【JDK1.8】JDK1.8集合源码阅读——TreeMap(二)
一、前言
在前一篇博客中,我们对TreeMap的继承关系进行了分析,在这一篇里,我们将分析TreeMap的数据结构,深入理解它的排序能力是如何实现的。这一节要有一定的数据结构基础,在阅读下面的之前,推荐大家先看一下:《算法4》深入理解红黑树。(个人比较喜欢算法四这里介绍的红黑树实现:从2-3树到红黑树的过渡很清晰,虽然源码里的实现不是这种方式 T^T),先了解一下红黑树的由来以及它的特性,这样能更好的理解TreeMap的实现。
二、 TreeMap的结构
TreeMap的内部实现就是一个红黑树。

对于红黑树的定义:
- 节点是红色或黑色。
- 根是黑色。
- 所有叶子都是黑色(叶子是NIL节点)。
- 每个红色节点必须有两个黑色的子节点。(从每个叶子到根的所有路径上不能有两个连续的红色节点。)
- 从任一节点到其每个叶子的所有简单路径都包含相同数目的黑色节点。
三、Tree源码解析
在前一篇博客中,我们已经见过了TreeMap的继承关系,所以这里就不重复了,让我们来看一下它的其他内容。
3.1 TreeMap的成员变量
public class TreeMap<K,V> extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable {
// Key的比较器,用作排序
private final Comparator<? super K> comparator;
//树的根节点
private transient Entry<K,V> root;
//树的大小
private transient int size = 0;
//修改计数器
private transient int modCount = 0;
//返回map的Entry视图
private transient EntrySet entrySet;
private transient KeySet<K> navigableKeySet;
private transient NavigableMap<K,V> descendingMap;
//定义红黑树的颜色
private static final boolean RED = false;
private static final boolean BLACK = true;
}
3.2 TreeMap的构造方法
对一些不重要的构造方法就不流水账一样的记录了。
3.2.1 TreeMap(Comparator<? super K> comparator)
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
允许用户自定义比较器进行key的排序。
3.2.2 public TreeMap(Map<? extends K, ? extends V> m)
public TreeMap(Map<? extends K, ? extends V> m) {
comparator = null;
putAll(m);
}
public void putAll(Map<? extends K, ? extends V> map) {
int mapSize = map.size();
//判断map是否SortedMap,不是则采用AbstractMap的putAll
if (size==0 && mapSize!=0 && map instanceof SortedMap) {
Comparator<?> c = ((SortedMap<?,?>)map).comparator();
//同为null或者不为null,类型相同,则进入有序map的构造
if (c == comparator || (c != null && c.equals(comparator))) {
++modCount;
try {
buildFromSorted(mapSize, map.entrySet().iterator(),
null, null);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
return;
}
}
super.putAll(map);
}
buildFromSorted将在后面解析,因为后面的构造函数也调用了这个方法。
3.2.3 public TreeMap(SortedMap<K, ? extends V> m)
public TreeMap(SortedMap<K, ? extends V> m) {
comparator = m.comparator();
try {
buildFromSorted(m.size(), m.entrySet().iterator(), null, null);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
}
下面让我们来看一下这个buildFromSorted方法:
/**
* size: map里键值对的数量
* it: 传入的map的entries迭代器
* str: 如果不为空,则从流里读取key-value
* defaultVal:见名知意,不为空,则value都用这个值
*/
private void buildFromSorted(int size, Iterator<?> it,
java.io.ObjectInputStream str,
V defaultVal)
throws java.io.IOException, ClassNotFoundException {
this.size = size;
root = buildFromSorted(0, 0, size-1, computeRedLevel(size),
it, str, defaultVal);
}
我们先来分析一下computeRedLevel方法:
private static int computeRedLevel(int sz) {
int level = 0;
for (int m = sz - 1; m >= 0; m = m / 2 - 1)
level++;
return level;
}
它的作用是用来计算完全二叉树的层数。什么意思呢,先来看一下下面的图:

把根结点索引看为0,那么高度为2的树的最后一个节点的索引为2,类推高度为3的最后一个节点为6,满足m = (m + 1) * 2。那么计算这个高度有什么好处呢,如上图,如果一个树有9个节点,那么我们构造红黑树的时候,只要把前面3层的结点都设置为黑色,第四层的节点设置为红色,则构造完的树,就是红黑树,满足前面提到的红黑树的5个条件。而实现的关键就是找到要构造树的完全二叉树的层数。
了解了上面的原理,后面就简单了,接着来看buildFromSorted方法:
/**
* level: 当前树的层数,注意:是从0层开始
* lo: 子树第一个元素的索引
* hi: 子树最后一个元素的索引
* redLevel: 上述红节点所在层数
* 剩下的3个就不解释了,跟上面的一样
*/
@SuppressWarnings("unchecked")
private final Entry<K,V> buildFromSorted(int level, int lo, int hi,
int redLevel,
Iterator<?> it,
java.io.ObjectInputStream str,
V defaultVal)
throws java.io.IOException, ClassNotFoundException {
// hi >= lo 说明子树已经构造完成
if (hi < lo) return null;
// 取中间位置,无符号右移,相当于除2
int mid = (lo + hi) >>> 1;
Entry<K,V> left = null;
//递归构造左结点
if (lo < mid)
left = buildFromSorted(level+1, lo, mid - 1, redLevel,
it, str, defaultVal);
K key;
V value;
// 通过迭代器获取key, value
if (it != null) {
if (defaultVal==null) {
Map.Entry<?,?> entry = (Map.Entry<?,?>)it.next();
key = (K)entry.getKey();
value = (V)entry.getValue();
} else {
key = (K)it.next();
value = defaultVal;
}
// 通过流来读取key, value
} else {
key = (K) str.readObject();
value = (defaultVal != null ? defaultVal : (V) str.readObject());
}
//构建结点
Entry<K,V> middle = new Entry<>(key, value, null);
// level从0开始的,所以上述9个节点,计算出来的是3,实际上就是代表的第4层
if (level == redLevel)
middle.color = RED;
//如果存在的话,设置左结点,
if (left != null) {
middle.left = left;
left.parent = middle;
}
// 递归构造右结点
if (mid < hi) {
Entry<K,V> right = buildFromSorted(level+1, mid+1, hi, redLevel,
it, str, defaultVal);
middle.right = right;
right.parent = middle;
}
return middle;
}
**另外提一句,buildFromSorted能这么构造是因为这是一个已经排序的map。😃 **
具体的构造顺序如下图(偷懒画了个简单的 ):
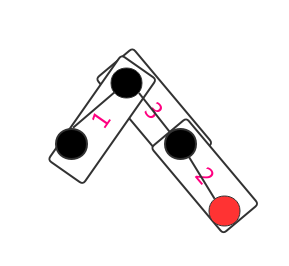
感兴趣的园友可以自己分析一下上面9个节点的是如何构造的。
3.3 TreeMap的重要方法
接下来,我们来看一下TreeMap里的一些重要的方法。
3.3.1 get(Object key)
对于map来说,根据key来获取value几乎是最常见的操作,下面我们来看一下:
public V get(Object key) {
//内部调用了getEntry方法。
Entry<K,V> p = getEntry(key);
return (p==null ? null : p.value);
}
final Entry<K,V> getEntry(Object key) {
// 如果有比较器,则调用通过比较器的来比较key的方法
if (comparator != null)
return getEntryUsingComparator(key);
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
// 获取key的Comparable接口
Comparable<? super K> k = (Comparable<? super K>) key;
//从根结点开始比较,根据二叉树的形式,小的往左树找,大的往右树找,直到找到返回
Entry<K,V> p = root;
while (p != null) {
int cmp = k.compareTo(p.key);
if (cmp < 0)
p = p.left;
else if (cmp > 0)
p = p.right;
else
return p;
}
return null;
}
对于Comparable<? super K> k = (Comparable<? super K>) key;,笔者一开始的时候在想为什么用<? super K>,用<? extends K>不行吗,不是根据PECS(Producer Extends, Consumer Super)原则,取出来的时候用extends吗。后来发现太傻了 T^T,这一原则是用来针对list的。这里肯定是用super,用K或者K的父类的compareTo方法。如果用extends的话,K的子类加了其他属性进行比较,那就根本没法进行比较了。
至于getEntryUsingComparator方法就不分析了,就是把compareTo变成了用Comparator进行比较,有兴趣的园友可以自己看看。
3.3.2 put(K key, V value)
public V put(K key, V value) {
Entry<K,V> t = root;
//根结点为空,则进行添加根结点并初始化参数
if (t == null) {
//用来进行类型检查
compare(key, key);
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
// 与get类型,分离comparator与comparable的比较
Comparator<? super K> cpr = comparator;
if (cpr != null) {
//循环查找key,如果找到则替换value,没有则记录其parent,后面进行插入
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
else {
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
//循环查找key,如果找到则替换value,没有则记录其parent,后面进行插入
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
//创建结点,然后比较与parent的大小,小放在左结点,大放在右节点
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
//对红黑树进行修复
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
put的逻辑还是比较清晰的,关键在于fixAfterInsertion对插入结点后的红黑树进行修复,维护其平衡,我们接着来看看它是如何实现的(在继续看之前,建议园友们先去了解一下左旋转和右旋转的操作)。
private void fixAfterInsertion(Entry<K,V> x) {
//约定插入的结点都是红节点
x.color = RED;
//x本身红色,如果其父节点也是红色,违反规则4,进行循环处理
while (x != null && x != root && x.parent.color == RED) {
//父节点是左结点
if (parentOf(x) == leftOf(parentOf(parentOf(x)))) {
//获取父节点的右兄弟y
Entry<K,V> y = rightOf(parentOf(parentOf(x)));
//p为左结点,y为红色 ①
if (colorOf(y) == RED) {
setColor(parentOf(x), BLACK);
setColor(y, BLACK);
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
} else {
// p为左结点,y为黑,x为右节点 ②
if (x == rightOf(parentOf(x))) {
x = parentOf(x);
rotateLeft(x);
}
// p为左结点,y为红,x为左结点 ③
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateRight(parentOf(parentOf(x)));
}
//父节点是右结点
} else {
Entry<K,V> y = leftOf(parentOf(parentOf(x)));
//p为右结点,y为红色 ④
if (colorOf(y) == RED) {
setColor(parentOf(x), BLACK);
setColor(y, BLACK);
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
} else {
//p为右结点,y为黑色,x为左结点 ⑤
if (x == leftOf(parentOf(x))) {
x = parentOf(x);
rotateRight(x);
}
//p为右结点,y为黑色,x为右结点 ⑥
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateLeft(parentOf(parentOf(x)));
}
}
}
//约定根结点都是黑节点
root.color = BLACK;
}
总结一下有这么几种情况:
- 由于p为红,则x没有兄弟结点(原则4),要想插入后维持红黑树平衡,必须从p,pp以及p的兄弟结点y中找到对应的处理情况来平衡。
- 首先,插入的结点x,颜色肯定是红色,插入位置两种情况——左结点或者右结点。
- 其次,父结点p肯定为红色,因为父节点p为黑色的话,那就不用调整了(插入红节点对原则五并没有印象),所以只有父结点p是左结点和右结点的两种情况。
- 既然父结点p为红色,那么父父结点pp肯定为黑色(根据原则四),那么p的兄弟节点y,存在两种情况,颜色为红或者黑。
所以综上,x插入要调整的所有情况有:2 * 2 * 2 = 8种,但是当y为红色的时候不用调整,不需要考虑x的插入位置,所以8 - 2 = 6种,且只要懂三种就够了,剩余的是左右对称的。至于为什么要这么处理这里就不展开了。感兴趣的园友们可以推荐这篇看一下:红黑树的插入操作
至于左旋转和右旋转就不拿出来分析了。
3.3.3 remove(Object key)
最后我们再来看一下remove方法:
public V remove(Object key) {
//获取Entry
Entry<K,V> p = getEntry(key);
if (p == null)
return null;
V oldValue = p.value;
//删除的关键方法
deleteEntry(p);
return oldValue;
}
在看deleteEntry之前,我们先来看一下successor方法,为其做准备:
//查找t的后继结点
static <K,V> TreeMap.Entry<K,V> successor(Entry<K,V> t) {
if (t == null)
return null;
//从t的右子树中找到最小的
else if (t.right != null) {
Entry<K,V> p = t.right;
while (p.left != null)
p = p.left;
return p;
//当右子树为空时,向上找到第一个左父节点
} else {
Entry<K,V> p = t.parent;
Entry<K,V> ch = t;
while (p != null && ch == p.right) {
ch = p;
p = p.parent;
}
return p;
}
}
上述的目的是找到最接近且大于t的结点,这样的话,直接用来替换掉t,对原有的树结构变动最小。
private void deleteEntry(Entry<K,V> p) {
modCount++;
size--;
//① p的左右子树都不为空,找到右子树中最小的结点,将key、value赋给p,然后p指向后继结点
if (p.left != null && p.right != null) {
Entry<K,V> s = successor(p);
p.key = s.key;
p.value = s.value;
p = s;
}
//获取p中不为空的结点,也可能两个都是空的
Entry<K,V> replacement = (p.left != null ? p.left : p.right);
//① 替换的结点有一个子节点
if (replacement != null) {
replacement.parent = p.parent;
if (p.parent == null)
root = replacement;
else if (p == p.parent.left)
p.parent.left = replacement;
else
p.parent.right = replacement;
//清空链接,以便可以使用fixAfterDeletion和内存回收
p.left = p.right = p.parent = null;
if (p.color == BLACK)
fixAfterDeletion(replacement);
// ② 删除的结点是根结点
} else if (p.parent == null) {
root = null;
// ③ 替换的结点是空节点
} else {
if (p.color == BLACK)
fixAfterDeletion(p);
if (p.parent != null) {
if (p == p.parent.left)
//清空链接,方便GC
p.parent.left = null;
else if (p == p.parent.right)
p.parent.right = null;
//清空链接,方便GC
p.parent = null;
}
}
}
整体思路是:
- 当删除结点p的左右结点都不为空的时候,选择大于且最接近p的后继结点s,直接将s的key、value替换掉p的原有值,然后对后继结点s做删除处理。此时的s必有一个左必为空,做操作2
- 对于有左右结点有一个为空的p时,在不为空的结点replacement,与p的parent之间修改父子节点间引用关系
- 两个结点都是空的就更简单了,直接删掉
- 对于删除的黑色的结点进行fix
在获取replacement的时候,p的左右结点为空的个数>=1,
- 没有进前面if条件,则说明p至少有一个为空
- 进入if条件,则在p的右树中找最小节点s,s左结点必为空,右结点可能存在
下面让我们来看一下fixAfterDeletion的源码的源码:
private void fixAfterDeletion(Entry<K,V> x) {
while (x != root && colorOf(x) == BLACK) {
//x是左结点且为黑色
if (x == leftOf(parentOf(x))) {
//获取兄弟右节点
Entry<K,V> sib = rightOf(parentOf(x));
//① 兄弟右节点sib颜色是红色
if (colorOf(sib) == RED) {
setColor(sib, BLACK);
setColor(parentOf(x), RED);
rotateLeft(parentOf(x));
sib = rightOf(parentOf(x));
}
//② sib的子节点都是黑色
if (colorOf(leftOf(sib)) == BLACK &&
colorOf(rightOf(sib)) == BLACK) {
setColor(sib, RED);
x = parentOf(x);
//sib子节点不全为黑
} else {
//③ sib右子节点为黑色
if (colorOf(rightOf(sib)) == BLACK) {
setColor(leftOf(sib), BLACK);
setColor(sib, RED);
rotateRight(sib);
sib = rightOf(parentOf(x));
}
// ④
setColor(sib, colorOf(parentOf(x)));
setColor(parentOf(x), BLACK);
setColor(rightOf(sib), BLACK);
rotateLeft(parentOf(x));
x = root;
}
// 对称
} else {
Entry<K,V> sib = leftOf(parentOf(x));
if (colorOf(sib) == RED) {
setColor(sib, BLACK);
setColor(parentOf(x), RED);
rotateRight(parentOf(x));
sib = leftOf(parentOf(x));
}
if (colorOf(rightOf(sib)) == BLACK &&
colorOf(leftOf(sib)) == BLACK) {
setColor(sib, RED);
x = parentOf(x);
} else {
if (colorOf(leftOf(sib)) == BLACK) {
setColor(rightOf(sib), BLACK);
setColor(sib, RED);
rotateLeft(sib);
sib = leftOf(parentOf(x));
}
setColor(sib, colorOf(parentOf(x)));
setColor(parentOf(x), BLACK);
setColor(leftOf(sib), BLACK);
rotateRight(parentOf(x));
x = root;
}
}
}
setColor(x, BLACK);
}
fixAfterDeletion总体思路是:由于删除的结点x是黑色,所以在该结点的树上做调整没法使红黑树恢复平衡,所以要依靠x的兄弟结点sib做文章,依靠p结点以及sib和其子结点,将x的黑色结点+1,这里具体就不展开了。感兴趣的园友们可以推荐这篇看一下:红黑树的删除操作
四、总结
TreeMap这一章对数据结构的理解有一定的要求。如果深入分析为什么在插入和删除调整过程中做这些操作的话,篇幅会太长,以后如果有空的话,再细细讨论。另外有解读不对的地方可以留言指正,最后谢谢各位园友观看,与大家共同进步!
参考链接:
作者:joemsu
出处:http://www.cnblogs.com/joemsu
如果您喜欢我的文章,请不吝点一下“推荐”按钮,您的支持将会是我不竭的动力。
版权声明:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号