PostgreSQL主从流复制部署
1.准备知识:
1. PostgreSQL的安装。
2. 流复制特点。
PostgreSQL在9.0之后引入了主从的流复制机制,所谓流复制,就是从服务器通过tcp流从主服务器中同步相应的数据。这样当主服务器数据丢失时从服务器中仍有备份。
与基于文件日志传送相比,流复制允许保持从服务器更新。 从服务器连接主服务器,其产生的流WAL记录到从服务器, 而不需要等待主服务器写完WAL文件。
PostgreSQL流复制默认是异步的。在主服务器上提交事务和从服务器上变化可见之间有一个小的延迟,这个延迟远小于基于文件日志传送,通常1秒能完成。如果主服务器突然崩溃,可能会有少量数据丢失。
同步复制必须等主服务器和从服务器都写完WAL后才能提交事务。这样在一定程度上会增加事务的响应时间。
配置同步复制仅需要一个额外的配置步骤: synchronous_standby_names必须设置为一个非空值。synchronous_commit也必须设置为on。
这里部署的是异步的流复制。
注:
主从服务器所在节点的系统、环境最好一致。PostgreSQL版本也最好一致,否则可能会有问题。
2. 准备工作:
1. 服务器2台(1台也可以。需要安装2个实例)
2. PostgreSQL安装文件(最好是安装同一个版本,以免出现问题,必须大于9.0,否则不行)
此处本人使用的是2台服务器,主服务器使用Windows Server 2008 R2,从服务器Windows Server 2012 R2。 PostgreSQL版本9.3.5-3。
注意安装后,需要配置防火墙出入站规则才能联通。
若是使用的Linux服务器,注意防火墙的状态。
3. 软件安装。
自行安装。
4. 实施部署
4.1.主服务器
A.创建复制用户/角色
psql -U postgres
输入密码
命令行登录pgsql> create role replica login replication encrypted password 'replica';
B.修改认证文件g_hba.conf,允许从服务器来连接和复制
host all all X.X.X.X/32 trust #允许XX这个从服务器连接到主服务器
host replication replica X.X.X.X/32 md5 #允许使用replica用户来复制,第二个字段必须要填replicationC.主服务器流复制的设置,修改 postgresql.conf
archive_mode = on # 允许归档
wal_level = hot_standby
max_wal_senders = 32 # 这个设置了可以最多有几个流复制连接,差不多有几个从,就设置几个wal_keep_segments = 256 # 设置流复制保留的最多的xlog数目
wal_sender_timeout = 60s # 设置流复制主机发送数据的超时时间
max_connections = 100 # 这个设置要注意下,从库的max_connections必须要大于主库的D.重启主服务器PostgreSQL服务
在从服务器测试一下连接。不行就检查一下防火墙。
4.2 从服务器
A. 停止PostgreSQL服务,清空data目录。
rm -rf /opt/pgsql/data/* #先将data目录下的数据都清空(此处是linux命令,因为在下使用的Cmder.)
B. 从主节点拷贝数据到从节点
pg_basebackup -h 192.168.20.93 -U replica -D /opt/pgsql/data -X stream -P
C.配置从服务器recovery.conf
复制/share/recovery.conf.sample 到 /data/recovery.conf
cp /share/recovery.conf.sample /data/recovery.conf
修改recovery.conf
standby_mode = on # 说明该节点是从服务器
primary_conninfo = 'host=Y.Y.Y.Y port=5432 user=replica password=replica' # 主服务器的信息以及连接的用户
recovery_target_timeline = 'latest'D.配置从服务器postgresql.conf
wal_level = hot_standby
max_connections = 1000 # 一般查多于写的应用从库的最大连接数要比较大
hot_standby = on # 说明这台机器不仅仅是用于数据归档,也用于数据查询
max_standby_streaming_delay = 30s # 数据流备份的最大延迟时间
wal_receiver_status_interval = 10s # 多久向主报告一次从的状态,当然从每次数据复制都会向主报告状态,这里只是设置最长的间隔时间
hot_standby_feedback = on # 如果有错误的数据复制,是否向主进行反馈
注意:如果开启了max_prepared_transactions,也必须保证从服务器的最大连接数要比主服务器大。E.重启从服务器服务,在主服务器验证。
重启从服务器服务。
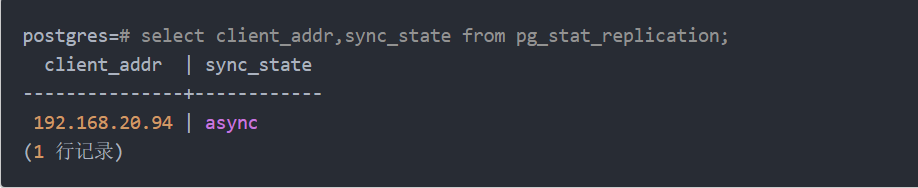
在主服务器验证,查询select client_addr,sync_state from pg_stat_replication;![]()
类似如上结果,配置成功。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号