
isv大规模数据迁移和加密
公司的核心业务合作伙伴淘宝网,最近出现泄漏用户信息的现象,找了好久找不到根源,于是乎,淘宝那边决定对所有敏感数据进行加密,从出口和入口都走密文,于是乎,我们的工作量就来了。
我们的一个底单数据库,存储了大量淘宝卖家和买家的订单打印,申请单号,发货,回收单号等等操作的日志,大概有10亿左右数据(自动删除2个月之前的数据),哎呦我的fuck啊,也就是说,我们这边要对10亿数据做加密处理。。。。。。。。。
很荣幸,整个数据的操作过程由我来写工具,其中的考虑和过程,我来这里大致的记录一下,以便留下深的记忆。
好吧,先上一张我们用户与底单库的数据架构图。
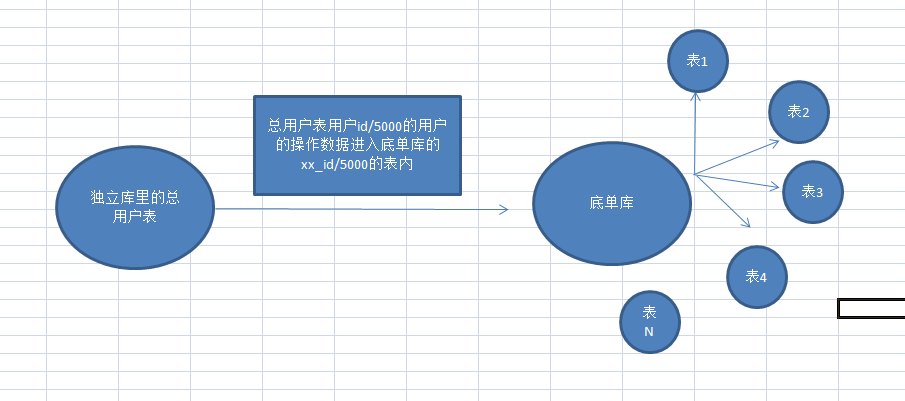
图上,我大致说一下,我们这一个独立库存储用户的独立信息,有一张总用户表,用户id/5000取int值,也就是5000个用户的底单数据插入到底单库中对应的一张表中。
底单库的服务器是阿里聚石塔最高级别的专用数据库服务器,容量2T,由于表的字段很多,数据占用磁盘空间的限制,我们保存用户2个月的数据,勉强维持2T的数据容量,但是,表中的例如用户手机,收件人,买家旺旺等字段需要加密,加密都是走阿里提供的加密解密接口方式,本来一个字段就20个字符最多,加密后就要200以内字符,这样不用全部加密硬盘空间就没了,经过讨论,确定方案是,加数据库,增加两台新的底单库,存储逻辑下图:
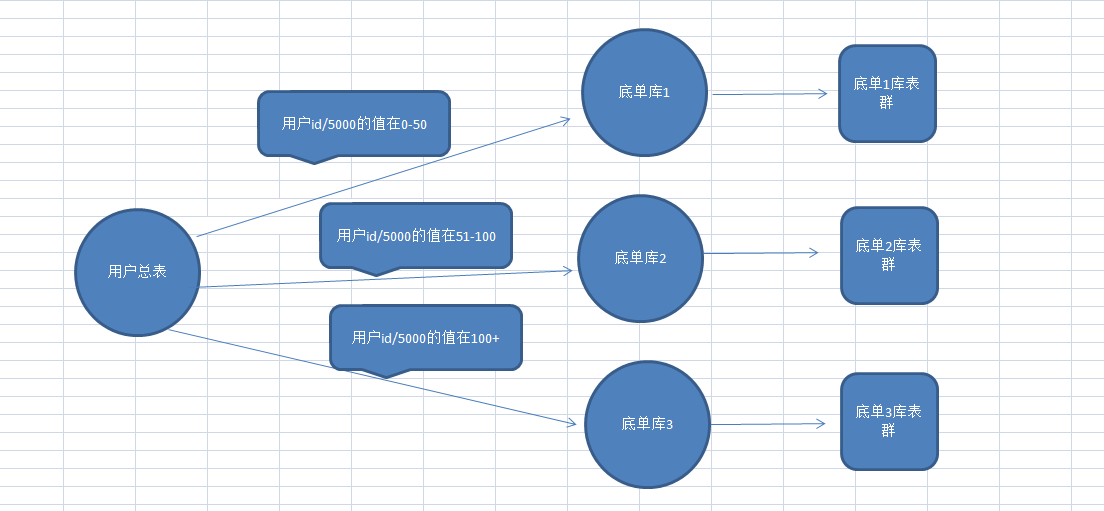
上图显示,加了新库,所以,在加密之前,首先要迁移用户数据。
要把底单1库(老库)中的51-100的表数据迁移到底单2库,101以上的表数据迁移到底单3库。为了保存老数据,底单2和3库新建的表要分别是51-100,101+,这里注意一点,新库的新表的起始自增id千万不要从0开始,因为,当你开始迁移数据的时候,对应的应用服务器一定会更新程序,这时候51表以上的用户的数据不会再往老库插,而是对应的入到新库里面,由于要把老库数据迁移过来,如果自增id从0开始,就会导致新数据的id和老数据的id产生唯一约束冲突。所以,看了下所有的旧表数据最大自增id,最多的在8000多W,所以,再程序上线前,我们给新表的自增id设置成1亿,来防止这个问题出现。
最后落实的迁移数据方案:由于数据比较多,就算每天半夜12点以后大规模迁移,也不现实,应用服务器不可能同时更新,所以最后决定细水长流模式,以业务服务器和用户为外循环,来操作迁移,每台业务服务器的用户的用户不规律的操作日志数据存在不同的底单库表中,也就是说一个老底单库的51-148(我们老底单库分表分了148张)的表中可能都会有当前服务器用户的数据,我以每个表启动一个线程来分别跑当前表的用户数据,,写的是每个业务服务器,固定开98个线程,去跑不同的底单表用户数据,跑了几台服务器后,发现个严重问题,由于每用户可跑的线程,也会循环查一次独立库的服务器,开2台服务器同时跑数据,就会造成独立库服务器的CPU飙升到100%,计算加上各种延迟,也不可避免,还影响效率。所以,最后在当前业务服务器的站点启动的时候,计算当前服务器的用户具体分布到哪几张底单表中,然后就单独开这几个线程,极大的降低了独立库的数据库压力,改完之后,同时更新10台服务器同时跑数据,毫无压力,因为很多服务器的用户数据分布的底单表比较少,都是10以内张。这样在独立库创建一个用户状态表,里面字段:
 再加一个字段host,当前用户对应的应用服务器。
再加一个字段host,当前用户对应的应用服务器。
这样,每台应用服务器每个线程的任务就是,不断的取当前线程(表)的底单数据,我是每次取1000条,往新库对应表里通过事务导入,并且在状态表记录logid,当前1000条数据最小的id,下次循环,再查数据的时候只查比这个logid小的数据的1000条,这么做的原因是,防止中间程序未知问题挂掉,不知道从哪里开始继续导入,防止重复数据,当循环取当前用户数据为0的时候,跳出当前用户的循环,更改状态表的status为1,线程休眠自定义时间,继续下一个用户。做好日志记录。思维导图就不画了。
经过2周时间,用户数据全部迁移完毕,过程也不是那么一番顺利,有个别用户,出现问题,从新跑的数据。接下来开始数据加密了。
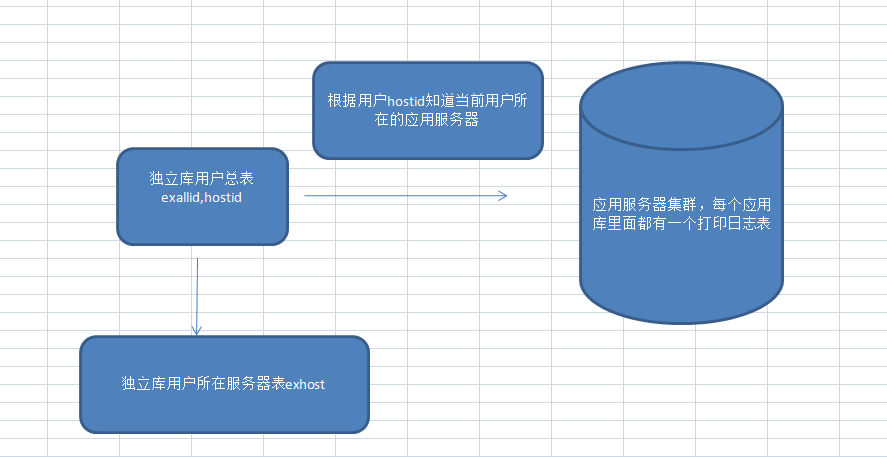
数据加密,因为还有一个纯打印日志表,这个表也需要进行加密,也就是1个用户需要加密的是底单数据和打印日志数据,为了可以让所有服务器可以同时更新加密数据,每台服务器只开两个线程,1个线程加密用户底单数据,一个线程加密打印日志数据。打印日志表,跟每台业务服务器数据库放在一起,,下图是我们公司对这几个数据存储的架构图:
加密数据,老底单库的前50张表也要加密。具体的代码逻辑和迁移数据差不多,只是稍微复杂了一些流程而已。
最后落实的工具,导用户到用户迁移/加密状态表页面,用户数据迁移/加密的监控页面,业务数据库连接层的扩展。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号