
JavaEE实战——XML文档DOM、SAX、STAX解析方式详解
JavaEE实战——XML文档DOM、SAX、STAX解析方式详解
<span class="tags-box artic-tag-box">
<span class="label">标签:</span>
<a data-track-click="{"mod":"popu_626","con":"DOM"}" class="tag-link" href="http://so.csdn.net/so/search/s.do?q=DOM&t=blog" target="_blank">DOM </a><a data-track-click="{"mod":"popu_626","con":"SAX"}" class="tag-link" href="http://so.csdn.net/so/search/s.do?q=SAX&t=blog" target="_blank">SAX </a><a data-track-click="{"mod":"popu_626","con":"STAX"}" class="tag-link" href="http://so.csdn.net/so/search/s.do?q=STAX&t=blog" target="_blank">STAX </a><a data-track-click="{"mod":"popu_626","con":"JAXP"}" class="tag-link" href="http://so.csdn.net/so/search/s.do?q=JAXP&t=blog" target="_blank">JAXP </a><a data-track-click="{"mod":"popu_626","con":"XML Pull"}" class="tag-link" href="http://so.csdn.net/so/search/s.do?q=XML Pull&t=blog" target="_blank">XML Pull </a>
<span class="article_info_click">更多</span></span>
<div class="tags-box space">
<span class="label">个人分类:</span>
<a class="tag-link" href="https://blog.csdn.net/zhongkelee/article/category/6278290" target="_blank">JavaEE </a>
</div>
</div>
<div class="operating">
</div>
</div>
</div>
</div>
<article>
<div id="article_content" class="article_content clearfix csdn-tracking-statistics" data-pid="blog" data-mod="popu_307" data-dsm="post">
<div class="article-copyright">
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/zhongkelee/article/details/51737710 </div>
<link rel="stylesheet" href="https://csdnimg.cn/release/phoenix/template/css/ck_htmledit_views-f76675cdea.css">
<div class="htmledit_views">
前言
本文接着上一篇博客进行XML文档解析处理语法的介绍。在上一篇博客XML语法中我们提到了,XML技术在企业中主要应用在存储、传输数据和作为框架的配置文件这两块领域。本博客介绍的技术主要就是应用在通过XML进行存储和传输数据这一块。大致分为:JAXP DOM 解析、JAXP SAX 解析、XML PULL 进行 STAX 解析这三个方面。
简介
使用xml 存储和传输数据
1、通过程序生成xml
2、读取xml中数据 ---- xml 解析
XML解析方式有三种:DOM、SAX、StAX
三种解析方式对应着三种解析思想,表述如下。
什么是DOM、SAX、StAX ?
DOM Document Object Model ----- 文档对象模型
DOM思想: 将整个xml 加载内存中,形成文档对象,所有对xml操作都对内存中文档对象进行
DOM 是官方xml解析标准
* 所以DOM是所有开发语言都支持的 ---- Java、JavaScript 都支持DOM
SAX Simple API for XML ----- XML 简单 API
程序员为什么发明sax解析方式?? 当xml 文档非常大,不可能将xml所有数据加载到内存
SAX 思想:一边解析 ,一边处理,一边释放内存资源 ---- 不允许在内存中保留大规模xml 数据
StAX The Stream API for XML ----- XML 流 API ---- JDK6.0新特性
STAX 是一种 拉模式 XML 解析方式,SAX 是一种 推模式 XML 解析方式(SAX性能不如STAX,STAX技术较新)
注解:
推push模式:由服务器为主导,向客户端主动发送数据( 推送 )
拉pull模式: 由客户端为主导,主动向服务器申请数据( 轮询 )
三种解析开发包
掌握了三种思想后,程序员在实际开发中,使用已经开发好工具包 ----- JAXP 、DOM4j 、XML PULL
注解:
解析方式 与 解析开发包 关系?
解析方式是解析xml 思想,没有具体代码
解析开发包是解析xml思想具体代码实现。
JAXP 是sun官方推出实现技术 同时支持 DOM SAX STAX
DOM4j 是开源社区开源框架 支持 DOM 解析方式
XML PULL Android 移动设备内置xml 解析技术 支持 STAX 解析方式
DOM和SAX/STAX区别
|--DOM 支持回写
|--会将整个XML载入内存,以树形结构方式存储
|--XML比较复杂的时候,或者当你需要随机处理文档中数据的时候不建议使用
|--SAX/STAX
|--相比DOM是一种更为轻量级的方案
|--采用穿行方法读取 -- 文件输入流(字节、字符)读取
|--编程较为复杂
|--无法再读取过程中修改XML数据
注意:
当SAX和STAX 读取xml数据时,如果读取到内存数据不释放 ----- 内存中将存在整个xml文档数据(这种情况下就类似DOM 可以支持修改和回写)
DOM、SAX、STAX 在实际开发中选择?
在javaee日常开发中 ---- 优先使用DOM (编程简单)
当xml 文档数据非常多,不可能使用DOM ---造成内存溢出 ------ 优先使用STAX
移动开发 使用 STAX ---- Android XML PULL
JAXP DOM 解析
JAXP开发包简介
JAXP(Java API for XML Processing):
DOM、SAX、STAX 只是XML解析方式,没有API
JAXP是 Sun 提供的一套XML解析API,它很好的支持DOM和SAX解析方式,JDK6.0开始支持STAX解析方式,JAXP 开发包是JavaSE的一部分,它由javax.xml、org.w3c.dom 、org.xml.sax 包及其子包组成,在 javax.xml.parsers 包中,定义了几个工厂类,程序员调用这些工厂类,可以得到对xml文档进行解析的 DOM 或 SAX 的解析器对象。
JAXP 开发 进行 xml解析 软件包:
javax.xml.parsers 存放 DOM 和 SAX 解析器
javax.xml.stream 存放 STAX 解析相关类
org.w3c.dom 存放DOM解析时 数据节点类
org.xml.sax 存放SAX解析相关工具类
DOM解析模型
DOM 是以层次结构组织的节点或信息片断的集合,是 XML 数据的一种树型表示
XML文档中所有的元素、属性、文本都会被解析成node节点 ---- 从而在内存中形成XML文档树型模型 ---- 所有的解析操作都围绕着这个模型进行
(属性节点不属于任何节点的父节点或者子节点!)
节点之间关系:parent、children、sibling(兄弟)
DOM 解析快速入门
1、创建 xml 文档 books.xml在企业实际开发中,为了简化xml 生成和解析 ---- xml 数据文件通常不使用约束的
2、使用DOM解析xml
将整个xml文档加载到内存中 : 工厂 --- 解析器 ---解析加载
- DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();//工厂
- DocumentBuilder builder = builderFactory.newDocumentBuilder();//解析器
- Document document = builder.parse("books.xml");//装载进内存
3、Document通过 getElementsByTagName("") 获得 指定标签的节点集合 NodeList
通过 NodeList 提供 getLength 和 item遍历 节点集合- 遍历ArrayList
- for (int i=0;i<arraylist.size();i++){
- arraylist.get(i);
- }
-
- 遍历NodeList
- for (int i=0;i<nodelist.getLength();i++){
- nodelist.item(i); ----- 将遍历的每个节点转换子接口类型
- }
什么是 Node?
对于xml 来说,xml所有数据都是node节点 (元素节点、属性节点、文本节点、注释节点、CDATA节点、文档节点)
Element Attr Text Comment CDATASection Document ----- 都是 Node 子接口
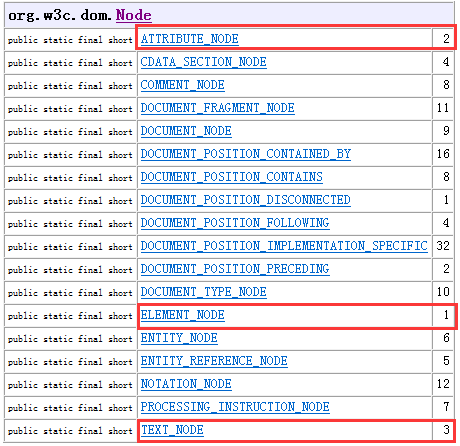
当开发人员获得某个Node类型后,就可以把Node节点转换成相应的节点对象(Element、Attr、Text)。
注解:
node有三个通用API :
|--getNodeName():返回节点的名称
|--getNodeType():返回节点的类型 ---- ELEMENT_NODE=1、ATTRIBUTE_NODE=2、TEXT_NODE=3
|--getNodeValue():返回节点的值 ---- 所有元素节点value都是 null
另外,对于元素节点ELEMENT来说:
|--获得元素节点中的属性值
|--element.getAttribute(属性名称)
|--获得元素节点内部文本内容
|--element.getTextContent()
|--element.getFirstChild().getNodeValue()
代码示例:
books.xml:
- <?xml version="1.0" encoding="UTF-8"?>
- <books>
- <book>
- <name>java编程基础</name>
- <price>80</price>
- </book>
- <book>
- <name>java高级应用</name>
- <price>100</price>
- </book>
- </books>
测试程序:
- package cn.itcast.dom.jaxp;
-
- import java.io.File;
- import java.io.IOException;
-
- import javax.xml.parsers.DocumentBuilder;
- import javax.xml.parsers.DocumentBuilderFactory;
- import javax.xml.transform.dom.DOMSource;
- import javax.xml.transform.stream.StreamResult;
-
- import org.junit.Test;
- import org.w3c.dom.Document;
- import org.w3c.dom.Element;
- import org.w3c.dom.Node;
- import org.w3c.dom.NodeList;
-
- public class DOMTest {
- @Test
- // 查询 java编程基础 书 售价
- public void demo3() throws Exception {
- // 装载xml 加载内存 --- Document对象
- DocumentBuilderFactory builderFactory = DocumentBuilderFactory
- .newInstance();
- DocumentBuilder builder = builderFactory.newDocumentBuilder();
- Document document = builder.parse("books.xml");
-
- // 利用全局查询 锁定 每个name节点
- NodeList nodelist = document.getElementsByTagName("name");
- for (int i = 0; i < nodelist.getLength(); i++) {
- Element name = (Element) nodelist.item(i);
- if (name.getTextContent().equals("java编程基础")) {
- // 图书 找到了
- // price 是 name 节点 兄弟的兄弟,三个换行符也是子节点
- Element price = (Element) name.getNextSibling()
- .getNextSibling();
- System.out.println(price.getTextContent());
- }
- }
- }
-
- @Test
- // 查询 java编程基础 书 售价
- public void demo2() throws Exception {
- // 装载xml 加载内存 --- Document对象
- DocumentBuilderFactory builderFactory = DocumentBuilderFactory
- .newInstance();
- DocumentBuilder builder = builderFactory.newDocumentBuilder();
- Document document = builder.parse("books.xml");
-
- // 全局查询 作为程序 切入
- NodeList nodelist = document.getElementsByTagName("book");
- // 遍历 强制转换 Element
- for (int i = 0; i < nodelist.getLength(); i++) {
- Element book = (Element) nodelist.item(i);
- // 找 哪个 book 节点 当中 name 节点值 java编程基础 ---- 查找book的name 子节点
- NodeList chidren = book.getChildNodes();
- //System.out.println(chidren.getLength());//注意:回车、空格也是子元素
- Element name = (Element) chidren.item(1); // book的第二个子节点就是name
- if (name.getTextContent().equals("java编程基础")) {
- // 当前for循环 这本书 是目标图书
- // 打印图书价格 price 是 book 第四个子节点
- Element price = (Element) chidren.item(3);
- System.out.println(price.getTextContent());
- }
- }
- }
-
- @Test
- public void demo1() throws Exception {
- // 通过DOM 解析 XML --- 载入整个xml 工厂 -- 解析器 --- 加载
-
- // 构造工厂
- DocumentBuilderFactory builderFactory = DocumentBuilderFactory
- .newInstance();
- // 通过工厂 获得解析器
- DocumentBuilder builder = builderFactory.newDocumentBuilder();
-
- // 使用解析器 加载 xml文档
- Document document = builder.parse("books.xml");
-
- // Document代表整个xml 文档,通过操作Document,操作xml数据
-
- // 将所有图书名称打印出来
- // 这里 nodelist 代表节点的集合
- // 查询所有 name标签
- NodeList nodelist = document.getElementsByTagName("name");
- // 遍历集合中 所有 node
- System.out.println("图书name节点数量:" + nodelist.getLength());
- for (int i = 0; i < nodelist.getLength(); i++) {
- // 获得每个 node 节点
- Node node = nodelist.item(i); // 这里每个node 都是 <name></name> ---- 元素
- Element e = (Element) node; // 将 节点转换为 子类型 节点
- System.out.println(e.getNodeName()); // 节点元素名称
- System.out.println(e.getNodeType()); // 节点元素 类型
- System.out.println(e.getNodeValue()); // 节点元素 值
- // 输出 name 元素 子节点文本节点值
- System.out.println(e.getFirstChild().getNodeValue());
- System.out.println(e.getTextContent());
- System.out.println("------------------------------------");
- }
- }
- }
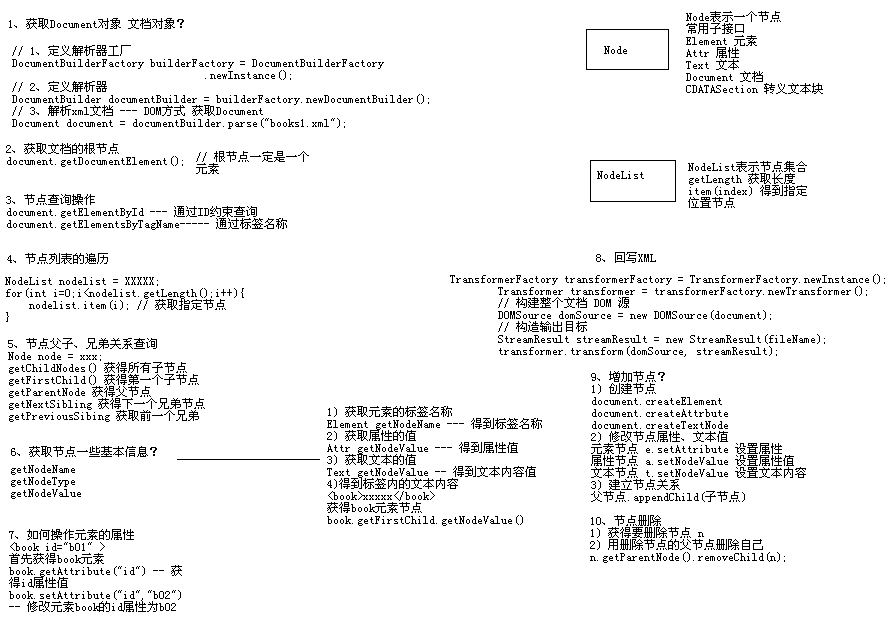
DOM 编程思路小结
1、装载XML文档 ---- Document (工厂--解析器--解析加载)
2、Document 获得指定元素 ----- getElementsByTagName (返回 NodeList)3、遍历NodeList 获得 每个 Node
4、将每个Node 强制转换 Element
5、通过元素节点API 操作属性和文本内容
|--getAttribute 获得属性值
|--getTextContent 获得元素内部文本内容
这其中,第一步是固定套路:
- DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();//工厂
- DocumentBuilder builder = builderFactory.newDocumentBuilder();//解析器
- Document document = builder.parse("books.xml");//装载进内存
DOM的增删改查 ---- CURD
XML元素查询
节点对象的查询总结:
先用全局查找锁定范围,再用相对关系查找 得到需要数据。|--全局查找元素节点
|--document.getElementByTagName
|--document.getElementById( 需要带约束的XML)
|--相对节点位置查找节点
|--getChildNodes():返回这个节点的所有子节点列表
|--getFirstChild():返回这个节点的第一个子节点
|--getParentNode():返回这个节点的父节点对象
|--getNextSibling():返回这个节点的下一个兄弟节点(注意空白也是节点)
|--getPreviousSibling():返回这个节点的前一个兄弟节点
注意:getElementById 方法 必须用于带有约束 xml文档中 !!!!!!!
例如:
books.xml:
- <?xml version="1.0" encoding="UTF-8"?>
- <!DOCTYPE books [
- <!ELEMENT books (book+) >
- <!ELEMENT book (name,price) >
- <!ELEMENT name (#PCDATA) >
- <!ELEMENT price (#PCDATA) >
- <!ATTLIST book
- id ID #REQUIRED <!--就是这个东西-->
- >
- ]>
- <books>
- <book id="b001">
- <name>java编程基础</name>
- <price>80</price>
- </book>
- <book id="b002">
- <name>java高级应用</name>
- <price>100</price>
- </book>
- </books>
getElementById 代码示例:
- package cn.itcast.dom.jaxp;
-
- import java.io.File;
- import java.io.IOException;
-
- import javax.xml.parsers.DocumentBuilder;
- import javax.xml.parsers.DocumentBuilderFactory;
- import javax.xml.transform.Transformer;
- import javax.xml.transform.TransformerFactory;
- import javax.xml.transform.dom.DOMSource;
- import javax.xml.transform.stream.StreamResult;
-
- import org.junit.Test;
- import org.w3c.dom.Document;
- import org.w3c.dom.Element;
- import org.w3c.dom.Node;
- import org.w3c.dom.NodeList;
-
- public class DOMTest {
- @Test
- // getElementById 用法 --- 查找 id b002 图书 名称
- public void demo4() throws Exception {
- // 装载xml 加载内存 --- Document对象
- DocumentBuilderFactory builderFactory = DocumentBuilderFactory
- .newInstance();
- DocumentBuilder builder = builderFactory.newDocumentBuilder();
- Document document = builder.parse("books.xml");
-
- // 直接通过id 查找 ----- 文档必须使用 约束 --- 不用约束xml文档 不能 使用getElementById
- Element book = document.getElementById("b002");
- System.out.println(book);
- System.out.println(book.getChildNodes().item(1).getTextContent());
- }
所有开发语言默认支持DTD,当使用Schema时,单独编程导入schema !
如何对xml文件进行schema约束?- DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
- SchemaFactory factory = SchemaFactory.newInstance(XMLConstants.W3C_XML_SCHEMA_NS_URI);
- StreamSource ss = new StreamSource("books.xsd");
- Schema schema = factory.newSchema(ss);
- builderFactory.setSchema(schema);
- builderFactory.setNamespaceAware(true);
XML回写
XML DOM 增加 、修改 和 删除操作 ------ 操作 内存中文档对象 ---- 操作内存结束后要回写进某一文件中更新XML文档步骤:
|--javax.xml.transform包中的Transformer类用于把代表XML文件的Document对象转换成XML格式进行输出
|--Transformer对象通过TransformerFactory获得
|--Transformer类通过transform方法完成转换操作,该方法接收一个源和一个目的地。我们可以通过:
|--javax.xml.transform.dom.DOMSource类来关联要转换的document对象,
|--javax.xml.transform.stream.StreamResult 对象来表示数据的目的地。
代码示例:
- package cn.itcast.dom.jaxp;
-
- import java.io.File;
- import java.io.IOException;
-
- import javax.xml.parsers.DocumentBuilder;
- import javax.xml.parsers.DocumentBuilderFactory;
- import javax.xml.transform.Transformer;
- import javax.xml.transform.TransformerFactory;
- import javax.xml.transform.dom.DOMSource;
- import javax.xml.transform.stream.StreamResult;
-
- import org.junit.Test;
- import org.w3c.dom.Document;
- import org.w3c.dom.Element;
- import org.w3c.dom.Node;
- import org.w3c.dom.NodeList;
-
- public class DOMTest {
- @Test
- // 将 books.xml 加载内存中,将文档内容写入另一个xml books_bak.xml(回写)
- public void demo5() throws Exception, IOException {
- // 将 文档 载入内存
- DocumentBuilderFactory builderFactory = DocumentBuilderFactory
- .newInstance();
- DocumentBuilder builder = builderFactory.newDocumentBuilder();
- Document document = builder.parse("books.xml");
-
- // 回写xml 用到 Transformer
- TransformerFactory transformerFactory = TransformerFactory
- .newInstance();
- Transformer transformer = transformerFactory.newTransformer();
-
- DOMSource domSource = new DOMSource(document);// 用document构造数据源
- StreamResult result = new StreamResult(new File("books_bak.xml"));
-
- transformer.transform(domSource, result);
- }
- }
其实你可以发现回写也是固定套路:
- TransformerFactory transformerFactory = TransformerFactory.newInstance();
- Transformer transformer = transformerFactory.newTransformer();
- DOMSource domSource = new DOMSource(document);// 用document构造数据源
- StreamResult result = new StreamResult(new File("books_bak.xml"));
- transformer.transform(domSource, result);
XML元素添加
|--创建节点元素
|--document.createXXX()创建节点
|--将节点元素加入指定位置
|--element.getDocumentElement()获得根节点
|--element.appendChild(org.w3c.dom.Node)添加节点
|--回写XML
XML元素修改
|--加载xml到内存|--查询到指定元素
|--修改元素的属性值
|--element.setAttribute(name,value);
|--修改元素内文本内容
|--element.setTextContent(value);
|--回写XML
XML元素删除
|--删除节点.getParentNode().removeChild(删除节点)(删除必须通过父节点、注意每次删完之后修复nodelist长度!)
代码示例:
- package cn.itcast.dom.jaxp;
-
- import java.io.File;
-
- import javax.xml.parsers.DocumentBuilder;
- import javax.xml.parsers.DocumentBuilderFactory;
- import javax.xml.transform.Transformer;
- import javax.xml.transform.TransformerFactory;
- import javax.xml.transform.dom.DOMSource;
- import javax.xml.transform.stream.StreamResult;
-
- import org.junit.Test;
- import org.w3c.dom.Document;
- import org.w3c.dom.Element;
- import org.w3c.dom.NodeList;
-
- /**
- * CURD create update read delete
- *
- * @author seawind
- *
- */
- public class DOMCURDTest {
- @Test
- // 删除所有 java书名 ----- 图书
- public void testDelete() throws Exception {
- // 加载xml 到内存
- DocumentBuilderFactory builderFactory = DocumentBuilderFactory
- .newInstance();
- DocumentBuilder builder = builderFactory.newDocumentBuilder();
- Document document = builder.parse("books.xml");
-
- NodeList nodelist = document.getElementsByTagName("name");
- for (int i = 0; i < nodelist.getLength(); i++) {
- Element name = (Element) nodelist.item(i);
- if (name.getTextContent().contains("java")) {
- // 这本书删除 --- 通过name 获得图书
- Element book = (Element) name.getParentNode();
- // 删除 必须 通过父节点
- book.getParentNode().removeChild(book);
- i--; // 修复list长度
- }
- }
-
- // 回写
- TransformerFactory transformerFactory = TransformerFactory
- .newInstance();
- Transformer transformer = transformerFactory.newTransformer();
- DOMSource domSource = new DOMSource(document);// 用document构造数据源
- StreamResult result = new StreamResult(new File("books_bak.xml"));
- transformer.transform(domSource, result);
- }
-
- @Test
- // 将 java高级应用 价格上调 20%
- public void testUpdate() throws Exception {
- // 加载xml 到内存
- DocumentBuilderFactory builderFactory = DocumentBuilderFactory
- .newInstance();
- DocumentBuilder builder = builderFactory.newDocumentBuilder();
- Document document = builder.parse("books.xml");
-
- // 查找 java高级应用书
- NodeList nodelist = document.getElementsByTagName("name");
- for (int i = 0; i < nodelist.getLength(); i++) {
- Element name = (Element) nodelist.item(i);
- if (name.getTextContent().equals("java高级应用")) {
- // 找到了 --- 获得价格节点
- Element price = (Element) name.getNextSibling()
- .getNextSibling();
- double money = Double.parseDouble(price.getTextContent());
- money = money * 1.2;
-
- price.setTextContent(money + "");
- }
- }
-
- // 回写
- TransformerFactory transformerFactory = TransformerFactory
- .newInstance();
- Transformer transformer = transformerFactory.newTransformer();
- DOMSource domSource = new DOMSource(document);// 用document构造数据源
- StreamResult result = new StreamResult(new File("books_bak.xml"));
- transformer.transform(domSource, result);
- }
-
- @Test
- // 向xml 添加一个 book元素
- public void testAdd() throws Exception {
- // 1 将原来 books.xml 加载到内容
- DocumentBuilderFactory builderFactory = DocumentBuilderFactory
- .newInstance();
- DocumentBuilder builder = builderFactory.newDocumentBuilder();
- Document document = builder.parse("books.xml");
-
- // 2、添加节点 创建节点 books
- Element newBook = document.createElement("book"); // <book></book>
- newBook.setAttribute("id", "b003");
-
- // 创建name节点
- Element newName = document.createElement("name"); // <name></name>
- newName.setTextContent("编程高手秘笈");
-
- // 将 新 name 放入 新 book
- newBook.appendChild(newName);
-
- // 3、添加节点到指定位置 ---- 获得books根节点
- Element root = document.getDocumentElement();
- root.appendChild(newBook);
-
- // 4、回写xml
- TransformerFactory transformerFactory = TransformerFactory
- .newInstance();
- Transformer transformer = transformerFactory.newTransformer();
- DOMSource domSource = new DOMSource(document);// 用document构造数据源
- StreamResult result = new StreamResult(new File("books_bak.xml"));
- transformer.transform(domSource, result);
- }
- }
DOM总结:
JAXP SAX 解析
SAX 和 STAX 都是 基于事件驱动 ----- SAX推模式 STAX拉模式
SAX解析处理器的常用事件
|--DefaultHandler类(在 org.xml.sax.helpers 软件包中)来实现所有这些回调,并提供所有回调方法默认的空实现|--startDocument() ---- 文档开始事件
|--startElement() ---- 元素开始事件
|--characters() ---- 文本元素事件
|--endElement() ---- 元素结束事件
|--endDocument() ----- 文档结束事件
SAX解析原理
SAX和DOM不同:
DOM解析器 ---- 将整个XML文档全部加载到内存,返回文档对象Document
解析器DocumentBuilder ---- Document document = builder.parse(file)
SAX解析器 ---- 一边读取XML一边解析一边处理,并没有返回值
解析器SAXParser ---- 将XML文档和文档解析处理器(DefaultHandler及其子类)同时传递给SAX解析器 ---- 解析器调用处理器相应的事件处理方法来处理文档
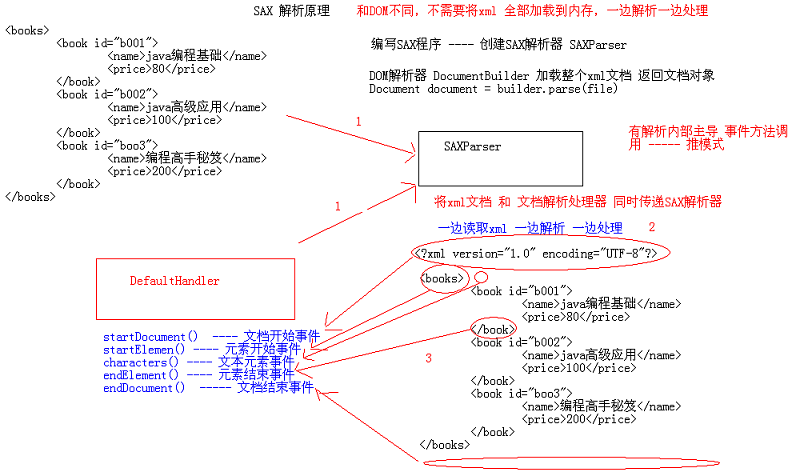
为什么说SAX是推模式解析? 解析器控制xml文件解析,由解析器调用相应事件方法
由位于服务器端的解析器内部主导的事件方法调用 ---- 推模式
SAX解析器采用了基于事件的模型,它在解析XML文档的时候可以触发一系列的事件,发生相应事件时,将调用一个回调方法,例如:
- <?xml version=“1.0” encoding=“utf-8”?>
- <config>
- <server>UNIX</server>
- </config>
依次触发的事件:
Start documentStart element (config)
Characters (whitespace)
Start element (server)
Characters (UNIX)
End element (server)
Characters (whitespace)
End element (config)
End document
代码示例:
server.xml:
- <?xml version="1.0" encoding="UTF-8"?>
- <config>
- <server id="s100">UNIX</server>
- </config>
- package cn.itcast.sax.jaxp;
-
- import javax.xml.parsers.SAXParser;
- import javax.xml.parsers.SAXParserFactory;
-
- import org.xml.sax.Attributes;
- import org.xml.sax.SAXException;
- import org.xml.sax.helpers.DefaultHandler;
-
- /**
- * 编写sax解析xml 实例
- *
- * @author seawind
- *
- */
- public class SAXTest {
- public static void main(String[] args) throws Exception {
- // 1、工厂
- SAXParserFactory factory = SAXParserFactory.newInstance();
- // 2、通过工厂获得解析器
- SAXParser parser = factory.newSAXParser();
-
- // 3 、创建 Handler
- MyHandler handler = new MyHandler();
-
- // 4、将xml 文档 和 handler 同时传递给 解析器
- parser.parse("server.xml", handler);
- }
- }
-
- /**
- * 继承 DefaultHandler 重写 5 个事件方法
- *
- * @author seawind
- *
- */
- class MyHandler extends DefaultHandler {
- @Override
- public void startDocument() throws SAXException {
- System.out.println("start document...");
- }
-
- @Override
- public void startElement(String uri, String localName, String qName,
- Attributes attributes) throws SAXException {
- System.out.println("start element(" + qName + ")...");
- // 打印server元素 id 属性 --- 判断当前开始元素是 server
- if (qName.equals("server")) {
- System.out.println("id属性的值:" + attributes.getValue("id"));
- }
- }
-
- @Override
- public void characters(char[] ch, int start, int length)
- throws SAXException {
- String content = new String(ch, start, length);
- System.out.println("characters: " + content);
- }
-
- @Override
- public void endElement(String uri, String localName, String qName)
- throws SAXException {
- System.out.println("end element(" + qName + ")...");
- }
-
- @Override
- public void endDocument() throws SAXException {
- System.out.println("end document...");
- }
-
- }
使用SAX方式解析XML步骤
|--使用SAXParserFactory创建SAX解析工厂
|--SAXParserFactory spf = SAXParserFactory.newInstance();
|--通过SAX解析工厂得到解析器对象
|--SAXParser sp = spf.newSAXParser();
|--通过解析器对象解析xml文件
|--sp.parse("book.xml“,new XMLContentHandler());
|--这里的XMLContentHandler 继承 DefaultHandler
|--在startElement() endElement() 获得 开始和结束元素名称
|--在characters() 获得读取到文本内容
|--在startElement() 读取属性值
XML PULL 解析
STAX 拉模式xml 解析方式 ----- 客户端程序,自己控制xml事件,主动调用相应事件方法
XML PULL 解析器开发包简介
当使用XML PULL,如果使用Android系统,系统内置无需下载任何开发包;如果想JavaSE、JavaEE使用pull解析技术下载单独pull 开发工具包。、
xpp3 ----- XML Pull Parser 3 是pull API 代码实现
使用pull 解析器
1、去网站上 下载 pull 解析器的实现 xpp3 (Android 内置)
2、将 xpp3-1.1.3.4.C.jar 导入 java工程
良好习惯:要导入jar包应当位于当前工程内部。
方法:在工程内新建lib文件夹,将jar复制过来,然后将pull解析器xpp3.jar包添加至Java Build Path (Libraries--Add JARs 或右键jar包 Add to Build Path),这样pull解析器才能使用。
注解:jar 包就是.class文件 集合压缩包 (采用zip格式压缩)
3、创建pull 解析器 ---- XmlPullParser
4、将xml 文档内容传递 pull 解析器
5、需要客户端程序手动完成解析,XmlPullParser存放解析方法next(),用于解析器解析下一事件
STAX解析原理
Pull解析器 使用 stax 解析方式 ---- 拉模式解析
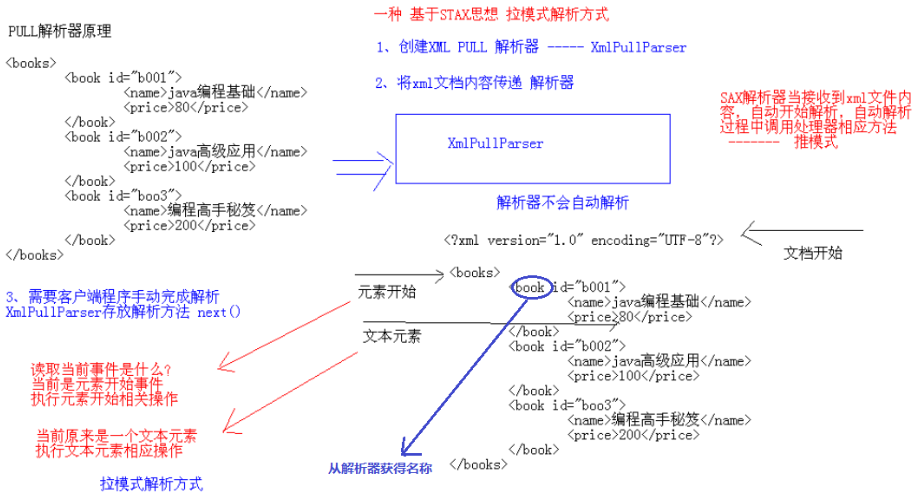
SAX解析器当接收到XML文件内容,服务器端解析器SAXParser自动开始解析,自动解析过程中调用处理器相应方法 ---- 推模式
Pull采用将xml文档传递解析器,解析器XmlPullParser不会自动解析,需要手动通过next触发文档解析事件,在客户端代码中获取当前事件 ,从而调用相应事件处理方法。
为什么 STAX 解析方式 效率 好于 SAX ?
1、SAX 无选择性的,所有事件都会处理的解析方式,解析器控制事件的调用;StAX由用户自主控制需要处理事件类型以及事件的调用。
2、在使用Stax进行数据解析时,随时终止解析。
使用XML Pull解析 XML
|--参考官方文档
|--http://www.xmlpull.org/v1/download/unpacked/doc/quick_intro.html
|--Xpp3 XmlPullParser javadoc
|--关键代码
|--创建解析器工厂
|--XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
|--factory.setNamespaceAware(true);
|--根据工厂创建解析器
|--XmlPullParser xpp = factory.newPullParser();
|--读取xml文件
|--xpp.setInput(inStream, "UTF-8");
|--当前节点事件类型
|--int eventType = xpp.getEventType();
|--下一个节点事件
|--eventType = xpp.next();
|--获得元素名称
|--xpp.getName();
|--获得标签属性值
|--xpp.getAttributeValue
|--获得标签后面文本内容
|--xpp.nextText();
代码示例:
books.xml:
- <?xml version="1.0" encoding="UTF-8"?>
- <!DOCTYPE books [
- <!ELEMENT books (book+) >
- <!ELEMENT book (name,price) >
- <!ELEMENT name (#PCDATA) >
- <!ELEMENT price (#PCDATA) >
- <!ATTLIST book
- id ID #REQUIRED <!--就是这个东西-->
- >
- ]>
- <books>
- <book id="b001">
- <name>java编程基础</name>
- <price>80</price>
- </book>
- <book id="b002">
- <name>java高级应用</name>
- <price>100</price>
- </book>
- <book id="boo3">
- <name>编程高手秘笈</name>
- <price>200</price>
- </book>
- </books>
遍历代码实例、查询某本书的价格:
- package cn.itcast.stax.pull;
-
- import java.io.FileInputStream;
-
- import org.junit.Test;
- import org.xmlpull.v1.XmlPullParser;
- import org.xmlpull.v1.XmlPullParserFactory;
-
- /**
- * 通过 pull 解析器 解析 xml
- *
- * @author seawind
- *
- */
- public class PullTest {
- @Test
- // 通过 pull 解析技术 查看 "编程高手秘笈" 价格
- public void demo2() throws Exception {
- // 1. 创建 pull 解析器
- XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
- XmlPullParser parser = factory.newPullParser();
- // 2. 将 xml文档传递 解析器
- parser.setInput(new FileInputStream("books.xml"), "utf-8");
-
- // 通过循环 驱动事件解析
- int event;
-
- // 查找name 标识位
- boolean isFound = false;
- while ((event = parser.getEventType()) != XmlPullParser.END_DOCUMENT) {
- // 获得 开始元素 name
- if (event == XmlPullParser.START_TAG
- && parser.getName().equals("name")) {
- // 获得元素后面文本
- String bookname = parser.nextText();
- if (bookname.equals("编程高手秘笈")) {
- isFound = true;
- // 这本书就是我要找到
- // parser.next();
- // System.out.println(parser.getEventType());
- // parser.next(); // price 开始
- // System.out.println(parser.getEventType());
- // String money = parser.nextText();//太麻烦,用标识位简单
- // System.out.println(money);
- }
- }
-
- if (event == XmlPullParser.START_TAG
- && parser.getName().equals("price") && isFound) {
- System.out.println(parser.nextText());
- break;
- }
-
- parser.next();
- }
- }
-
- @Test
- public void demo1() throws Exception {
- // 1、创建 xml pull 解析器
- // 工厂
- XmlPullParserFactory xmlPullParserFactory = XmlPullParserFactory
- .newInstance();
-
- // 通过工厂 获得解析器
- XmlPullParser parser = xmlPullParserFactory.newPullParser();
-
- // 2、将 xml 文件 传递 解析器
- parser.setInput(new FileInputStream("books.xml"), "utf-8");
-
- // pull 解析器用得是 拉模式 数据 解析
- int event;
-
- while ((event = parser.getEventType()) != XmlPullParser.END_DOCUMENT) {
- //System.out.println(event);
-
- // 打印哪个元素开始了 ---- 判断当前事件 是 元素开始事件
- if (event == XmlPullParser.START_TAG) {
- // 所有数据 从解析器 获得
- System.out.println(parser.getName() + "元素开始了...");
- }
-
- // 打印 哪个 元素 结束了
- if (event == XmlPullParser.END_TAG) {
- System.out.println(parser.getName() + "元素 结束了...");
- }
-
- // 处理下一个事件
- parser.next();
- }
-
- // parser.getEventType()获得当前事件类型
- // 可以通过查看XmlPullParser源码得到各常量代表意义
- // int event = parser.getEventType();
- //
- // System.out.println(event);//START_DOCUMENT = 0
- //
- // parser.next(); // 解析器解析下一个事件
- //
- // int event2 = parser.getEventType();
- //
- // System.out.println(event2);//START_TAG = 2
- //
- // parser.next();
- //
- // int event3 = parser.getEventType();
- //
- // System.out.println(event3);//TEXT = 4
-
- }
- }
XML PULL 生成XML文档
Pull 解析器 生成 xml 文档功能 ---- 通过 XmlSerializer 生成 xml 文档
解析xml :文档开始、元素开始、文本元素、元素结束、文档结束
生成xml :生成文档声明(文档开始),元素开始、文本内容、元素结束 、文档结束
代码示例:
1、生成简单xml
2、通过对象数据生成xml
3、通过对象List数据生成xml
---- 序列化 XmlSerializer
- package cn.itcast.stax.pull;
-
- import java.io.FileOutputStream;
- import java.util.ArrayList;
- import java.util.List;
-
- import org.junit.Test;
- import org.xmlpull.v1.XmlPullParserFactory;
- import org.xmlpull.v1.XmlSerializer;
-
- import cn.itcast.domain.Company;
-
- /**
- * 生成 xml
- *
- * @author seawind
- *
- */
- public class SerializerTest {
- @Test
- // 根据 List<Company> 生成xml
- public void demo3() throws Exception {
- List<Company> companies = new ArrayList<Company>();
-
- Company company = new Company();
- company.setName("传智播客");
- company.setPnum(200);
- company.setAddress("西二旗软件园!");
-
- Company company2 = new Company();
- company2.setName("CSDN");
- company2.setPnum(1000);
- company2.setAddress("西二旗 软件园 ");
-
- companies.add(company);
- companies.add(company2);
-
- // 序列化对象
- XmlSerializer serializer = XmlPullParserFactory.newInstance()
- .newSerializer();
-
- // 设置输出文件
- serializer.setOutput(new FileOutputStream("company.xml"), "utf-8");
-
- serializer.startDocument("utf-8", true);
-
- serializer.startTag(null, "companies");
-
- // 遍历list集合
- for (Company c : companies) {
- serializer.startTag(null, "company");
-
- serializer.startTag(null, "name");
- serializer.text(c.getName());
- serializer.endTag(null, "name");
-
- serializer.startTag(null, "pnum");
- serializer.text(c.getPnum() + "");
- serializer.endTag(null, "pnum");
-
- serializer.startTag(null, "address");
- serializer.text(c.getAddress());
- serializer.endTag(null, "address");
-
- serializer.endTag(null, "company");
- }
-
- serializer.endTag(null, "companies");
-
- serializer.endDocument();
-
- }
-
- @Test
- // 根据company对象数据生成xml
- public void demo2() throws Exception {
- Company company = new Company();
- company.setName("传智播客");
- company.setPnum(200);
- company.setAddress("西二旗软件园!");
-
- /*
- * <company>
- *
- * <name>传智播客</name>
- *
- * <pnum>200</pnum>
- *
- * <address>西二旗软件园</address>
- *
- * </company>
- */
-
- // 获得序列化对象
- XmlSerializer serializer = XmlPullParserFactory.newInstance()
- .newSerializer();
-
- // 传递 输出目标文件 给序列化对象
- serializer.setOutput(new FileOutputStream("company.xml"), "utf-8");
-
- serializer.startDocument("utf-8", true);
-
- serializer.startTag(null, "company");
-
- serializer.startTag(null, "name");
- serializer.text(company.getName());
- serializer.endTag(null, "name");
-
- serializer.startTag(null, "pnum");
- serializer.text(company.getPnum() + "");
- serializer.endTag(null, "pnum");
-
- serializer.startTag(null, "address");
- serializer.text(company.getAddress());
- serializer.endTag(null, "address");
-
- serializer.endTag(null, "company");
-
- serializer.endDocument();
- }
-
- @Test
- public void demo1() throws Exception {
- // 获得XmlSerializer对象
- XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
- XmlSerializer serializer = factory.newSerializer();
-
- // 设置序列化输出文档
- serializer.setOutput(new FileOutputStream("company.xml"), "utf-8");
-
- // 文档开始
- serializer.startDocument("utf-8", true);
-
- // 元素开始
- serializer.startTag(null, "company"); // 没有命名空间 ,"" 或者 null
-
- // 文本元素
- serializer.text("传智播客");
-
- // 元素结束
- serializer.endTag(null, "company");
-
- // 文档结束
- serializer.endDocument();
-
- /*
- * <?xml version="1.0" encoding="UTF-8" standalone="yes" ?>
- *
- * <company>
- *
- * 传智播客
- *
- * </company>
- */
- }
- }
STAX的增删改查 ---- CURD
对xml文件通过pull解析器进行CURD操作原理:
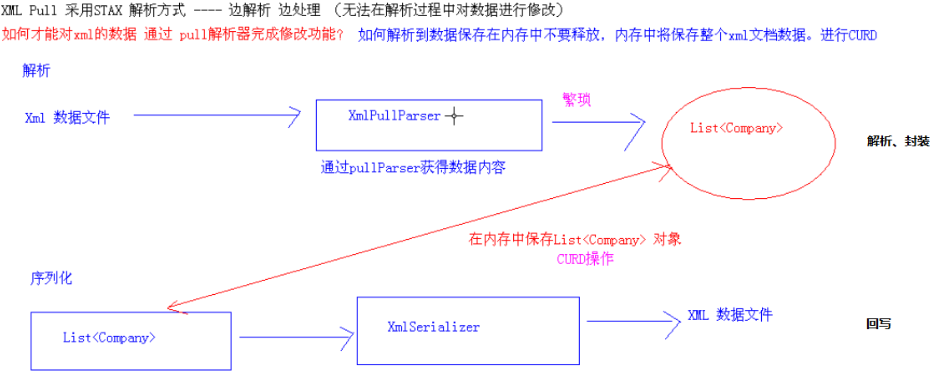
当下问题:pull解析器封装List对象过程 ---- 如何将XML数据 --> List<Object>

将xml数据通过pull解析器生成List集合,代码示例:
company源码:
- package cn.itcast.domain;
-
- /**
- * 公司数据类
- *
- * @author seawind
- *
- */
- public class Company {
- private String name;
- private int pnum;//人数
- private String address;
-
- public String getName() {
- return name;
- }
-
- public void setName(String name) {
- this.name = name;
- }
-
- public int getPnum() {
- return pnum;
- }
-
- public void setPnum(int pnum) {
- this.pnum = pnum;
- }
-
- public String getAddress() {
- return address;
- }
-
- public void setAddress(String address) {
- this.address = address;
- }
-
- }
测试代码:
- package cn.itcast.stax.pull;
-
- import java.io.FileInputStream;
- import java.util.ArrayList;
- import java.util.List;
-
- import org.junit.Test;
- import org.xmlpull.v1.XmlPullParser;
- import org.xmlpull.v1.XmlPullParserFactory;
-
- import cn.itcast.domain.Company;
-
- public class PullCURD {
- @Test
- // 将xml中数据 ---- List集合对象
- public void demo1() throws Exception {
- List<Company> companies = new ArrayList<Company>();
- Company company = null;//定义一个临时Company引用
-
- // 获得解析器
- XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
- XmlPullParser parser = factory.newPullParser();
-
- // 向解析器传入xml文件
- parser.setInput(new FileInputStream("company.xml"), "utf-8");
-
- // 遍历解析
- int event;
- while ((event = parser.getEventType()) != XmlPullParser.END_DOCUMENT) {
-
- if (event == XmlPullParser.START_TAG
- && parser.getName().equals("company")) {
- // company 开始 创建 company 对象
- company = new Company();
- }
-
- if (event == XmlPullParser.START_TAG
- && parser.getName().equals("name")) {
- // name 元素开始 -- 封装name属性
- company.setName(parser.nextText());
- }
-
- if (event == XmlPullParser.START_TAG
- && parser.getName().equals("pnum")) {
- company.setPnum(Integer.parseInt(parser.nextText()));
- }
-
- if (event == XmlPullParser.START_TAG
- && parser.getName().equals("address")) {
- company.setAddress(parser.nextText());
- }
-
- if (event == XmlPullParser.END_TAG
- && parser.getName().equals("company")) {
- // company 结束
- companies.add(company);
- }
-
- parser.next();
- }
-
- for (Company c : companies) {
- System.out.println(c.getName());
- System.out.println(c.getPnum());
- System.out.println(c.getAddress());
- System.out.println("----------------------");
- }
-
- }
- }
当内存中读取到List<Object>后,就可以CURD,最后序列化到XML文件中即可。
因为上述方法经常使用,所以建议在程序中抽取这两个方法 ----- 1. xml ---> List对象 2. List对象生成xml
* XmlPullUtils通用程序(反射+泛型) ------ 编写一个工具类 以后pull解析
- package cn.itcast.stax.pull;
-
- import java.io.FileInputStream;
- import java.io.FileOutputStream;
- import java.util.ArrayList;
- import java.util.List;
-
- import org.xmlpull.v1.XmlPullParser;
- import org.xmlpull.v1.XmlPullParserFactory;
- import org.xmlpull.v1.XmlSerializer;
-
- import cn.itcast.domain.Company;
-
- /**
- * 工具类 抽取两个方法 :1、xml --> List 2 List --> XML
- *
- * @author seawind
- *
- */
- public class PullUtils {
- /**
- * 接收xml文件,返回 List集合
- *
- * @param fileName
- * @return
- * @throws Exception
- */
- public static List<Company> parseXml2List(String fileName) throws Exception {
- List<Company> companies = new ArrayList<Company>();
-
- // 获得解析器
- XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
- XmlPullParser parser = factory.newPullParser();
-
- // 设置 xml 输入文件
- parser.setInput(new FileInputStream(fileName), "utf-8");
-
- // 解析遍历
- int event;
- // 定义一个临时Company 引用
- Company company = null;
- while ((event = parser.getEventType()) != XmlPullParser.END_DOCUMENT) {
- // 将每个<company> 元素封装 Company对象
- // 1、在company开始时候,创建对象
- if (event == XmlPullParser.START_TAG
- && parser.getName().equals("company")) {
- company = new Company();
- }
-
- // 2、读取name元素时,向company对象中封装 name属性
- if (event == XmlPullParser.START_TAG
- && parser.getName().equals("name")) {
- company.setName(parser.nextText());
- }
-
- // 3、读取pnum元素时,向company对象保存pnum属性
- if (event == XmlPullParser.START_TAG
- && parser.getName().equals("pnum")) {
- company.setPnum(Integer.parseInt(parser.nextText()));
- }
-
- // 4、读取address元素,向company封装 address属性
- if (event == XmlPullParser.START_TAG
- && parser.getName().equals("address")) {
- company.setAddress(parser.nextText());
- }
-
- // 5、读取company元素结束时,将company对象加入集合
- if (event == XmlPullParser.END_TAG
- && parser.getName().equals("company")) {
- companies.add(company);
- }
-
- // 解析 下一个 事件
- parser.next();
- }
-
- return companies;
- }
-
- /**
- * 同时接收xml文件和List集合,将集合中数据写入xml文件中
- *
- * @param companies
- * @param fileName
- * @throws Exception
- */
- public static void serializeList2Xml(List<Company> companies,
- String fileName) throws Exception {
- // 获得序列化对象
- XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
- XmlSerializer serializer = factory.newSerializer();
-
- // 写文件之前,指定输出文件
- serializer.setOutput(new FileOutputStream(fileName), "utf-8");
-
- // 文档开始
- serializer.startDocument("utf-8", true);
-
- // 根元素开始 companies
- serializer.startTag(null, "companies");
-
- // 遍历集合List ,每个List中Company对象 生成一个片段
- for (Company company : companies) {
- // company 开始
- serializer.startTag(null, "company");
-
- // name属性开始
- serializer.startTag(null, "name");
-
- // 写入name数据
- serializer.text(company.getName());
-
- // name属性结束
- serializer.endTag(null, "name");
-
- // pnum 属性开始
- serializer.startTag(null, "pnum");
-
- // 写入pnum数据
- serializer.text(company.getPnum() + "");
-
- // pnum 属性结束
- serializer.endTag(null, "pnum");
-
- // address属性开始
- serializer.startTag(null, "address");
-
- // 写入 address值
- serializer.text(company.getAddress());
-
- // address属性结束
- serializer.endTag(null, "address");
-
- // company 结束
- serializer.endTag(null, "company");
- }
-
- // 根元素结束
- serializer.endTag(null, "companies");
-
- // 文档结束
- serializer.endDocument();
- }
- }
对内存中List进行CURD操作
- package cn.itcast.stax.pull;
-
- import java.io.FileInputStream;
- import java.util.ArrayList;
- import java.util.List;
-
- import org.junit.Test;
- import org.xmlpull.v1.XmlPullParser;
- import org.xmlpull.v1.XmlPullParserFactory;
-
- import cn.itcast.domain.Company;
-
- /**
- * 完成pull解析器CURD操作
- *
- * @author seawind
- *
- */
- public class PullCURD {
- @Test
- // CSDN 从列表删除
- public void testDelete() throws Exception {
- // 1、解析 xml 数据到内存 list
- List<Company> companies = PullUtils.parseXml2List("company.xml");
-
- // 2、从list集合中删除 csdn 的company对象
- for (Company company : companies) {
- if (company.getName().equals("CSDN")) {
- companies.remove(company);
- break;//不写break,会报并发错误
- }
- }
-
- // 3、回写xml
- PullUtils.serializeList2Xml(companies, "company_bak.xml");
- }
-
- @Test
- // 将传智播客人数 200%
- public void testUpdate() throws Exception {
- // 1、解析 xml 数据到内存 list
- List<Company> companies = PullUtils.parseXml2List("company.xml");
-
- // 2、增长传智播客人数 200%
- for (Company company : companies) {
- if (company.getName().equals("传智播客")) {
- company.setPnum(company.getPnum() * 2);
- }
- }
-
- // 3、回写xml
- PullUtils.serializeList2Xml(companies, "company_bak.xml");
- }
-
- @Test
- // 查询 csdn人数
- public void testSelect() throws Exception {
- // 1、解析 xml 数据到内存 list
- List<Company> companies = PullUtils.parseXml2List("company.xml");
- // 2 遍历集合对象
- for (Company company : companies) {
- if (company.getName().equals("CSDN")) {
- System.out.println(company.getPnum());
- }
- }
- }
-
- @Test
- // 向 company插入一个公司信息
- public void testAdd() throws Exception {
- // 1、解析 xml 数据到内存 list
- List<Company> companies = PullUtils.parseXml2List("company.xml");
-
- // 2、添加company对象
- Company company = new Company();
- company.setName("baidu");
- company.setPnum(5000);
- company.setAddress("百度大楼!");
- companies.add(company);
-
- // 3、将List对象回写xml
- PullUtils.serializeList2Xml(companies, "company_bak.xml");
- }
-
- @Test
- // 测试工具类 PullUtils中方法
- public void demo2() throws Exception {
- // 将 company.xml 复制 company_bak.xml
- // 解析获得集合
- List<Company> companies = PullUtils.parseXml2List("company.xml");
- // 将集合写入 company_bak.xml
- PullUtils.serializeList2Xml(companies, "company_bak.xml");
- }
- }
综合案例
平时的开发过程中,经常涉及到xml文件的解析,实现xml文件到java bean的转换。当前有个xml文件,在不允许使用第三方jar的情况下解析xml文件,并根据member节点建立member对象。文件格式如下:
- <?xml version="1.0" encoding="UTF-8"?>
- <root>
- <member>
- <name>Jack1</name>
- <age>18</age>
- <grade>70</grade>
- </member>
- <member>
- <name>Appl2</name>
- <age>20</age>
- <grade>70</grade>
- </member>
- <member>
- <name>Appl2</name>
- <age>20</age>
- <grade>70</grade>
- </member>
- <member>
- <name>Appl2</name>
- <age>20</age>
- <grade>72</grade>
- </member>
- <member>
- <name>Adpl2</name>
- <age>20</age>
- <grade>73</grade>
- </member>
- <member>
- <name>ccpl2</name>
- <age>20</age>
- <grade>75</grade>
- </member>
- <member>
- <name>bppl2</name>
- <age>20</age>
- <grade>75</grade>
- </member>
- </root>
在输入文件中(文件类型为xml文件),存放话务员的基本信息。该文件中的话务员信息是乱序并且有可能重复的,现在需要输出每位话务员的信息,对于重复的信息只能输出一次。要求如下:
1、需要把话务员信息使用集合类缓存起来,并且集合中的信息必须唯一(姓名+年龄唯一)。
2、输出话务员信息,输出格式为:姓名(年龄):成绩|姓名(年龄):成绩,依次按照成绩、姓名、年龄升序排列。
3、启动两个线程分别做如下处理:
线程一:对于话务员年龄小于(包含)18岁的,成绩统一加10分。并把话务员信息依次按照成绩、姓名、年龄升序的方式输出到一个队列中。队列的大小不能超过10个。
线程二: 现有两个分公司(A,B)依次选择话务员,如:A选择第一个话务员后,B再选择一个,依次类推,直到话务员被选完。最后,分别输出A,B两个分公司所选择的话务员信息,输出格式为:姓名(年龄):成绩|姓名(年龄):成绩,依次按照成绩、姓名、年龄升序排列。
控制台输出:
1、输出话务员信息,输出格式为:姓名(年龄):成绩|姓名(年龄):成绩,依次按照成绩、姓名、年龄升序排列。
2、输出分公司A选择的话务员信息,输出格式为:姓名(年龄):成绩|姓名(年龄):成绩,依次按照成绩、姓名、年龄升序排列。
3、输出分公司B选择的话务员信息,,输出格式为:姓名(年龄):成绩|姓名(年龄):成绩,依次按照成绩、姓名、年龄升序排列。
上面输出的结果为:
Appl2(20):70|Jack1(18):70|Adpl2(20):73|bppl2(20):75|ccpl2(20):75
Appl2(20):70|bppl2(20):75|Jack1(18):80
Adpl2(20):73|ccpl2(20):75
分析:题目要求 XML 文档
1、将话务员数据从xml 文件 读取出来 ------ Java 对象 ----- 很多 话务员 ----- Java对象 集合
* 集合中的信息必须唯一(姓名+年龄唯一) ---- java 对象使用姓名+年龄 排重
2、输出话务员信息 --- 依次按照成绩、姓名、年龄升序排列
Appl2(20):70|Jack1(18):70|Adpl2(20):73|bppl2(20):75|ccpl2(20):75
Appl2(20):70|Jack1(18):70|Adpl2(20):73|bppl2(20):75|ccpl2(20):75|
3、线程一:对于话务员年龄小于(包含)18岁的,成绩统一加10分。并把话务员信息依次按照成绩、姓名、年龄升序的方式输出到一个队列中。队列的大小不能超过10个。
4、线程二: 现有两个分公司(A,B)依次选择话务员 ,输出格式为:姓名(年龄):成绩|姓名(年龄):成绩,依次按照成绩、姓名、年龄升序排列。
注:
HashSet --- 排重集合 排重hashCode 和 equals
TreeSet ---- 即排重又排序集合 排重和排序 通过compareTo
* 当排重和排序字段相同时 ---TreeSet ,否则不可以用TreeSet
Comparable<E>接口中的排序方法 ---- public int compareTo(E o):
前-后 升序
后-前 降序
代码示例:
Member.java:
- package mytest;
-
- public class Member implements Comparable<Member>, Cloneable {
- private String name;
- private int age;
- private int grade;
-
- @Override
- public int hashCode() {
- final int prime = 31;
- int result = 1;
- result = prime * result + age;
- result = prime * result + ((name == null) ? 0 : name.hashCode());
- return result;
- }
-
- @Override
- public boolean equals(Object obj) {
- if (this == obj)
- return true;
- if (obj == null)
- return false;
- if (getClass() != obj.getClass())
- return false;
- Member other = (Member) obj;
- if (age != other.age)
- return false;
- if (name == null) {
- if (other.name != null)
- return false;
- } else if (!name.equals(other.name))
- return false;
- return true;
- }
-
- public String getName() {
- return name;
- }
-
- public void setName(String name) {
- this.name = name;
- }
-
- public int getAge() {
- return age;
- }
-
- public void setAge(int age) {
- this.age = age;
- }
-
- @Override
- public int compareTo(Member o) {
- // 升序 当前元素 - 传入元素 值
- // 成绩升序
- int result1 = this.getGrade() - o.getGrade();
- if (result1 == 0) {
- // 姓名升序
- int result2 = this.name.compareTo(o.name);
- if (result2 == 0) {
- // 年龄升序
- int result3 = this.age - o.age;
- return result3;
- } else {
- return result2;
- }
- } else {
- return result1;
- }
- }
-
- public void setGrade(int grade) {
- this.grade = grade;
- }
-
- public int getGrade() {
- return grade;
- }
-
- @Override
- public Object clone() throws CloneNotSupportedException {
- return super.clone();
- }
- }
MemberTest.java
- package mytest;
-
- import java.util.ArrayList;
- import java.util.HashSet;
- import java.util.LinkedList;
- import java.util.List;
- import java.util.Queue;
- import java.util.Set;
- import java.util.TreeSet;
-
- import javax.xml.parsers.DocumentBuilder;
- import javax.xml.parsers.DocumentBuilderFactory;
-
- import org.w3c.dom.Document;
- import org.w3c.dom.Element;
- import org.w3c.dom.NodeList;
-
- public class MemberTest {
- public static void main(String[] args) throws Exception {
- // 第一问 读取xml数据进行排重
- // 将xml中数据 保存 Member对象集合
- Set<Member> members = new HashSet<Member>();
-
- // 读取xml --- JAXP DOM
- DocumentBuilderFactory builderFactory = DocumentBuilderFactory
- .newInstance();
- DocumentBuilder builder = builderFactory.newDocumentBuilder();
- Document document = builder.parse("member.xml");
-
- // 每一个<member>标签 对应 member
- NodeList nodeList = document.getElementsByTagName("member");
- for (int i = 0; i < nodeList.getLength(); i++) {
- Element memberElement = (Element) nodeList.item(i);
- Member member = new Member();
- // 第二个元素 name
- member.setName(memberElement.getChildNodes().item(1)
- .getTextContent());
- // 第四个元素 age
- member.setAge(Integer.parseInt(memberElement.getChildNodes()
- .item(3).getTextContent()));
- // 第六个元素 grade
- member.setGrade(Integer.parseInt(memberElement.getChildNodes()
- .item(5).getTextContent()));
-
- // 将 member存入集合
- members.add(member);
- }
- // 检查第一问结果:输出应该是5
- //System.out.println(members.size());
-
- // 第二问 ,对 Set中member数据进行排序
- Set<Member> sortMembers = new TreeSet<Member>();
- sortMembers.addAll(members);
- for (Member member : sortMembers) {
- System.out.print(member.getName() + "(" + member.getAge() + "):"
- + member.getGrade() + "|");
- }
- System.out.println();
-
- // 第三问
- // ,对于话务员年龄小于(包含)18岁的,成绩统一加10分。
- //并把话务员信息依次按照成绩、姓名、年龄升序的方式输出到一个队列中。
- //队列的大小不能超过10个
- new Thread(new MyThread1(sortMembers)).start();
-
- // 第四问 模拟选人
- Runnable a = new MyThread2(sortMembers, "A");
- Runnable b = new MyThread2(sortMembers, "B");
-
- new Thread(a).start();
- new Thread(b).start();
- }
- }
-
- class MyThread2 implements Runnable {
-
- private static List<Member> members;//static保证唯一
- private String companyName;
-
- private static boolean aturn = true;//static保证唯一
-
- public MyThread2(Set<Member> members, String companyName) {
- // 将set中元素转存List中,实现有序取出元素remove(index)
- this.members = new ArrayList<Member>();
- this.members.addAll(members);
-
- this.companyName = companyName;
- }
-
- @Override
- public void run() {
- synchronized (members) {
- while (members.size() != 0) {
- // System.out.println(companyName + "执行");
- if (aturn && companyName.equals("A")) {
- Member m = members.remove(0);
- System.out.println("A公司选择:" + m.getName());
-
- aturn = false;
- members.notify();
- try {
- System.out.println("A 等待");
- members.wait();
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- if (!aturn && companyName.equals("B")) {
- Member m = members.remove(0);
- System.out.println("B公司选择:" + m.getName());
-
- aturn = true;
- members.notify();
- try {
- System.out.println("B 等待");
- members.wait();
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- }
- }
- System.exit(0);
- }
-
- }
-
- class MyThread1 implements Runnable {
-
- private Set<Member> members;
- private Queue<Member> queue = new LinkedList<Member>();
-
- public MyThread1(Set<Member> members) {
- this.members = members;
- }
-
- @Override
- public void run() {
- // 加分排序
- Set<Member> sortMembers = new TreeSet<Member>();
-
- // 遍历原来的集合
- for (Member member : members) {
- if (member.getAge() <= 18) {
- // 加分 ---不能在原来对象里加分
- Member m = null;
- try {
- m = (Member) member.clone();
- m.setGrade(m.getGrade() + 10);
- sortMembers.add(m);
- } catch (CloneNotSupportedException e) {
- e.printStackTrace();
- }
- } else {
- // 不需要克隆
- sortMembers.add(member);
- }
- }
-
- for (Member member : sortMembers) {
- System.out.print(member.getName() + "(" + member.getAge() + "):"
- + member.getGrade() + "|");
- // 加入队列
- queue.add(member);
- }
- System.out.println();
- }
- }
<script>
(function(){
function setArticleH(btnReadmore,posi){
var winH = $(window).height();
var articleBox = $("div.article_content");
var artH = articleBox.height();
if(artH > winH*posi){
articleBox.css({
'height':winH*posi+'px',
'overflow':'hidden'
})
btnReadmore.click(function(){
articleBox.removeAttr("style");
$(this).parent().remove();
})
}else{
btnReadmore.parent().remove();
}
}
var btnReadmore = $("#btn-readmore");
if(btnReadmore.length>0){
if(currentUserName){
setArticleH(btnReadmore,3);
}else{
setArticleH(btnReadmore,1.2);
}
}
})()
</script>
</article>

