语法格式 : select [ , ...] from table_reference [ , ...]
去重复值
distinct关键字 , 从select结果集中删除所有重复的行,使结果集中每一行都是唯一的
语法格式: select distinct [ , ...] from table_reference [ , ...]
查询列的选择
手动输入列名: 多个列之间用逗号隔开
select a , b , f1 , f2 from t1 , t2;
可以计算出来的字段
select a+b from t1;
表明限定名来控制列明重复
select t1.f1 , t2.f1 from t1 , t2;
别名的设置
select a_id as aid from table;
条件查询
语法格式:
condition子句
select_statement { predicate } [ { and | or } condition ] [ , ...]
条件查询由表达式和操作符共同定义
select * form table where course_name = 'Joey';
逻辑操作符
and , or , not 优先级 NOT> AND > OR
运算规则:
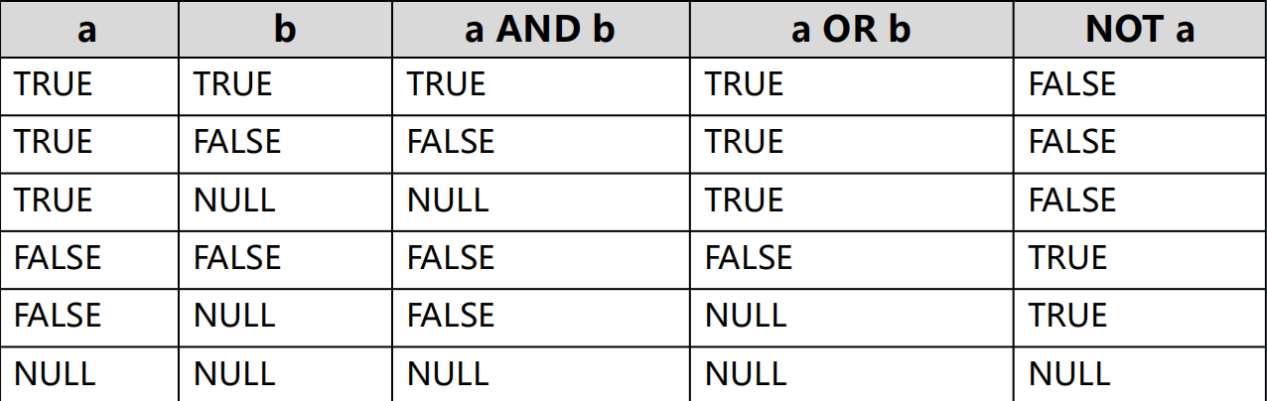
测试运算符

join**连接查询**
实际应用中所需要的数据 , 经常会查询两个或者两个以上的表 . 该查询方式称为连接查询 . 建立在互相存在的父子表之间 .
语法格式 :
select [ , ... ] from table_reference
[ left [outer] | right [outer] | full [outer] | inner ]
join table_reference
[on { predicate } [ { and | or} condition ] [ , ...] ]
当查询的from子句中出现多个表时,数据库就会执行连接
where 子句中可以通过指定 "(+)" 操作符的方式将表的连接关系转换为外连接 , 但是不建议采取这种方式 。
内连接
关键字:inner join ,其中inner可以省略。必须按顺序执行语句
内连接所指定的两个数据源处于平等的地位
内连接返回两个表中所有满足连接条件的数据记录
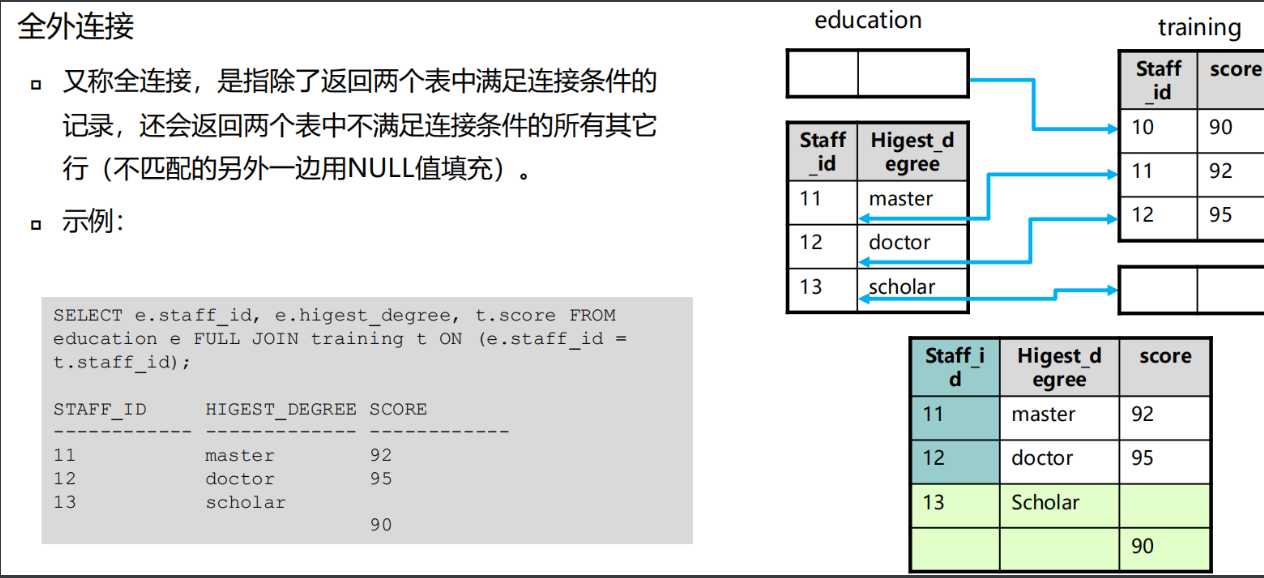
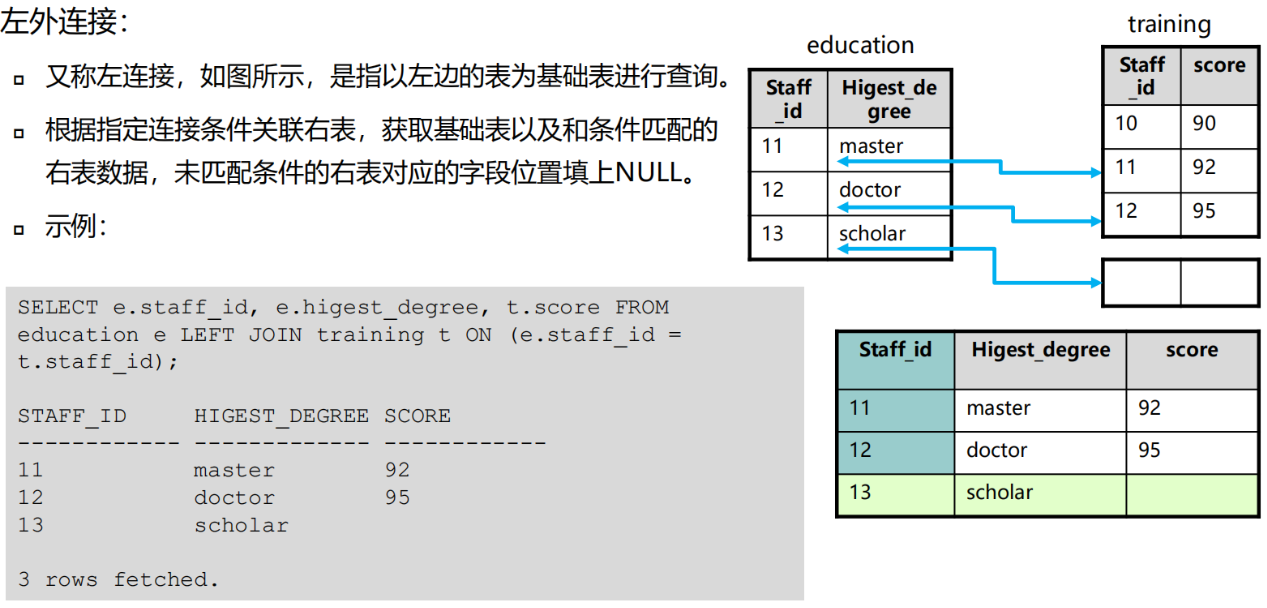
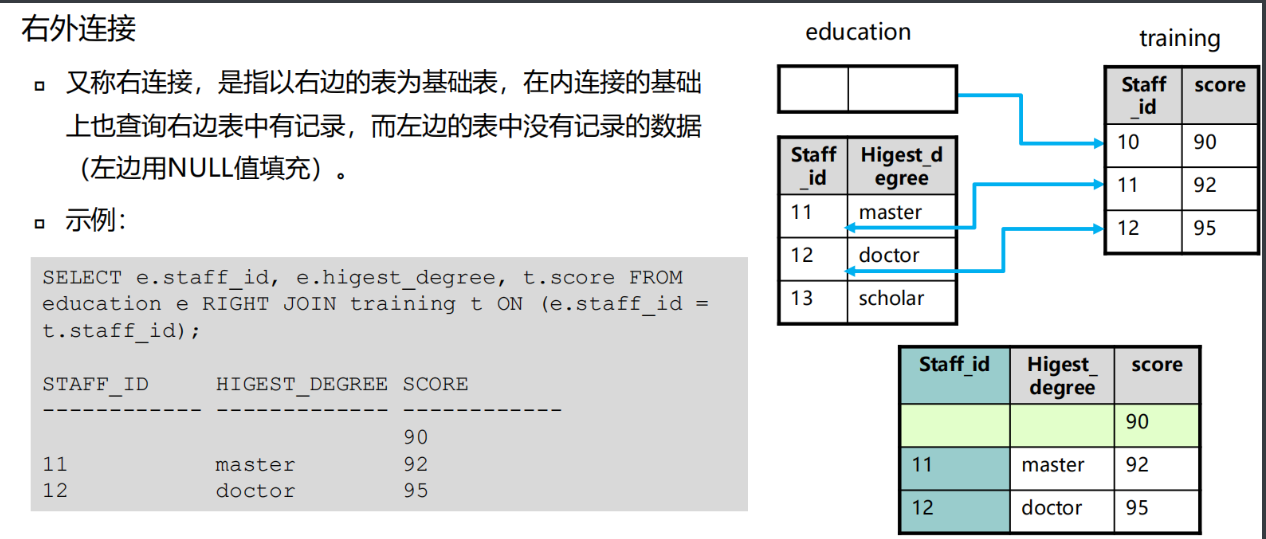
外连接
外连接以一个数据源为基础,将另外一个数据源与之进行条件匹配
外连接返回满足(不满足)连接条件的记录
外连接分为左外连接、右外连接、全外连接
子查询
是指在查询、建表或者插入语句的内部嵌入查询,以获得临时结果集。
·子查询可以分为相关子查询和非相关子查询
·子查询的语法格式与普通查询相同
使用方法:
·子查询可以出现在from子句中(内联视图)、where子句(嵌套子查询)、以及with as子句中。
·with as 语句:定义一个SQL片段,该SQL片段会被整个SQL语句用到。
·语法格式:with { table_name as select_statement_1 } [ , ... ] select_statement_02
·table_name
用户自定义存储SQL片段的表的名称。
·select_statement_01
从基本表中查询数据的select语句
·select_statement_02
从用户自定义的存储SQL片段的表中查询数据的select语句
合并结果集
可以使用集合运算符处理多个查询的结果集,输出最终结果。
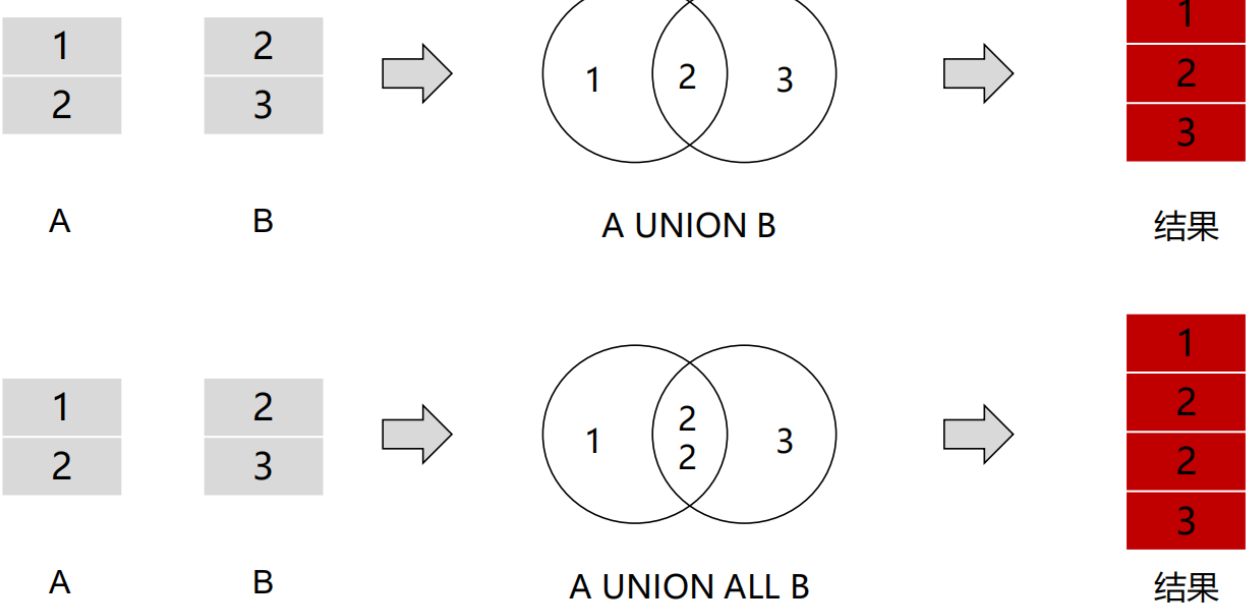
·Union运算符:将多个查询快的结果集合并为一个结果集输出。
select_statement union [all] select_subquery
使用方法:
·每个查询块的查询列数目必须相同。
·每个查询块对应的查询列必须为相同类型或同一数据类型组
·关键字all的意思是保持所有重复数据,而没有all的情况下表示删除所有重复数据
差异结果集
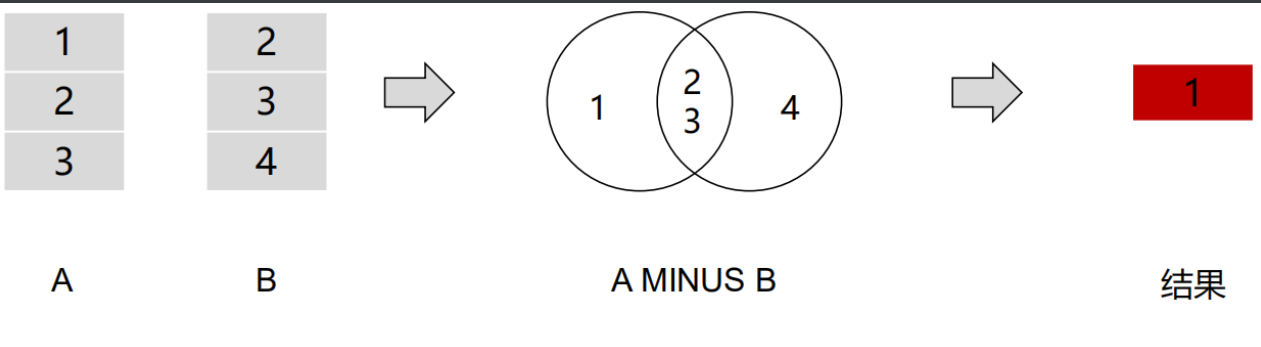
minus/except 运算符
·对查询结果集的减法,计算存在于左边查询语句的输出、而不存在右边查询语句输出的结果
·A minus B C <==> A中存在,BC中不存在的记录
语法: select_statement_01 minus/expect select_statement_02 [ ... ]
select_statement_01:产生第一个结果集的select语句
select_statement_02:产生第二个结果集的select语句
数据分组
将数据表中的记录以某个或者某些列为标准,值相等的划分一组.
语法格式: group by { column_name } [ , ... ]
使用方法:
·group by 子句中的表达式可以包含from子句中表,视图的任何列。
·group by 子句对行进行分组,但是不保证结果集的顺序。要对分组进行排序使用order by 子句
·group by 后的表达式可以使用括号,如:group by (expr1, exprp2) , 或者group by(expr1) , (expr2)
Having子句
与group by子句配合使用选择特殊的组。having子句将组的一些属性与一个常数值比较,只有满足having子句条件的组才会被提取出来
语法:having condition[ , ... ]
数据排序
order by子句,查询语句返回的行根据指定的列进行排序。
语法:order by { column_name | number | expression } [ ASC | DESC ] [ nulls first | nulls last ] [ , ... ]
使用方法:
·order by 语句默认按照升序对记录进行排序。如果需要按照降序对记录进行排序,请使用 DESC关键字
·nulls first | nulls last 关键字指定order by 列中的null值排序位置,first(last) 表示将null值排在最前面(最后面)
若不指定该选项,ASC默认为 nulls last ,DESC 默认为 nulls first
数据限制
两个独立子句 : limit 子句 & offset 子句
limit子句允许限制查询返回的行,可以指定偏移量,以及要返回的行数或者行百分比 limit { count | All }
offset 子句设置开始的返回的位置 offset start
使用方法:
·start :指定在返回行之前要跳过的行数
·count :指定要返回的最大行数
·limit 5,20与limit 20 offset 5 及 offset 5 limit 20等效
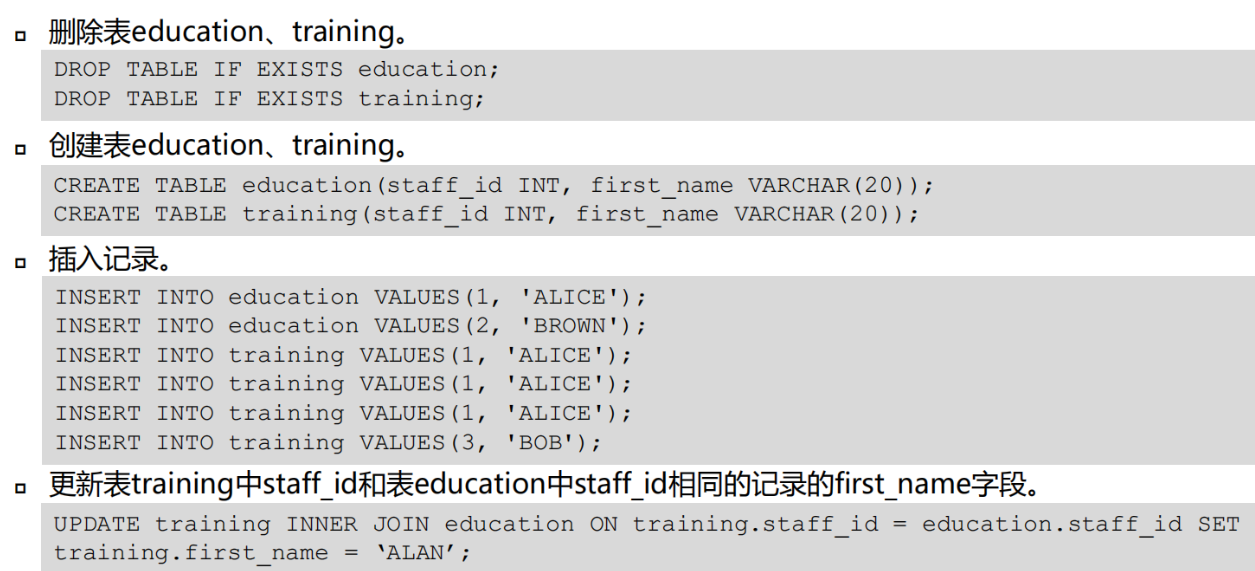
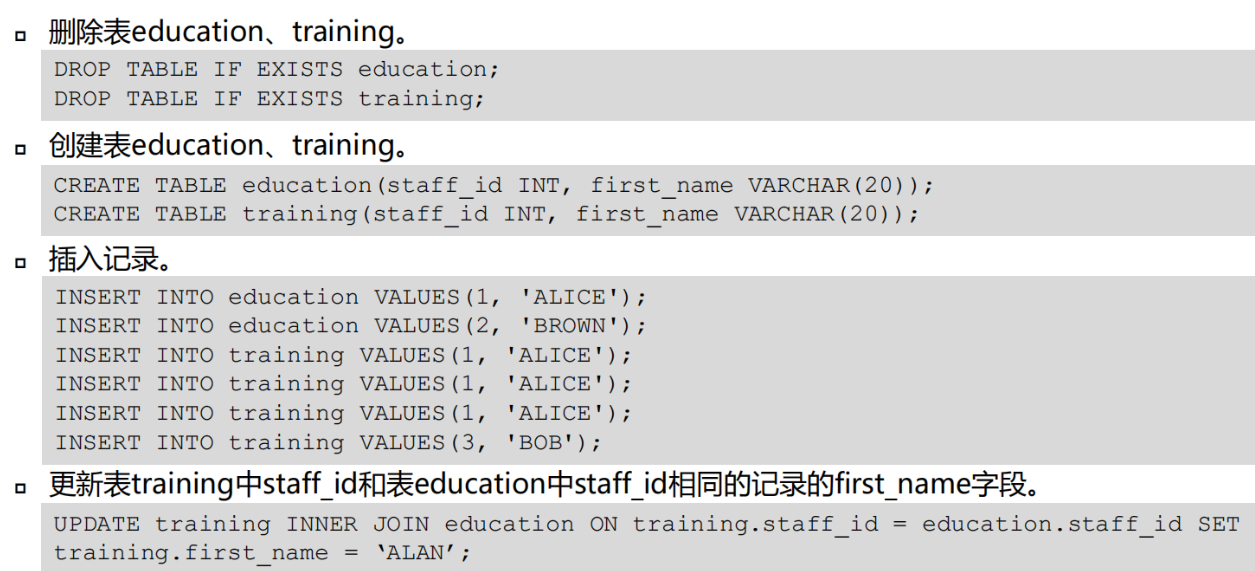
数据更新
数据插入
在表中插入新的数据
注意:
1、只有拥有表insert权限的用户,才可以向表中插入数据
2、如果使用returning子句,用户必须要有对该表的select权限
3、如果使用query子句插入来自查询里的数据行,用户还需要拥有在查询里使用表的select权限
4、insert事务提交是默认关闭的。绘画退出时,需要显示commit,否则记录将会丢失
语法:
insert into table_name 属性值
i
数据修改
更新表中行的值
注意:
1、update事务提交是默认关闭的。会话退出时,需要显示commit,否则记录会丢失。
2、执行该语句的用户需要由对表更新的权限。
3、普通用户不允许update系统SYS用户对象。不支持临时表的多表更新。
语法:
update table_name set table_name_stuff=new_table_name_stuff
数据删除
从表中删除行
注意:
1、delete事务提交是默认关闭的。会话退出时,需要显示commit,否则记录会丢失。
2、执行该语句的用户需要由对表删除的权限。
语法:
delete * from table_name;
数据定义
数据库对象
是数据库组成部分,数据库对象包括:表、索引、视图、存储过程、缺省值、规则、触发器、用户、函数等
表:存储数据对象以及对象之间的关系,由行和列组成
索引:是对数据库表中一列或者多列的值进行排序的一种结构,加快访问速度和效率。
视图:从一个或几个基本表中导出的虚表,用于控制用户对数据的访问
存储过程:是一组为了完成特定功能的SQL语句的集合.用于报表统计,数据迁移.
缺省值 : 当在表中创建列或者插入数据时,对未指定具体值的列或者列数据项预先设定的值
规则 : 对数据库表中数据信息的限制,限定的是表的列
触发器 : 一种特殊类型的存储过程,通过指定的事件触发执行 , 一般用于数据审计 , 数据备份
函数 : 对一些业务逻辑的封装,以完成特定的功能
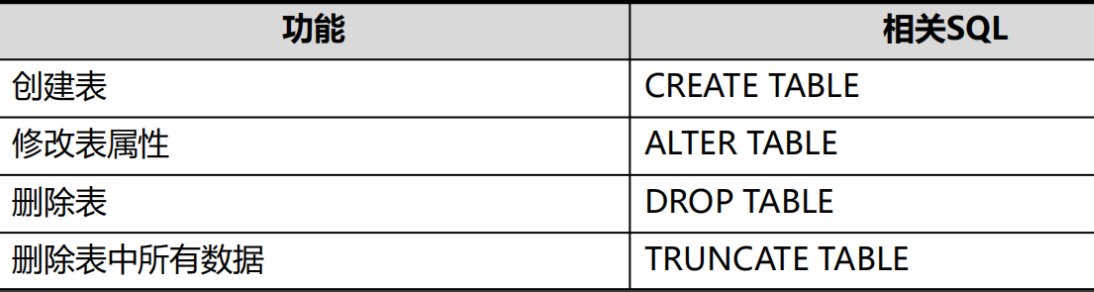
Data Definition Language 数据定义语言 , 用于定义或者修改数据库中的对象:
1. create用来创建数据库对象
2. alter用来修改数据库对象的属性
3. drop用来删除数据库对象
关于表的数据库sql操作
创建表的参数说明:
~global 创建全局表
~temporary 创建临时表
~if not exists 创建表时,如果表存在,则不做改动直接返回 , 如果表不存在则创建新表
~[schema_name.]table_name 表名不能和用户下表重名
~relational_properties 表属性名 , 包括列名 , 类型 , 行内约束和行外约束 .
修改表属性
1.列的添加,删除,修改,重命名
2.约束的添加,删除
3.约束的启动和禁用
4.修改分区的名称
5.修改分区的表空间
注意:
`执行该语句的用户需要有alter any table系统权限 , 普通用户不可以修改系统用户对象
`增加表中列属性时 , 保证表中无记录
`修改表中列属性时 , 保证表中的所有的记录该列为null

删除表
注意:
1.用户能够删除自己的表 ; 删除其他用户下的表时需要drop any table 权限 , 普通用户不可以删除系统用户对象
2.删除表并不会立即把表中记录删除 , 将表重命名置recycle标记 , 并放入回收站 可以通过flashback命令回退
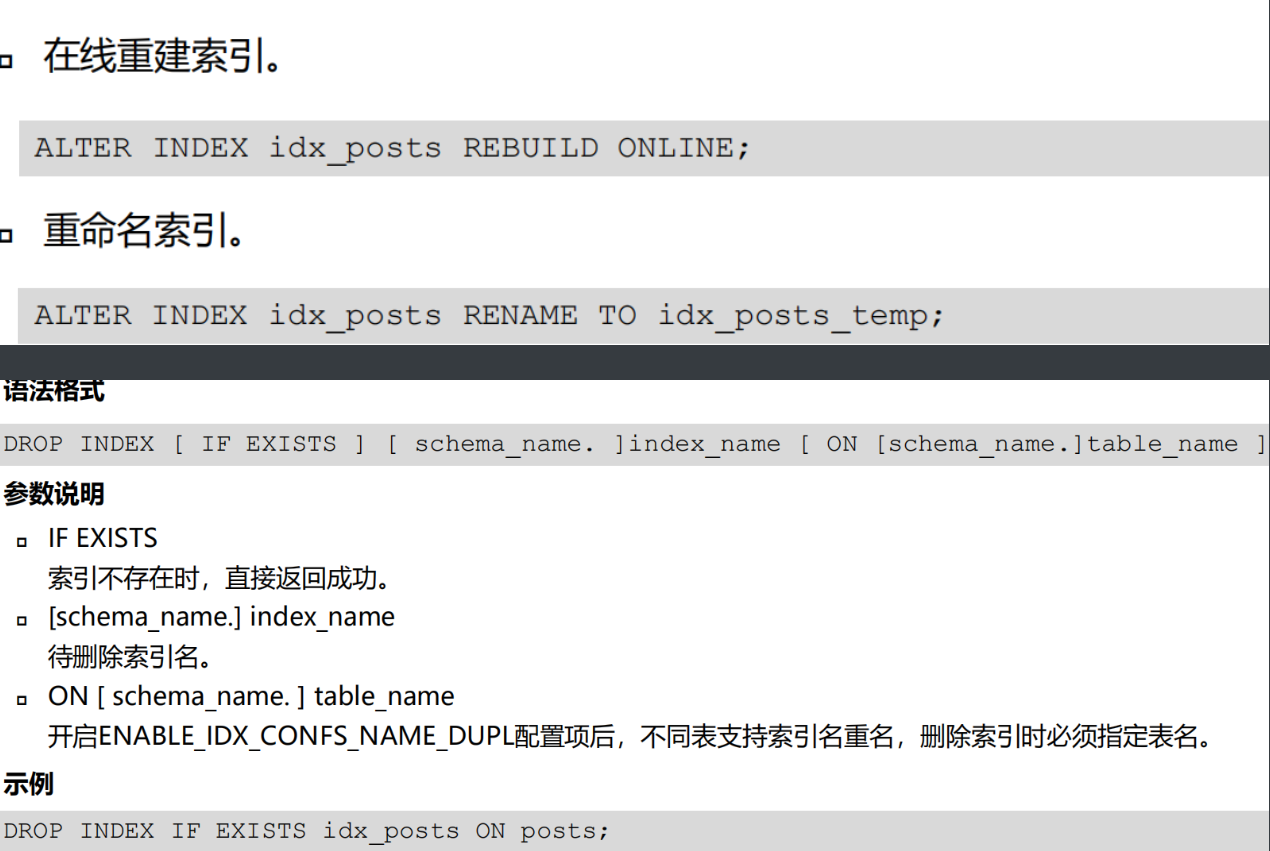
语法: drop [ temporary ] table [ if exists ] [ schema_name. ] table_name [ cascade constraints ] [ purge ]
cascade constraints : 如果被删除父表被别的子表外键引用 , 那么删除父表也会报错 , 而使用cascade constraints , 则可以删除父表 并且删除外键
purge : 删除表默认放回回收站 purge表示直接删除

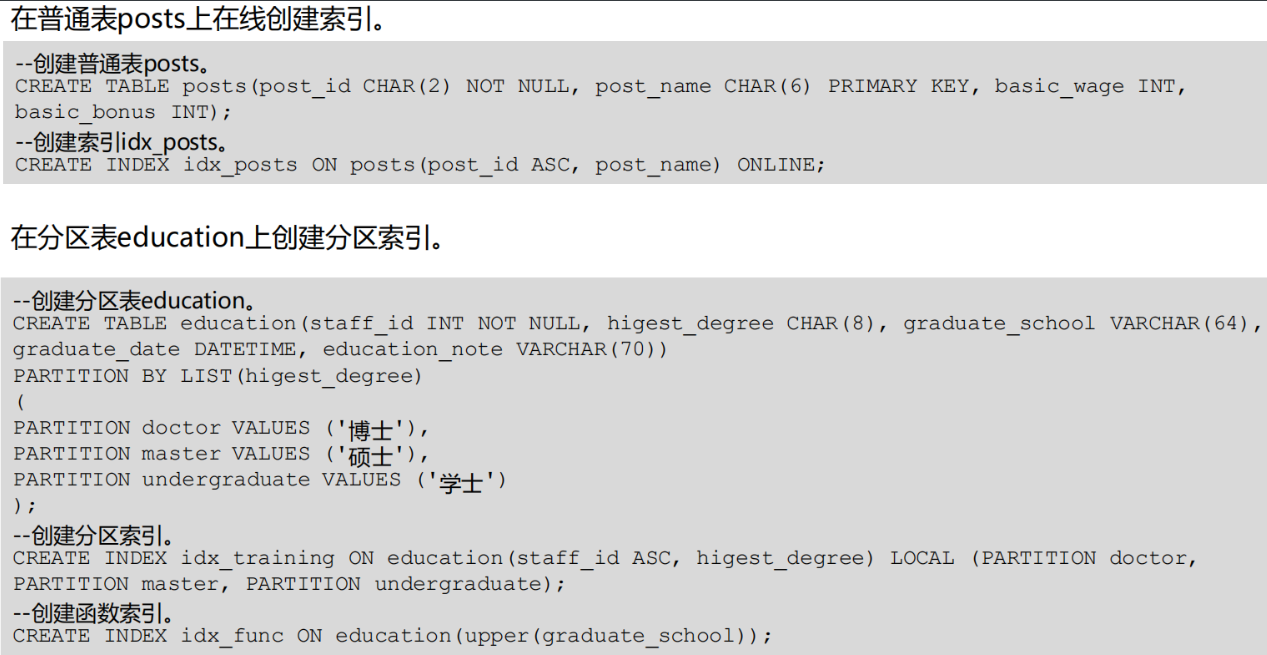
定义索引
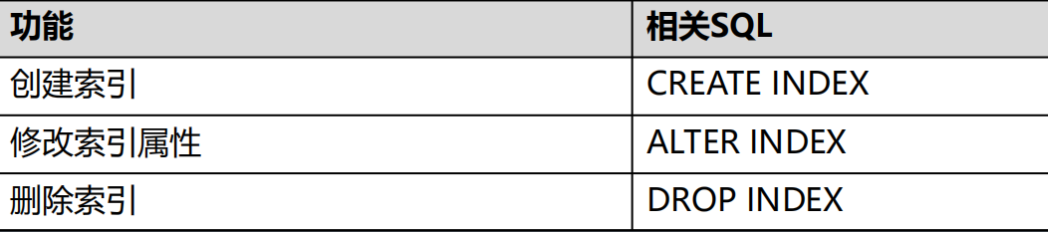
按照索引列数分为: 单索引列 和 多索引列
按照使用方法分为: 普通索引 , 唯一索引 , 函数索引 , 分区索引
参数说明:
1. unique :创建唯一索引 , 每次添加数据时检测表中是否有重复值 . 如果插入或者更新的值会导致重复记录会产生一个新的错误 .
-
index_name : 要创建的索引名
-
table_name : 要创建索引的表名 , 可以有用户修饰
-
online :在线创建索引
定义视图
视图是一个或者几个基本表导出的虚表,可用于控制用户对数据的访问.
~ : 创建视图 create view
~ : 删除视图 drop view
视图与表不同,数据库中仅存放数据的定义,而不存放视图对应的数据,数据仍然存放在原来的 基本表中
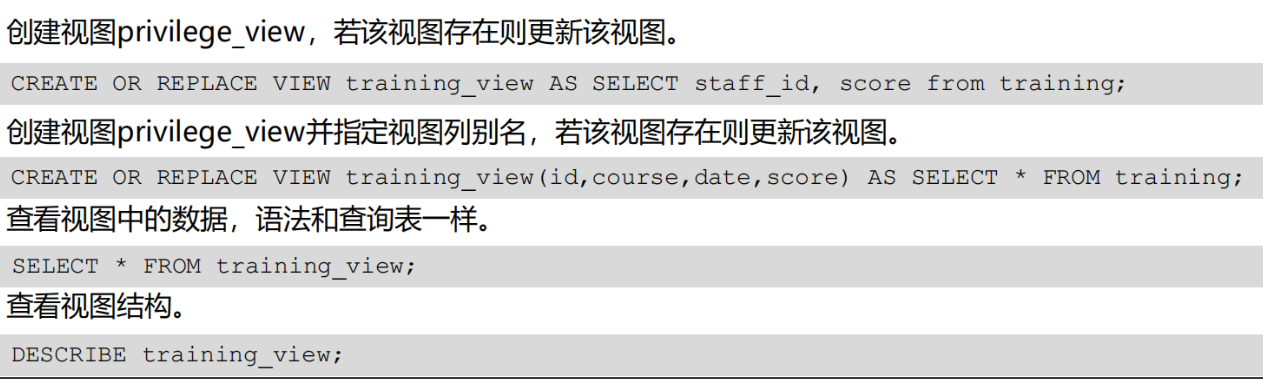
创建视图:create [ or peplace ] view [ schema_name. ] view_name [ ( alias [ , ... ] ) ] as subquery
参数说明:
1、or peplace 创建视图时,若视图存在则更新
2、[ schema_name. ] view.name 视图名
3、[ ( alias [ , ... ] ) ] 视图列别名
4、as subquery 子查询
删除视图
drop view [ if exists ] [ schema_name. ] view_name
参数说明:
[ if exists ] :试图存在则执行删除
[ schema_name. ] view_name :待删除的视图
定义序列
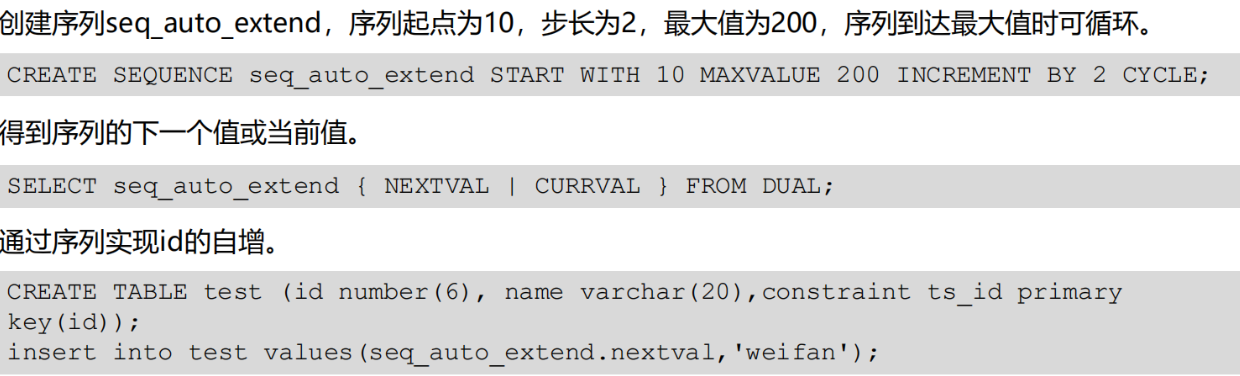
序列可以产生一组等间隔的值,能够自增,用于表的主键
SQL语句:
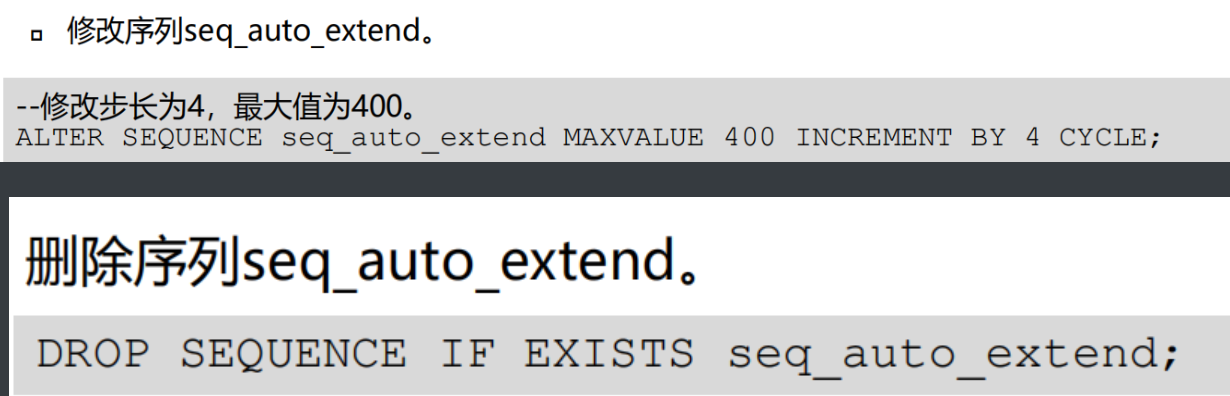
1、创建序列 : create sequence
2、修改序列 : alter sequence
3、删除序列 : drop sequence
数据控制
事务控制
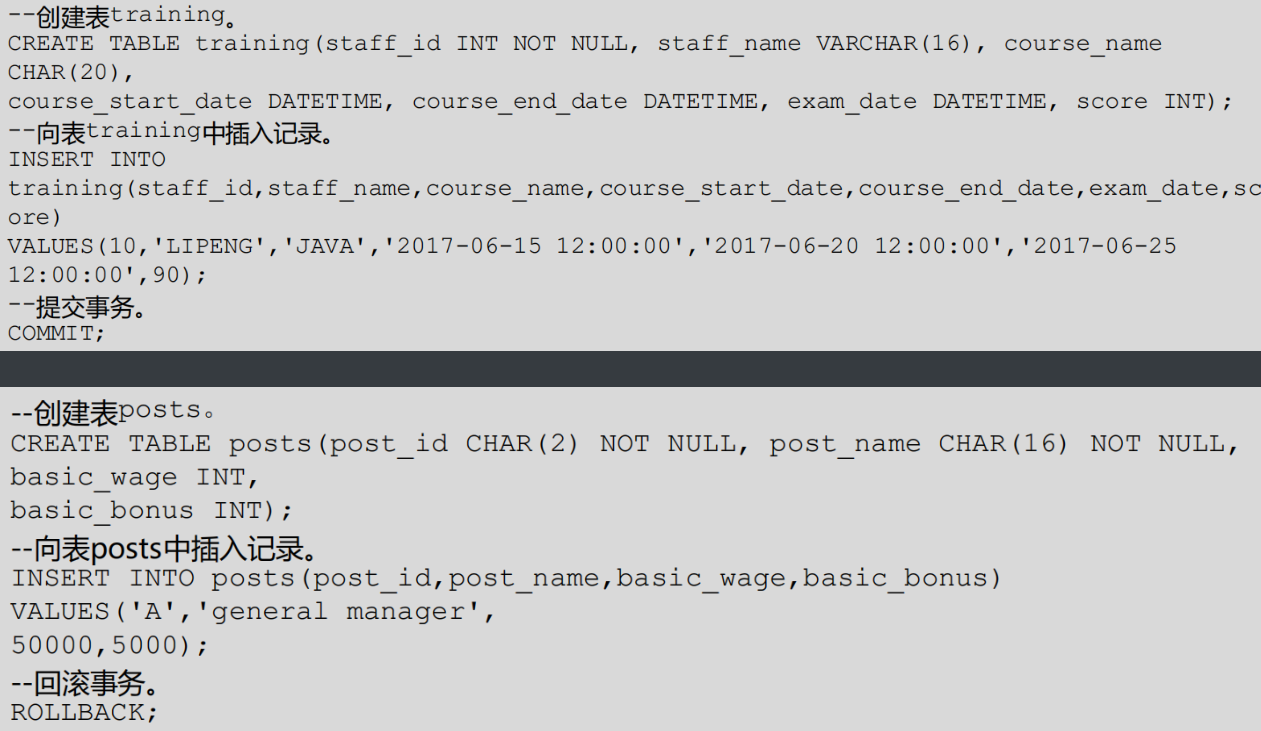
·事务是用户定义的一个数据库操作序列,这些操作要么全做,要么全不做,是一个不可分割的工作单位
·事务控制提供了事务的启动、提交、两阶段提交准备、回滚、设置隔离级别操作,并支持在事务中创建保存点。
~提交事务(使当前事务工作单元中的所有操作“永久化”,并结束该事务) commit
~回滚事务(废除当前事务工作单元中所有的操作,并结束该事务) rollback
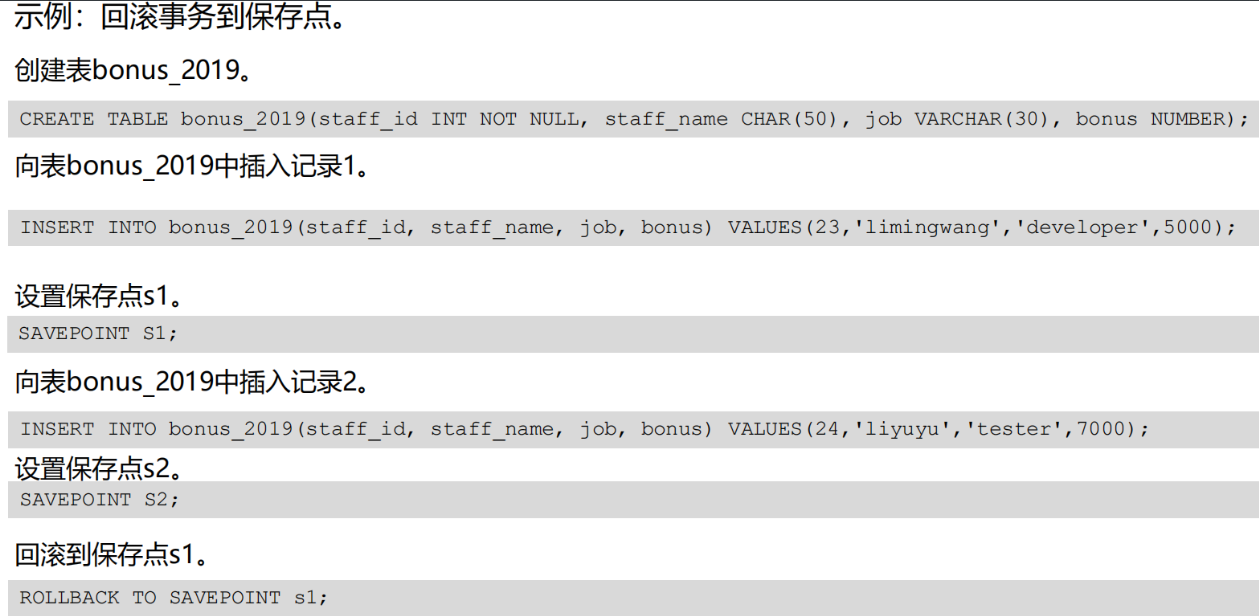
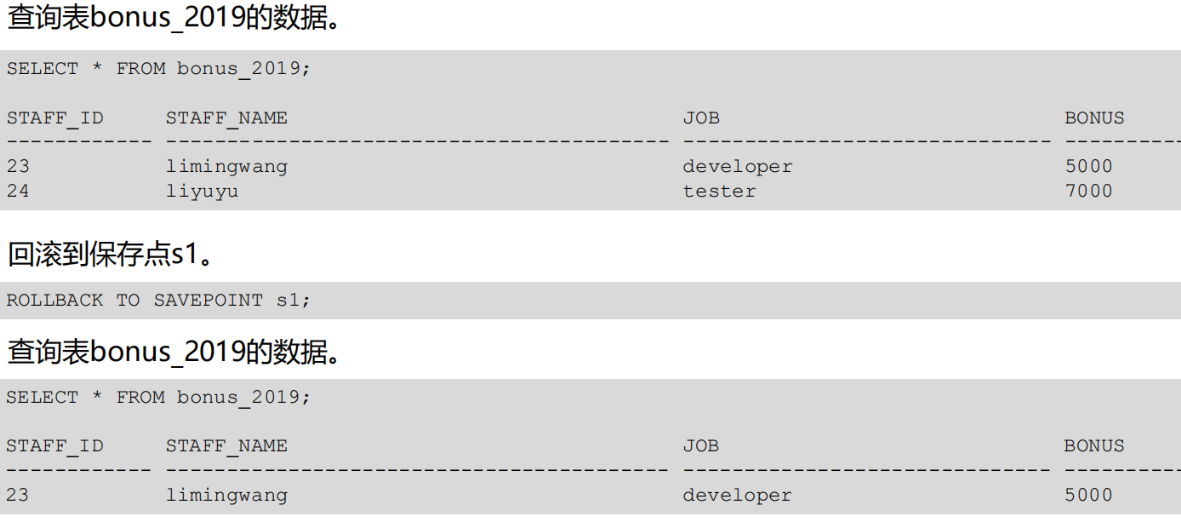
事务保存点
·savepoint 语句用在事务中设置保存点
·保存点提供了一种灵活的回滚,事务在执行中可以回滚到某个保存点。在该保存点以前的操作有效。而以后的操作被回滚掉。一个事务中可以设置多个保存点。
语法:savepoint savepoint_name