端的输出文件
⚠️ MapReduce容错和HDFS是两回事

 浙公网安备 33010602011771号
浙公网安备 33010602011771号