
使用readlines()读取文件时出现/n及其解决办法
想要实现将文件中的数据全部读取并存入一个列表的功能,文件内容如下,打算使用readlines()进行操作。
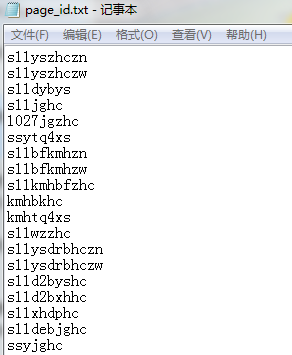
初始代码:
1 f = open('page_id.txt', 'r', encoding='UTF-8') 2 lines = f.readlines()
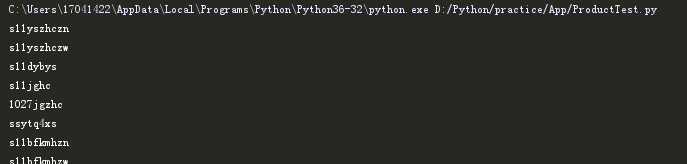
在使用readlines()函数来读取文件的时候,得到的结果却是带换行符\n的:

那么只能手动将列表中的\n消除掉。这边总结两个方案:
方案一:
f = open('page_id.txt', 'r', encoding='UTF-8') lines = f.readlines()for i in range(0,len(lines)-1): lines[i] = lines[i].strip('\n') print(lines)
使用for循环将列表中每个元素中的\n都删掉,这里用到了strip()函数。用法贴在后面。
方案二:
f = open('page_id.txt', 'r', encoding='UTF-8') lines = f.readlines() l_length = len(lines) lines = ''.join(lines) #将列表类型转换为字符转类型 lines.strip('\n') #strip函数可以将字符串 lines = lines.split('\n') #将去掉\n之后的字符串再次转换为列表,分隔符为换行\n print(lines)
这里经过了两步转换。
因为strip()函数只能对字符串进行操作,因此需要先将列表转为字符串;在经过strip()函数操作之后,再将其用split()转为列表。
在经过第一步转换并使用strip()之后,得到的字符串如下,因此在转列表的时候考虑以\n为分隔符进行split()操作。
两个方法转换完成之后的结果即我们想要的列表:

附strip函数用法:
函数原型
声明:s为字符串,rm为要删除的字符序列
s.strip(rm) 删除s字符串中开头、结尾处,位于 rm删除序列的字符
s.lstrip(rm) 删除s字符串中开头处,位于 rm删除序列的字符
s.rstrip(rm) 删除s字符串中结尾处,位于 rm删除序列的字符
注意:
当rm为空时,默认删除空白符(包括'\n', '\r', '\t', ' ')
最懒的人就是整天忙得没时间学习、反思、成长的人。

