
1. Linux概述
1.1 Linux操作系统架构简介
Linux系统一般有4个主要部分:
①内核②shell③文件系统④应用程序。
内核、shell和文件系统一起形成了基本的操作系统结构,它们使得用户可以运行程序、管理文件并使用系统。部分结构层次如下图
1.2 OSI、TCP/IP协议栈与Linux网络架构
1.2.1 OSI与TCP/IP协议栈
OSI(Open System Interconnection,开放式通信互联)是由ISO(International Organization for Standardization,国际标准化组织)制定的标准模型。旨在将世界各地的各种计算机互联。
然而,OSI模型过于庞大、复杂。参照此模型,技术人员开发了TCP/IP协议栈,简化OSI七层模型为TCP/IP四层模型。获得了更广泛的使用。
OSI模型和TCP/IP模型对比:

从上图可以看到,TCP/IP模型合并了OSI模型的应用层、表示层和会话层,将OSI模型的数据链路层和物理层合并为网络访问层。
上图还列出了各层模型对应TCP/IP协议栈中的协议以及各层协议之间的关系。比如DNS协议是建立在TCP和UDP协议的基础上,FTP、HTTP、TELNET协议建立在TCP协议的基础上,NTP、TFTP、SNMP建立在UDP协议的基础上,而TCP、UDP协议又建立在IP协议的基础上,以此类推…..
1.2.2 Linux网络架构
Linux网络体系结构如下图由以下五个部分组成 1)系统调用接口 2)协议无关几口 3)网络协议 4)设备无关接口 5 设备驱动程序。
下面分别简述五个部分:
1.2.2.1 系统调用接口
系统调用接口是用户空间的应用程序正常访问内核的唯一合法途径(终端和陷入也可访问内核)。如:
asmlingkage long sys_getpid(void)
{
return current->pid;
}
系统调用一般由sys开头 ,前面的修饰符是asmlingkage,表示函数由堆栈获得参数。
1.2.2.2 协议无关接口
协议无关接口是由socket来实现的。它提供了一组通用函数来支持各种不同协议。
通过网络栈进行的通信都需要对 socket 进行操作。Linux 中的 socket 结构是 struct sock ,这个结构是在 linux/include/net/sock.h 中定义的。这个巨大的结构中包含了特定 socket 所需要的所有状态信息,其中包括 socket 所使用的特定协议和在 socket 上可以执行的一些操作。
网络子系统可以通过一个定义了自己功能的特殊结构来了解可用协议。每个协议都维护了一个名为 proto 的结构(可以在 linux/include/net/sock.h 中找到)。这个结构定义了可以在从 socket 层到传输层中执行特定的 socket 操作
1.2.2.3 网络协议
Linux支持多种网络协议,可以在<linux/socket.h>中查到所支持的网络协议:
#define AF_UNIX 1 /* Unix domain sockets */
#define AF_LOCAL 1 /* POSIX name for AF_UNIX */
#define AF_INET 2 /* Internet IP Protocol */
#define AF_AX25 3 /* Amateur Radio AX.25 */
#define AF_IPX 4 /* Novell IPX
… …
其中每一个所支持的协议对应net_family[]数组中的一项,net_family[]是结构体指针数组,其中的每一项都是一个结构体指针,指向一个net_proto_family 结构
struct net_proto_family {
int family;
int (*create) (struct socket * sock, int protocol);
short authentication;
short encryption;
short encrypt_net;
struct module *owner;
};
1.2.2.4 设备无关接口
设备无关接口是由net_device实现的。任何设备和上层通信都是通过net_device设备无关接口。
它将协议与具有很多各种不同功能的硬件设备连接在一起。这一层提供了一组通用函数供底层网络设备驱动程序使用,让它们可以对高层协议栈进行操作。
首先,设备驱动程序可能会通过调用 register_netdevice 或 unregister_netdevice 在内核中进行注册或注销。调用者首先填写 net_device 结构,然后传递这个结构进行注册。内核调用它的 init 函数(如果定义了这种函数),然后执行一组健全性检查,并创建一个 sysfs 条目,然后将新设备添加到设备列表中(内核中的活动设备链表)。在 linux/include/linux/netdevice.h 中可以找到这个 net_device 结构。这些函数都是在 linux/net/core/dev.c 中实现的。
要从协议层向设备中发送 sk_buff ,就需要使用 dev_queue_xmit 函数。这个函数可以对 sk_buff 进行排队,从而由底层设备驱动程序进行最终传输(使用 sk_buff 中引用的 net_device 或 sk_buff->dev 所定义的网络设备)。dev 结构中包含了一个名为 hard_start_xmit 的方法,其中保存有发起 sk_buff 传输所使用的驱动程序函数。
报文的接收通常是使用 netif_rx 执行的。当底层设备驱动程序接收一个报文(包含在所分配的 sk_buff 中)时,就会通过调用 netif_rx 将 sk_buff 上传至网络层。然后,这个函数通过 netif_rx_schedule 将 sk_buff 在上层协议队列中进行排队,供以后进行处理。可以在 linux/net/core/dev.c 中找到 dev_queue_xmit 和 netif_rx 函数。
1.2.2.5 设备驱动程序
网络栈底部是负责管理物理网络设备的设备驱动程序。例如,包串口使用的 SLIP 驱动程序以及以太网设备使用的以太网驱动程序都是这一层的设备。
在进行初始化时,设备驱动程序会分配一个 net_device 结构,然后使用必须的程序对其进行初始化。这些程序中有一个是 dev->hard_start_xmit ,它定义了上层应该如何对 sk_buff 排队进行传输。这个程序的参数为 sk_buff 。这个函数的操作取决于底层硬件,但是通常 sk_buff 所描述的报文都会被移动到硬件环或队列中。就像是设备无关层中所描述的一样,对于 NAPI 兼容的网络驱动程序来说,帧的接收使用了 netif_rx 和 netif_receive_skb 接口。NAPI 驱动程序会对底层硬件的能力进行一些限制。
1.2.3 各层次设计的主要数据结构与函数
1.2.3.1 核心数据结构-sk_buff
网络层的数据都是通过sk_buff来传递的。
与sk_buff相关的一些数据结构有:socket sock proto proto_ops;
在Linux内核的网络实现中,使用了一个缓存结构(struct sk_buff)来管理网络报文,这个缓存区也叫套接字缓存。sk_buff是内核网络子系统中最重要的一种数据结构,它贯穿网络报文收发的整个周期。该结构在内核源码的include/linux/skbuff.h文件中定义。我们有必要了解结构中每个字段的意义。
一个套接字缓存由两部份组成:
· 报文数据:存储实际需要通过网络发送和接收的数据。
· 管理数据(struct sk_buff):管理报文所需的数据,在sk_buff结构中有一个head指针指向内存中报文数据开始的位置,有一个data指针指向报文数据在内存中的具体地址。head和data之间申请有足够多的空间用来存放报文头信息。
下面是sk_buf的数据结构:
struct sk_buff
{
struct sk_buff *next,*prev;
struct sk_buff_head *list;
struct sock *sk; //sock结构指针
struct timeval stamp;
struct net_device *dev, *rx_dev;
union /* Transport layer header */
{
struct tcphdr *th;
struct udphdr *uh;
struct icmphdr *icmph;
struct igmphdr *igmph;
struct iphdr *ipiph;
struct spxhdr *spxh;
unsigned char *raw;
} h; //传输层头
union /* Network layer header */
{
struct iphdr *iph;
struct ipv6hdr *ipv6h;
struct arphdr *arph;
struct ipxhdr *ipxh;
unsigned char *raw;
} nh; //网络层头
union /* Link layer header */
{
struct ethhdr *ethernet;
unsigned char *raw;
} mac; //数据链路层头
struct dst_entry *dst;
char cb[48];
unsigned int len, csum; //数据长度,是否被消耗
volatile char used;
unsigned char is_clone, cloned, pkt_type, ip_summed; //是否克隆 已克隆 报文类型 校验和
__u32 priority;
atomic_t users;
unsigned short protocol, security;
unsigned int truesize;
unsigned char *head, *data, *tail, *end; //data和tail指向当前有效数据的头和尾
void (*destructor)(struct sk_buff *); //head和end指向socket的头和尾
…
};
1.2.2.2 net_device
设备无关层的统一接口。
net_device结构是Linux内核中所有网络设备的基础数据结构。包含网络适配器的硬件信息(中断、端口、驱动程序函数等)和高层网络协议的网络配置信息(IP地址、子网掩码等)。该结构的定义位于include/linux/netdevice.h
每个net_device结构表示一个网络设备,如eth0、eth1...。这些网络设备通过dev_base线性表链接起来。内核变量dev_base表示已注册网络设备列表的入口点,它指向列表的第一个元素(eth0)。然后各元素用next字段指向下一个元素(eth1)。使用ifconfig -a命令可以查看系统中所有已注册的网络设备。
net_device结构通过alloc_netdev函数分配,alloc_netdev函数位于net/core/dev.c文件中。该函数需要三个参数。
· 私有数据结构的大小
· 设备名,如eth0,eth1等。
· 配置例程,这些例程会初始化部分net_device字段。
分配成功则返回指向net_device结构的指针,分配失败则返回NULL。
下面是net_device的部分数据结构
struct net_device
{
/*
* This is the first field of the "visible" part of this structure
* (i.e. as seen by users in the "Space.c" file). It is the name
* the interface.
*/
char name[IFNAMSIZ]; //不必多说,就是ifconfig 后面的第一个参数
/* device name hash chain */
struct hlist_node name_hlist;
/*
* I/O specific fields
* FIXME: Merge these and struct ifmap into one
*/
unsigned long mem_end; /* shared mem end */
unsigned long mem_start; /* shared mem start */
unsigned long base_addr; /* device I/O address */
unsigned int irq; /* device IRQ number */
/*
* Some hardware also needs these fields, but they are not
* part of the usual set specified in Space.c.
*/
unsigned char if_port; /* Selectable AUI, TP,..*/
unsigned char dma; /* DMA channel */
unsigned long state;
struct list_head dev_list;
/* The device initialization function. Called only once. */
int (*init)(struct net_device *dev);
/* ------- Fields preinitialized in Space.c finish here ------- */
/* Net device features */
unsigned long features;
1.2.2.3 物理层上的数据
hard_header_length 第二层包报头长度
mtu 最大传输单元
tx_queue_len 网络设备输出队列最大长度
type 网络适配器硬件类型
addr_len 第二层地址长度
dev_addr[MAX_ADDR_LEN] 第二层地址
broadcast[MAX_ADDR_LEN] 广播地址
*mc_list 指向具有多播第二层地址的线性表
mc_count dev_mc_list中的地址数量(多播地址数)
watchdpg_timeo 超时时间(从trans_start开始,经过watchdog_timeo时间后超时)
1.2.2.4 硬件相关字段
rmem_end 接受内存尾地址
rmem-start 接受内存首地址
mem_end 发送内存尾地址
mem_start 发送内存首地址
base_addr 网络设备的基地址(见后图)
irq 中断号
if_port 端口号
1.2.2.5 设备驱动程序的函数
init() 搜索并初始化网络设备
uninit() 注销网络设备
destructor() 当网络设备的最后一个引用refcnt被删除时调用此函数
open () 打开网络设备
stop() 关闭网络设备
hard_start_xmit() 发送包,成功返回0,否则返回1
get_stats() 获取网络设备状态信息,这些信息以net_device_stats 结构的形式返回
get_wireless_stats() 获取无限网络设备的状态信息,这些信息以iw_statistics 结构的形式返回
set_multicast_list() 将多播MAC地址传给网络适配器
watchdog_timeo() 超时处理函数
do_ioctl() 向网络驱动程序传递网络适配器相关的ioctl()命令
set_config() 运行时改变网络适配器的配置
上面所列的方法依赖于所使用的网络适配器,也就是说如果需要他们的功能则必须由驱动程序来提供。
下面所列的方法较少依赖于适配器,不必由驱动程序相关方法实现。
hard_header() 根据源和目标第二层地址创建二层报头
rebuild_header() 重建第二层报头
hard_header_cache() 用硬报头缓存中保存的数据填充第二层报头
header_cache_update() 更改硬报头缓存中保存的第二层报头数据
hard_header_parse() 从套接字缓冲区的包数据空间读取第二层报头的发送地址
set_mac_address() 设mac地址
change_mtu() 改变mtu长度
2.send和recv的传输层流程
首先进入socketcall函数,socketcall函数是所有socket函数进入内核空间的共同入口
socketcall的定义如下
SYSCALL_DEFINE2(socketcall, int, call, unsigned long __user *, args)
{
unsigned long a[AUDITSC_ARGS];
unsigned long a0, a1;
int err;
unsigned int len;
if (call < 1 || call > SYS_SENDMMSG)
return -EINVAL;
call = array_index_nospec(call, SYS_SENDMMSG + 1);
len = nargs[call];
if (len > sizeof(a))
return -EINVAL;
/* copy_from_user should be SMP safe. */
if (copy_from_user(a, args, len))
return -EFAULT;
err = audit_socketcall(nargs[call] / sizeof(unsigned long), a);
if (err)
return err;
a0 = a[0];
a1 = a[1];
switch (call) {
case SYS_SOCKET:
err = __sys_socket(a0, a1, a[2]);
break;
case SYS_BIND:
err = __sys_bind(a0, (struct sockaddr __user *)a1, a[2]);
break;
case SYS_CONNECT:
err = __sys_connect(a0, (struct sockaddr __user *)a1, a[2]);
break;
case SYS_LISTEN:
err = __sys_listen(a0, a1);
break;
case SYS_ACCEPT:
err = __sys_accept4(a0, (struct sockaddr __user *)a1,
(int __user *)a[2], 0);
break;
case SYS_GETSOCKNAME:
err =
__sys_getsockname(a0, (struct sockaddr __user *)a1,
(int __user *)a[2]);
break;
case SYS_GETPEERNAME:
err =
__sys_getpeername(a0, (struct sockaddr __user *)a1,
(int __user *)a[2]);
break;
case SYS_SOCKETPAIR:
err = __sys_socketpair(a0, a1, a[2], (int __user *)a[3]);
break;
case SYS_SEND:
err = __sys_sendto(a0, (void __user *)a1, a[2], a[3],
NULL, 0);
break;
case SYS_SENDTO:
err = __sys_sendto(a0, (void __user *)a1, a[2], a[3],
(struct sockaddr __user *)a[4], a[5]);
break;
case SYS_RECV:
err = __sys_recvfrom(a0, (void __user *)a1, a[2], a[3],
NULL, NULL);
break;
case SYS_RECVFROM:
err = __sys_recvfrom(a0, (void __user *)a1, a[2], a[3],
(struct sockaddr __user *)a[4],
(int __user *)a[5]);
break;
case SYS_SHUTDOWN:
err = __sys_shutdown(a0, a1);
break;
case SYS_SETSOCKOPT:
err = __sys_setsockopt(a0, a1, a[2], (char __user *)a[3],
a[4]);
break;
case SYS_GETSOCKOPT:
err =
__sys_getsockopt(a0, a1, a[2], (char __user *)a[3],
(int __user *)a[4]);
break;
case SYS_SENDMSG:
err = __sys_sendmsg(a0, (struct user_msghdr __user *)a1,
a[2], true);
break;
case SYS_SENDMMSG:
err = __sys_sendmmsg(a0, (struct mmsghdr __user *)a1, a[2],
a[3], true);
break;
case SYS_RECVMSG:
err = __sys_recvmsg(a0, (struct user_msghdr __user *)a1,
a[2], true);
break;
case SYS_RECVMMSG:
if (IS_ENABLED(CONFIG_64BIT) || !IS_ENABLED(CONFIG_64BIT_TIME))
err = __sys_recvmmsg(a0, (struct mmsghdr __user *)a1,
a[2], a[3],
(struct __kernel_timespec __user *)a[4],
NULL);
else
err = __sys_recvmmsg(a0, (struct mmsghdr __user *)a1,
a[2], a[3], NULL,
(struct old_timespec32 __user *)a[4]);
break;
case SYS_ACCEPT4:
err = __sys_accept4(a0, (struct sockaddr __user *)a1,
(int __user *)a[2], a[3]);
break;
default:
err = -EINVAL;
break;
}
return err;
}
可以看到发送send的入口函数是 __sys_sendto,recv函数的入口是 _ _sys_recvfrom()函数
截图入下:
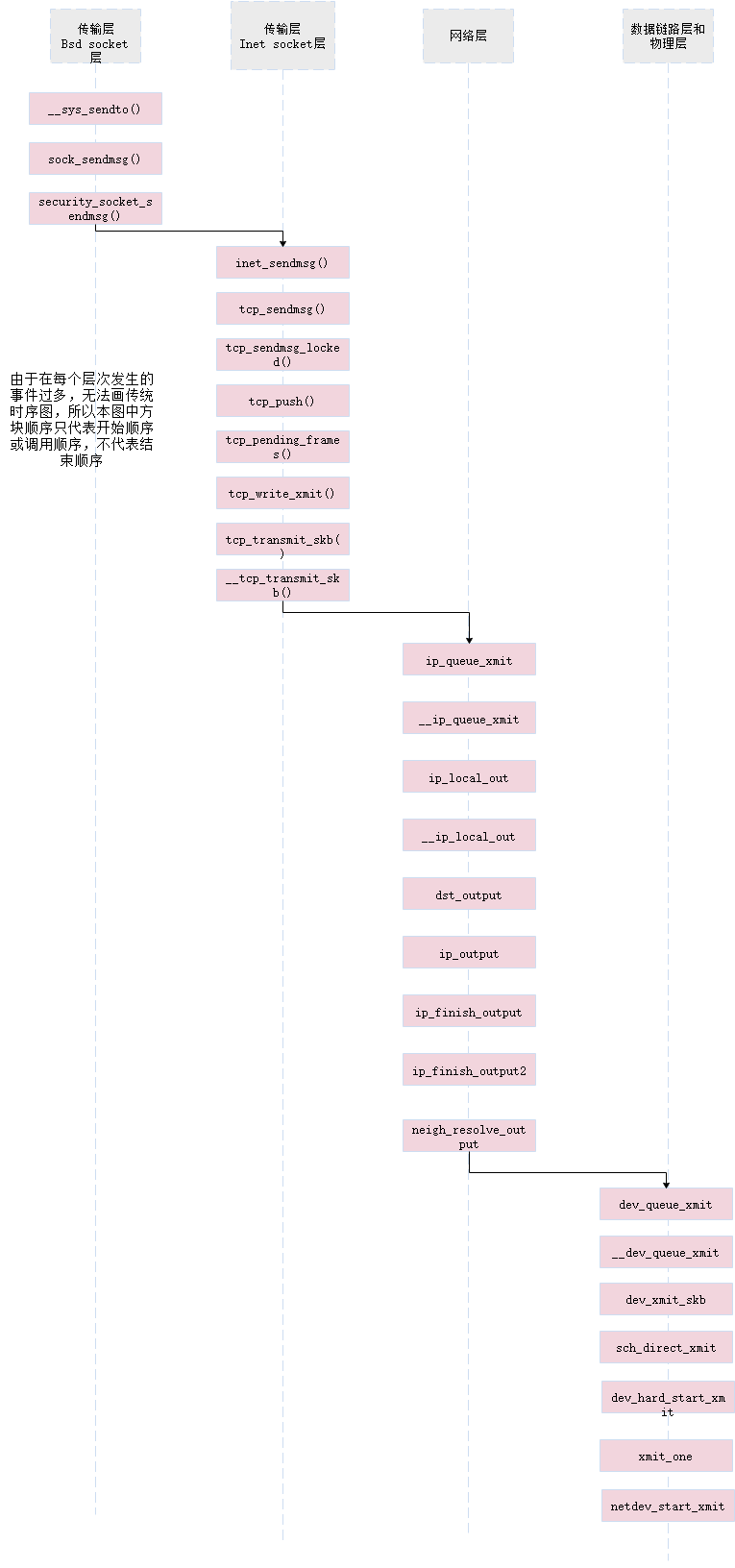
2.1 send在传输层的函数调用流程
2.1.1 Bsd Socket层
2.1.1.1 __sys_sendto函数

sendto() 用来将数据由指定的socket 传给对方主机. 参数s 为已建好连线的socket, 如果利用UDP协议则不需经过连线操作. 参数msg 指向欲连线的数据内容, 参数flags 一般设0, 详细描述请参考send(). 参数to 用来指定欲传送的网络地址, 结构sockaddr 请参考bind(). 参数tolen 为sockaddr 的结果长度.
在第1952行,可以看到调用到sock_sendmsg函数
2.1.1.2 sock_sendmsg函数
可以看到其中直接调用了security_socket_sendmsg函数
security_socket_sendmsg()对数据的发送进行了一些安全性的措施
security_socket_sendmsg()定义如下

通过以上步骤,在kernel启动以后,实现了对kernel中的某些函数的hook。
如果有被hook的系统调用发生,则会触发selinux的安全检查。
实现安全检查的逻辑如下:
1)在每个task_struct对象中保留对struct cred对象的引用,struct cred *real_cred;
2)从real_cred对象中有个security引用(void*类型);
3)从security对象中提取需要安全上下文;
4)通过对比进程的安全上下文,和目标文件的安全上下文,决定deny/permissive当前的系统调用。
然后调用sock_sendmsg_nosec()函数来发送数据
sock_sendmsg_nosec()函数在/net/socket.c中

开始调用下一层的inet_sendmsg()函数
2.1.2 Inet_socket层
2.1.2.1 inet_sendmsg函数
inet_sendmsg在/net/ipv4/af_inet.c中
在进行必要的准备工作后,根据参数选择调用tcp_sendmsg,udp_sendmsg

2.1.2.2 tcp_sendmsg函数
tcp_sendmsg()在net/ipv4/tcp.c中
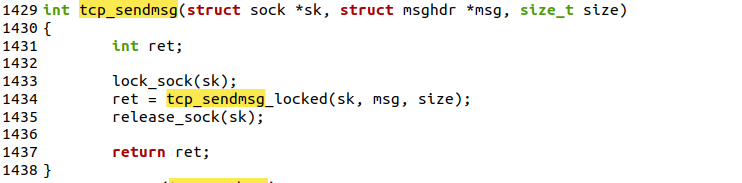
可以看出函数是先调用lock_sock()加锁,然后调用tcp_sendmsg_locked()函数进行发送,然后调用release_sock()函数进行解锁
// 申请SKB和缓存空间, 将用户空间数据复制到缓存空间中,然后发送出去
int tcp_sendmsg_locked(struct sock *sk, struct msghdr *msg, size_t size) {
// ......
// 这里取得超时时间, 非阻塞时timeo=0
timeo = sock_sndtimeo(sk, flags & MSG_DONTWAIT);
// ......
// while循环直到用户空间的数据都复制到了内核空间
while (msg_data_left(msg)) {
// ......
// 假设需要发送的数据量很大,则一直往内核缓存塞用户空间的数据,直到:
if (!sk_page_frag_refill(sk, pfrag))
goto wait_for_memory; // 如果缓存不足,进入wait_for_memory
// ......
}
// ......
// 如果是非阻塞模式, 这里timeo为0, 即立刻返回用户态, 否则阻塞
wait_for_memory:
err = sk_stream_wait_memory(sk, &timeo);
// ......
}
而在tcp_sendmsg_locked()
tcp_sendmsg_locked()中,主要调用了tcp_push()函数
2.1.2.3 tcp_push函数
tcp_push调用了__tcp_push_pending_frames()函数
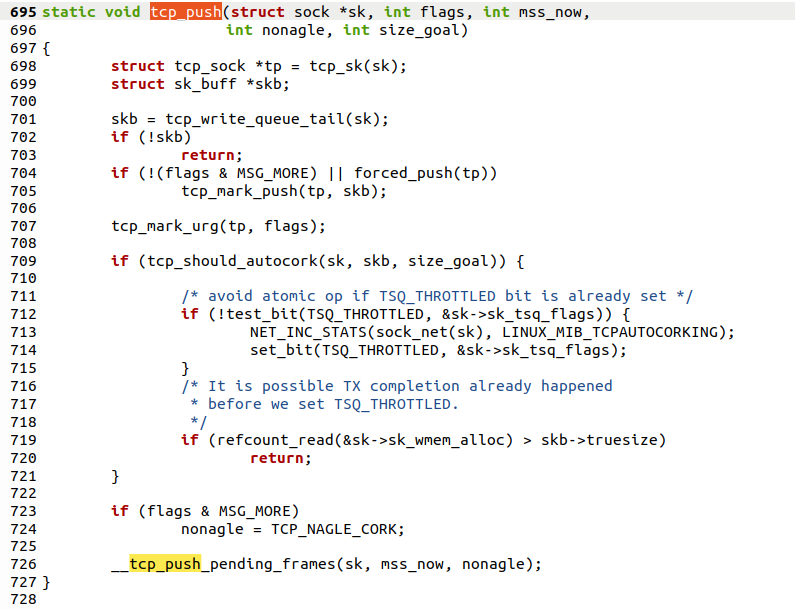
②tcp_write_xmit()函数把数据写到缓存里,即实现了拥塞控制,然后调用了tcp_transmit_skb传输数据
2.1.2.4 tcp_transmit_skb函数
tcp_transmit_skb的作用是复制或者拷贝skb,构造skb中的tcp首部,并将调用网络层的发送函数发送skb;在发送前,首先需要克隆或者复制skb,因为在成功发送到网络设备之后,skb会释放,而tcp层不能真正的释放,是需要等到对该数据段的ack才可以释放;然后构造tcp首部和选项;最后调用网络层提供的发送回调函数发送skb,ip层的回调函数为ip_queue_xmit;

tcp_transmit_skb()直接调用了__tcp_tranmit_skb()

2.1.3 调试验证√
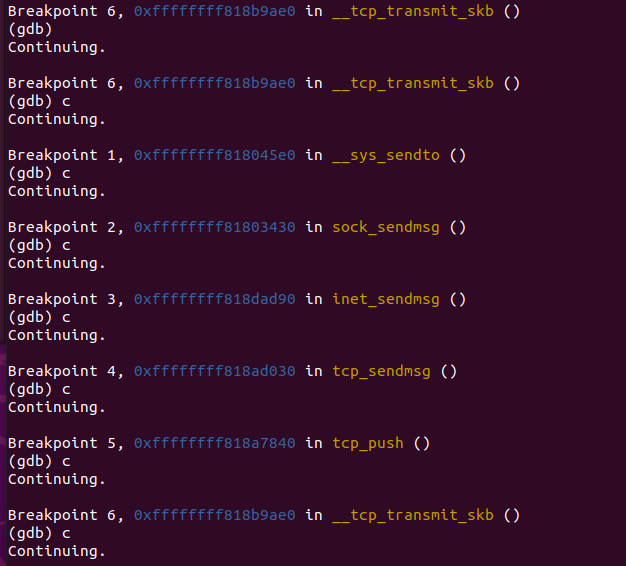
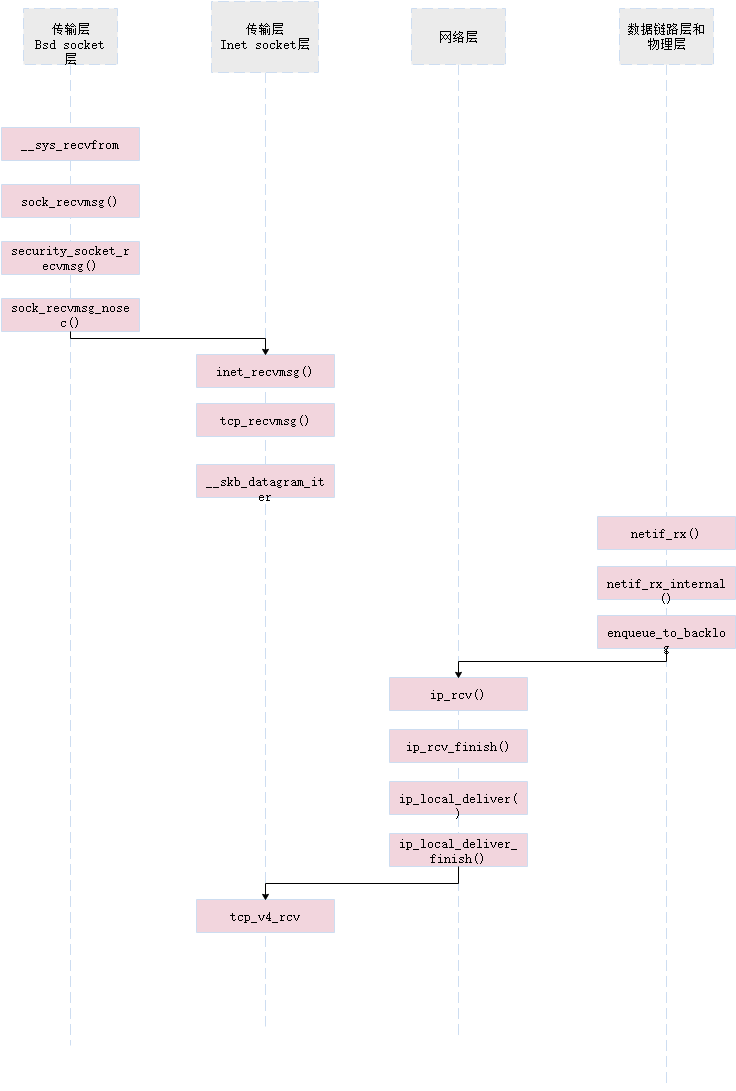
2.2 recv在传输层的函数调用流程
2.2.1 Bsd socket层
2.2.1.1 __sys_recvfrom函数
__sys_recvfrom调用了sock_recvmsg来接收数据,整个函数实际调用的是sock->ops->recvmsg(sock, msg, msg_data_left(msg), flags);,同样,根据tcp_prot结构的初始化,调用的其实是tcp_rcvmsg .接受函数比发送函数要复杂得多,因为数据接收不仅仅只是接收,tcp的三次握手也是在接收函数实现的,所以收到数据后要判断当前的状态,是否正在建立连接等,根据发来的信息考虑状态是否要改变,在这里,我们仅仅考虑在连接建立后数据的接收
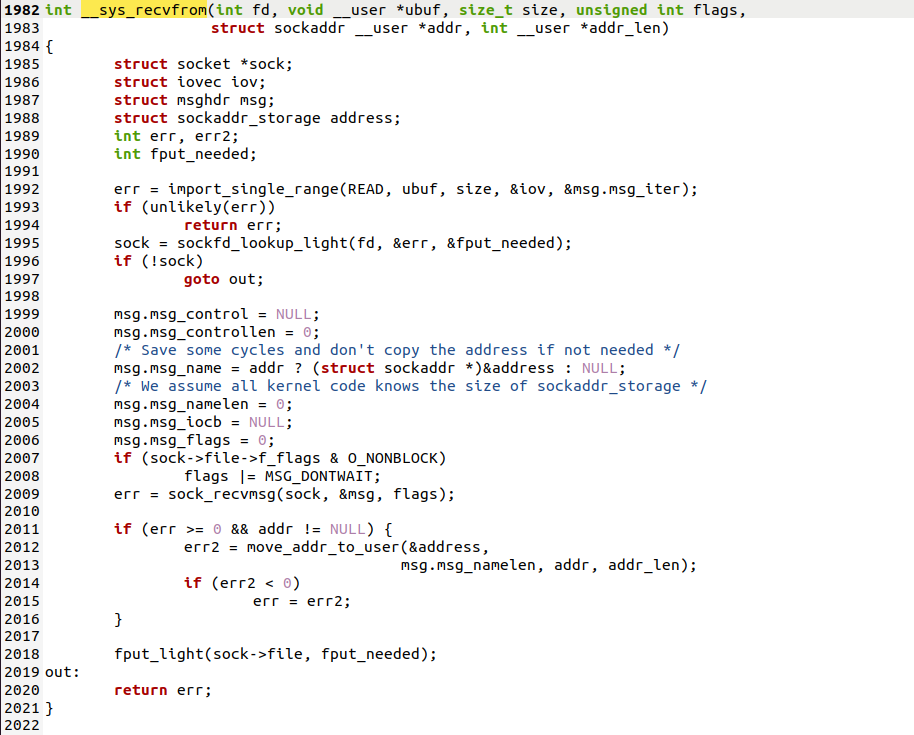
2.2.1.2 sock_recvmsg函数

再sock_recvmsg()函数调用了securty_socket_recvmsg()来进行安全检查,让sock_recvmsg_nosec()负责具体的接受工作。

2.2.2 Inet Socket层
2.2.2.1 inet_recvmsg函数
/net/ipv4/af_inet.c

在进行一系列准备工作吼,根据第838行的代码,因为本程序使用的TCP协议,所以选择tcp_recvmsg函数进行执行
2.2.2.2 tcp_recvmsg函数
/net/ipv4/tcp.c
tcp_recvmsg的函数体如下图
int tcp_recvmsg(struct sock *sk, struct msghdr *msg, size_t len, int nonblock,
int flags, int *addr_len)
{
struct tcp_sock *tp = tcp_sk(sk);
int copied = 0;
u32 peek_seq;
u32 *seq;
unsigned long used;
int err, inq;
int target; /* Read at least this many bytes */
long timeo;
struct sk_buff *skb, *last;
u32 urg_hole = 0;
struct scm_timestamping_internal tss;
int cmsg_flags;
if (unlikely(flags & MSG_ERRQUEUE))
return inet_recv_error(sk, msg, len, addr_len);
if (sk_can_busy_loop(sk) && skb_queue_empty_lockless(&sk->sk_receive_queue) &&
(sk->sk_state == TCP_ESTABLISHED))
sk_busy_loop(sk, nonblock);
lock_sock(sk);
err = -ENOTCONN;
if (sk->sk_state == TCP_LISTEN)
goto out;
cmsg_flags = tp->recvmsg_inq ? 1 : 0;
timeo = sock_rcvtimeo(sk, nonblock);
/* Urgent data needs to be handled specially. */
if (flags & MSG_OOB)
goto recv_urg;
if (unlikely(tp->repair)) {
err = -EPERM;
if (!(flags & MSG_PEEK))
goto out;
if (tp->repair_queue == TCP_SEND_QUEUE)
goto recv_sndq;
err = -EINVAL;
if (tp->repair_queue == TCP_NO_QUEUE)
goto out;
/* 'common' recv queue MSG_PEEK-ing */
}
seq = &tp->copied_seq;
if (flags & MSG_PEEK) {
peek_seq = tp->copied_seq;
seq = &peek_seq;
}
target = sock_rcvlowat(sk, flags & MSG_WAITALL, len);
do {
u32 offset;
/* Are we at urgent data? Stop if we have read anything or have SIGURG pending. */
if (tp->urg_data && tp->urg_seq == *seq) {
if (copied)
break;
if (signal_pending(current)) {
copied = timeo ? sock_intr_errno(timeo) : -EAGAIN;
break;
}
}
/* Next get a buffer. */
last = skb_peek_tail(&sk->sk_receive_queue);
skb_queue_walk(&sk->sk_receive_queue, skb) {
last = skb;
/* Now that we have two receive queues this
* shouldn't happen.
*/
if (WARN(before(*seq, TCP_SKB_CB(skb)->seq),
"TCP recvmsg seq # bug: copied %X, seq %X, rcvnxt %X, fl %X\n",
*seq, TCP_SKB_CB(skb)->seq, tp->rcv_nxt,
flags))
break;
offset = *seq - TCP_SKB_CB(skb)->seq;
if (unlikely(TCP_SKB_CB(skb)->tcp_flags & TCPHDR_SYN)) {
pr_err_once("%s: found a SYN, please report !\n", __func__);
offset--;
}
if (offset < skb->len)
goto found_ok_skb;
if (TCP_SKB_CB(skb)->tcp_flags & TCPHDR_FIN)
goto found_fin_ok;
WARN(!(flags & MSG_PEEK),
"TCP recvmsg seq # bug 2: copied %X, seq %X, rcvnxt %X, fl %X\n",
*seq, TCP_SKB_CB(skb)->seq, tp->rcv_nxt, flags);
}
/* Well, if we have backlog, try to process it now yet. */
if (copied >= target && !sk->sk_backlog.tail)
break;
if (copied) {
if (sk->sk_err ||
sk->sk_state == TCP_CLOSE ||
(sk->sk_shutdown & RCV_SHUTDOWN) ||
!timeo ||
signal_pending(current))
break;
} else {
if (sock_flag(sk, SOCK_DONE))
break;
if (sk->sk_err) {
copied = sock_error(sk);
break;
}
if (sk->sk_shutdown & RCV_SHUTDOWN)
break;
if (sk->sk_state == TCP_CLOSE) {
/* This occurs when user tries to read
* from never connected socket.
*/
copied = -ENOTCONN;
break;
}
if (!timeo) {
copied = -EAGAIN;
break;
}
if (signal_pending(current)) {
copied = sock_intr_errno(timeo);
break;
}
}
tcp_cleanup_rbuf(sk, copied);
if (copied >= target) {
/* Do not sleep, just process backlog. */
release_sock(sk);
lock_sock(sk);
} else {
sk_wait_data(sk, &timeo, last);
}
if ((flags & MSG_PEEK) &&
(peek_seq - copied - urg_hole != tp->copied_seq)) {
net_dbg_ratelimited("TCP(%s:%d): Application bug, race in MSG_PEEK\n",
current->comm,
task_pid_nr(current));
peek_seq = tp->copied_seq;
}
continue;
found_ok_skb:
/* Ok so how much can we use? */
used = skb->len - offset;
if (len < used)
used = len;
/* Do we have urgent data here? */
if (tp->urg_data) {
u32 urg_offset = tp->urg_seq - *seq;
if (urg_offset < used) {
if (!urg_offset) {
if (!sock_flag(sk, SOCK_URGINLINE)) {
WRITE_ONCE(*seq, *seq + 1);
urg_hole++;
offset++;
used--;
if (!used)
goto skip_copy;
}
} else
used = urg_offset;
}
}
if (!(flags & MSG_TRUNC)) {
err = skb_copy_datagram_msg(skb, offset, msg, used);
if (err) {
/* Exception. Bailout! */
if (!copied)
copied = -EFAULT;
break;
}
}
WRITE_ONCE(*seq, *seq + used);
copied += used;
len -= used;
tcp_rcv_space_adjust(sk);
skip_copy:
if (tp->urg_data && after(tp->copied_seq, tp->urg_seq)) {
tp->urg_data = 0;
tcp_fast_path_check(sk);
}
if (used + offset < skb->len)
continue;
if (TCP_SKB_CB(skb)->has_rxtstamp) {
tcp_update_recv_tstamps(skb, &tss);
cmsg_flags |= 2;
}
if (TCP_SKB_CB(skb)->tcp_flags & TCPHDR_FIN)
goto found_fin_ok;
if (!(flags & MSG_PEEK))
sk_eat_skb(sk, skb);
continue;
found_fin_ok:
/* Process the FIN. */
WRITE_ONCE(*seq, *seq + 1);
if (!(flags & MSG_PEEK))
sk_eat_skb(sk, skb);
break;
} while (len > 0);
/* According to UNIX98, msg_name/msg_namelen are ignored
* on connected socket. I was just happy when found this 8) --ANK
*/
/* Clean up data we have read: This will do ACK frames. */
tcp_cleanup_rbuf(sk, copied);
release_sock(sk);
if (cmsg_flags) {
if (cmsg_flags & 2)
tcp_recv_timestamp(msg, sk, &tss);
if (cmsg_flags & 1) {
inq = tcp_inq_hint(sk);
put_cmsg(msg, SOL_TCP, TCP_CM_INQ, sizeof(inq), &inq);
}
}
return copied;
out:
release_sock(sk);
return err;
recv_urg:
err = tcp_recv_urg(sk, msg, len, flags);
goto out;
recv_sndq:
err = tcp_peek_sndq(sk, msg, len);
goto out;
}
这里共维护了三个队列:prequeue、backlog、receive_queue,分别为预处理队列,后备队列和接收队列,在连接建立后,若没有数据到来,接收队列为空,进程会在sk_busy_loop函数内循环等待,知道接收队列不为空,并调用函数数skb_copy_datagram_msg将接收到的数据拷贝到用户态,实际调用的是__skb_datagram_iter,这里同样用了struct msghdr *msg来实现
int __skb_datagram_iter(const struct sk_buff *skb, int offset,
struct iov_iter *to, int len, bool fault_short,
size_t (*cb)(const void *, size_t, void *, struct iov_iter *),
void *data)
{
int start = skb_headlen(skb);
int i, copy = start - offset, start_off = offset, n;
struct sk_buff *frag_iter;
/* 拷贝tcp头部 */
if (copy > 0) {
if (copy > len)
copy = len;
n = cb(skb->data + offset, copy, data, to);
offset += n;
if (n != copy)
goto short_copy;
if ((len -= copy) == 0)
return 0;
}
/* 拷贝数据部分 */
for (i = 0; i < skb_shinfo(skb)->nr_frags; i++) {
int end;
const skb_frag_t *frag = &skb_shinfo(skb)->frags[i];
WARN_ON(start > offset + len);
end = start + skb_frag_size(frag);
if ((copy = end - offset) > 0) {
struct page *page = skb_frag_page(frag);
u8 *vaddr = kmap(page);
if (copy > len)
copy = len;
n = cb(vaddr + frag->page_offset +
offset - start, copy, data, to);
kunmap(page);
offset += n;
if (n != copy)
goto short_copy;
if (!(len -= copy))
return 0;
}
start = end;
}
2.2.2.3 tcp_v4_rcv函数
/net/tcp_ipv4.c
tcp_v4_rcv被ip_local_deliver函数调用,是从IP层协议向INET Socket层提交的"数据到"请求,入口参数skb存放接收到的数据,len是接收的数据的长度,这个函数首先移动skb->data指针,让它指向tcp头,然后更新tcp层的一些数据统计,然后进行tcp的一些值的校验.再从INET Socket层中已经建立的sock{}结构变量中查找正在等待当前到达数据的哪一项.可能这个sock{}结构已经建立,或者还处于监听端口、等待数据连接的状态。返回的sock结构指针存放在sk中。然后根据其他进程对sk的操作情况,将skb发送到合适的位置.调用如下:
TCP包接收器(tcp_v4_rcv)将TCP包投递到目的套接字进行接收处理. 当套接字正被用户锁定,TCP包将暂时排入该套接字的后备队列(sk_add_backlog).这时如果某一用户线程企图锁定该套接字(lock_sock),该线程被排入套接字的后备处理等待队列(sk->lock.wq).当用户释放上锁的套接字时(release_sock,在tcp_recvmsg中调用),后备队列中的TCP包被立即注入TCP包处理器(tcp_v4_do_rcv)进行处理,然后唤醒等待队列中最先的一个用户来获得其锁定权. 如果套接字未被上锁,当用户正在读取该套接字时, TCP包将被排入套接字的预备队列(tcp_prequeue),将其传递到该用户线程上下文中进行处理.如果添加到sk->prequeue不成功,便可以添加到 sk->receive_queue队列中(用户线程可以登记到预备队列,当预备队列中出现第一个包时就唤醒等待线程.)
tcp_v4_rcv详细的定义代码如下
int tcp_v4_rcv(struct sk_buff *skb)
{
struct net *net = dev_net(skb->dev);
struct sk_buff *skb_to_free;
int sdif = inet_sdif(skb);
const struct iphdr *iph;
const struct tcphdr *th;
bool refcounted;
struct sock *sk;
int ret;
if (skb->pkt_type != PACKET_HOST)
goto discard_it;
/* Count it even if it's bad */
__TCP_INC_STATS(net, TCP_MIB_INSEGS);
if (!pskb_may_pull(skb, sizeof(struct tcphdr)))
goto discard_it;
th = (const struct tcphdr *)skb->data;
if (unlikely(th->doff < sizeof(struct tcphdr) / 4))
goto bad_packet;
if (!pskb_may_pull(skb, th->doff * 4))
goto discard_it;
/* An explanation is required here, I think.
* Packet length and doff are validated by header prediction,
* provided case of th->doff==0 is eliminated.
* So, we defer the checks. */
if (skb_checksum_init(skb, IPPROTO_TCP, inet_compute_pseudo))
goto csum_error;
th = (const struct tcphdr *)skb->data;
iph = ip_hdr(skb);
lookup:
sk = __inet_lookup_skb(&tcp_hashinfo, skb, __tcp_hdrlen(th), th->source,
th->dest, sdif, &refcounted);
if (!sk)
goto no_tcp_socket;
process:
if (sk->sk_state == TCP_TIME_WAIT)
goto do_time_wait;
if (sk->sk_state == TCP_NEW_SYN_RECV) {
struct request_sock *req = inet_reqsk(sk);
bool req_stolen = false;
struct sock *nsk;
sk = req->rsk_listener;
if (unlikely(tcp_v4_inbound_md5_hash(sk, skb))) {
sk_drops_add(sk, skb);
reqsk_put(req);
goto discard_it;
}
if (tcp_checksum_complete(skb)) {
reqsk_put(req);
goto csum_error;
}
if (unlikely(sk->sk_state != TCP_LISTEN)) {
inet_csk_reqsk_queue_drop_and_put(sk, req);
goto lookup;
}
/* We own a reference on the listener, increase it again
* as we might lose it too soon.
*/
sock_hold(sk);
refcounted = true;
nsk = NULL;
if (!tcp_filter(sk, skb)) {
th = (const struct tcphdr *)skb->data;
iph = ip_hdr(skb);
tcp_v4_fill_cb(skb, iph, th);
nsk = tcp_check_req(sk, skb, req, false, &req_stolen);
}
if (!nsk) {
reqsk_put(req);
if (req_stolen) {
/* Another cpu got exclusive access to req
* and created a full blown socket.
* Try to feed this packet to this socket
* instead of discarding it.
*/
tcp_v4_restore_cb(skb);
sock_put(sk);
goto lookup;
}
goto discard_and_relse;
}
if (nsk == sk) {
reqsk_put(req);
tcp_v4_restore_cb(skb);
} else if (tcp_child_process(sk, nsk, skb)) {
tcp_v4_send_reset(nsk, skb);
goto discard_and_relse;
} else {
sock_put(sk);
return 0;
}
}
if (unlikely(iph->ttl < inet_sk(sk)->min_ttl)) {
__NET_INC_STATS(net, LINUX_MIB_TCPMINTTLDROP);
goto discard_and_relse;
}
if (!xfrm4_policy_check(sk, XFRM_POLICY_IN, skb))
goto discard_and_relse;
if (tcp_v4_inbound_md5_hash(sk, skb))
goto discard_and_relse;
nf_reset_ct(skb);
if (tcp_filter(sk, skb))
goto discard_and_relse;
th = (const struct tcphdr *)skb->data;
iph = ip_hdr(skb);
tcp_v4_fill_cb(skb, iph, th);
skb->dev = NULL;
if (sk->sk_state == TCP_LISTEN) {
ret = tcp_v4_do_rcv(sk, skb);
goto put_and_return;
}
sk_incoming_cpu_update(sk);
bh_lock_sock_nested(sk);
tcp_segs_in(tcp_sk(sk), skb);
ret = 0;
if (!sock_owned_by_user(sk)) {
skb_to_free = sk->sk_rx_skb_cache;
sk->sk_rx_skb_cache = NULL;
ret = tcp_v4_do_rcv(sk, skb);
} else {
if (tcp_add_backlog(sk, skb))
goto discard_and_relse;
skb_to_free = NULL;
}
bh_unlock_sock(sk);
if (skb_to_free)
__kfree_skb(skb_to_free);
put_and_return:
if (refcounted)
sock_put(sk);
return ret;
no_tcp_socket:
if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb))
goto discard_it;
tcp_v4_fill_cb(skb, iph, th);
if (tcp_checksum_complete(skb)) {
csum_error:
__TCP_INC_STATS(net, TCP_MIB_CSUMERRORS);
bad_packet:
__TCP_INC_STATS(net, TCP_MIB_INERRS);
} else {
tcp_v4_send_reset(NULL, skb);
}
discard_it:
/* Discard frame. */
kfree_skb(skb);
return 0;
discard_and_relse:
sk_drops_add(sk, skb);
if (refcounted)
sock_put(sk);
goto discard_it;
do_time_wait:
if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) {
inet_twsk_put(inet_twsk(sk));
goto discard_it;
}
tcp_v4_fill_cb(skb, iph, th);
if (tcp_checksum_complete(skb)) {
inet_twsk_put(inet_twsk(sk));
goto csum_error;
}
switch (tcp_timewait_state_process(inet_twsk(sk), skb, th)) {
case TCP_TW_SYN: {
struct sock *sk2 = inet_lookup_listener(dev_net(skb->dev),
&tcp_hashinfo, skb,
__tcp_hdrlen(th),
iph->saddr, th->source,
iph->daddr, th->dest,
inet_iif(skb),
sdif);
if (sk2) {
inet_twsk_deschedule_put(inet_twsk(sk));
sk = sk2;
tcp_v4_restore_cb(skb);
refcounted = false;
goto process;
}
}
/* to ACK */
/* fall through */
case TCP_TW_ACK:
tcp_v4_timewait_ack(sk, skb);
break;
case TCP_TW_RST:
tcp_v4_send_reset(sk, skb);
inet_twsk_deschedule_put(inet_twsk(sk));
goto discard_it;
case TCP_TW_SUCCESS:;
}
goto discard_it;
}
2.2.3 调试验证√
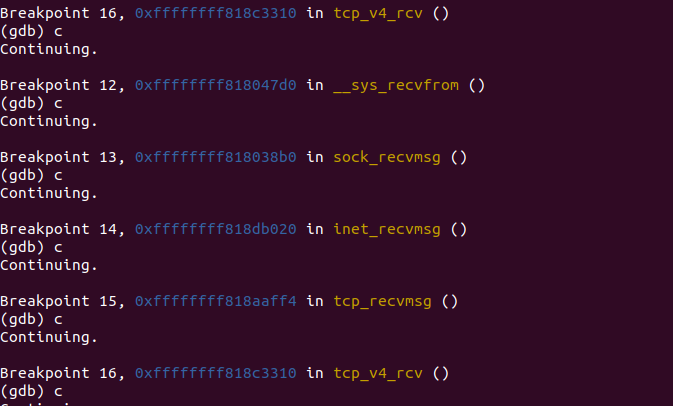
3.send和recv网络层流程
3.1 send在网络层的函数调用流程
3.1.1 ip_queue_xmit函数
ip_queue_xmit()在include/net/ip.h中
ip_queue_xmit函数直接调用__ip_queue_xmit()函数

__ip_queue_xmit()在net/ipv4/ip_output.c中
int __ip_queue_xmit(struct sock *sk, struct sk_buff *skb, struct flowi *fl,
__u8 tos)
{
struct inet_sock *inet = inet_sk(sk);
struct net *net = sock_net(sk);
struct ip_options_rcu *inet_opt;
struct flowi4 *fl4;
struct rtable *rt;
struct iphdr *iph;
int res;
/* Skip all of this if the packet is already routed,
* f.e. by something like SCTP.
*/
rcu_read_lock();
inet_opt = rcu_dereference(inet->inet_opt);
fl4 = &fl->u.ip4;
rt = skb_rtable(skb);
if (rt)
goto packet_routed;
/* Make sure we can route this packet. */
rt = (struct rtable *)__sk_dst_check(sk, 0);
if (!rt) {
__be32 daddr;
/* Use correct destination address if we have options. */
daddr = inet->inet_daddr;
if (inet_opt && inet_opt->opt.srr)
daddr = inet_opt->opt.faddr;
/* If this fails, retransmit mechanism of transport layer will
* keep trying until route appears or the connection times
* itself out.
*/
rt = ip_route_output_ports(net, fl4, sk,
daddr, inet->inet_saddr,
inet->inet_dport,
inet->inet_sport,
sk->sk_protocol,
RT_CONN_FLAGS_TOS(sk, tos),
sk->sk_bound_dev_if);
if (IS_ERR(rt))
goto no_route;
sk_setup_caps(sk, &rt->dst);
}
skb_dst_set_noref(skb, &rt->dst);
packet_routed:
if (inet_opt && inet_opt->opt.is_strictroute && rt->rt_uses_gateway)
goto no_route;
/* OK, we know where to send it, allocate and build IP header. */
skb_push(skb, sizeof(struct iphdr) + (inet_opt ? inet_opt->opt.optlen : 0));
skb_reset_network_header(skb);
iph = ip_hdr(skb);
*((__be16 *)iph) = htons((4 << 12) | (5 << 8) | (tos & 0xff));
if (ip_dont_fragment(sk, &rt->dst) && !skb->ignore_df)
iph->frag_off = htons(IP_DF);
else
iph->frag_off = 0;
iph->ttl = ip_select_ttl(inet, &rt->dst);
iph->protocol = sk->sk_protocol;
ip_copy_addrs(iph, fl4);
/* Transport layer set skb->h.foo itself. */
if (inet_opt && inet_opt->opt.optlen) {
iph->ihl += inet_opt->opt.optlen >> 2;
ip_options_build(skb, &inet_opt->opt, inet->inet_daddr, rt, 0);
}
ip_select_ident_segs(net, skb, sk,
skb_shinfo(skb)->gso_segs ?: 1);
/* TODO : should we use skb->sk here instead of sk ? */
skb->priority = sk->sk_priority;
skb->mark = sk->sk_mark;
res = ip_local_out(net, sk, skb);
rcu_read_unlock();
return res;
no_route:
rcu_read_unlock();
IP_INC_STATS(net, IPSTATS_MIB_OUTNOROUTES);
kfree_skb(skb);
return -EHOSTUNREACH;
}
上面函数功能可以总结为:
-
相关合法性检查;
-
防火墙过滤;
-
对数据包是否需要分片发送进行检查;
-
进行可能的数据包缓存处理;
-
对多播和广播数据报是否需要回送本机进行检查;
-
调用函数 ip_local_out() 进行处理。
上面函数内部涉及到一个函数,把数据包分片,当数据包大小大于最大传输单元时,需要将数据包分片传送,这里则是通过函数 ip_fragment 实现的。
3.1.2 ip_local_out函数
可以看出ip_local_out直接调用__ip_local_out函数

将要从本地发出的数据包,会在构造了ip头之后,调用ip_local_out函数,该函数设置数据包的总长度和校验和,然后经过netfilter的LOCAL_OUT钩子点进行检查过滤,如果通过,则调用dst_output函数,实际上调用的是ip数据包输出函数ip_output;
/include/net/dst.h

3.1.3 ip_output函数
/net/ipv4/ip_output.c
可以ip_output函数中执行了一个狗子程序,并调用了ip_finish_output()函数

3.1.4 ip_finish_output函数
net/ipv4/ip_output.c

从图中,可以看出,ip_finish_output()直接调用了__ip_finish_output()。而在ip_finish_output()中对skb进行分片判断,需要分片,则分片后输出,不需要分片则知直接输出;
3.1.5 ip_finish_output2函数
/net/ipv4/ip_output.c
对skb的头部空间进行检查,看是否能够容纳下二层头部,若空间不足,则需要重新申请skb;然后,获取邻居子系统,并通过邻居子系统输出;

在228行,调用neigh_otuput()邻居子系统进行输出
3.1.6 neigh_resolve_output函数
/include/net/neighbour.h

在第1487行,调用dev_queue_xmit()在数据链路层进行输出。
3.2 调试验证√
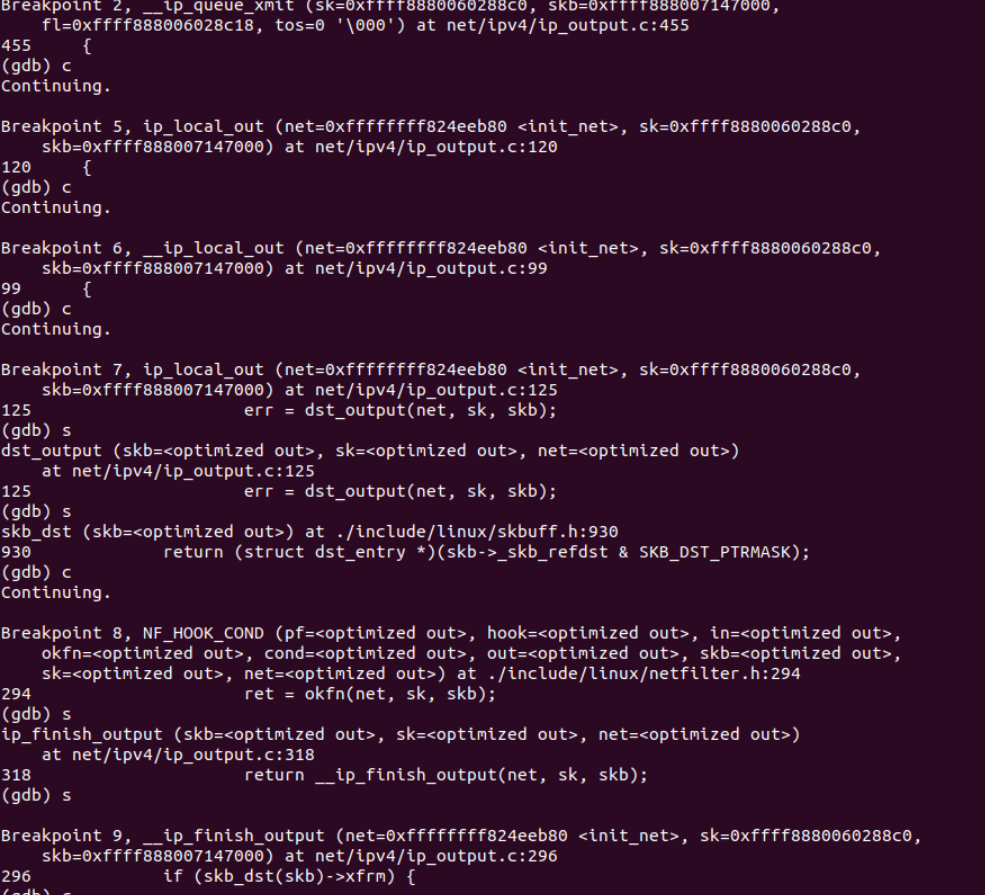

3.3 recv在网络层的函数调用流程
ip层收包流程概述:
-
在inet_init中注册了类型为ETH_P_IP协议的数据包的回调ip_rcv
-
当二层数据包接收完毕,会调用netif_receive_skb根据协议进行向上层分发
-
类型为ETH_P_IP类型的数据包,被传递到三层,调用ip_rcv函数
-
ip_rcv完成基本的校验和处理工作后,经过PRE_ROUTING钩子点
-
经过PRE_ROUTING钩子点之后,调用ip_rcv_finish完成数据包接收,包括选项处理,路由查询,并且根据路由决定数据包是发往本机还是转
3.2.1 ip_rcv函数
ip_rcv函数体内的流程详细见下面代码注释
/*
* Main IP Receive routine.
*/
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev)
{
const struct iphdr *iph;
struct net *net;
u32 len;
/* When the interface is in promisc. mode, drop all the crap
* that it receives, do not try to analyse it.
*/
/* 混杂模式下,非本机包 */
if (skb->pkt_type == PACKET_OTHERHOST)
goto drop;
/* 获取net */
net = dev_net(dev);
__IP_UPD_PO_STATS(net, IPSTATS_MIB_IN, skb->len);
/* 检查skb共享 */
skb = skb_share_check(skb, GFP_ATOMIC);
if (!skb) {
__IP_INC_STATS(net, IPSTATS_MIB_INDISCARDS);
goto out;
}
/* 测试是否可以取得ip头 */
if (!pskb_may_pull(skb, sizeof(struct iphdr)))
goto inhdr_error;
/* 取ip头 */
iph = ip_hdr(skb);
/*
* RFC1122: 3.2.1.2 MUST silently discard any IP frame that fails the checksum.
*
* Is the datagram acceptable?
*
* 1. Length at least the size of an ip header
* 2. Version of 4
* 3. Checksums correctly. [Speed optimisation for later, skip loopback checksums]
* 4. Doesn't have a bogus length
*/
/* 头部长度不足20 或者版本不是4 */
if (iph->ihl < 5 || iph->version != 4)
goto inhdr_error;
BUILD_BUG_ON(IPSTATS_MIB_ECT1PKTS != IPSTATS_MIB_NOECTPKTS + INET_ECN_ECT_1);
BUILD_BUG_ON(IPSTATS_MIB_ECT0PKTS != IPSTATS_MIB_NOECTPKTS + INET_ECN_ECT_0);
BUILD_BUG_ON(IPSTATS_MIB_CEPKTS != IPSTATS_MIB_NOECTPKTS + INET_ECN_CE);
__IP_ADD_STATS(net,
IPSTATS_MIB_NOECTPKTS + (iph->tos & INET_ECN_MASK),
max_t(unsigned short, 1, skb_shinfo(skb)->gso_segs));
/* 测试实际应取的ip头 */
if (!pskb_may_pull(skb, iph->ihl*4))
goto inhdr_error;
/* 取ip头 */
iph = ip_hdr(skb);
/* 校验和错误 */
if (unlikely(ip_fast_csum((u8 *)iph, iph->ihl)))
goto csum_error;
/* 取总长度 */
len = ntohs(iph->tot_len);
/* skb长度比ip包总长度小 */
if (skb->len < len) {
__IP_INC_STATS(net, IPSTATS_MIB_INTRUNCATEDPKTS);
goto drop;
}
/* 比头部长度还小 */
else if (len < (iph->ihl*4))
goto inhdr_error;
/* Our transport medium may have padded the buffer out. Now we know it
* is IP we can trim to the true length of the frame.
* Note this now means skb->len holds ntohs(iph->tot_len).
*/
/* 设置总长度为ip包的长度 */
if (pskb_trim_rcsum(skb, len)) {
__IP_INC_STATS(net, IPSTATS_MIB_INDISCARDS);
goto drop;
}
/* 取得传输层头部 */
skb->transport_header = skb->network_header + iph->ihl*4;
/* Remove any debris in the socket control block */
/* 重置cb */
memset(IPCB(skb), 0, sizeof(struct inet_skb_parm));
/* 保存输入设备信息 */
IPCB(skb)->iif = skb->skb_iif;
/* Must drop socket now because of tproxy. */
skb_orphan(skb);
/* 经过PRE_ROUTING钩子点 */
return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING,
net, NULL, skb, dev, NULL,
ip_rcv_finish);
csum_error:
__IP_INC_STATS(net, IPSTATS_MIB_CSUMERRORS);
inhdr_error:
__IP_INC_STATS(net, IPSTATS_MIB_INHDRERRORS);
drop:
kfree_skb(skb);
out:
return NET_RX_DROP;
}
3.2.2 ip_rcv_finish函数
作用:
1)、确定数据包是转发还是在本机协议栈上传,如果是转发要确定输出网络设备和下一个接受栈的地址。
2)、解析和处理部分IP选项。
static int ip_rcv_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
const struct iphdr *iph = ip_hdr(skb);
struct rtable *rt;
struct net_device *dev = skb->dev;
void (*edemux)(struct sk_buff *skb);
/* if ingress device is enslaved to an L3 master device pass the
* skb to its handler for processing
*/
skb = l3mdev_ip_rcv(skb);
if (!skb)
return NET_RX_SUCCESS;
/*
启用了early_demux
skb路由缓存为空
skb的sock为空
不是分片包
*/
if (net->ipv4.sysctl_ip_early_demux &&
!skb_dst(skb) &&
!skb->sk &&
!ip_is_fragment(iph)) {
const struct net_protocol *ipprot;
/* 找到上层协议 */
int protocol = iph->protocol;
/* 获取协议对应的prot */
ipprot = rcu_dereference(inet_protos[protocol]);
/* 找到early_demux函数,如tcp_v4_early_demux */
if (ipprot && (edemux = READ_ONCE(ipprot->early_demux))) {
/* 调用该函数,将路由信息缓存到skb->refdst */
edemux(skb);
/* must reload iph, skb->head might have changed */
/* 重新取ip头 */
iph = ip_hdr(skb);
}
}
/*
* Initialise the virtual path cache for the packet. It describes
* how the packet travels inside Linux networking.
*/
/* 校验路由失败 */
if (!skb_valid_dst(skb)) {
/* 查路由 */
int err = ip_route_input_noref(skb, iph->daddr, iph->saddr,
iph->tos, dev);
if (unlikely(err)) {
if (err == -EXDEV)
__NET_INC_STATS(net, LINUX_MIB_IPRPFILTER);
goto drop;
}
}
#ifdef CONFIG_IP_ROUTE_CLASSID
if (unlikely(skb_dst(skb)->tclassid)) {
struct ip_rt_acct *st = this_cpu_ptr(ip_rt_acct);
u32 idx = skb_dst(skb)->tclassid;
st[idx&0xFF].o_packets++;
st[idx&0xFF].o_bytes += skb->len;
st[(idx>>16)&0xFF].i_packets++;
st[(idx>>16)&0xFF].i_bytes += skb->len;
}
#endif
/* 处理ip选项 */
if (iph->ihl > 5 && ip_rcv_options(skb))
goto drop;
/* 找到路由缓存项 */
rt = skb_rtable(skb);
if (rt->rt_type == RTN_MULTICAST) {
__IP_UPD_PO_STATS(net, IPSTATS_MIB_INMCAST, skb->len);
} else if (rt->rt_type == RTN_BROADCAST) {
__IP_UPD_PO_STATS(net, IPSTATS_MIB_INBCAST, skb->len);
} else if (skb->pkt_type == PACKET_BROADCAST ||
skb->pkt_type == PACKET_MULTICAST) {
struct in_device *in_dev = __in_dev_get_rcu(dev);
/* RFC 1122 3.3.6:
*
* When a host sends a datagram to a link-layer broadcast
* address, the IP destination address MUST be a legal IP
* broadcast or IP multicast address.
*
* A host SHOULD silently discard a datagram that is received
* via a link-layer broadcast (see Section 2.4) but does not
* specify an IP multicast or broadcast destination address.
*
* This doesn't explicitly say L2 *broadcast*, but broadcast is
* in a way a form of multicast and the most common use case for
* this is 802.11 protecting against cross-station spoofing (the
* so-called "hole-196" attack) so do it for both.
*/
if (in_dev &&
IN_DEV_ORCONF(in_dev, DROP_UNICAST_IN_L2_MULTICAST))
goto drop;
}
/* 调用路由项的input函数,可能为ip_local_deliver或者ip_forward */
return dst_input(skb);
drop:
kfree_skb(skb);
return NET_RX_DROP;
}
3.2.3 ip_local_deliver函数
net/ipv4/ip_input.c
在ip_local_deliver()中,如果发现数据报有被分片,则进行组装。然后调用NF_INET_LOCAL_IN处的钩子函数,如果数据包被钩子函数放行,则调用ip_local_deliver_finish()继续处理。

3.2.4 ip_local_deliver_finish函数
ip_local_deliver_finish()主要做了:
- 处理RAW IP,如果有配置安全策略,则进行IPsec安全检查。
- 根据IP报头的protocol字段,找到对应的L4协议(net_protocol),调用该协议的接收函数net_protocol->handler()。
- 对于TCP协议,net_protocol实例为tcp_protocol,协议处理函数为tcp_v4_rcv()。
接下来就进入四层协议的处理流程了,TCP协议的入口函数为tcp_v4_rcv()。
static int ip_local_deliver_finish(struct sk_buff *skb)
{
struct net *net = dev_net(skb->dev);
/* 把skb->data指向L4协议头,更新skb->len */
__skb_pull(skb, ip_hdrlen(skb));
/* 赋值skb->transport_header */
skb_reset_transport_header(skb);
rcu_read_lock();
{
int protocol = ip_hdr(skb)->protocol; /* L4协议号 */
int hash, raw;
const struct net_protocol *ipprot;
resubmit:
/* 处理RAW IP */
raw = raw_local_deliver(skb, protocol);
hash = protocol & (MAX_INET_PROTOS - 1); /* 作为数组索引 */
/* 从inet_protos数组中取出对应的net_protocol元素,TCP的为tcp_protocol */
ipprot = rcu_dereference(inet_protos[hash]);
if (ipprot != NULL) {
int ret;
if (! net_eq(net, &init_net) && ! ipprot->netns_ok) {
if (net_ratelimit())
printk("%s: proto %d isn't netns-ready\n", __func__, protocol);
kfree_skb(skb);
goto out;
}
/* 如果需要检查IPsec安全策略 */
if (! ipprot->no_policy) {
if (! xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) {
kfree_skb(skb);
goto out;
}
nf_reset(skb);
}
/* 调用L4协议的处理函数,对于TCP,调用tcp_protocol->handler,为tcp_v4_rcv() */
ret = ipprot->handler(skb);
if (ret < 0) {
protocol = - ret;
goto resubmit;
}
IP_INC_STATS_BH(net, IPSTATS_MIB_INDELIVERS);
} else {
if (! raw) {
if (xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) {
IP_INC_STATS_BH(net, IPSTATS_MIB_INUNKNOWNPROTOS);
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_PROT_UNREACH, 0);
} else
IP_INC_STATS_BH(net, IPSTATS_MIB_INDELIVERS);
kfree_skb(skb);
}
}
out:
rcu_read_unlock();
return 0;
}
3.4 调试验证√

4.send和recv链路层和物理层流程
4.1 send在数据链路层和物理层的函数调用流程
4.1.1 dev_queue_xmit函数
/net/core/dev.c

可以看出,dev_queue_xmit直接调用__dev_queue_xmit()函数
下面是__dev_queue_xmit()函数的函数体
将缓冲区排队以传输到网络设备。发送者必须在调用之前已经设置了设备和优先级并建立了缓冲区
此功能。可以从中断中调用该函数。失败时返回否定的errno代码。成功不会保证帧将被发送,因为它可能由于丢失导致交通拥堵或流量整形。
static int __dev_queue_xmit(struct sk_buff *skb, struct net_device *sb_dev)
{
struct net_device *dev = skb->dev;
struct netdev_queue *txq;
struct Qdisc *q;
int rc = -ENOMEM;
bool again = false;
skb_reset_mac_header(skb);
if (unlikely(skb_shinfo(skb)->tx_flags & SKBTX_SCHED_TSTAMP))
__skb_tstamp_tx(skb, NULL, skb->sk, SCM_TSTAMP_SCHED);
/* Disable soft irqs for various locks below. Also
* stops preemption for RCU.
*/
rcu_read_lock_bh();
skb_update_prio(skb);
qdisc_pkt_len_init(skb);
#ifdef CONFIG_NET_CLS_ACT
skb->tc_at_ingress = 0;
# ifdef CONFIG_NET_EGRESS
if (static_branch_unlikely(&egress_needed_key)) {
skb = sch_handle_egress(skb, &rc, dev);
if (!skb)
goto out;
}
# endif
#endif
/* If device/qdisc don't need skb->dst, release it right now while
* its hot in this cpu cache.
*/
if (dev->priv_flags & IFF_XMIT_DST_RELEASE)
skb_dst_drop(skb);
else
skb_dst_force(skb);
txq = netdev_core_pick_tx(dev, skb, sb_dev);
q = rcu_dereference_bh(txq->qdisc);
trace_net_dev_queue(skb);
if (q->enqueue) {
rc = __dev_xmit_skb(skb, q, dev, txq);
goto out;
}
/* The device has no queue. Common case for software devices:
* loopback, all the sorts of tunnels...
* Really, it is unlikely that netif_tx_lock protection is necessary
* here. (f.e. loopback and IP tunnels are clean ignoring statistics
* counters.)
* However, it is possible, that they rely on protection
* made by us here.
* Check this and shot the lock. It is not prone from deadlocks.
*Either shot noqueue qdisc, it is even simpler 8)
*/
if (dev->flags & IFF_UP) {
int cpu = smp_processor_id(); /* ok because BHs are off */
if (txq->xmit_lock_owner != cpu) {
if (dev_xmit_recursion())
goto recursion_alert;
skb = validate_xmit_skb(skb, dev, &again);
if (!skb)
goto out;
HARD_TX_LOCK(dev, txq, cpu);
if (!netif_xmit_stopped(txq)) {
dev_xmit_recursion_inc();
skb = dev_hard_start_xmit(skb, dev, txq, &rc);
dev_xmit_recursion_dec();
if (dev_xmit_complete(rc)) {
HARD_TX_UNLOCK(dev, txq);
goto out;
}
}
HARD_TX_UNLOCK(dev, txq);
net_crit_ratelimited("Virtual device %s asks to queue packet!\n",
dev->name);
} else {
/* Recursion is detected! It is possible,
* unfortunately
*/
recursion_alert:
net_crit_ratelimited("Dead loop on virtual device %s, fix it urgently!\n",
dev->name);
}
}
rc = -ENETDOWN;
rcu_read_unlock_bh();
atomic_long_inc(&dev->tx_dropped);
kfree_skb_list(skb);
return rc;
out:
rcu_read_unlock_bh();
return rc;
}
从对_dev_queue_xmit函数的分析来看,发送报文有2中情况:
1.有拥塞控制策略的情况,比较复杂,但是目前最常用
2.没有enqueue的状况,比较简单,直接发送到driver,如loopback等使用
先检查是否有enqueue的规则,如果有即调用__dev_xmit_skb进入拥塞控制的flow,如果没有且txq处于On的状态,那么就调用dev_hard_start_xmit直接发送到driver,好 那先分析带Qdisc策略的flow 进入__dev_xmit_skb
4.1.2 dev_xmit_skb函数
static inline int __dev_xmit_skb(struct sk_buff *skb, struct Qdisc *q,
struct net_device *dev,
struct netdev_queue *txq)
{
spinlock_t *root_lock = qdisc_lock(q);
struct sk_buff *to_free = NULL;
bool contended;
int rc;
qdisc_calculate_pkt_len(skb, q);
if (q->flags & TCQ_F_NOLOCK) {
rc = q->enqueue(skb, q, &to_free) & NET_XMIT_MASK;
qdisc_run(q);
if (unlikely(to_free))
kfree_skb_list(to_free);
return rc;
}
/*
* Heuristic to force contended enqueues to serialize on a
* separate lock before trying to get qdisc main lock.
* This permits qdisc->running owner to get the lock more
* often and dequeue packets faster.
*/
contended = qdisc_is_running(q);
if (unlikely(contended))
spin_lock(&q->busylock);
spin_lock(root_lock);
if (unlikely(test_bit(__QDISC_STATE_DEACTIVATED, &q->state))) {
__qdisc_drop(skb, &to_free);
rc = NET_XMIT_DROP;
} else if ((q->flags & TCQ_F_CAN_BYPASS) && !qdisc_qlen(q) &&
qdisc_run_begin(q)) {
/*
* This is a work-conserving queue; there are no old skbs
* waiting to be sent out; and the qdisc is not running -
* xmit the skb directly.
*/
qdisc_bstats_update(q, skb);
if (sch_direct_xmit(skb, q, dev, txq, root_lock, true)) {
if (unlikely(contended)) {
spin_unlock(&q->busylock);
contended = false;
}
__qdisc_run(q);
}
qdisc_run_end(q);
rc = NET_XMIT_SUCCESS;
} else {
rc = q->enqueue(skb, q, &to_free) & NET_XMIT_MASK;
if (qdisc_run_begin(q)) {
if (unlikely(contended)) {
spin_unlock(&q->busylock);
contended = false;
}
__qdisc_run(q);
qdisc_run_end(q);
}
}
spin_unlock(root_lock);
if (unlikely(to_free))
kfree_skb_list(to_free);
if (unlikely(contended))
spin_unlock(&q->busylock);
return rc;
}
从上述分析来看,可以分成2个状况:
- Qdisc满足上述3个条件,置位TCQ_F_CAN_BYPASS,0个包,没有running直接调用sch_direct_xmit,感觉这种状况,是一开始刚发第一个包的时候肯定是这种状况...
- 不满足上述的3个条件 一个或者多个,那就直接进行enqueue操作,然后运行qdisc
个人认为,第一种状况是在网络通畅的状况下遇到的状况,qdisc的队列基本上处于空的状态,都是直接传送给driver了,第二种情况是属于出现网络拥塞的情况,出现发送失败的状况了
Q里面还有一些待发送的数据包,为了保证Q中的数据按照Qdisc的规则发送,比如先进先出,就需要enqueue操作,然后再去dequeue发送出去!
4.1.3 sch_dirct_xmit函数
下面来分析sch_direct_xmit,这个函数可能传输几个数据包,因为在不经过queue状况下和经过queue的状况下都会调通过这个函数发送,如果是queue状况,肯定是能够传输多个数据包了,本文后面也有分析,并按照需求处理return的状态,需要拿着__QDISC___STATE_RUNNING bit,只有一个CPU 可以执行这个函数, 在这里有可能会出现BUSY的状况!
int sch_direct_xmit(struct sk_buff *skb, struct Qdisc *q,
struct net_device *dev, struct netdev_queue *txq,
spinlock_t *root_lock, bool validate)
{
int ret = NETDEV_TX_BUSY;
/* And release qdisc */
spin_unlock(root_lock);
/* Note that we validate skb (GSO, checksum, ...) outside of locks */
if (validate)
skb = validate_xmit_skb_list(skb, dev);
if (likely(skb)) {
HARD_TX_LOCK(dev, txq, smp_processor_id());
/*如果说txq被stop,即置位QUEUE_STATE_ANY_XOFF_OR_FROZEN,就直接ret = NETDEV_TX_BUSY
*如果说txq 正常运行,那么直接调用dev_hard_start_xmit发送数据包*/
if (!netif_xmit_frozen_or_stopped(txq))
skb = dev_hard_start_xmit(skb, dev, txq, &ret);
HARD_TX_UNLOCK(dev, txq);
} else {
spin_lock(root_lock);
return qdisc_qlen(q);
}
spin_lock(root_lock);
/*进行返回值处理! 如果ret < NET_XMIT_MASK 为true 否则 flase*/
if (dev_xmit_complete(ret)) {
/* Driver sent out skb successfully or skb was consumed */
/*这个地方需要注意可能有driver的负数的case,也意味着这个skb被drop了*/
ret = qdisc_qlen(q);
} else if (ret == NETDEV_TX_LOCKED) {
/* Driver try lock failed */
ret = handle_dev_cpu_collision(skb, txq, q);
} else {
/* Driver returned NETDEV_TX_BUSY - requeue skb */
if (unlikely(ret != NETDEV_TX_BUSY))
net_warn_ratelimited("BUG %s code %d qlen %d\n",
dev->name, ret, q->q.qlen);
/*发生Tx Busy的时候,重新进行requeue*/
ret = dev_requeue_skb(skb, q);
}
/*如果txq stop并且ret !=0 说明已经无法发送数据包了ret = 0*/
if (ret && netif_xmit_frozen_or_stopped(txq))
ret = 0;
return ret;
}
4.1.4 dev_hard_start_xmit函数
继续看dev_hard_start_xmit,这个函数比较简单,调用xmit_one来发送一个到多个数据包了
4.1.5 xmit_one函数
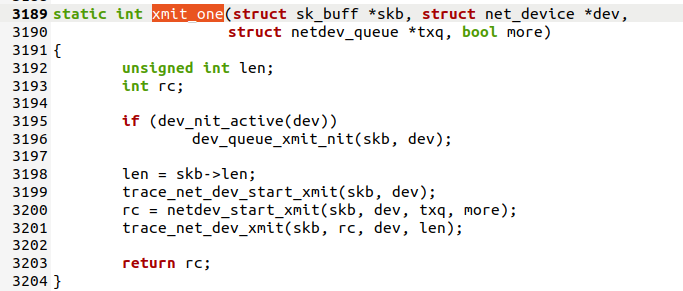
主要是在3200行调用了netdev_start_xmit
4.1.6 netdev_start_xmit函数
netdev_start_xmit,__netdev_start_xmit 再加上xmit_one()这个三个函数,其目的就是将封包送到driver的tx函数了.. 中间在送往driver之前,还会经历抓包的过程,本文不介绍抓包的流程了。
static inline netdev_tx_t netdev_start_xmit(struct sk_buff *skb, struct net_device *dev,
struct netdev_queue *txq, bool more)
{
const struct net_device_ops *ops = dev->netdev_ops;
int rc;
/*__netdev_start_xmit 里面就完全是使用driver 的ops去发包了,其实到此为止,一个skb已经从netdevice
*这个层面送到driver层了,接下来会等待driver的返回*/
rc = __netdev_start_xmit(ops, skb, dev, more);
/*如果返回NETDEV_TX_OK,那么会更新下Txq的trans时间戳哦,txq->trans_start = jiffies;*/
if (rc == NETDEV_TX_OK)
txq_trans_update(txq);
return rc;
}
static inline netdev_tx_t __netdev_start_xmit(const struct net_device_ops *ops,
struct sk_buff *skb, struct net_device *dev,
bool more)
{
skb->xmit_more = more ? 1 : 0;
return ops->ndo_start_xmit(skb, dev);
}
4.2 调试验证√
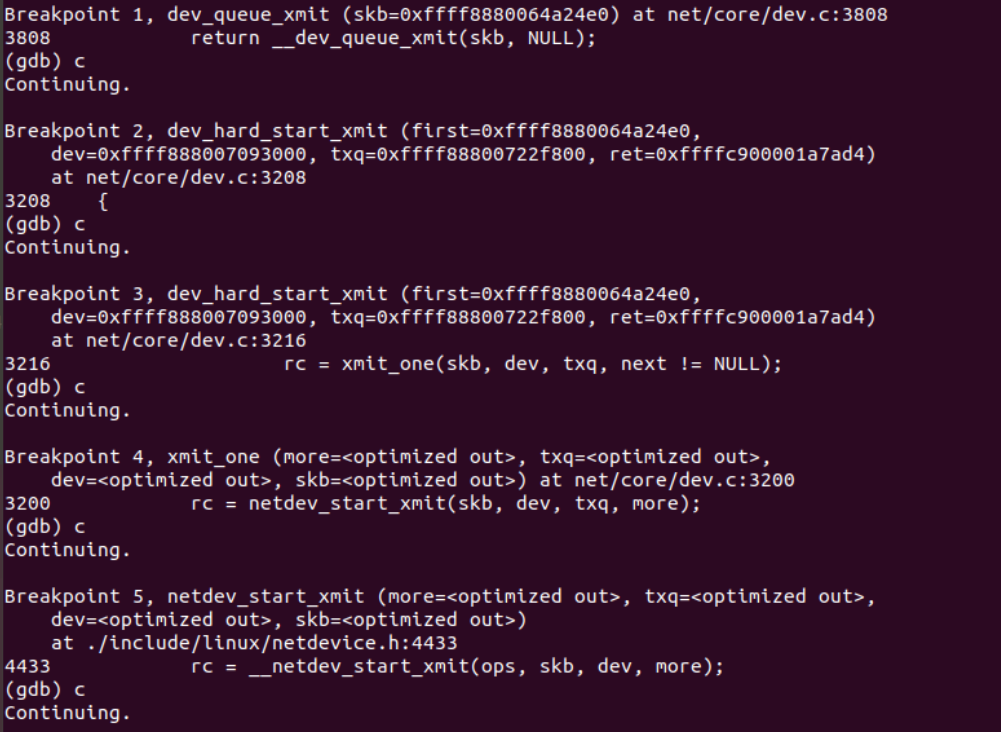
4.3 recv在数据链路层和物理层的函数调用流程
4.2.1 netif_rx函数
/net/core/dev.c, line 4434
netif_rx()是内核接收网络数据包的入口。
netif_rx()主要调用enqueue_to_backlog()进行后续处理。

netif_rx函数主要调用了netif_rx_internal函数,netif_rx_internal函数定义如下
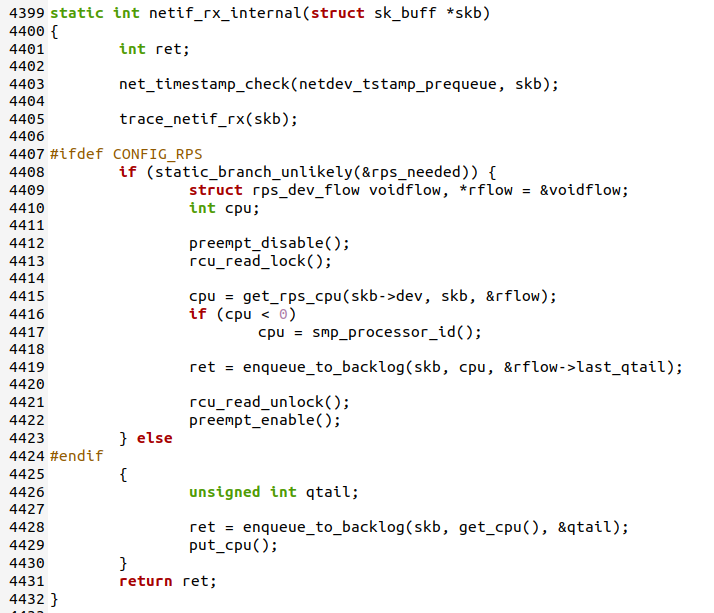
netif_rx_internal主要调用enqueue_to_backlog()进行后续处理。
4.2.2 enqueue_to_backlog函数
netif_rx()调用enqueue_to_backlog()来处理。
首先获取当前cpu的softnet_data实例sd,然后:
-
如果接收队列sd->input_pkt_queue不为空,说明已经有软中断在处理数据包了,
则不需要再次触发软中断,直接将数据包添加到接收队列尾部即可。
-
如果接收队列sd->input_pkt_queue为空,说明当前没有软中断在处理数据包,
则把虚拟设备backlog添加到sd->poll_list中以便进行轮询,最后设置NET_RX_SOFTIRQ
标志触发软中断。
-
如果接收队列sd->input_pkt_queue满了,则直接丢弃数据包
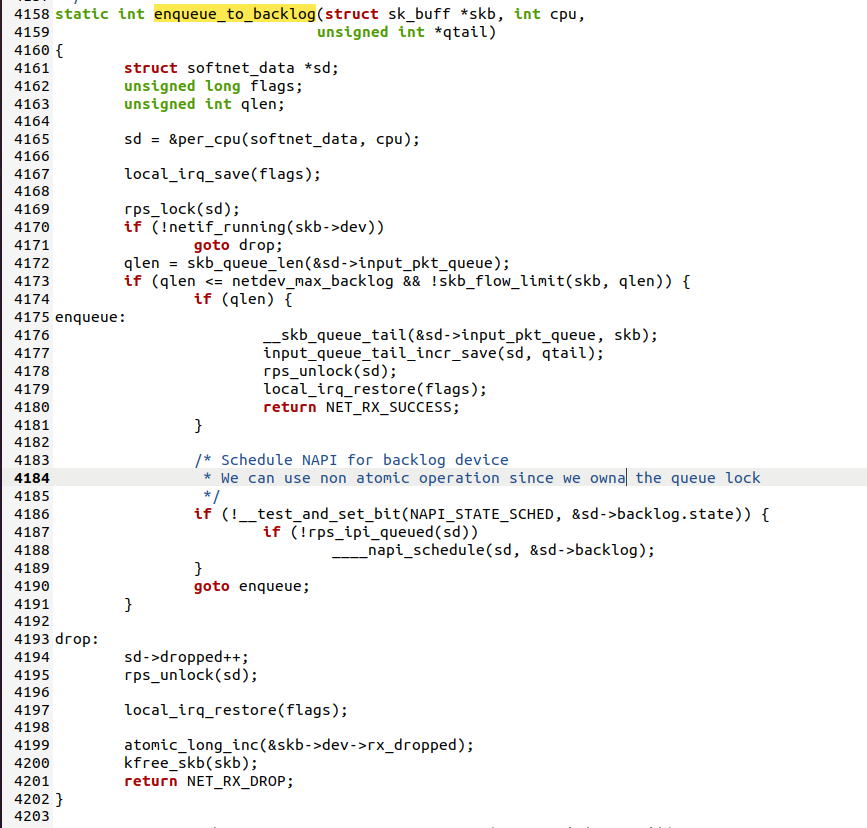
4.4 调试验证√
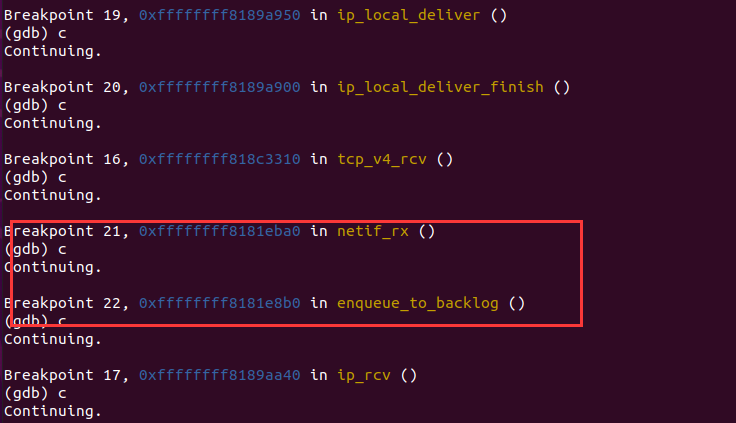
5.时序图


 浙公网安备 33010602011771号
浙公网安备 33010602011771号