

Java7任务并行执行神器:Fork&Join框架
Java7任务并行执行神器:Fork&Join框架
<span class="tags-box artic-tag-box">
<span class="label">标签:</span>
<a data-track-click="{"mod":"popu_626","con":"JAVA"}" class="tag-link" href="http://so.csdn.net/so/search/s.do?q=JAVA&t=blog" target="_blank">JAVA </a><a data-track-click="{"mod":"popu_626","con":"FORKJOIN"}" class="tag-link" href="http://so.csdn.net/so/search/s.do?q=FORKJOIN&t=blog" target="_blank">FORKJOIN </a>
<span class="article_info_click">更多</span></span>
<div class="tags-box space">
<span class="label">个人分类:</span>
<a class="tag-link" href="https://blog.csdn.net/youanyyou/article/category/695509" target="_blank">Java </a>
</div>
</div>
<div class="operating">
</div>
</div>
</div>
</div>
<article>
<div id="article_content" class="article_content clearfix csdn-tracking-statistics" data-pid="blog" data-mod="popu_307" data-dsm="post">
<div class="article-copyright">
版权声明:转载请注明原文链接,非法转载者将追究其法律责任。 https://blog.csdn.net/youanyyou/article/details/78990280 </div>
<div class="markdown_views">
<!-- flowchart 箭头图标 勿删 -->
<svg xmlns="http://www.w3.org/2000/svg" style="display: none;"><path stroke-linecap="round" d="M5,0 0,2.5 5,5z" id="raphael-marker-block" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);"></path></svg>
<h4 id="forkjoin是什么">Fork/Join是什么?</h4>
Fork/Join框架是Java7提供的并行执行任务框架,思想是将大任务分解成小任务,然后小任务又可以继续分解,然后每个小任务分别计算出结果再合并起来,最后将汇总的结果作为大任务结果。其思想和MapReduce的思想非常类似。对于任务的分割,要求各个子任务之间相互独立,能够并行独立地执行任务,互相之间不影响。
Fork/Join的运行流程图如下:

我们可以通过Fork/Join单词字面上的意思去理解这个框架。Fork是叉子分叉的意思,即将大任务分解成并行的小任务,Join是连接结合的意思,即将所有并行的小任务的执行结果汇总起来。

工作窃取算法
ForkJoin采用了工作窃取(work-stealing)算法,若一个工作线程的任务队列为空没有任务执行时,便从其他工作线程中获取任务主动执行。为了实现工作窃取,在工作线程中维护了双端队列,窃取任务线程从队尾获取任务,被窃取任务线程从队头获取任务。这种机制充分利用线程进行并行计算,减少了线程竞争。但是当队列中只存在一个任务了时,两个线程去取反而会造成资源浪费。
工作窃取的运行流程图如下:

Fork/Join核心类
Fork/Join框架主要由子任务、任务调度两部分组成,类层次图如下。
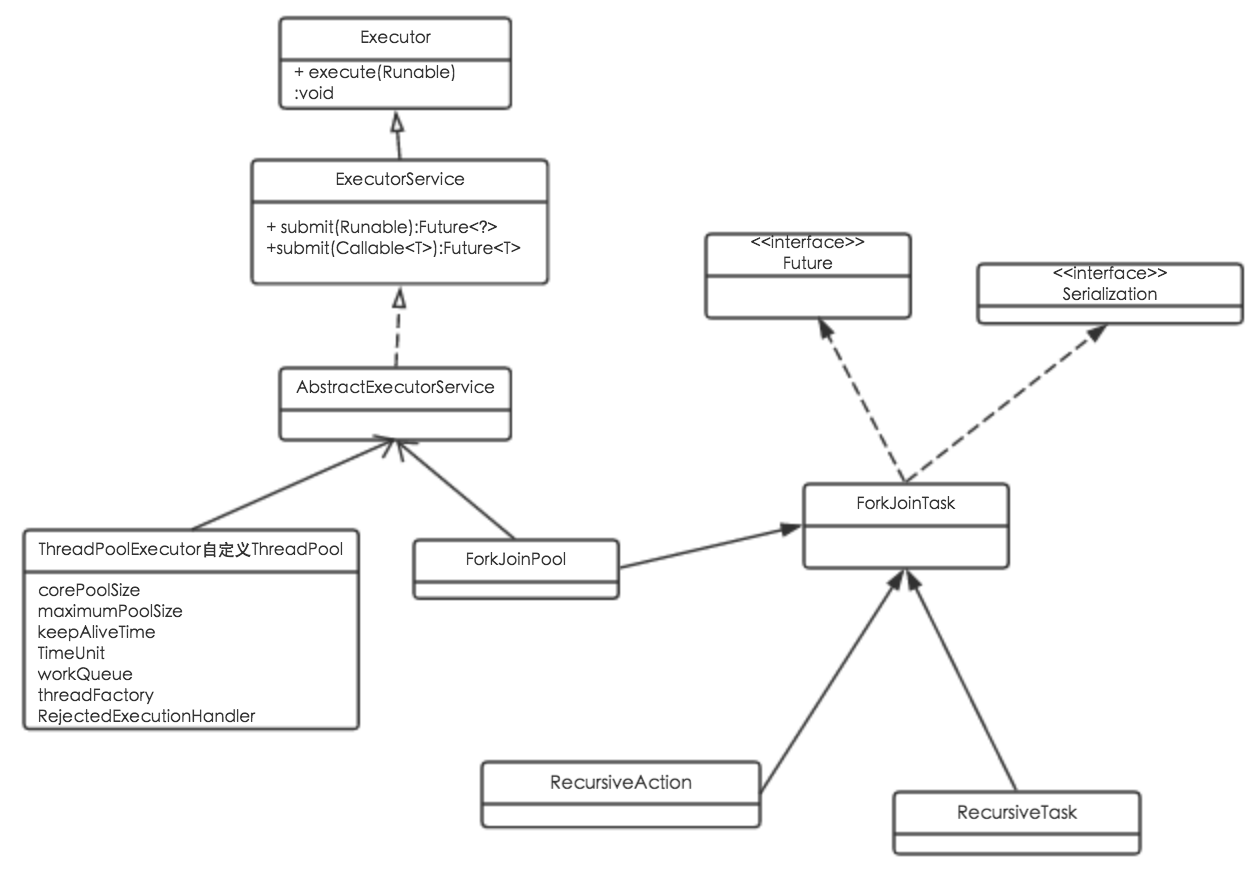
- ForkJoinPool
ForkJoinPool是ForkJoin框架中的任务调度器,和ThreadPoolExecutor一样实现了自己的线程池,提供了三种调度子任务的方法:
- execute:异步执行指定任务,无返回结果;
- invoke、invokeAll:异步执行指定任务,等待完成才返回结果;
submit:异步执行指定任务,并立即返回一个Future对象;
- ForkJoinTask
Fork/Join框架中的实际的执行任务类,有以下两种实现,一般继承这两种实现类即可。
- RecursiveAction:用于无结果返回的子任务;
- RecursiveTask:用于有结果返回的子任务;
Fork/Join框架实战
下面实现一个Fork/Join小例子,从1+2+…10亿,每个任务只能处理1000个数相加,超过1000个的自动分解成小任务并行处理;并展示了通过不使用Fork/Join和使用时的时间损耗对比。
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
public class ForkJoinTask extends RecursiveTask<Long> {
private static final long MAX = 1000000000L;
private static final long THRESHOLD = 1000L;
private long start;
private long end;
public ForkJoinTask(long start, long end) {
this.start = start;
this.end = end;
}
public static void main(String[] args) {
test();
System.out.println("--------------------");
testForkJoin();
}
private static void test() {
System.out.println("test");
long start = System.currentTimeMillis();
Long sum = 0L;
for (long i = 0L; i <= MAX; i++) {
sum += i;
}
System.out.println(sum);
System.out.println(System.currentTimeMillis() - start + "ms");
}
private static void testForkJoin() {
System.out.println("testForkJoin");
long start = System.currentTimeMillis();
ForkJoinPool forkJoinPool = new ForkJoinPool();
Long sum = forkJoinPool.invoke(new ForkJoinTask(1, MAX));
System.out.println(sum);
System.out.println(System.currentTimeMillis() - start + "ms");
}
@Override
protected Long compute() {
long sum = 0;
if (end - start <= THRESHOLD) {
for (long i = start; i <= end; i++) {
sum += i;
}
return sum;
} else {
long mid = (start + end) / 2;
ForkJoinTask task1 = new ForkJoinTask(start, mid);
task1.fork();
ForkJoinTask task2 = new ForkJoinTask(mid + 1, end);
task2.fork();
return task1.join() + task2.join();
}
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
这里需要计算结果,所以任务继承的是RecursiveTask类。ForkJoinTask需要实现compute方法,在这个方法里首先需要判断任务是否小于等于阈值1000,如果是就直接执行任务。否则分割成两个子任务,每个子任务在调用fork方法时,又会进入compute方法,看看当前子任务是否需要继续分割成孙任务,如果不需要继续分割,则执行当前子任务并返回结果。使用join方法会阻塞并等待子任务执行完并得到其结果。
程序输出:
test
500000000500000000
4992ms
--------------------
testForkJoin
500000000500000000
508ms- 1
- 2
- 3
- 4
- 5
- 6
- 7
从结果看出,并行的时间损耗明显要少于串行的,这就是并行任务的好处。
尽管如此,在使用Fork/Join时也得注意,不要盲目使用。
- 如果任务拆解的很深,系统内的线程数量堆积,导致系统性能性能严重下降;
- 如果函数的调用栈很深,会导致栈内存溢出;
推荐阅读
分享Java干货,高并发编程,热门技术教程,微服务及分布式技术,架构设计,区块链技术,人工智能,大数据,Java面试题,以及前沿热门资讯等。
<script>
(function(){
function setArticleH(btnReadmore,posi){
var winH = $(window).height();
var articleBox = $("div.article_content");
var artH = articleBox.height();
if(artH > winH*posi){
articleBox.css({
'height':winH*posi+'px',
'overflow':'hidden'
})
btnReadmore.click(function(){
articleBox.removeAttr("style");
$(this).parent().remove();
})
}else{
btnReadmore.parent().remove();
}
}
var btnReadmore = $("#btn-readmore");
if(btnReadmore.length>0){
if(currentUserName){
setArticleH(btnReadmore,3);
}else{
setArticleH(btnReadmore,1.2);
}
}
})()
</script>
</article>
