chapter2 Hadoop文件系统
Doug Cutting 根据 GFS 和 MapReduce 的思想创建了开源的 Hadoop 项目。
通常认为 Hadoop 项目是 Google 发表的学术论文 GFS 和 MapReduce 的开源实现。
Hadoop的核心是分布式文件系统HDFS和MapReduce。

1 设计思想
分布式文件系统 HDFS 要解决的问题:
- 如何存储上百 GB/TB 级别的大文件
- 如何保证文件系统的容错
(HDFS 的目标是部署在由低廉的普通服务器甚至个人PC组成的庞大集群,集群中节点的故障是普遍现象) - 如何进行大文件的并发读写控制
HDFS 解决以上问题采用的思想:
- 文件分块存储:HDFS 将大文件分割为数据块(通常每块大小为64MB)这些数据块可分布到集群中不同的节点上。每个数据块在本地文件系统中以单独的文件存储。
- 分块冗余存储:每个数据块也要做冗余备份,多个备份分散到不同的节点上。
- 简化文件读写:避免读写冲突(文件一次写入后不再修改,仅允许多次读取)避免随机写(仅支持顺序写入,不允许随机写入)
采用 文件分块存储、分块冗余存储、简化文件读写 的思想解决 大文件存储、容错、并发读写控制的问题
2 体系架构
2.1 架构图
HDFS 采用“主从”架构,由 NameNode、Secondary NameNode、DataNode构成。
NameNode所在节点为主节点,Secondary NameNode所在节点是主节点的备份节点,DataNode所在节点为从节点。此外,客户端发起文件读写等操作请求。
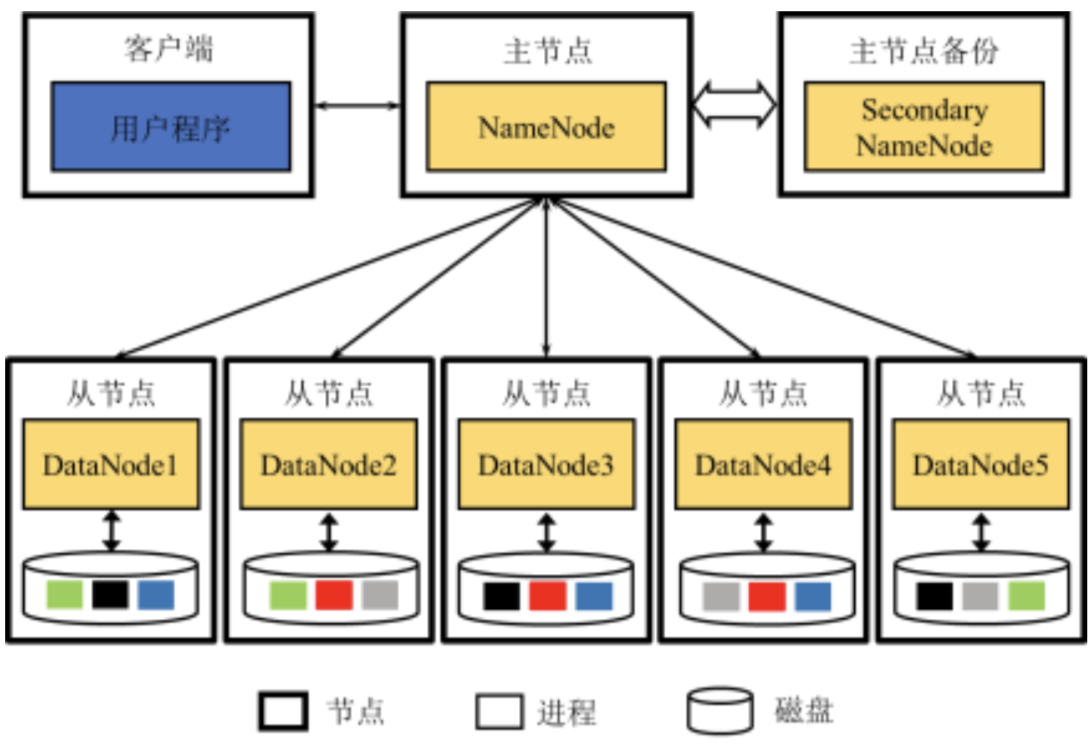
各组件功能:
- NameNode:负责 HDFS 的元数据管理及DataNode定位等工作
- Secondary NameNode:充当NameNode的备份
- DataNode:负责数据块的存储,为客户端提供实际的文件数据
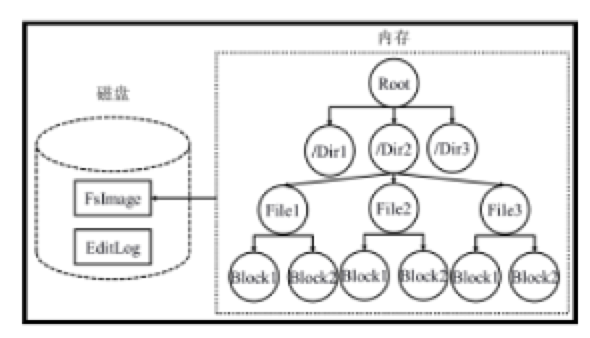
NameNode
NameNode在内存中维护树形结构的目录(HDFS的目录结构),其中 块信息只是指示了文件块存储的位置DataNode,并不实际存储文件。
FsImage文件:内存中的文件目录结构及其元信息在磁盘上的快照
Editlog文件:两次快照之间,针对目录及文件修改的操作,以日志形式记录
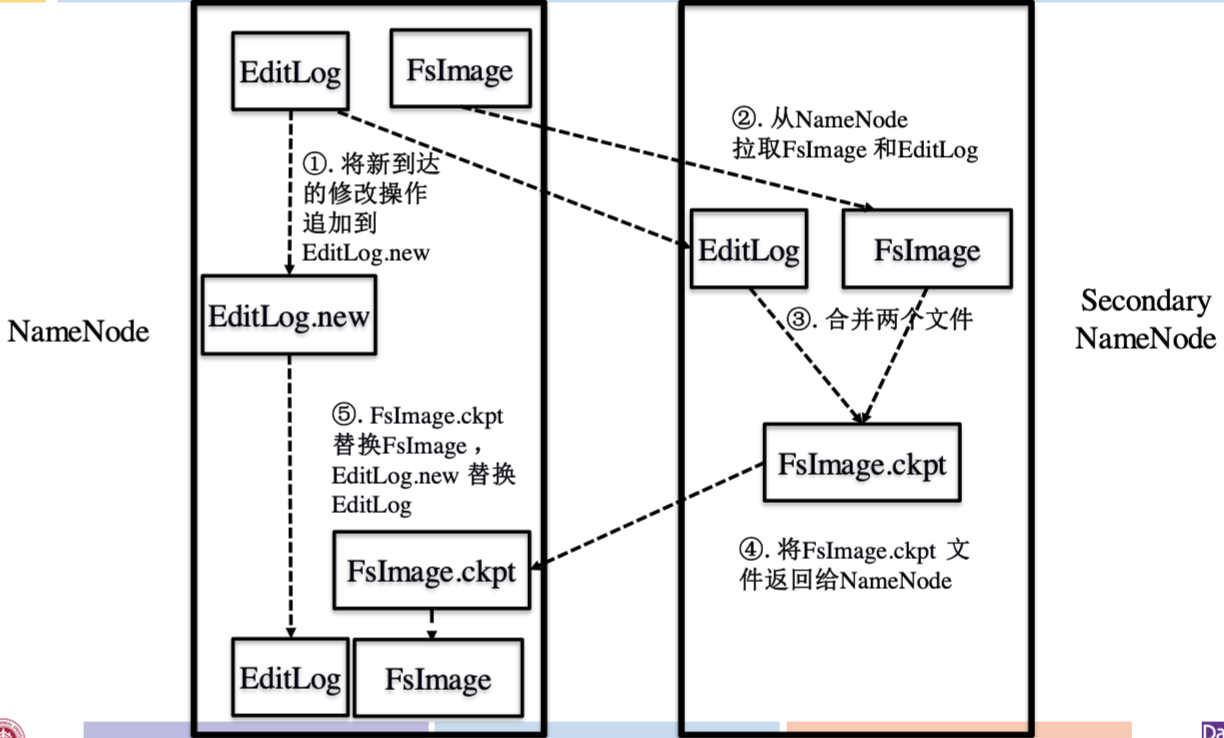
Secondary NameNode
Secondary NameNode作为NameNode的备份,一般在另一台单独的物理计算机上运行,定期备份 FsImage、Editlog两个文件,合并形成文件目录及其元信息的远程检查点,并将检查点返回给NameNode。
属于冷备份而不是热备份,因为一旦 NameNode宕机使用Secondary NameNode恢复,会丢失Editlog.new中的信息。
DataNode
DataNode 是HDFS复杂数据块实际存储的结点,根据NameNode控制信息进行数据块的存储(Linux文件形式)和检索。
2.2 应用程序执行流程
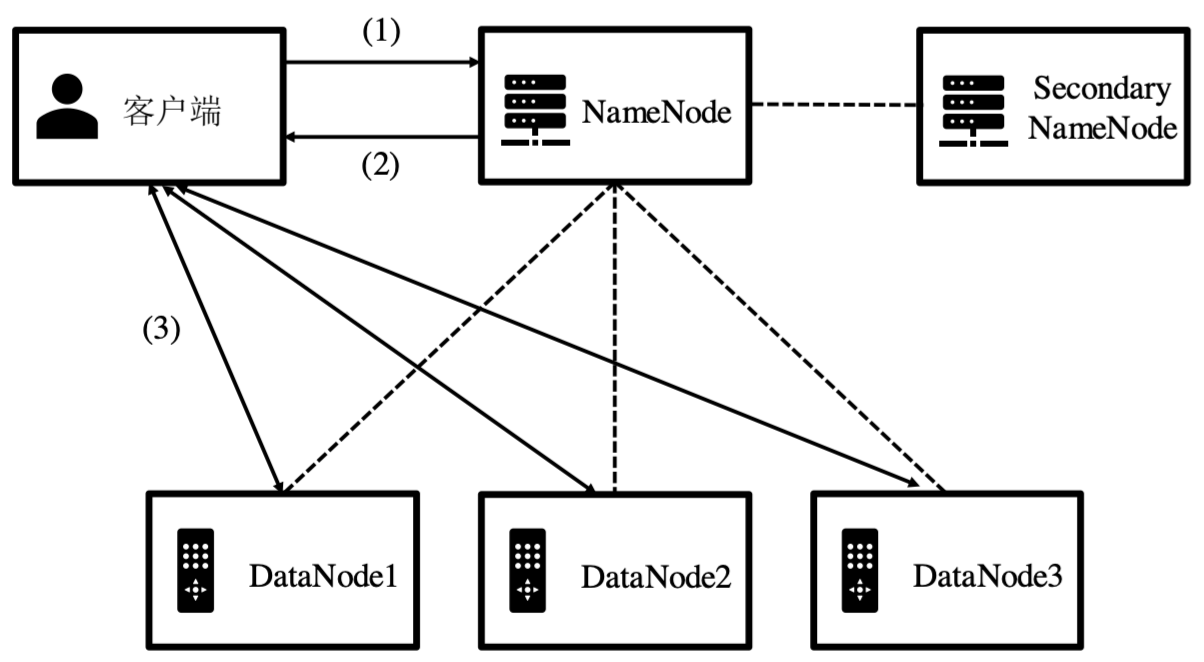
- 客户端向NameNode发起文件操作请求
- NameNode反馈
- 若是读写文件操作,则NameNode告知客户端文件存储的位置信息
- 若是创建、删除、重命名目录或文件等操作,NameNode修改文件目录结构成功后结束
- 对于删除操作,HDFS不会立即去删除DataNode上的数据块,而是等到特定时间才会真正删除
- 对于读写文件操作,客户端获知具体位置信息后再与DataNode进行读写交互
3 工作原理
HDFS 将大文件切分为文件块,并作为HDFS读写文件的最小单位。HDFS 对这些文件进行备份。
3.1 文件分块与备份
NameNode上的元信息指示了文件块所存放的DataNode。
一般 HDFS 中每个文件块都有3个副本,文件块存放策略:
- 第一个副本:放置在上传文件的数据节点——支持快速写入
- 第二个副本:放置在与第一个副本不同的机架的某一节点上——利于整体上减少跨机架的网络流量
- 第三个副本:与第一个副本相同的机架的其他节点上——利于应对故障发生时的文件块读取
- 更多副本:随机节点
以上副本放置策略只是启发式的,并不是严格最优的副本放置策略。
3.2 文件写入
-
客户端向NameNode发起文件写入请求。
-
NameNode根据启发式策略决定文件块放置的DataNode,并将DataNode位置告知客户端。
-
客户端与DataNode 1建立连接,DataNode 1与DataNode 2建立连接,DataNode 2与DataNode 3建立连接,客户端将文件块以流水线方式写入这些DataNode。
-
当 DataNode 3写入完毕后向DataNode 2发送确认消息,DataNode 2再向DataNode 1发送确认消息,DataNode 1向客户端发送确认消息,表示该文件块写入成功。
⚠️单个文件块的传输是流水线方式,文件块之间的传输是一种阻塞方式。
3.3 文件读取
-
客户端读取数据时,从NameNode获得数据块不同副本的存放位置,包含副本所在的数据节点
-
最近者优先原则:优先选择与客户端在同一个机架的数据块副本,没有则随机选择副本
-
以此类推,客户端读取下一个数据块,直到读取完所有数据块
读取HDFS文件时,客户端可一次性获取所有文件块的位置信息;写入文件时,客户端在每次写入文件块之前都要询问NameNode该文件块存放的位置。
3.4 文件读写与一致性
采用一次写入多次读取的简化一致性模型:
- 一个文件经过创建、写入和关闭就不得改变文件中的内容
- 已经写入到HDFS的文件,仅允许在文件末尾追加数据,不允许修改
- 对文件进行写入或追加操作时,NameNode拒绝其他对该文件的读写请求
- 对文件进行读取操作时,NameNode允许其他对该文件的读请求
简化一致性模型:
- 好处:避免读写冲突、用户编程不需要考虑文件锁
- 问题:要修改已有文件内容,只能将文件删除后再重新写入文件
4 容错机制
- NameNode 故障:利用 Secondary NameNode 的FsImage和Editlog恢复,会丢失 Editlog.new 中的信息
- Secondary NameNode 故障:HDFS仍可对外服务,但无法应对 NameNode 故障
- DataNode 故障:
- 节点上的所有数据都被标记为“不可读”
- 定期检查备份因子:NameNode定期检查DataNode心跳,若DataNode发生宕机,会造成部分文件块副本数目<设定的副本数目,系统需在其他DataNode上对这些文件块进行备份以达到预定的副本数目。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号