深度学习入门基础概念(2)
转载自CSDN专栏|http://dwz.cn/80rGi5
神经网络基础
13)批次(Batches):在训练神经网络的同时,不用一次发送整个输入,我们将输入分成几个随机大小相等的块。与整个数据集一次性馈送到网络时建立的模型相比,批量训练数据使得模型更加广义化。
14)周期(Epochs):定义为向前和向后传播中所有批次的单次训练迭代。这意味着一个周期是整个输入数据的单次向前和向后传递。
- 你可以自己选择训练网络的周期数量,更多的周期将显示出更高的网络准确性,然而,网络融合也需要更长的时间。
- 需注意的是,如果周期数太高,网络可能会过拟合。
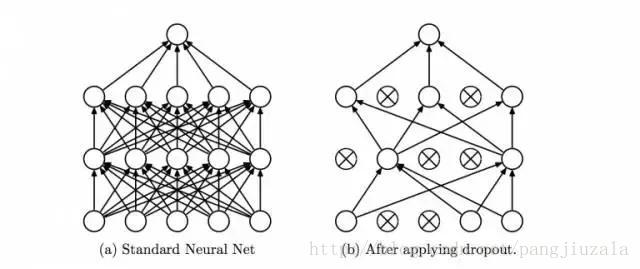
15)丢弃(Dropout):Dropout是一种正则化技术,可防止网络过拟合。顾名思义,在训练期间,隐藏层中的一定数量的神经元被随机地丢弃。
16)批量归一化(Batch Normalization):作为一个概念,批量归一化可以被认为是我们在河流中设定为特定检查点的水坝。这样做是为了确保数据的分发与希望获得的下一层相同。当我们训练神经网络时,权重在梯度下降的每个步骤之后都会改变,这会改变数据的形状如何发送到下一层。但是下一层预期分布类似于之前所看到的分布,所以我们在将数据发送到下一层之前明确规范化数据。
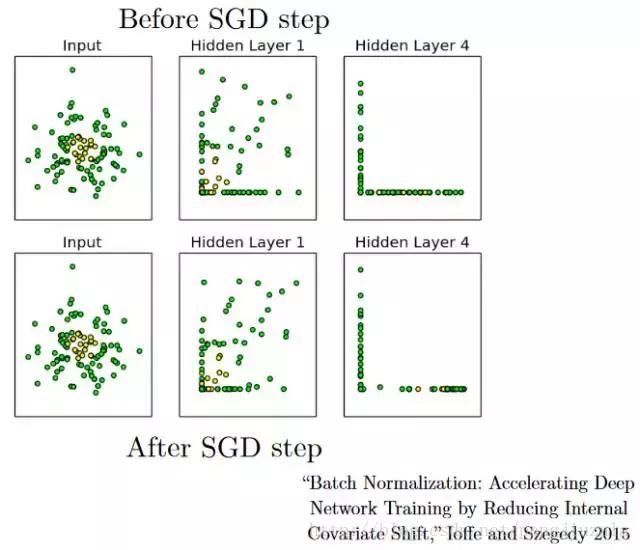
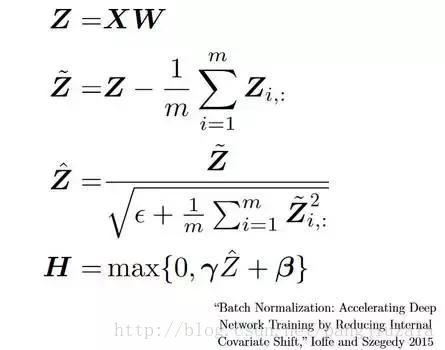
- SGD是指随机梯度下降(Stochastic Gradient Descent,简称SGD),批量梯度下降法(Batch Gradient Descent,简称BGD)在更新每一个参数时,都需要所有的训练样本,从而导致训练过程会随着样本数量的加大而变得异常的缓慢 。为了解决这一弊端,人们提出了SGD,每次迭代只需要一个样本,训练速度快,但准确度有所下降。
- 批量归一化通过减少内部协变量变化加快深度网络训练
卷积神经网络(CNN)
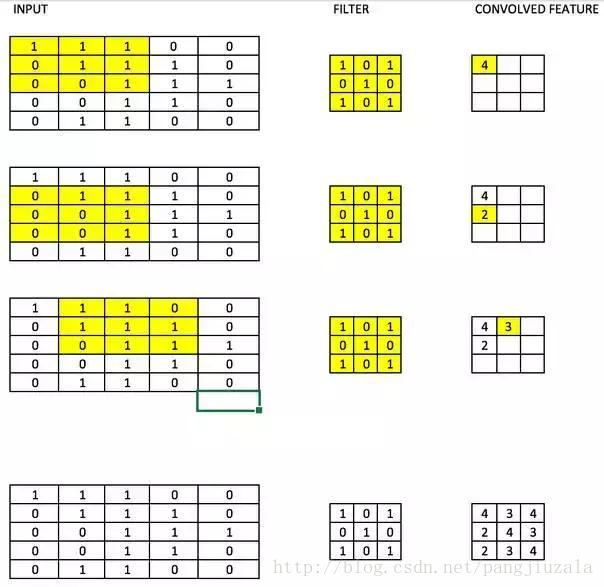
17)滤波器(Filters):CNN中的滤波器与加权矩阵一样,它与输入图像的一部分相乘以产生一个回旋输出。我们假设有一个大小为28*28的图像,我们随机分配一个大小为3*3的滤波器,然后与图像不同的3*3部分相乘,形成所谓的卷积输出。滤波器尺寸通常小于原始图像尺寸。在成本最小化的反向传播期间,滤波器值被更新为重量值。
如下图所示,这里filter是一个3 * 3矩阵,与图像的每个3*3部分相乘以形成卷积特征。
18)卷积神经网络(CNN):卷积神经网络基本上应用于图像数据。假设我们有一个大小为(28*28*3)的输入,如果我们使用正常的神经网络,将有2352(28*28*3)参数。并且随着图像的大小增加,参数的数量变得非常大。我们“卷积”图像以减少参数数量(如上面滤波器定义所示)。当我们将滤波器滑动到输入体积的宽度和高度时,将产生一个二维激活图,给出该滤波器在每个位置的输出。我们将沿深度尺寸堆叠这些激活图,并产生输出量。
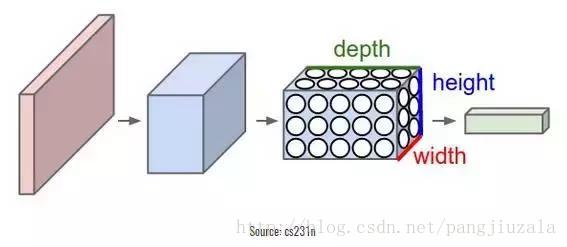
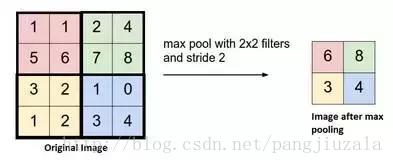
19)池化(Pooling):通常在卷积层之间定期引入池化层。这基本上是为了减少一些参数,并防止过拟合。最常见的池化类型是使用MAX(取最大值)操作的滤波器尺寸(2,2)的池层,它将占用原始图像的每个4*4矩阵的最大值。也可以使用其他操作(如平均池)进行池化,但是最大池数量在实践中表现更好。
20)填充(Padding)
- 相同填充:在图像之间添加额外的零层,以使输出图像的大小与输入相同。在应用滤波器之后,卷积层具有等于实际图像的大小。
- 有效填充:将图像保持为具有实际或“有效”的图像的所有像素。在这种情况下,在应用滤波器之后,输出的长度和宽度的大小在每个卷积层处不断减小。
21)数据增广(Data Augmentation):在深度学习中,有的时候训练集不够多,或者某一类数据较少,或者为了防止过拟合,让模型更加鲁棒性,data augmentation是一个不错的选择。常见的数据增广方法有
- 人工增加训练集的大小. 通过平移, 翻转, 加噪声等方法从已有数据中创造出一批"新"的数据。详细链接
- Regularization. 数据量比较小会导致模型过拟合, 使得训练误差很小而测试误差特别大. 通过在Loss Function 后面加上正则项可以抑制过拟合的产生. 缺点是引入了一个需要手动调整的hyper-parameter. 详细链接
- Dropout. 这也是一种正则化手段. 不过跟以上不同的是它通过随机将部分神经元的输出置零来实现. 详细链接
- Unsupervised Pre-training. 用Auto-Encoder或者RBM的卷积形式一层一层地做无监督预训练, 最后加上分类层做有监督的Fine-Tuning. 详细链接
循环神经网络(RNN)
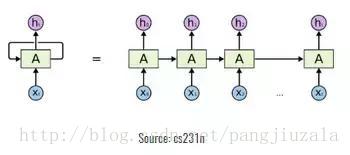
22)循环神经元(Recurrent Neuron):循环神经元是在T时间内将神经元的输出发送回给它。如果你看图,输出将返回输入t次。展开的神经元看起来像连接在一起的t个不同的神经元。这个神经元的基本优点是它给出了更广义的输出。
23)循环神经网络(RNN):循环神经网络特别适用于顺序数据,其中先前的输出用于预测下一个输出。在这种情况下,网络中有循环。隐藏神经元内的循环使他们能够存储有关前一个单词的信息一段时间,以便能够预测输出。隐藏层的输出在t时间戳内再次发送到隐藏层。展开的神经元看起来像上图。只有在完成所有的时间戳后,循环神经元的输出才能进入下一层。发送的输出更广泛,以前的信息保留的时间也较长。
然后根据展开的网络将错误反向传播以更新权重。这被称为通过时间的反向传播(BPTT)。
24)消失梯度问题(Vanishing Gradient Problem):激活函数的梯度非常小的情况下会出现消失梯度问题。在权重乘以这些低梯度时的反向传播过程中,它们往往变得非常小,并且随着网络进一步深入而“消失”。这使得神经网络忘记了长距离依赖。这对循环神经网络来说是一个问题,长期依赖对于网络来说是非常重要的。这可以通过使用不具有小梯度的激活函数ReLu来解决。
25)激增梯度问题(Exploding Gradient Problem):这与消失的梯度问题完全相反,激活函数的梯度过大。在反向传播期间,它使特定节点的权重相对于其他节点的权重非常高,这使得它们不重要。这可以通过剪切梯度来轻松解决,使其不超过一定值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号