stackoverflow:Purpose of memory align/内存对齐的目的(原文+翻译)
原文:https://stackoverflow.com/questions/381244/purpose-of-memory-alignment
翻译:joey
The memory subsystem on a modern processor is restricted to accessing memory at the granularity and alignment of its word size; this is the case for a number of reasons.
现代处理器上的内存系统,都对于内存存取的粒度和是否对齐有所限制,这就是很多理由的源头。
(译注:本人的理解就是两点,必须从指定的地址开始读取和每次必须读一个字)
Speed 速度
Modern processors have multiple levels of cache memory that data must be pulled through; supporting single-byte reads would make the memory subsystem throughput tightly bound to the execution unit throughput(aka cpu-bound); this is all reminiscent of how PIO mode was surpassed by DMA for many of the same reasons in hard drives.
现代处理器都有多级缓存,数据必须经过这些缓存。由于要支持单字节的存取,使得内存系统的吞吐量和执行单元(EU)的吞吐量密切相关(又名:cpu-bound)。这让人联想起编程实现IO(PIO)模式是怎样被直接内存存取(DMA)取代的,在许多硬件中也是因为如上相同的理由。
The CPU always reads at its word size(4 bytes on a 32-bit processor), so when you do a unaligned address access -- on a processor that supports it -- the processor is going to read multiple words. The CPU will read each word of memory that your requested address straddles. This causes an amplification of up to 2X the number of memory transactions required to access the requested data.
CPU总是一次读取一个字的数据(对于一个32位的处理器,一个字是4字节,64位则是8字节),所以当你进行一次非对齐的内存存取时——如果处理器支持的话(译注:有的处理器不支持非对齐的内存存取)——处理器会从内存中读取多个字。CPU会读取每个你请求读取的变量横跨过的单元,这就造成了在请求存取指定数据的时候(可以是float,double等),至多会有相较于对齐时2倍的内存单元访问量。
Because of this, it can very easily be slower to read two bytes than four. For example, say you have a struct in memory that looks like this:
正因为这样,读取两个字节很容易就可以比读四个字节慢。比如,假设在内存中有一个如下的结构体:
(译注:比如两个字节是分散在两个不对齐的word里,就要读取两次,而如果四个字节都在一个对齐的word里,就只需要读取一次)
struct mystruct {
char c; // one byte
int i; // four bytes
short s; // two bytes
}
On a 32-bit processor it would most likely be aligned like shown here:
在32位机上,对齐后内存布局大概像这样:
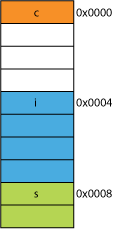
The processor can read each of these members in on transaction.
对于每个成员变量,处理器通过读取一个字(word)都可以读到。
Say you had a packed version of the struct, maybe from the network where is was packed for transmission efficiency, it might look something like this:
假如你有一个“拥挤版”的结构体(译注:个人认为就是未对齐的版本),可能对于网络传输来说,是为了传输效率,可能看起来像这样:
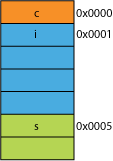
Reading the first byte is going to be the same.
读char c的时候,未对齐版本和对齐版本是一样的。
When you ask the processor to give you 16bits form 0x0005 it will have to read a word from 0x004 and shift left 1 byte to place it in a 16-bit register, some extra work, but most can handle that in one cycle.
当你让处理器从0x0005给你16位数据时,它会从0x0004开始,读取一个字,并把数据左移(<<)一8位,以便将其放入一个16位的寄存器里,此外还有些额外的工作,但是几乎都可以在一个周期内(译注:总线周期?)完成。
When you ask for 32bits from 0x0001 you'll get a 2X amplification. The processor will read from 0x0000 into the result register and shift left 1 byte, then read again from 0x0004 into a temporary register, shift right 3 bytes, then OR it with the result register.
当你从0x0001请求32位数据时,这将会是双倍的开销。处理器会首先从0x0000开始读取数据放入结果寄存器,并将其左移8位,然后再从0x0004开始读取,把数据放入暂存寄存器里,并将数据右移24位,最后将暂存寄存器中的数据与结果寄存器里的数据作“或”运算。
Range 地址范围
For any given address space, if the architecture can assume that the 2 LSBs are always 0 (e.g., 32-bit machines) then it can access 4 times more memory (the 2 saved bits can represent 4 distinct states), Taking the 2 LSBs off of an address would give you a 4-byte alignment; also referred to as a stride of 4 bytes. Each time an address is incremented it is effectively incrementing bit 2, not bit 0, i.e., the last 2 bits will always continue to be 00.
对于给定的地址空间,如果处理器构架可以假设地址的最低两位恒为0(比如32位机),然后它就可以访问四倍大于现在地址空间的内存(因为保留的两位可以表示四个不同的状态)(译注:个人理解为地址线中权重最高的两位都为0了),拿走地址线的最低两位会为你带来4字节的对齐,也可以理解为是一次地址线的变动,地址空间就跨过4个字节。每次地址的增加,都增加的是地址线的bit2,而不是bit0。也就是说,最低两个仍然将一直为00。
This can even affect the physical design of the system. If the address bus needs 2 fewer bits, there can be 2 fewer pins on the CPU, and 2 fewer traces on the circuit board.
这甚至可以影响到系统的物理设计(译注:不就是芯片设计嘛,说那么文绉绉的干嘛)。如果地址总线不需要那两个位,CPU上可以少设计两个引脚,电路板上也可以少走两根线。
Atomicity 原子性
The CPU can operate on an aligned word of memory atomically, meaning that no other instruction can interrupt that operation. This is critical to the correct operation of many lock-free data structures and other concurrency paradigms.
CPU对于内存中已经对齐了的字的操作,是原子的,也就是说没有其他的指令可以打断这个操作,这对于很多无锁数据结构和并发编程范式的正确操作是至关重要的。
Conclusion 总结
The memory system of a processor is quite a bit more complex and involved than described here; a discussion on how an x86 processor actually addresses memory can help (many processors work similarly).
处理器的内存系统比本文描述的要复杂的多,这篇文章可能会有所帮助:how an x86 processor actually addresses memory can help
There are many more benefits to adhering to memory alignment that you can read at this IBM article.
从这篇文章中你可以读到非常多遵守内存对齐的好处。
computer's primary use is to transform data. Modern memory architectures and technologies have been optimized over decades to facilitate getting more data, in, out, and between more and faster execution units–in a highly reliable way.
计算机的首要任务是传输数据,为了促进吞吐吞吐更多数据,现代内存架构和技术已经被优化了几十年,它是一个存在于更多更快的执行单元的一个高度可靠的通道。

