「保姆级」网络爬虫教程(一):你的百度文库下载券我都包了!
 本篇文章是「保姆级」带你入门和进阶网络爬虫系列文章的开篇,在本篇文章中我会手把手教你:如何利用简单的方法骗过百度文库的反爬机制,爬取指定的文档页面,并将文档下载下来 skr~。
本篇文章是「保姆级」带你入门和进阶网络爬虫系列文章的开篇,在本篇文章中我会手把手教你:如何利用简单的方法骗过百度文库的反爬机制,爬取指定的文档页面,并将文档下载下来 skr~。
点赞再看,养成习惯。微信公众号搜索「Job Yan」关注这个爱发技术干货的 Coder。本文 GitHub https://github.com/JobYan/PythonPearls 已收录,还有算法学习、爬虫进阶等资料,以及我的系列文章,欢迎 Star 和完善。
大家好,我是 「Job」。本篇文章是「保姆级」带你入门和进阶网络爬虫系列文章的开篇,在本篇文章中我会手把手教你:如何利用简单的方法骗过百度文库的反爬机制,爬取指定的文档页面,并将文档下载下来 skr~。温馨提示,本文字数较多,可能需要阅读较长时间,建议先点赞收藏,防止迷路。
想必大家都对百度文库已经很熟悉了,百度文库现在的收费策略,简直不要太霸道。百度文库的 VIP 策略有点恶心,之前积分可以换取下载券,为了获得积分,我当时还好心的把自己的一些文档上传到了百度文库。而现在积分根本用不到了,全是 VIP。最恶心的是,我之前上传的文档明明设置的是积分下载,而百度直接设置成为 VIP 专享,所以百度在利用我们的文档敛财,而给我们的积分却不能下载任何文档,我能说这是平台的垄断行为吗?这样好吗?这样不好,希望他耗子尾汁。这让我想起了以前网上流传的一张 Gif。

可能很多人和我的感觉是一样的,作为平台不能只关心自己的利益,还要考虑用户和贡献者的利益。所以,本期咱们学习如何利用 Python 编写爬虫脚本,爬取某些百度文库的文档,找回一些文库用户的存在感。
说了这么多无关的内容,接下来咱们开始正式的教学内容。为了便于讲解,我把抓取的过程分成了 4 步,如下图所示:
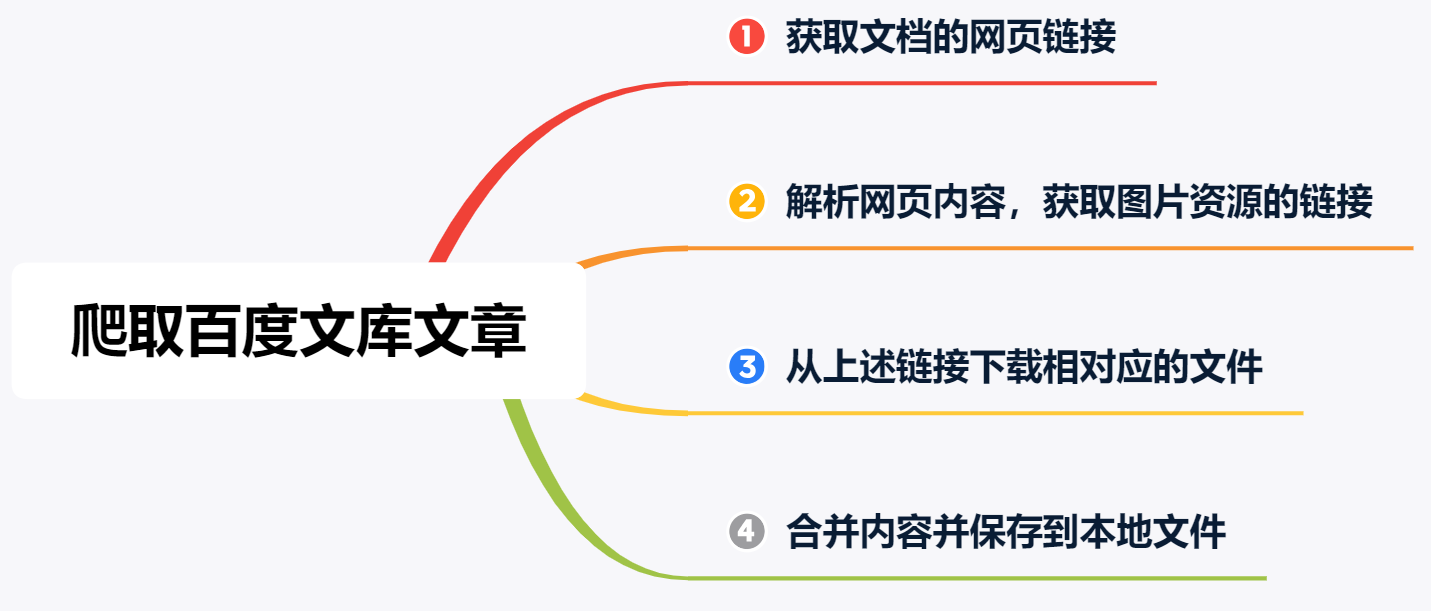
需要注意的事项有两点:
第一点,我们爬取到的文件和文库中的原文件是有区别的,以PPT类型的文件为例,我们在文档页面看到的内容其实是 PPT 经过渲染后的图片。也就是说浏览器中我们看到的都是一些图片。所以我们可以利用 Python 等编写爬虫脚本,爬取网页中的相关图片。再将这些图片合并成 PDF 文档。
第二点,不同文件类型的爬取方式是不同的,这里我先卖个关子。下一篇博文教你下载 Word,TXT,PPT 等类型的文档。
下面以某篇 PPT 文档为例,分步骤展开讲解。
第一步,获取文档的网页链接
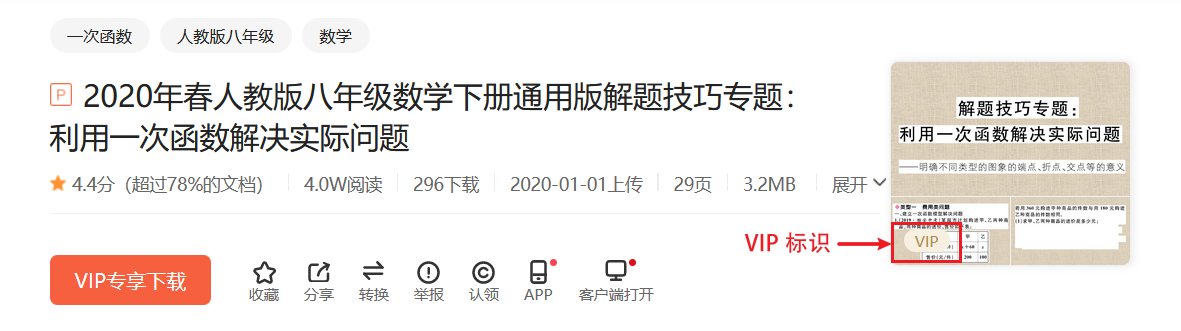
首先在浏览器中访问文库首页并获取某 PPT文档 的链接。我打开文库首页之后,随便找了篇 PPT 文档。在这里以及后面的示例程序中,我就不粘贴文档的真实链接了,一律以https://wenku.baidu.com/view/xxx.html来代替。网页截图如下:
获取文档网页链接以后,我们便可以利用 Python 自带的 requests 库获取网页内容的获取。网页的代码如下:
import requests
url = "https://wenku.baidu.com/view/xxx.html"
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
res = requests.get(url, headers=header) # Get 网页内容
我猜这个时候,很多小伙伴已经跃跃欲试了,很快就抄起键盘使出了一套 Ctrl+C 和 Ctrl+V 的组合拳,趁 IDE 没有防备,很快啊,反手就是一个 F5。此时,一丝不易觉察的笑容从你的脸上掠过,然而年轻人你笑得太早了,很快啊,你就露出惊讶的神情,「Job」老师,发生什么事了?原来啊,就在前些日子,百度文库修改了反爬策略,以前可以很容易获取到的网页内容,现在无法正常获取了。

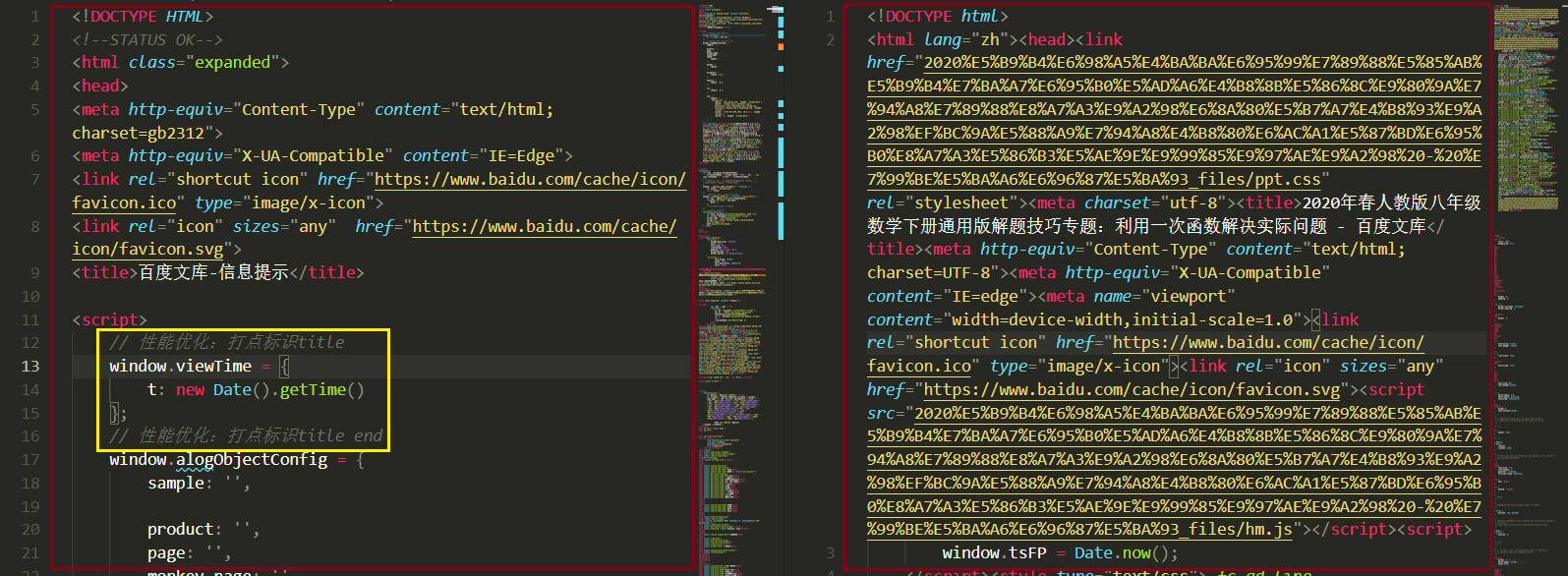
从下图中我们可以看出,使用上述代码下载到的 html 内容和原本的 html 内容是不一样的。左边红框中的内容利用上面的代码抓取到的 html 内容,右侧红框中的内容是 Firefox 浏览器保存的离线网页内容。两者是不一致的,并且左侧的内容中黄色框标识的地方好像表示文库团队在收集数据从而达到更好的反爬效果。[温馨提示:点击图片便可查看高清大图]
而在上面的代码正是通过之前简单的方式进行爬取,所以出现了问题。不过不要慌,接下来,我会教会你如何去解决这个问题。接下来,咱们欣赏一副优美的图片,让心灵的窗户休息一下。

相信看到这里的小伙伴都是很想知道问题答案的,我也就不卖关子了,直接放大招(贴代码)。下面的代码是我经过了一下午的调试和观察得出来的解决问题的方法。
import requests
url = "https://wenku.baidu.com/view/xxx.html"
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
res = requests.get('https://wenku.baidu.com')
cookie = res.cookies
# Get 网页内容
res = requests.get(url, headers=header, cookies=cookie)
在说出问题解决方法之前,请大家认真阅读上面的代码,并找出和之前代码的不同之处。
上面的代码很简单,相信细心的小伙伴已经很轻松就发现了和之前代码的不同之处,那就是在抓取目标网页之前,先抓取了一条和百度相关的网页,在这里咱们先抓取的是百度文库的首页,即 https://www.wenku.baidu.com,然后利用这次的 cookies 信息,对文库的指定网页进行抓取。
其实简单理解就是:首先让百度文库认为咱们是有身份的,这里的身份就是咱们访问百度文库首页获得的 cookies,然后凭借该身份就可以抓取百度文库的指定网页。趁其尚未觉察之际,咱们赶紧把指定网页爬取下来,「来骗来偷袭」。从目前来看这种简单的技巧可以很有效的解决被百度反爬的问题。
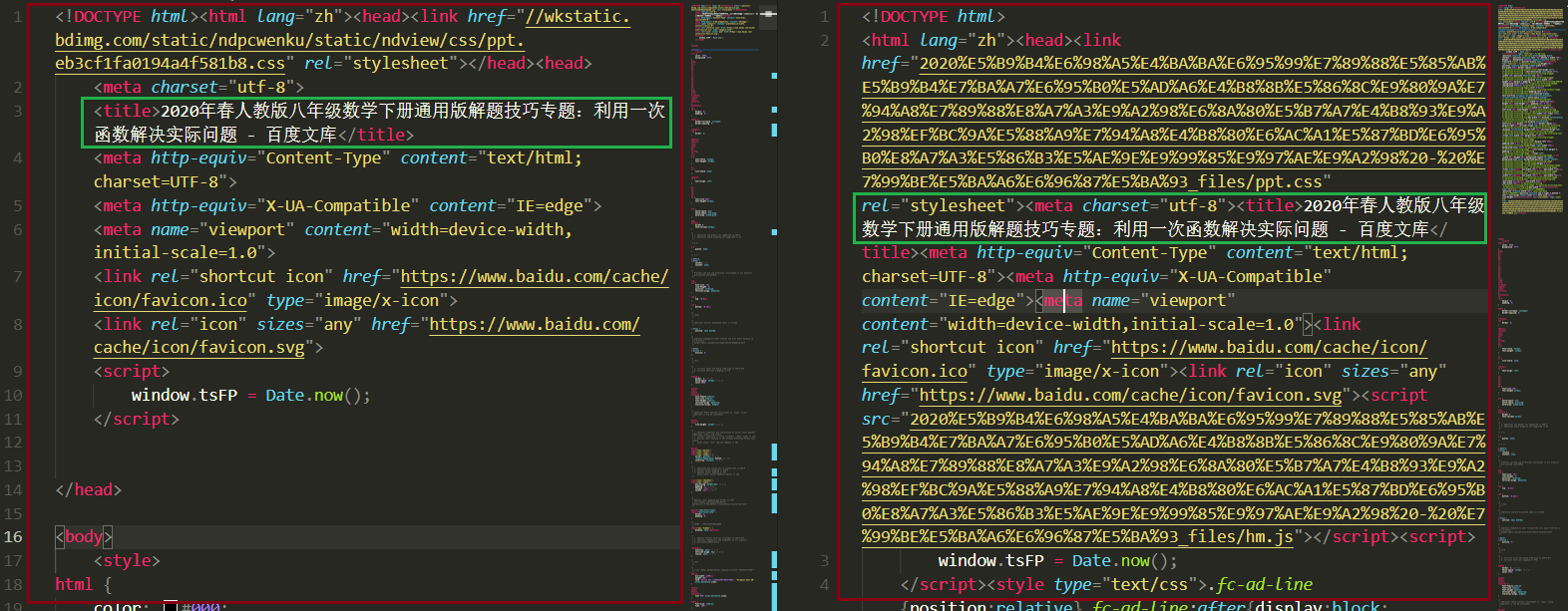
通过上述操作之后,我们获取到了和浏览器中相同的网页内容。左边红框中的内容利用上面的代码抓取到的 html 内容,右侧红框中的内容是 Firefox 浏览器保存的离线网页内容。两者是不一致的,不过没关系,我们已经抓取到了我们想要的内容。
第二步,解析网页内容,获取图片资源的链接
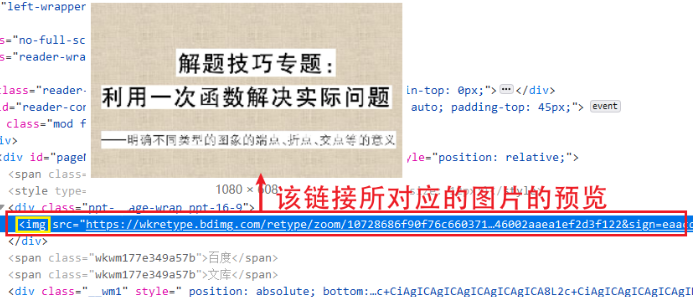
这部分是本文的关键。由前面的内容我们知道了,PPT 以图片的形式存在于网页中。那么很简单,我们首先可以利用浏览器的网页调试功能来分析网页中的各个元素。可以看到网页上的 HTML 元素的嵌套就跟洋葱似的。一层嵌套着一层,而我们获取的图片的链接是洋葱里的最里层,所以我们要一层一层的拨开它的心,从而获取图片的资源链接。下图展示了剥洋葱的过程,很生动形象。通过这种方法,我们可以很轻松的找到 PPT 页面的链接。
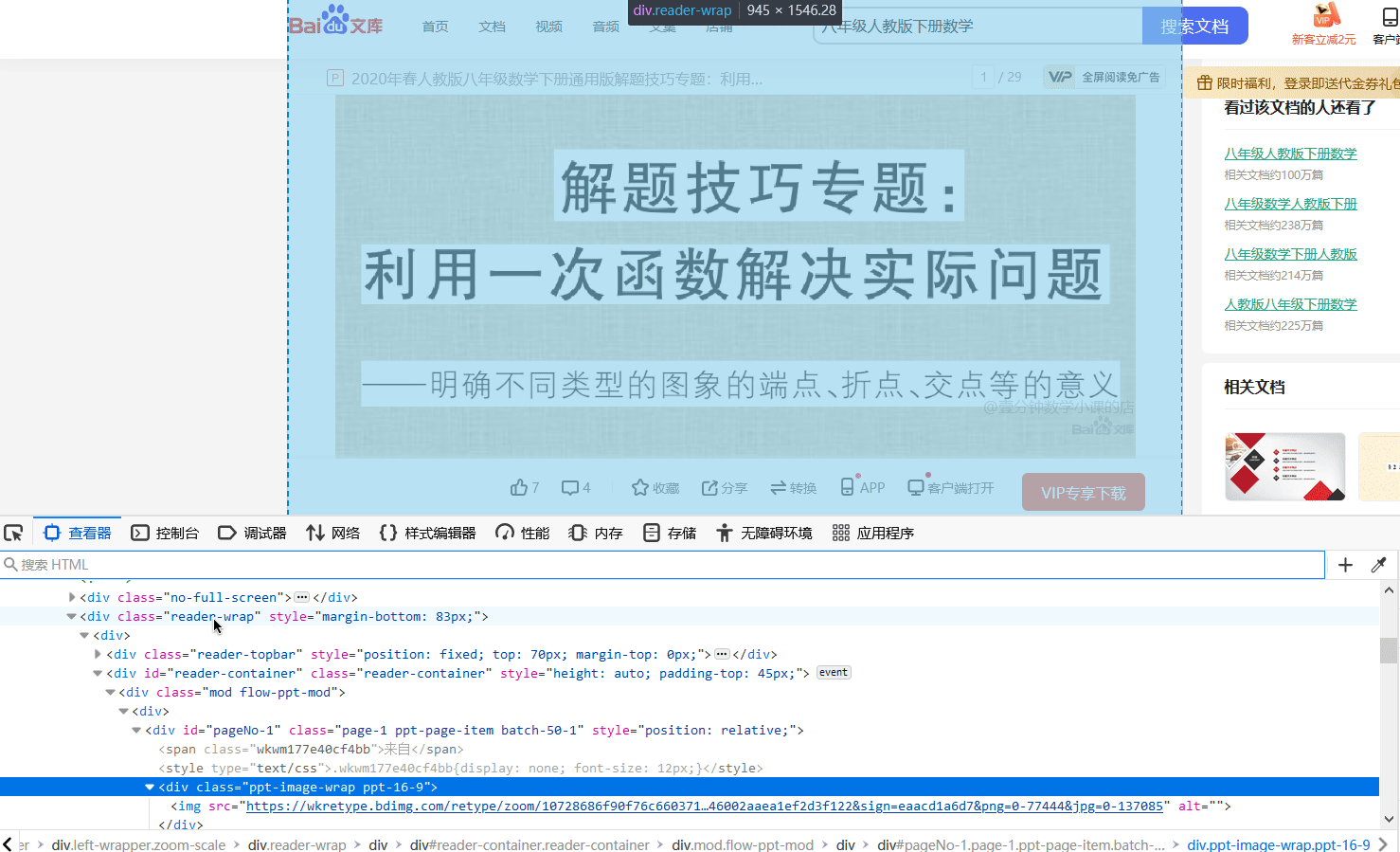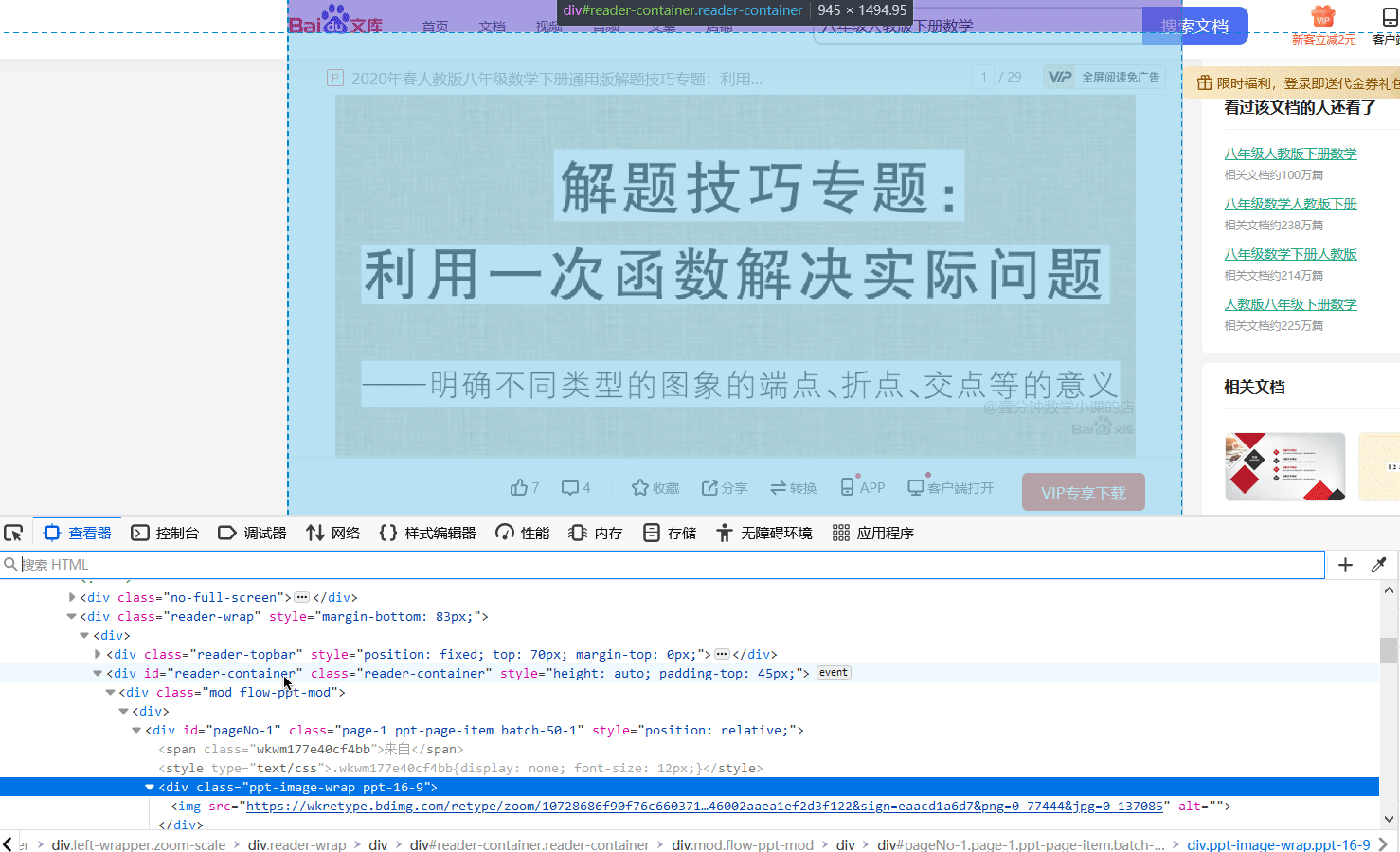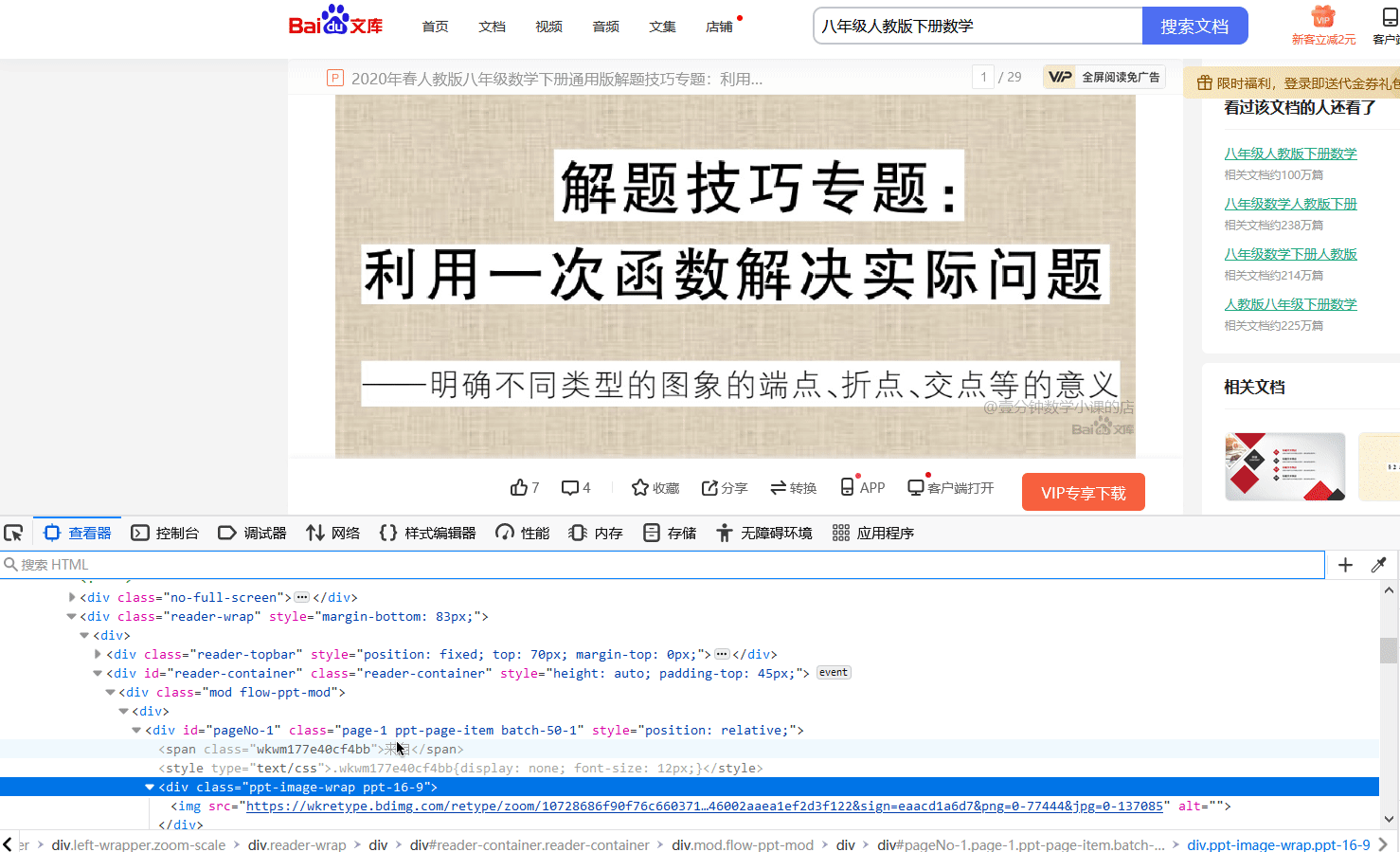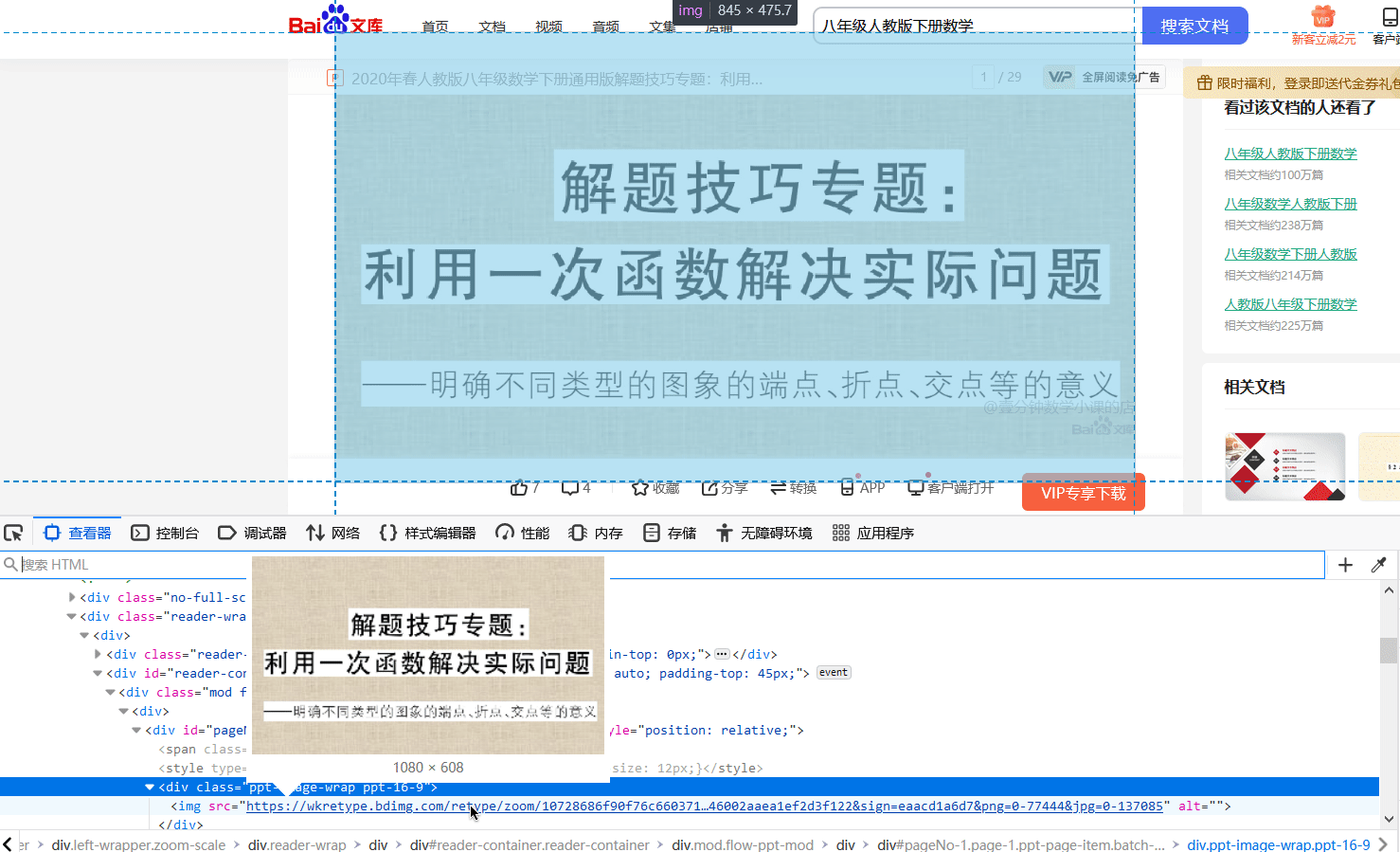
在找到第一页的 PPT 图片之后,其余图片很可以很容易的被找到,如下图绿框中标注的内容。通过这种方式我们可以很方便的找到各页图片的链接,但要程序去做,那应该怎样去编写代码呢?别慌,其实我们找到图片的链接之后,接下来编写代码的工作就简单了,'人生苦短,我用 Python',Python 中有许多现成的库函数可以帮助我们完成这个简单的任务,接下来我们会利用BeautifulSoup 来查找图片的链接。
为方便大家的理解,我先把代码放到下方,请大家先阅读一遍,接下来我会对关键地方进行讲解。
import html
from bs4 import BeautifulSoup
html_content = res.text # 网页文本内容
# 接下来,利用 Beautiful 找寻 res.text 中的相关字段
soup = BeautifulSoup(html_content, 'html.parser')
title = soup.title.text
title = title.replace(' - 百度文库', '')
print('文章标题:' + title)
# 利用 BeautifulSoup 获取文档图片的链接
img_srcs = soup.find_all('img')
img_num = len(img_srcs)
print(f"该 PPT 文档总共包含 {img_num} 张图片。")
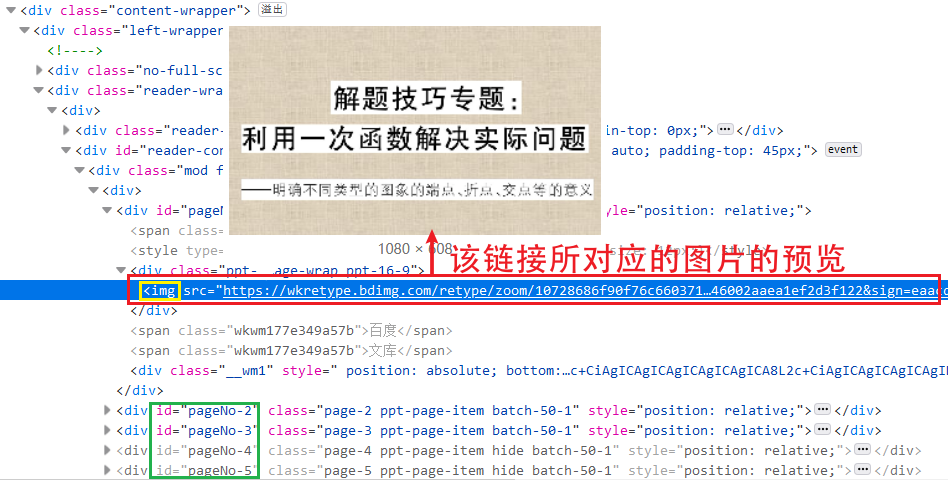
在第 6 行,使用 BeautifulSoup 解析网页内容,能够得到一个 BeautifulSoup 的对象。(更多 BeautifulSoup 的内容,请查阅官方的帮助文档,放心该文档提供了中文版的)。接下来,就可以很方便的获取网页内容中标签的相关信息。如下图所示,图片的链接包含于 标签中,所以我们利用
img_srcs = soup.find_all('img') 可以很轻松的获取该网页中包含的全部 标签。
可能有小伙伴会问, 标签中会不会包含着其他非 PPT 图片的链接?很有可能,但我现在并未发现这种情况,所以大家可以按照这种方式来获取图片的链接。
第三步,从上述链接下载相对应的文件
接下来的工作就很简单了,先上代码后解释,关键内容已写注释。
# 定义下载图片的函数,方便后续下载图片
def download_img(img_url, img_name, header, cookie):
try:
r = requests.get(img_url, headers=header, stream=True, cookies=cookie)
if r.status_code == 200 or r.status_code == 206:
open(img_name, 'wb').write(r.content) # 将内容写入图片
return True, None
except Exception as e:
return False, traceback.format_exc()
i = 0
# 遍历获取到的标签列表
for img_src in img_srcs:
i = i + 1
print(f"正在下载第 {i} 张图片,进度 {i} / {img_num} 。")
# <img src="https://wkretype.bdimg.com/retype/zoom/xxx" alt="">
img_herf = img_src.get('src') # 获取图像链接
if img_herf == None:
# 有的图片用的是'data-src'
# 即:<img data-src="https://wkretype.bdimg.com/retype/zoom/xxx" alt="">
img_herf = img_src.get('data-src') # 获取图像链接
try:
img_herf = html.unescape(img_herf)
except:
print(f"第 {i} 张图片下载失败。")
continue
img_name = str(i) + '.png'
# 下载图片
ret_val, message = download_img(img_herf, img_name, header, cookie)
if ret_val:
print(f"第 {i} 张图片下载成功 。")
else:
print(f"第 {i} 张图片下载失败,错误信息如下:\n", message)
第四步,将下载的图片合并保存为 PDF 文件
下面的工作也很简单,将下载到的图片输出到 PDF 文件中。先上代码,后解释。
import fitz
doc = fitz.open()
img_dir, _ = os.path.split(img_paths[0])
for img_path in img_paths:
imgdoc = fitz.open(img_path) # 打开图片
pdfbytes = imgdoc.convertToPDF() # 使用图片创建单页的 PDF
imgpdf = fitz.open("pdf", pdfbytes)
doc.insertPDF(imgpdf) # 将当前页插入文档
# 保存在图片文件夹下
save_pdf_path = os.path.join(img_dir, pdf_name)
if os.path.exists(save_pdf_path):
os.remove(save_pdf_path)
doc.save(save_pdf_path) # 保存pdf文件
doc.close()
在上面的代码中,我们借助 fitz 库的帮助,完成了将图片直接输出为 PDF 文件的工作。
总结:
在本篇文章中,我们学习了如何避开百度的反爬机制,获得 PPT 的网页内容,并利用 BeautifulSoup 对网页内容进行解析,获取图片链接地址,接着,我们通过链接地址下载图片,最后,我们把图片合并保存为 PDF 文档的形式。
「温馨提示」本次讲解过程所编写的代码我已上传到网盘中,网盘链接:传送门,提取码:sfa5
如果我的文章帮到了你,请给一个小心心,有了你的鼓励我后续会更有动力创作出更加优质的文章,从而帮助到更多的小伙伴。当然,如果你觉得本文章在某些方面是不够好的,请在评论区留言,你的意见对我真的非常重要,谢谢。
我已经将本文章中讲述的源码都打包好了,并且还利用 pyinstaller 生成了可执行文件,如果你有这方面需求的话,请关注公众号「Job Yan」,后台回复百度文库,即可获取相关文件,后期程序更新的话,我会第一时间将相应文件更新到微信公众号后台。本系列教程持续更新,如果你也对爬虫感兴趣,欢迎关注,咱们共同进步,一起成长。
欢迎各位小伙伴用你们心爱的大手机扫描屏幕上的二维码(长按二维码可以识别或者保存到本地哟😘)。这是个套了支付宝马甲的公众号二维码,不信你就扫扫看(手动斜眼)。

文章持续更新,可以微信公众号搜索「Job Yab」第一时间阅读,本文 GitHub https://github.com/JobYan/PythonPearls 已经收录,还有算法学习、爬虫进阶等资料,欢迎 Star 和完善。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号