
EQueue - 一个纯C#写的分布式消息队列介绍2
一年前,当我第一次开发完EQueue后,写过一篇文章介绍了其整体架构,做这个框架的背景,以及架构中的所有基本概念。通过那篇文章,大家可以对EQueue有一个基本的了解。经过了1年多的完善,EQueue无论是功能上还是成熟性上都完善了不少。所以,希望再写一篇文章,介绍一下EQueue的整体架构和关键特性。
EQueue架构
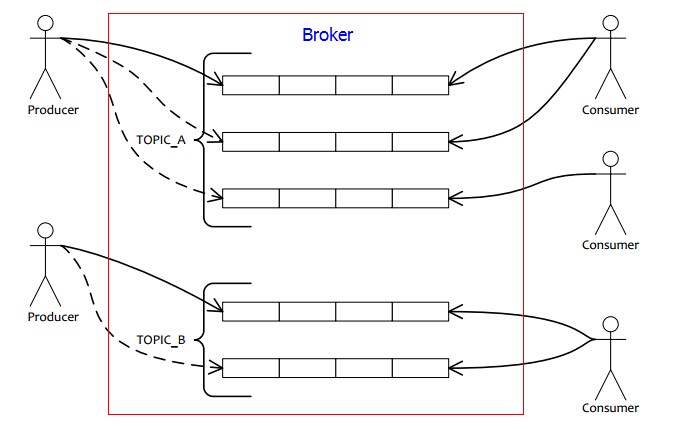
EQueue是一个分布式的、轻量级、高性能、具有一定可靠性,纯C#编写的消息队列,支持消费者集群消费模式。
主要包括三个部分:producer, broker, consumer。producer就是消息发送者;broker就是消息队列服务器,负责接收producer发送过来的消息,以及持久化消息;consumer就是消息消费者,consumer从broker采用拉模式到broker拉取消息进行消费,具体采用的是long polling(长轮训)的方式。这种方式的最大好处是可以让broker非常简单,不需要主动去推消息给consumer,而是只要负责持久化消息即可,这样就减轻了broker server的负担。同时,consumer由于是自己主动去拉取消息,所以消费速度可以自己控制,不会出现broker给consumer消息推的太快导致consumer来不及消费而挂掉的情况。在消息实时性方面,由于是长轮训的方式,所以消息消费的实时性也可以保证,实时性和推模型基本相当。
EQueue是面向topic的架构,和传统的MSMQ这种面向queue的方式不同。使用EQueue,我们不需要关心queue。producer发送消息时,指定的是消息的topic,而不需要指定具体发送到哪个queue。同样,consumer发送消息也是一样,订阅的是topic,不需要关心自己想从哪个queue接收消息。然后,producer客户端框架内部,会根据当前的topic获取所有可用的queue,然后通过某种queue select strategy选择一个queue,然后把消息发送到该queue;同样,consumer端,也会根据当前订阅的topic,获取其下面的所有的queue,以及当前所有订阅这个topic的consumer,按照平均的方式计算出当前consumer应该分配到哪些queue。这个分配的过程就是消费者负载均衡。
Broker的主要职责是:
发送消息时:负责接收producer的消息,然后持久化消息,然后建立消息索引信息(把消息的全局offset和其在queue中的offset简历映射关系),然后返回结果给producer;
消费消息时:负责根据consumer的pull message request,查询一批消息(默认是一次pull request拉取最多32个消息),然后返回给consumer;
各位看官如果对EQueue中的一些基本概念还不太清楚,可以看一下我去年写的介绍1,写的很详细。下面,我想介绍一下EQueue的一些有特色的地方。
EQueue关键特性
高性能与可靠性设计
网络通信模型,采用.NET自带的SocketAsyncEventArgs,内部基于Windows IOCP网络模型。发送消息支持async, sync, oneway三种模式,无论是哪种模式,内部都是异步模式。当同步发送消息时,就是框架帮我们在异步发送消息后,同步等待消息发送结果,等到结果返回后,才返回给消息发送者;如果一定时间还不返回,则报超时异常。在异步发送消息时,采用从EventStore开源项目中学习到的优秀的socket消息发送设计,目前测试下来,性能高效、稳定。通过几个案例运行很长时间,没有出现通信层方面的问题。
broker消息持久化的设计。采用WAL(Write-Ahead Log)技术,以及异步批量持久化到SQL Server的方式确保消息高效持久化且不会丢。消息到达broker后,先写入本地日志文件,这种设计在db, nosql等数据库中很常见,都是为了确保消息或请求不丢失。然后,再异步批量持久化消息到SQL Server,采用.NET自带的SqlBulkCopy技术。这种方式,我们可以确保消息持久化的实时性和很高的吞吐量,因为一条消息只要写入本地日志文件,然后放入内存的一个dict即可。
当broker意外宕机,可能会有一些消息还没持久化到SQL Server;所以,我们在重启broker时,我们除了先从SQL Server恢复所有未消费的消息到内存外,同时记录当前SQL Server中的最后一条消息的offset,然后我们从本地日志文件扫描offset+1开始的所有消息,全部恢复到SQL Server以及内存。
需要简单提一下的是,我们在把消息写入到本地日志文件时,不可能全部写入到一个文件,所以要拆文件。目前是根据log4net来写消息日志,每100MB一个日志文件。为什么是100MB?是因为,我们的这个消息日志文件的用途主要是用来在Broker重启时,恢复SQL Server中最后还没来得及持久化的那些消息的。正常情况下,这些消息量应该不会很多。所以,我们希望,当扫描本地日志文件时,尽量能快速的扫描文件。通常100MB的消息日志文件,已经可以存储不少的消息量,而SQL Server中未持久化的消息通常不会超过这个量,除非当机前,出现长时间消息无法持久化的情况,这种情况,应该会被我们监控到并及时发现,并采取措施。当然,每个消息日志文件的大小,可以支持配置。另外一点,就是从日志文件恢复的时候,还是需要有一个算法的,因为未被持久化的消息,有可能不只在最近的一个消息日志文件里,有可能在多个日志文件里,因为就像前面所说,会出现大量消息没有持久化到SQL Server的情况。
但总之,在保证高性能的前提下,消息不丢(可靠性)是完全可以保证的。
消费消息方面,采用批量拉取消息进行消费的方式。默认consumer一个pull message request会最多拉取32个消息(只要存在这么多未消费消息的话);然后consumer会并行消费这些消费,除了并行消费外,也可以配置为单线程线性消费。broker在查询消息时,一般情况未消费消息总是在内存的,只有有一种情况不在内存,这个下面详细分析。所以,查询消息应该说非常快。
不过上面提到的消息可靠性,只能尽量保证单机不丢消息。由于消息是放在DB,以及本地日志。所以,如果DB服务器硬盘坏了,或者broker的硬盘坏了,那就会有丢消息的可能性。要解决这个问题,就需要做replication了。EQueue下一步会支持broker的集群和故障转移(failover)。目前,我开发了一个守护进程服务,会监控broker进程是否挂掉,如果挂掉,则自动重启,一定程度上也会提高broker的可用性。
我觉得,做事情,越简单越好,不要一开始就搞的太复杂。复杂的东西,往往难以维护和驾驭,虽然理论很美好,但总是会出现各种问题,呵呵。就像去中心化的架构虽然理论好像很美好,但实际使用中,发现还是中心化的架构更好,更具备实战性。
支持消费者负载均衡
消费者负载均衡是指某个topic的所有消费者,可以平均消费这个topic下的所有queue。我们使用消息队列,我认为这个特性非常重要。设想,某一天,我们的网站搞了一个活动,然后producer产生的消息猛增。此时,如果我们的consumer服务器如果还是只有原来的数量,那很可能会来不及处理这么多的消息,导致broker上的消息大量堆积。最终会影响用户请求的响应时间,因为很多消息无法及时被处理。
所以,遇到这种情况,我们希望分布式消息队列可以方便的允许我们动态添加消费者机器,提高消费能力。EQueue支持这样的动态扩展能力。假如某个topic,默认有4个queue,然后每个queue对应一台consumer机器进行消费。然后,我们希望增加一倍的consumer时,只要在EQueue Web控制台上,为这个topic增加4个queue,然后我们再新增4台consumer机器即可。这样EQueue客户端会支持自动负载均衡,几秒钟后,8个consumer就可以各自消费对应的queue了。然后,当活动过后,消息量又会回退到正常水平,那么我们就可以再减少queue,并下线多余的consumer机器。
另外,EQueue还充分考虑到了下线queue时的平滑性,可以支持先冻结某个queue,这样可以确保不会有新的消息发送到该queue。然后我们等到这个queue的消息都消费完后,就可以下线consumer机器和删除该queue了。这点,应该说,阿里的rocketmq也没有做到,呵呵。
broker支持大量消息堆积
这个特性,我之前专门写过一篇文章,详细介绍设计思路,这里也简单介绍一下。MQ的一个很重要的作用就是削峰,就是在遇到一瞬间大量消息产生而消费者来不及一下子消费时,消息队列可以起到一个缓冲的作用,从而可以确保消息消费者服务器不会垮掉,这个就是削峰。如果使用RPC的方式,那最后所有的请求,都会压倒DB,DB就会承受不了这么多的请求而挂掉。
所以,我们希望MQ支持消息堆积的能力,不能因为为了快,而只能支持把消息放入服务器内存。因为服务器内存的大小是有限的,假设我们的消息服务器内存大小是128G,每个消息大小为1KB,那差不多最多只能堆积1.3亿个消息。不过一般来说1.3亿也够了,呵呵。但这个毕竟要求大内存作为前提的。但有时我们可能没有那么大的服务器内存,但也需要堆积这么多的消息的能力。那就需要我们的MQ在设计上也提供支持。EQueue可以允许我们在启动时配置broker服务器上允许在内存里存放的消息数以及消息队列里消息的全局offset和queueOffset的映射关系(我称之为消息索引信息)的数量。我们可以根据我们的服务器内存的大小进行配置。然后,broker上会有定时的扫描线程,定时扫描是否有多出来的消息和消息索引,如果有,则移除多出来的部分。通过这个设计,可以确保服务器内存一定不会用完。但是否要移除也有一个前提,就是必须要求这个消息已经持久化到SQL Server了。否则就不能移除。这个应该通常可以保证,因为一般不会出现1亿个消息都还没持久化到DB,如果出现这个情况,说明DB一定出了什么严重的问题,或者broker无法与db建立连接了。这种情况下,我们应该早就已经发现了,EQueue Web监控控制台上随时可以查看消息的最大全局offset,已经持久化的最大全局offset。
上面这个设计带来的一个问题是,假如现在consumer要拉取的消息不在内存了怎么办?一种办法是从DB把这个消息拉取到内存,但一条条拉,肯定太慢了。所以,我们可以做一个优化,就是发现当前消息不在内存时,因为很可能下一条消息也不在内存,所以我们可以一次性从Sql Server DB拉取10000个消息(可配置),这样后续的10000个消息就一定在内存了,我们需要再访问DB。这个设计其实是在内存使用和拉取消息性能之间的一个权衡后的设计。Linux的pagecache的目的也是这个。
另外一点,就是我们broker重启时,不能全部把所有消息都恢复到内存,而是要判断是否已经到达内存可以承受的最大消息数了。如果已经到达,那就不能再放入内存了;同理,消息索引信息的恢复也是一样。否则,在消息堆积过多的时候,就会导致broker重启时,内存爆掉了。
消息消费进度更新的设计
EQueue的消息消费进度的设计,和kafka, rocketmq是一个思路。就是定时保存每个queue的消费进度(queue consumed offset),一个long值。这样设计的好处是,我们不用每次消费完一个消息后,就立即发送一个ack回复消息到broker。如果是这样,对broker的压力是很大的。而如果只是定时发送一个消费进度,那对broker的压力很小。那这个消费进度怎么来?就是采用滑动门技术。就是consumer端,在拉取到一批消息后,先放入本地内存的一个SortedDictionary里。然后继续去拉下一批消息。然后会启动task去并行消费这些刚刚拉取到的消息。所以,这个本地的SortedDictionary就是存放了所有已经拉取到本地但还没有被消费掉的消息。然后当某个task thread消费掉一个消息后,会把它从SortedDictionary中移除。然后,我上面所说的滑动门技术,就是指,在每次移除一个消息后,获取当前SortedDictionary里key最小的那个消息的queue offset。随着消息的不断消费,这个queue offset也会不断增大,从宏观的角度看来,就像是一扇门在不停的往前移动。
但这个设计有个问题,就是假如这个Dict里,有一个offset=100的消息一直没被消费掉,那就算后面的消息都被消费了,最后这个滑动门还是不会前进。因为这个dict里的最后的那个queue offset总是100。这个应该好理解的吧。所以这种情况下,当consumer重启后,下次消费的位置还是会从100开始,后面的也会重新消费一遍。所以,我们的消费者内部,需要都支持幂等处理消息。
支持消息回溯
因为broker上的消息,不是消息消费掉了就立即删除,而是定时删除,比如每2天删除一次(可以配置)。所以,当我们哪天希望重新消费1天前的消息的时候,EQueue也是完全支持的。只要在consumer启动前,修改消费进度到以前的某个特定的值即可。
Web管理控制台
EQueue有一个完善的Web管理控制台,我们可以通过该控制台管理topic,管理queue,查看消息,查看消息消费进度,查看消息堆积情况等信息。但是目前还不支持报警,以后会慢慢增加报警功能。
通过这个控制台,我们使用EQueue就会方便很多,可以实时了解消息队列服务器的健康状况。贴一个管理控制台的UI界面,让大家有个印象:

EQueue未来的计划
- broker支持集群,master-slave模式,使其具备更高的可用性和扩展性;
- Web管理控制台支持报警;
- 出一份性能测试报告,目前我主要是没有实际服务器,没办法实际测试;
- 考虑支持非DBC持久化的支持,比如本地key/value存储支持,或者完全的本地文件持久化消息(难度很大);
- 其他小功能完善和代码局部调整;
我相信:没有做不好,只有没耐心。



