


关于storm程序性能压测记录及总结
STORM性能压测步骤记录及总结
压测前的准备
1.明确压测计划和方案。
(1).首先确定本次压测的目的是什么。
(2).例如是验证目标工程是否能够达到预定的性能指标,还是需要通过调整压测资源的分配,经过多次压测比对结果,发现性能瓶颈的所在。
(3).压测指标一般来说是根据往年同时段或者最近一次大促峰值的数据量按照一定比例增加后评估得出的。
可能会影响性能几个因素:
a. 机器数、
b. worker数、
c. 执行器数(这里体现为worker数和执行器的配比)、
d. 接收topic的partition数
e. 程序代码内部的逻辑复杂度
压测指标
a. CUP使用情况;
b. 内存使用情况;
c. 最大瞬间处理峰值TPS;
d. 持续峰值TPS(能够持续三分钟以上的最大值);
e. 平均TPS;
f. spout数据下发到每个partition是否均匀;
g. 网络IO;
2. 准备好压测所需要的数据。
(1)一般来说需要根据压测指标的tps来准备相应数量的数据,尽量保证灌入的数据可以持续处理10分钟以上,时间太短的话不足以保证数据处理的稳定性。
(2)确定数据是否可以重复灌入。由于可能需要进行多次压测,或者压测数据不够的时候,首先要确定可否重复使用数据,比如需要将第一次接收的数据存入redis或者hbase表中,后面存在去重或者其他重复数据处理逻辑,那么使用重复数据就会对压测结果造成影响。
3.提前报备
进行压测之前先在群中知会一下,以免有其他人同时在进行别的操作而对压测结果造成影响。
4. 对压测拓扑对象进行分析。
a.确定拓扑中有多少spout和bolt,搞清楚它们之间的联系和处理逻辑,确定有多少种日志需要进行压测,单场景还是混合场景。
b.对于涉及到数据写入redis、hbase、hive等,如果存在去重或者其他重复数据处理逻辑,需要在压测前将其进行清空处理。
5.提前打开对应服务器上cpu等监控界面
查看cpu和内存: /nmon下 ./nmon_x86_64_centos6
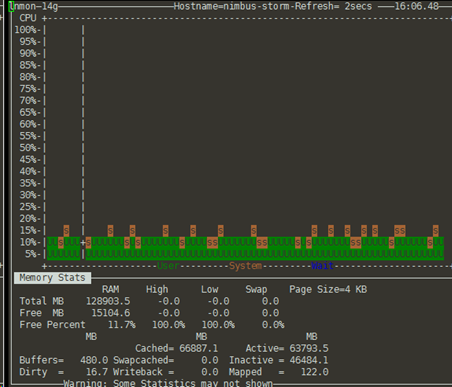
如果有专门的监控页面或工具(如zabbix等)则会更加便捷,能够一站式的监控多项指标。
压测步骤
第一步:向kafka灌入数据
注:发送数据之前一定要保证storm UI上的对应拓扑已经杀死或者是Deactive状态,否则数据发送之后会马上被消费掉,无法堆积到大量的数据达到压测效果。
直接在服务器上向kafka发送数据
此方法需要先将事先准备好的压测数据上传至服务器上,使用linux命令进行数据发送。
注:此方法可能出现灌入数据在分区上分布不均匀的情况,酌情使用。
cat /data/testdata/10033593/kafkadata/storm-expose-access/10.246.4* | /home/storm/software/kafka/bin/kafka-console-producer.sh --broker-list "broker地址" --topic storm_expose_access
第二步:启动拓扑并记录监控数据
当灌入数据达到预期达到之前预估的量的时候(保证灌入的数据可以持续处理10分钟以上),就可以开始进行压测了。
- 使用拓扑启动命令启动拓扑。
- 打开storm UI界面,进行数据记录。
- 如果配置有监控界面,可直接采用读取监控页面的数据来进行指标检测和记录。
由于拓扑内部进程完全启动需要一定的时间,因此在前几十秒中,是不进行数据处理的。因此最好从1min后再开始进行记录。
- Cpu监控
待cpu稳定后,观察cpu利用率是否在正常范围内,一般是75%以下。
- 查看拓扑进程分布
由于当拓扑分配多个worker的时候,拓扑进程可能随机分布到storm UI上面的几个服务器上,因此需要确定哪几台。
(1) 到storm UI上面查看集群所在的服务器
(2) 分别到这几台服务器上查看目标拓扑的进程号,查询不到时表示目标拓扑在该服务器上没有分配进程
查询命令: jps –m (或jps –m | grep 拓扑名)
下图中24922 即为dfp_sa_log在该台服务器上的进程号(一台服务器上可以有多个)

- 查看内存FullGC次数
根据年老代分区的内存变化情况判断JVM是否进行FullGC,记录内存在监控时间段内的FullGC次数。
应该尽可能减少Full GC的次数。在对JVM调优的过程中,很大一部分工作就是对于FullGC的调节
根据上面的方法得到的目标拓扑的进程号,可以查看该进程在当前服务器上的FullGC次数。
查询命令:jstat -gcutil +进程号

第三步:根据监控数据进行分析调整
1. Tps
选择两个时间点记录的数据量,取差值除以时间差,可得出tps。尽量选取时间间隔较长的进行计算,这样得出的结果属于系统稳定之后的数据,一般比较接近真实情况。
(1)当计算得出的tps跟预期指标相差不大时,说明当前系统可以满足性能要求。将压测过程中的数据记录下来整理成文档即可。
(2)当监控到的tps与预期指标相差甚远的时候,就需要对压测过程中可能造成tps上不去的原因进行定位分析了。
i.查看压测过程中拓扑中各个spout和bolt对应的capacity值,如果非常接近于1,或者已经超过1,则说明该spout/bolt已经达到处理极限。此时可对其分配几个excutor再压压看
ii. Spout的执行器数太少。当spout分配的执行器数小于topic分区数的时候,可能会造成接收到的数据不能及时下发给处理单元,造成tps过低,可以增加执行器数(excutor)数等于分区数在进行观察
iii.Topic分区影响,当tps相对于压测指标过低,同时各个bolt的capacity值都没有达到处理极限时,可能是topic分区较少从而入口接收数据的能力达不到造成的。可建议后期增加topic的分区数。
iv. Redis读取/写入影响,如果逻辑中存在redis读取或者写入操作的时候,可能也会对tps造成影响
v.逻辑太重导致,如关联mysql维表或者hbase
vi.外部rsf接口影响
2. Cpu
待cpu稳定后,观察cpu利用率,如果在75%以下则表示正常
如果CPU利用率过高,可以使用top命令查看当前占用率较高的是哪些进程,具体想要分析出cpu高的问题还需要其他手段。
3. 内存FullGC
如果内存FullGC过于频繁,则说明该拓扑处理过程中内存消耗过大,短时间内就需要清空一下内存,需要进行优化;或者也可能跟应用的逻辑和分配的资源有关。
通过jmap dump了jvm的堆内存,用visualvm查看dump出来的文件,进行进一步的分析调优。
一般来说,测试环境与实际生产环境上的资源配置相差较大,因此我们在测试环境上得出的结果一般与生产还是有一定差异。这可能就需要我们通过按照一定的比例调整测试环境上的配置资源数,分别得出分配不同资源时的结果,然后再根据这些结果进行线性估算得出在生产上可能需要的资源数,压测结果可供调整生产环境时进行参考。

