Machine Learning_Ng 第7讲 过拟合与正则化
本文首发于https://www.cnblogs.com/jngwl,如需转载,请务必 于文章显要位置处注明原文出处。
# 过拟合问题(The Problem of Overfitting)
1.什么是过拟合
过拟合问题是指训练出来的模型在训练集上表现很好,但在测试集上表现很差。即由于过度拟合原始数据,丢失了算法的本质,泛化能力较差。

2.为什么会产生过拟合问题
(1) 数据有噪声
为什么数据有噪声,就可能导致模型出现过拟合现象呢?
所有的机器学习过程都是一个search假设空间的过程!我们是在模型参数空间搜索一组参数,使得我们的损失函数最小,也就是不断的接近我们的真实假设模型,而真实模型只有知道了所有的数据分布,才能得到。
往往我们的模型是在训练数据有限的情况下,找出使损失函数最小的最优模型,然后将该模型泛化于所有数据的其它部分。这是机器学习的本质!
那好,假设我们的总体数据如下面左图所示,(我这里就假设总体数据分布满足一个线性模型y = kx+b,现实中肯定不会这么简单,数据量也不会这么少,至少也是多少亿级别,但是不影响解释。反正总体数据满足模型y)此时我们得到的部分数据,其中还有噪声的话,如下右图所示:


那么由上面训练数据点训练出来的模型肯定不是线性模型(总体数据分布下满足的标准模型),比如训练出来的模型如下:

如果我拿着这个有噪声训练的模型,在训练集合上通过不断训练,可以做到损失函数值为0,但是拿着这个模型,到真实总体数据分布中(满足线性模型)去泛化,效果会非常差,因为你拿着一个非线性模型去预测线性模型的真实分布,显而易得效果是非常差的,也就产生了过拟合现象!
(2)训练数据不足,有限的训练数据
当我们训练数据不足的时候,即使得到的训练数据没有噪声,训练出来的模型也可能产生过拟合现象。假设我们的总体数据分布如下,为一个二次函数模型吧:


我们得到的训练数据由于是有限的,比如是上面右图。那么由这个训练数据,我得到的模型是一个线性模型,通过训练较多的次数,我可以得到在训练数据使得损失函数为0的线性模型,拿这个模型我去泛化真实的总体分布数据(实际上是满足二次函数模型),很显然,泛化能力是非常差的,也就出现了过拟合现象!
(3)训练模型过度导致模型非常复杂
训练模型过度导致模型非常复杂,也会导致过拟合现象!这点和第一点原因结合起来其实非常好理解,当我们在训练数据训练的时候,如果训练过度,导致完全拟合了训练数据的话,得到的模型不一定是可靠的。
比如说,在有噪声的训练数据中,我们要是训练过度,会让模型学习到噪声的特征,无疑是会造成在没有噪声的真实测试集上准确率下降!
3.怎么解决过拟合问题
(1)丢弃一些不能帮助我们正确预测的特征。可以是手动选择特征,也可以使用一些模型选择的算法(如PCA)
(2)正则化。保留所有所有的特征,但是减少参数的大小(magnitude)
(3)early stopping
(4)数据集扩增(Data augmentation)
# 正则化(Regularization)
1.什么是正则化(What)
正则化(Regularization-Regular-Regularize),顾名思义即规则化,什么是规则?你妈喊你6点前回家吃饭,这就是规则,一个限制。因此,正则化即:给需要训练的目标函数加上一些规则(限制),让他们不要自我膨胀,不要像红色曲线一样想象力过于丰富。
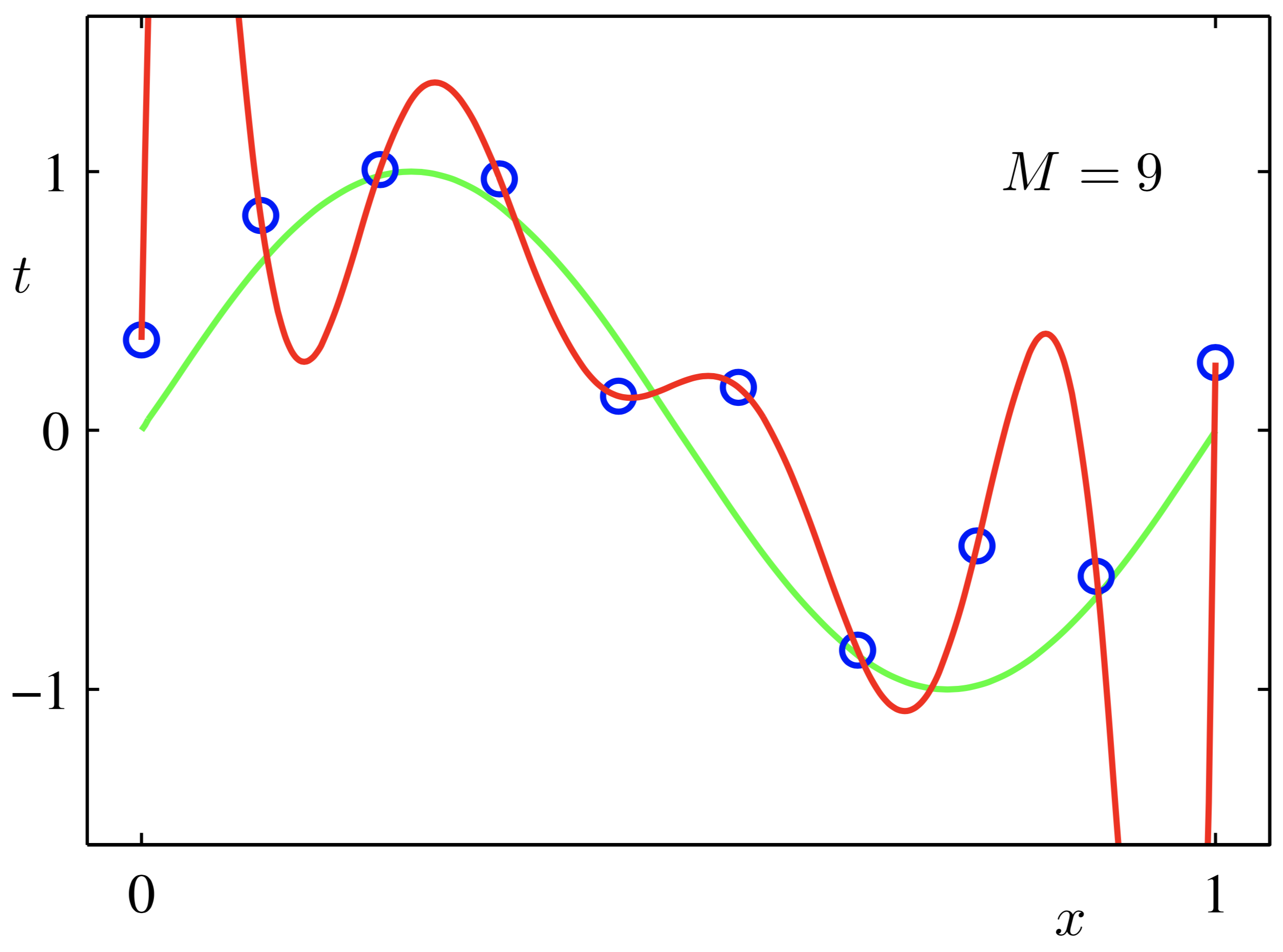
2.为什么要正则化(Why)
在机器学习算法中,我们常常将原始数据集分为三部分:training data、validation data、testing data。这个validation data是什么?它其实就是用来避免过拟合的,在训练过程中,我们通常用它来确定一些超参数(比如根据validation data上的accuracy来确定early stopping的epoch大小、根据validation data确定learning rate等等)。那为啥不直接在testing data上做这些呢?因为如果在testing data做这些,那么随着训练的进行,我们的网络实际上就是在一点一点地overfitting我们的testing data,导致最后得到的testing accuracy没有任何参考意义。因此,training data的作用是计算梯度更新权重,validation data用来确定一些参数以避免过拟合问题,testing data则给出一个accuracy以判断网络的好坏。
过拟合的时候,拟合函数的系数往往非常大,为什么?如上图红色所示,过拟合,就是拟合函数需要顾忌每一个点,最终形成的拟合函数波动很大。在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。而正则化是通过约束参数的范数使其不要太大,所以可以在一定程度上减少过拟合情况。
因此,采用正则化的目的通常为:减少过拟合问题, 进而增强泛化能力。
3.正则化线性回归
假设我们的模型为$h_\theta(x)=\theta_0+\theta_1x_1+\theta_2x_2^2+\theta_3x_3^3+\theta_4x_4^4$,通过下图我们可以看出正是那些高次项导致了过拟合的发生。因此,我们要想办法使高次项的系数接近于0,以避免过拟合问题。

当我们 有非常多的特征,并且不知道其中哪些特征我们要惩罚时,我们将对所有的特征进行惩罚, 并且让代价函数最优化的软件来选择这些惩罚的程度,即$$J(\theta)=\frac{1}{2m}[\sum_{i=1}^{m}((h_\theta(x^{(i)})-y^{(i)})^2+\lambda\sum_{j=1}^{n}\theta_j^2)]$$其中,$\lambda$称为正则化参数(Regularization Parameter):当λ的值很大时,为了使Cost Function 尽可能的小,所有的$\theta$的值(不包括$\theta_0$ )都会在一定程度上减小; 但是,如果λ的值太大了,那么$\theta$(不包括$\theta_0$ )都会趋近于0,这样我们所得到的只能是一条 平行于x 轴的直线。 所以对于正则化,我们要取一个合理的λ的值,这样才能更好的应用正则化。
此外,需注意我们不对$\theta_0$进行惩罚。

对于线性回归的求解,有两种算法:
(1)梯度下降法
每次在原有算法更新规则基础上令$\theta$(不包括$\theta_0$ )减去一个额外的值。或者理解为使$\theta_j$乘以一个(0,1)之间的小数,其他更新规则不变;$\theta_j=\theta_j-\alpha\frac{\partial}{\partial \theta_j}J(\theta)$且$h_\theta(x^{(i)})$中有一项为$\theta_jx_j^{(i)}$
 .
.
(2)正规方程法

4.正则化逻辑回归
类似于线性回归,我们也是给代价函数增加惩罚因子,如下图


(1)梯度下降法

(2)更高级优化算法

参考链接
1.https://dwz.cn/kCkHDisw

 浙公网安备 33010602011771号
浙公网安备 33010602011771号