
Redis笔记
Linux安装Redis
- 下载安装包
wget http://download.redis.io/releases/redis-?.?.?.tar.gz - 解压
tar –xvf 文件名.tar.gz - 编译安装
make install [destdir=/目录] - 服务启动
- 默认配置启动
- redis-server
- redis-server –-port 6379
- redis-server –-port 6380
- 指定配置文件启动
- redis-server redis.conf
- redis-server redis-6379.conf
- redis-server redis-6380.conf ……
- redis-server conf/redis-6379.conf
- redis-server config/redis-6380.conf
- Redis客户端连接
- 默认连接
- redis-cli
- 连接指定服务器
- redis-cli -h 127.0.0.1
- redis-cli –port 6379
- redis-cli -h 127.0.0.1 –port 6379
Redis数据类型及常用操作
一共有五种数据类型
string
- 常用命令
- 添加,修改数据
set key value # 添加,修改多个数据 mset key1 value1 key2 value2 ... - 获取数据
get key # 获取多个数据 mget key1 key2 ... - 删除数据
del key #删除多个数据 del key1 key 2 - 获取数据字符个数
strlen key - 追加信息到原始信息后部(如果原始信息不存在就新建)
append key value - 设置数值数据增加指定范围的值
# 数字数据有最大值:9223372036854775807,即java中long型最大值 incr key # key+1 incrbu key increment # key+increment incrbyfloat key increment #inctement可以说小数 - 设置数值数据减少指定范围的值
decr key decrby key increment - 设置数据的生命周期
setex key second value psetex key milliseconds value
- 添加,修改数据
hash
- 底层优化:
如果field数量较少,存储结构优化为类数组结构,如果field数量较多,存储结构使用HashMap结构 - 对应HashMap,常用命令
- 添加/修改数据
# 每个 hash 可以存储 2的32次方 - 1 个键值对 hset key field value # 添加/修改多个数据 hmset key field1 value1 field2 value2 # 设置独立键值对 hsetnx key field value - 获取数据
hget key field # 获取全部数据 hgetall key # 获取多个value数据 hmget key filed1 field2 - 删除数据
hdel key field1 field2... - 获取哈希表中字段的数量
hlen key - 判断哈希表中是否存在指定的字段
hexists key field - 获取哈希表中所有的字段名和字段值
hkeys key hvals key - 设置指定字段的数值数据增加指定范围的值
hincrby key field increment hincrbyfloat key field increment
- 添加/修改数据
list
- 对应LinkedList,采用双向链表
- 添加/修改数据
# 分别对应左和右 lpush key value [value2]... rpush key value [value2]... - 获取数据
lrange key start stop lindex key index llen key - 获取并移除数据
lpop key rpop key - 规定时间内获取并移除数据
blpop key1 [key2] timeout brpop key1 [key2] timeout brpoplpush source destination timeout - 移除指定数据
lrem key count value # value:移除几次
- 添加/修改数据
set
- 对应HashSet,仅存储键,不存储值,并且值不允许重复
- 常用命令
- 添加数据
sadd key member1 [member2] - 获取全部数据
smembers key - 删除数据
srem key member1 [member2] - 获取集合数据总量
scard key - 判断集合中是否包含指定数据
sismember key member - 随机获取集合中指定数量的数据
srandmember key [count] - 随机获取集合中的某个数据并将该数据移出集合
spop key [count] - 求两个集合的交、并、差集
sinter key1 [key2] sunion key1 [key2] sdiff key1 [key2] - 求两个集合的交、并、差集并存储到指定集合中
sinterstore destination key1 [key2] sunionstore destination key1 [key2] sdiffstore destination key1 [key2] - 将指定数据从原始集合中移动到目标集合中
smove source destination member
- 添加数据
sorted_set
- 对应TreeSet,具有排序功能
- 常用命令
- 添加数据
zadd key score1 member1 [score2 member2] - 获取全部数据
# WITHSCORE表示结果显示score zrange key start stop [WITHSCORES] zrevrange key start stop [WITHSCORES] - 删除数据
zrem key member [member ...] - 按条件获取数据
zrangebyscore key min max [WITHSCORES] [LIMIT] zrevrangebyscore key max min [WITHSCORES] - 条件删除数据
zremrangebyrank key start stop zremrangebyscore key min max - 获取集合数据总量
zcard key zcount key min max - 集合交、并操作
zinterstore destination numkeys key [key ...] zunionstore destination numkeys key [key ...] - 获取数据对应的索引(排名)
zrank key member zrevrank key member - score值获取与修改
zscore key member zincrby key increment member
- 添加数据
通用操作
- key基本操作
- 删除指定key
del key - 获取key是否存在
exists key - 获取key的类型
type key - 为指定key设置有效期
expire key seconds pexpire key milliseconds expireat key timestamp pexpireat key milliseconds-timestamp - 获取key的有效时间
ttl key pttl key - 切换key从时效性转换为永久性
persist key - 查询key
keys pattern keys * 查询所有 keys it* 查询所有以it开头 keys *heima 查询所有以heima结尾 keys ??heima 查询所有前面两个字符任意,后面以heima结尾 keys user:? 查询所有以user:开头,最后一个字符任意 keys u[st]er:1 查询所有以u开头,以er:1结尾,中间包含一个字母,s或t - 为key改名
rename key newkey renamenx key newkey - 对所有key排序
sort - 其他key通用操作
help @generic
- 删除指定key
- 数据库通用2操作
redis为每个服务提供有16个数据库,编号从0到15.每个数据库之间的数据相互独立- 切换数据库
select index quit ping echo message - 数据移动
move key db - 数据清楚
dbsize flushdb flushall
- 切换数据库
Redis持久化
- 将redis中的数据保存下来,有两种途径
- 将当前数据状态进行保存,快照形式,存储数据结果,存储格式简单,关注点在数据(RDB)
- 将数据的操作过程进行保存,日志形式,存储操作过程,存储格式复杂,关注点在数据的操作过程(AOF)
RDB
-
RDB启动方式
命令# 手动执行一次保存操作 save # 手动启动后台保存操作,但不是立即执行 bgsave # 服务器在运行过程中重启 debug reload # 关闭服务器时指定保存数据 shutdown save # 默认使用bgsave命令 -
RDB相关配置(在conf文件当中)
- save second changes
- 作用: 满足限定时间范围内key的变化数量达到指定数量即执行持久化
- 参数:second:监控时间范围。changes:监控key的变化量
- dbfilename dump.rdb
- 说明:设置本地数据库文件名,默认值为 dump.rdb
- 经验:通常设置为dump-端口号.rdb
- dir
- 说明:设置存储.rdb文件的路径
- 经验:通常设置成存储空间较大的目录中,目录名称data
- rdbcompression yes
- 说明:设置存储至本地数据库时是否压缩数据,默认为 yes,采用 LZF 压缩。
- 经验:通常默认为开启状态,如果设置为no,可以节省 CPU 运行时间,但会使存储的文件变大(巨大)
- rdbchecksum yes
- 说明:设置是否进行RDB文件格式校验,该校验过程在写文件和读文件过程均进行
- 经验:通常默认为开启状态,如果设置为no,可以节约读写性过程约10%时间消耗,但是存储一定的数据损坏风险
- stop-writes-on-bgsave-error yes(属于bgsave指令的配置)
- 说明:后台存储过程中如果出现错误现象,是否停止保存操作。
- 经验:通常默认为开启状态
- save second changes
-
注意事项
- save指令的执行会阻塞当前Redis服务器,直到当前RDB过程完成为止,有可能会造成长时间阻塞,线上环境不建议使用。
- bgsave命令是针对save阻塞问题做的优化。Redis会调用fork函数生成一个子进程创建rdb文件并返回消息。Redis内部所有涉及到RDB操作都采用bgsave的方式,save命令可以放弃使用
-
RDB优点:
- RDB是一个紧凑压缩的二进制文件,存储效率较高
- RDB内部存储的是redis在某个时间点的数据快照,非常适合用于数据备份,全量复制等场景
- RDB恢复数据的速度要比AOF快很多
- 应用:服务器中每X小时执行bgsave备份,并将RDB文件拷贝到远程机器中,用于灾难恢复
-
RDB缺点:
- RDB方式无论是执行指令还是利用配置,无法做到实时持久化,具有较大的可能性丢失数据
- bgsave指令每次运行要执行fork操作创建子进程,要牺牲掉一些性能
- Redis的众多版本中未进行RDB文件格式的版本统一,有可能出现各版本服务之间数据格式无法兼容现象
AOF
- AOF介绍:以独立日志的方式记录每次写命令,重启时再重新执行AOF文件中命令达到恢复数据的目的。与RDB相比可以简单描述为改记录数据为记录数据产生的过程。主要作用是解决了数据持久化的实时性,目前已经是Redis持久化的主流方式。
- AOF写数据的三种策略
- always(每次)
每次写入操作均同步到AOF文件中,数据零误差,性能较低,不建议使用。 - everysec(每秒)
每秒将缓冲区中的指令同步到AOF文件中,数据准确性较高,性能较高,建议使用,也是默认配置。在系统突然宕机的情况下丢失1秒内的数据 - no(系统控制)
由操作系统控制每次同步到AOF文件的周期,整体过程不可控
- always(每次)
- AOF功能开启的方式
# 是否开启AOF持久化功能,默认为不开启状态 appendonly yes|on # AOF写数据策略 appendfsync always|everysec|no # AOF持久化文件名,默认文件名未appendonly.aof,建议配置为appendonly-端口号.aof appendfilename filename #AOF持久化文件保存路径,与RDB持久化文件保持一致即可 dir - AOF重写
- 重写介绍:
随着命令不断写入AOF,文件会越来越大,为了解决这个问题,Redis引入了AOF重写机制压缩文件体积。AOF文件重
写是将Redis进程内的数据转化为写命令同步到新AOF文件的过程。简单说就是将对同一个数据的若干个条命令执行结
果转化成最终结果数据对应的指令进行记录。 - 重写作用:
- 降低磁盘占用量,提高磁盘利用率
- 提高持久化效率,降低持久化写时间,提高IO性能
- 降低数据恢复用时,提高数据恢复效率
- 重写规则
- 进程内已超时的数据不再写入文件
- 忽略无效指令,重写时使用进程内数据直接生成,这样新的AOF文件只保留最终数据的写入命令如del key1、 hdel key2、srem key3、set key4 111、set key4 222等
- 对同一数据的多条写命令合并为一条命令如lpush list1 a、lpush list1 b、 lpush list1 c 可以转化为:lpush list1 a b c。为防止数据量过大造成客户端缓冲区溢出,对list、set、hash、zset等类型,每条指令最多写入64个元素
- 重写配置
# 手动重写命令 bgrewriteaof # 自动重写配置 # 值aof文件的大小 auto-aof-rewrite-min-size size # aof文件增长比例,指当前aof文件比上次重写的增长比例大小。当前文件size比上基准文件size,如果大于配置比例就重写 auto-aof-rewrite-percentage percentage
- 重写介绍:
- RDB和AOF的对比
- 对数据非常敏感,建议使用默认的AOF持久化方案
- AOF持久化策略使用everysecond,每秒钟fsync一次。该策略redis仍可以保持很好的处理性能,当出
现问题时,最多丢失0-1秒内的数据。 - 注意:由于AOF文件存储体积较大,且恢复速度较慢
- AOF持久化策略使用everysecond,每秒钟fsync一次。该策略redis仍可以保持很好的处理性能,当出
- 数据呈现阶段有效性,建议使用RDB持久化方案
1. 数据可以良好的做到阶段内无丢失(该阶段是开发者或运维人员手工维护的),且恢复速度较快,阶段点数据恢复通常采用RDB方案
2. 注意:利用RDB实现紧凑的数据持久化会使Redis降的很低,慎重总结: - 综合比对
- RDB与AOF的选择实际上是在做一种权衡,每种都有利有弊
- 如不能承受数分钟以内的数据丢失,对业务数据非常敏感,选用AOF
- 如能承受数分钟以内的数据丢失,且追求大数据集的恢复速度,选用RDB
- 灾难恢复选用RDB
- 双保险策略,同时开启 RDB 和 AOF,重启后,Redis优先使用 AOF 来恢复数据,降低丢失数据的量
- 对数据非常敏感,建议使用默认的AOF持久化方案
Redis事务
Redis事务
- 事务介绍
Redis执行指令过程种,会存在多条连续的指令被干扰,打断,插队,出现数据异常的问题。事务的出现就是为了解决这种问题。redis事务就是一个命令执行的队列,将一系列预定义命令包装成一个整体(一个队列)。当执行时,一次性按照添加顺序依次执行,中间不会被打断或者干扰,一个队列中,一次性、顺序性、排他性的执行一系列命令 - 事务的命令操作
# 开启事务,设定事务的开启位置,此指令执行后,后续的所有指令均加入到事务中
multi
# 执行事务,设定事务的结束位置,同时执行事务。与multi成对出现,成对使用
exec
# 加入事务的命令暂时进入到任务队列中,并没有立即执行,只有执行exec命令才开始统一执行
# 取消事务,终止当前事务的定义,发生在multi之后,exec之前
discard
- 事务注意事项
- 定义事务的过程中,命令格式输入错误
- 语法错误,指命令书写格式有误
- 处理结果:如果定义的事务中所包含的命令存在语法错误,整体事务中所有命令均不会执行。包括那些语法正确的命令。
- 定义事务的过程中,命令执行出现错误
- 运行错误,指命令格式正确,但是无法正确的执行。例如对list进行incr操作
- 处理结果
能够正确运行的命令会执行,运行错误的命令不会被执行注意:已经执行完毕的命令对应的数据不会自动回滚,需要程序员自己在代码中实现回滚
- 定义事务的过程中,命令格式输入错误
Redis锁
- 介绍:基于特定条件的事务执行,多用在多个客户端对服务端同一部分的数据进行操作
- 命令操作
# 对key添加监视锁,在执行exec前如果key发生了变化,终止事务执行
watch key1 [key2...]
# 取消对所有key的监视
unwatch key
- 分布式锁
#使用setnx设置一个公共锁
#利用setnx命令的返回值特征,有值则返回设置失败,无值则返回设置成功,对于返回设置成功的,拥有控制权,进行下一步的具体业务操作,对于返回设置失败的,不具有控制权,排队或等待操作完毕通过del操作释放锁
setnx lock-key value
#改良,用时间锁放在客户端在某种情况下长时间的不释放锁
#使用 expire 为锁key添加时间限定,到时不释放,放弃锁
expire lock-key second
pexpire lock-key milliseconds
由于操作通常都是微秒或毫秒级,因此该锁定时间不宜设置过大。具体时间需要业务测试后确认。
例如:持有锁的操作最长执行时间127ms,最短执行时间7ms。
测试百万次最长执行时间对应命令的最大耗时,测试百万次网络延迟平均耗时
锁时间设定推荐:最大耗时*120%+平均网络延迟*110%
如果业务最大耗时<<网络平均延迟,通常为2个数量级,取其中单个耗时较长即可
Redis删除策略
- Redis中的数据特征
Redis是一种内存级数据库,所有数据均存放在内存中,内存中的数据可以通过TTL key指令获取其状态- XX :具有时效性的数据
- -1 :永久有效的数据
- -2 :已经过期的数据 或 被删除的数据 或 未定义的数据Redis中的数据特征
定时删除
创建一个定时器,当key设置有过期时间,且过期时间到达时,由定时器任务立即执行对键的删除操作(每一个key,value都有一个地址值,地址值对应着一个时间)
- 优点:节约内存,到时就删除,快速释放掉不必要的内存占用
- 缺点:CPU压力很大,无论CPU此时负载量多高,均占用CPU,会影响redis服务器响应时间和指令吞吐量
- 总结:用处理器性能换取存储空间(拿时间换空间)
惰性删除
- 数据到达过期时间,不做处理。等下次访问该数据时
- 如果未过期,返回数据
- 发现已过期,删除,返回不存在
- 优点:节约CPU性能,发现必须删除的时候才删除
- 缺点:内存压力很大,出现长期占用内存的数据
- 总结:用存储空间换取处理器性能 expireIfNeeded() (拿时间换空间)
定期删除
- 定期删除步骤
- Redis启动服务器初始化时,读取配置server.hz的值,默认为10
- 每秒钟执行server.hz次serverCron()
- activeExpireCycle()对每个expires[*]逐一进行检测,每次执行250ms/server.hz
- 对某个expires[]检测时,随机挑选W个key检测,如果key超时,删除key。如果一轮中删除的key的数量>W25%,循环该过程。如果一轮中删除的key的数量≤W25%,检查下一个expires[],0-15循环。W取值=ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP属性值
- 参数current_db用于记录activeExpireCycle() 进入哪个expires[*] 执行
- 如果activeExpireCycle()执行时间到期,下次从current_db继续向下执行
- 周期性轮询redis库中的时效性数据,采用随机抽取的策略,利用过期数据占比的方式控制删除频度
- 特点1:CPU性能占用设置有峰值,检测频度可自定义设置
- 特点2:内存压力不是很大,长期占用内存的冷数据会被持续清理
- 总结:周期性抽查存储空间(随机抽查,重点抽查)
数据逐出算法
- 当新数据进入redis时,如果内存不足怎么办?
- Redis使用内存存储数据,在执行每一个命令前,会调用freeMemoryIfNeeded()检测内存是否充足。如果内存不满足新加入数据的最低存储要求,redis要临时删除一些数据为当前指令清理存储空间。清理数据的策略称为逐出算法。
- 注意:逐出数据的过程不是100%能够清理出足够的可使用的内存空间,如果不成功则反复执行。当对所有数据尝试完毕后,如果不能达到内存清理的要求,将出现错误信息。((error) OOM command not allowed when used memory >'maxmemory')
- 数据逐出算法的相关配置
# 最大可使用内存,占用物理内存的比例,默认值为0,表示不限制。生产环境中根据需求设定,通常设置在50%以上。 maxmemory # 每次选取待删除数据的个数,选取数据时并不会全库扫描,导致严重的性能消耗,降低读写性能。因此采用随机获取数据的方式作为待检测删除数据 maxmemory-samples # 删除策略,达到最大内存后的,对被挑选出来的数据进行删除的策略 maxmemory-policy 检测易失数据(可能会过期的数据集server.db[i].expires ) 1. volatile-lru:挑选最近最少使用的数据淘汰 2. volatile-lfu:挑选最近使用次数最少的数据淘汰 3. volatile-ttl:挑选将要过期的数据淘汰 4. volatile-random:任意选择数据淘汰 检测全库数据(所有数据集server.db[i].dict ) 5. allkeys-lru:挑选最近最少使用的数据淘汰 6. allkeys-lfu:挑选最近使用次数最少的数据淘汰 7. allkeys-random:任意选择数据淘汰 放弃数据驱逐 8. no-enviction(驱逐):禁止驱逐数据(redis4.0中默认策略),会引发错误OOM(Out Of Memory)
Redis基础配置
#设置服务器以守护进程的方式运行
daemonize yes|no
#绑定主机地址
bind 127.0.0.1
#设置服务器端口号
port 6379
#设置数据库数量
databases 16
#设置服务器以指定日志记录级别
loglevel debug|verbose|notice|warning
#日志记录文件名
logfile 端口号.log
#日志级别开发期设置为verbose即可,生产环境中配置为notice,简化日志输出量,降低写日志IO的频度
#设置同一时间最大客户端连接数,默认无限制。当客户端连接到达上限,Redis会关闭新的连接
maxclients 0
# 客户端闲置等待最大时长,达到最大值后关闭连接。如需关闭该功能,设置为 0
timeout 300
#导入并加载指定配置文件信息,用于快速创建redis公共配置较多的redis实例配置文件,便于维护
include /path/server-端口号.conf
Redis高级数据类型
Bitmaps
- 存储的是0,1数组
- 基础操作
#获取指定key对应偏移量上的bit值 getbit key offset #设置指定key对应偏移量上的bit值,value只能是1或0 setbit key offset value #对指定key按位进行交、并、非、异或操作,并将结果保存到destKey中(and:交.or:并. not:非. xor:异或) bitop op destKey key1 [key2...] #统计指定key中1的数量 bitcount key [start end]
HyperLogLog
- 基数是数据集去重后元素个数. HyperLogLog 是用来做基数统计的,运用了LogLog的算法
- 基础操作
#添加数据
pfadd key element [element ...]
# 统计数据
pfcount key [key ...]
#合并数据
pfmerge destkey sourcekey [sourcekey...]
- 注意事项
- 用于进行基数统计,不是集合,不保存数据,只记录数量而不是具体数据
- 核心是基数估算算法,最终数值存在一定误差
- 误差范围:基数估计的结果是一个带有 0.81% 标准错误的近似值
- 耗空间极小,每个hyperloglog key占用了12K的内存用于标记基数
- pfadd命令不是一次性分配12K内存使用,会随着基数的增加内存逐渐增大
- Pfmerge命令合并后占用的存储空间为12K,无论合并之前数据量多少
GEO
- 计算两个坐标的距离
- 基础操作
#添加坐标点
geoadd key longitude latitude member [longitude latitude member ...]
georadius key longitude latitude radius m|km|ft|mi [withcoord] [withdist] [withhash] [count count]
# 获取坐标点
geopos key member [member ...]
georadiusbymember key member radius m|km|ft|mi [withcoord] [withdist] [withhash] [count count]
# 计算坐标点距离
geodist key member1 member2 [unit]
geohash key member [member ...]
Redis主从复制
- 主从复制介绍
主从复制即将master中的数据即时、有效的复制到slave中
特征:一个master可以拥有多个slave,一个slave只对应一个master- 职责:
- master:写数据, 执行写操作时,将出现变化的数据自动同步到slave 读数据(可忽略)
- slave: 读数据, 写数据(禁止)
- 职责:
主从复制的作用
1. 读写分离:master写、slave读,提高服务器的读写负载能力
2. 负载均衡:基于主从结构,配合读写分离,由slave分担master负载,并根据需求的变化,改变slave的数
量,通过多个从节点分担数据读取负载,大大提高Redis服务器并发量与数据吞吐量
3. 故障恢复:当master出现问题时,由slave提供服务,实现快速的故障恢复
4. 数据冗余:实现数据热备份,是持久化之外的一种数据冗余方式
5. 高可用基石:基于主从复制,构建哨兵模式与集群,实现Redis的高可用方案
主从复制的工作流程
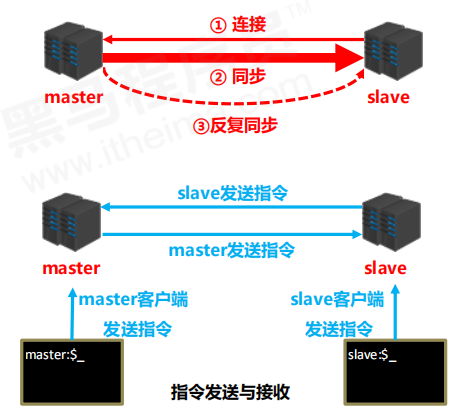
-
建立连接阶段(准备阶段)

-
连接命令(slave连接master)
#方式一:客户端发送命令 slaveof <masterip> <masterport> #方式二:启动服务器参数 redis-server -slaveof <masterip> <masterport> #方式三:服务器配置 slaveof <masterip> <masterport> slave系统信息 * master_link_down_since_seconds * masterhost * masterport master系统信息 * slave_listening_port(多个) -
断开连接
slaveof no one #slave断开连接后,不会删除已有数据,只是不再接受master发送的数据 -
授权访问

-
数据同步阶段
-
在slave初次连接master后,复制master中的所有数据到slave
-
将slave的数据库状态更新成master当前的数据库状态
-
工作流程
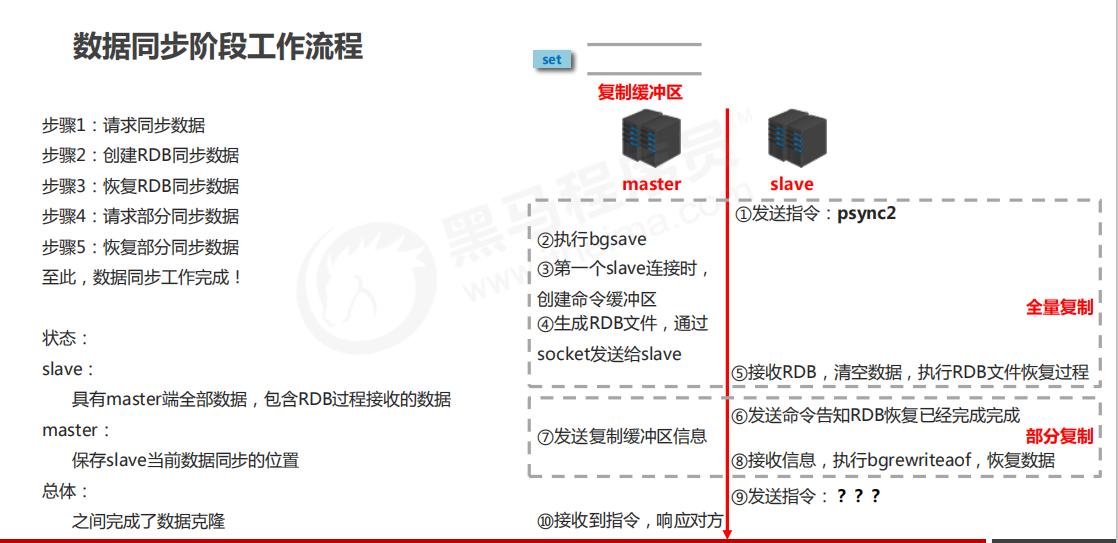
-
注意事项
- master端:
- 如果master数据量巨大,数据同步阶段应避开流量高峰期,避免造成master阻塞,影响业务正常执行
- 复制缓冲区大小设定不合理,会导致数据溢出。如进行全量复制周期太长,进行部分复制时发现数据已经存在丢失的情况,必须进行第二次全量复制,致使slave陷入死循环状态。
#复制缓冲区配置 repl-backlog-size 1mb- master单机内存占用主机内存的比例不应过大,建议使用50%-70%的内存,留下30%-50%的内存用于执行bgsave命令和创建复制缓冲区
- slave端
- 为避免slave进行全量复制、部分复制时服务器响应阻塞或数据不同步,建议关闭此期间的对外服务
slave-serve-stale-data yes|no - 数据同步阶段,master发送给slave信息可以理解master是slave的一个客户端,主动向slave发送命令
- 多个slave同时对master请求数据同步,master发送的RDB文件增多,会对带宽造成巨大冲击,如果master带宽不足,因此数据同步需要根据业务需求,适量错峰
- slave过多时,建议调整拓扑结构,由一主多从结构变为树状结构,中间的节点既是master,也是slave。注意使用树状结构时,由于层级深度,导致深度越高的slave与最顶层master间数据同步延迟较大,数据一致性变差,应谨慎选择
- master端:
-
命令传播阶段
- 当master数据库状态被修改后,导致主从服务器数据库状态不一致,此时需要让主从数据同步到一致的状态,同步的动作称为命令传播
- master将接收到的数据变更命令发送给slave,slave接收命令后执行命令
- 工作流程

- runid(服务器运行ID)
* 概念:服务器运行ID是每一台服务器每次运行的身份识别码,一台服务器多次运行可以生成多个运行id
* 组成:运行id由40位字符组成,是一个随机的十六进制字符,例如:fdc9ff13b9bbaab28db42b3d50f852bb5e3fcdce
* 作用:运行id被用于在服务器间进行传输,识别身份,如果想两次操作均对同一台服务器进行,必须每次操作携带对应的运行id,用于对方识别
* 实现方式:运行id在每台服务器启动时自动生成的,master在首次连接slave时,会将自己的运行ID发送给slave,slave保存此ID,通过info Server命令,可以查看节点的runid - 复制缓存区
复制缓冲区,又名复制积压缓冲区,是一个先进先出(FIFO)的队列,用于存储服务器执行过的命令,每次传播命令,master都会将传播的命令记录下来,并存储在复制缓冲区。每台服务器启动时,如果开启有AOF或被连接成为master节点,即创建复制缓冲区。用于保存master收到的所有指令(仅影响数据变更的指令,例如set,select)。当master接收到主客户端的指令时,除了将指令执行,会将该指令存储到缓冲区中 - 主从服务器复制偏移量(offset)
概念:一个数字,描述复制缓冲区中的指令字节位置- 分类:
- master复制偏移量:记录发送给所有slave的指令字节对应的位置(多个)
- slave复制偏移量:记录slave接收master发送过来的指令字节对应的位置(一个)
- 数据来源:
- master端:发送一次记录一次
- slave端:接收一次记录一次
- 作用:同步信息,比对master与slave的差异,当slave 断线后,恢复数据使用
- 心跳机制
进入命令传播阶段候,master与slave间需要进行信息交换,使用心跳机制进行维护,实现双方连接保持在线- master心跳:
指令:PING
周期:由repl-ping-slave-period决定,默认10秒 作用:判断slave是否在线
查询:INFO replication 获取slave最后一次连接时间间隔,lag项维持在0或1视为正常 - slave心跳任务
指令:REPLCONF ACK {offset}
周期:1秒
作用1:汇报slave自己的复制偏移量,获取最新的数据变更指令
作用2:判断master是否在线 - 心跳阶段注意事项
- 当slave多数掉线,或延迟过高时,master为保障数据稳定性,将拒绝所有信息同步操作
# slave数量少于2个,或者所有slave的延迟都大于等于10秒时,强制关闭master写功能,停止数据同步 min-slaves-to-write 2 min-slaves-max-lag 10 # slave数量由slave发送REPLCONF ACK命令做确认 # slave延迟由slave发送REPLCONF ACK命令做确认
- master心跳:
-
工作流程总结
主从复制常见问题
- 伴随着系统的运行,master的数据量会越来越大,一旦master重启,runid将发生变化,会导致全部slave的全量复制操作
- 解决办法
- master内部创建master_replid变量,使用runid相同的策略生成,长度41位,并发送给所有slave
- 在master关闭时执行命令 shutdown save,进行RDB持久化,将runid与offset保存到RDB文件中
- repl-id repl-offset
- 通过redis-check-rdb命令可以查看该信息
- master重启后加载RDB文件,恢复数据重启后,将RDB文件中保存的repl-id与repl-offset加载到内存中
- master_repl_id = repl master_repl_offset = repl-offset
- 通过info命令可以查看该信息
*作用:本机保存上次runid,重启后恢复该值,使所有slave认为还是之前的master
- 网络环境不佳,出现网络中断,slave不提供服务
- 问题原因
- 复制缓冲区过小,断网后slave的offset越界,触发全量复制
- 最终结果
- slave反复进行全量复制
- 解决方案
- 修改复制缓冲区大小
repl-backlog-size
- 修改复制缓冲区大小
- 建议设置如下:
- 测算从master到slave的重连平均时长second
- 获取master平均每秒产生写命令数据总量write_size_per_second
- 最优复制缓冲区空间 = 2 * second * write_size_per_second
- 问题原因
- master的CPU占用过高 或 slave频繁断开连接
- 问题原因
- slave每1秒发送REPLCONF ACK命令到master
- 当slave接到了慢查询时(keys * ,hgetall等),会大量占用CPU性能
- master每1秒调用复制定时函数replicationCron(),比对slave发现长时间没有进行响应
- 最终结果
- master各种资源(输出缓冲区、带宽、连接等)被严重占用
- 解决方案
通过设置合理的超时时间,确认是否释放slave
repl-timeout
- 问题原因
- slave与master连接断开
- 问题原因
- master发送ping指令频度较低
- master设定超时时间较短
- ping指令在网络中存在丢包
- 解决方法
- 提高ping指令发送的频度超时时间repl-time的时间至少是ping指令频度的5到10倍,否则slave很容易判定超时
repl-ping-slave-period
- 提高ping指令发送的频度超时时间repl-time的时间至少是ping指令频度的5到10倍,否则slave很容易判定超时
- 问题原因
- 多个slave获取相同数据不同步
- 问题原因
网络信息不同步,数据发送有延迟 - 解决方案
- 优化主从间的网络环境,通常放置在同一个机房部署,如使用阿里云等云服务器时要注意此现象
- 监控主从节点延迟(通过offset)判断,如果slave延迟过大,暂时屏蔽程序对该slave的数据访问
slave-serve-stale-data yes|no
开启后仅响应info、slaveof等少数命令(慎用,除非对数据一致性要求很高)
- 问题原因
Redis哨兵
- 简介:
哨兵(sentinel) 是一个分布式系统,用于对主从结构中的每台服务器进行监控,当出现故障时通过投票机制选择新的 master并将所有slave连接到新的master。 - 哨兵的作用:
- 监控
不断的检查master和slave是否正常运行。master存活检测、master与slave运行情况检测 - 通知(提醒)
当被监控的服务器出现问题时,向其他(哨兵间,客户端)发送通知。 - 自动故障转移
断开master与slave连接,选取一个slave作为master,将其他slave连接到新的master,并告知客户端新的服务器地址
- 监控
哨兵的启用
redis-sentinel sentinel-端口号.conf

哨兵工作原理
- 监控
- 同步所有节点的状态信息
- 获取各个sentinel的状态(是否在线)
- 获取master的状态
- master属性
- runid
- role:master
- 各个slave的详细信息
- master属性
- 获取所有slave的状态(根据master中的slave信息)
- slave属性
- runid
- role:slave
- master_host、master_port
- offset
- ……
- slave属性
- 通知
- 与各个节点不断保持同步,更新状态
- 故障转移
- 发现问题
- 竞选负责人
- 优选新master
- 新master上任,其他slave切换master,原master作为slave故障回复后连接
集群
- 简介:
集群就是使用网络将若干台计算机联通起来,并提供统一的管理方式,使其对外呈现单机的服务效果 - 作用:分散单台服务器的访问压力,实现负载均衡 分散单台服务器的存储压力,实现可扩展性,降低单台服务器宕机带来的业务灾难
- 具体搭建
Redis缓存可能出现的一些问题和解决方法
-
缓存预热
- 出现场景:
服务器启动后迅速宕机 - 出现原因:
- 请求数量较多
- 主从之间数据吞吐量较大,数据同步操作频度较高
- 解决方案:
- 前置准备工作:
- 日常例行统计数据访问记录,统计访问频度较高的热点数据
- 利用LRU数据删除策略,构建数据留存队列,例如:storm与kafka配合
- 准备工作:
- 将统计结果中的数据分类,根据级别,redis优先加载级别较高的热点数据
- 利用分布式多服务器同时进行数据读取,提速数据加载过程
- 热点数据主从同时预热
- 实施:
- 使用脚本程序固定触发数据预热过程
- 如果条件允许,使用了CDN(内容分发网络),效果会更好
- 前置准备工作:
- 总结:
缓存预热就是系统启动前,提前将相关的缓存数据直接加载到缓存系统。避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
- 出现场景:
-
缓存雪崩
- 出现场景:
- 系统平稳运行过程中,忽然数据库连接量激增
- 应用服务器无法及时处理请求
- 大量408,500错误页面出现
- 客户反复刷新页面获取数据
- 数据库崩溃
- 应用服务器崩溃
- 重启应用服务器无效
- Redis服务器崩溃
- Redis集群崩溃
- 重启数据库后再次被瞬间流量放倒
- 出现原因:
- 在一个较短的时间内,缓存中较多的key集中过期
- 此周期内请求访问过期的数据,redis未命中,redis向数据库获取数据
- 数据库同时接收到大量的请求无法及时处理
- Redis大量请求被积压,开始出现超时现象
- 数据库流量激增,数据库崩溃
- 重启后仍然面对缓存中无数据可用
- Redis服务器资源被严重占用,Redis服务器崩溃
- Redis集群呈现崩塌,集群瓦解
- 应用服务器无法及时得到数据响应请求,来自客户端的请求数量越来越多,应用服务器崩溃
- 应用服务器,redis,数据库全部重启,效果不理想
- 解决方案:
- 更多的页面静态化处理
- 构建多级缓存架构
Nginx缓存+redis缓存+ehcache缓存 - 检测Mysql严重耗时业务进行优化对数据库的瓶颈排查:例如超时查询、耗时较高事务等
- 灾难预警机制。监控redis服务器性能指标(CPU占用,CPU使用率,内存容量,查询平均响应时间,线程数)
- 限流、降级短时间范围内牺牲一些客户体验,限制一部分请求访问,降低应用服务器压力,待业务低速运转后再逐步放开访问
- LRU与LFU切换Redis中LRU和LFU的说明
- 数据有效期策略调整: 根据业务数据有效期进行分类错峰,A类90分钟,B类80分钟,C类70分钟, 过期时间使用固定时间+随机值的形式,稀释集中到期的key的数量
- 超热数据使用永久key
- 定期维护(自动+人工)对即将过期数据做访问量分析,确认是否延时,配合访问量统计,做热点数据的延时
- 加锁
- 总结:
缓存雪崩就是瞬间过期数据量太大,导致对数据库服务器造成压力。如能够有效避免过期时间集中,可以有效解决雪崩现象的出现(约40%),配合其他策略一起使用,并监控服务器的运行数据,根据运行记录做快速调整。
- 出现场景:
-
缓存击穿
- 出现场景:
- 系统平稳运行过程中
- 数据库连接量瞬间激增
- Redis服务器无大量key过期
- Redis内存平稳,无波动
- Redis服务器CPU正常
- 数据库崩溃
- 出现原因:
- Redis中某个key过期,该key访问量巨大
- 多个数据请求从服务器直接压到Redis后,均未命中
- Redis在短时间内发起了大量对数据库中同一数据的访问
- 解决方案:
- 预先设定以电商为例,每个商家根据店铺等级,指定若干款主打商品,在购物节期间,加大此类信息key的过期时长注意:购物节不仅仅指当天,以及后续若干天,访问峰值呈现逐渐降低的趋势
- 现场调整,监控访问量,对自然流量激增的数据延长过期时间或设置为永久性key
- 后台刷新数据,启动定时任务,高峰期来临之前,刷新数据有效期,确保不丢失
- 二级缓存设置不同的失效时间,保障不会被同时淘汰就行
- 加锁,分布式锁,防止被击穿,但是要注意也是性能瓶颈,慎重
- 总结:
缓存击穿就是单个高热数据过期的瞬间,数据访问量较大,未命中redis后,发起了大量对同一数据的数据库访问,导致对数据库服务器造成压力。应对策略应该在业务数据分析与预防方面进行,配合运行监控测试与即时调整策略,毕竟单个key的过期监控难度较高,配合雪崩处理策略即可。
- 出现场景:
-
缓存穿透
- 出现场景:
- 系统平稳运行过程中
- 应用服务器流量随时间增量较大
- Redis服务器命中率随时间逐步降低
- Redis内存平稳,内存无压力
- Redis服务器CPU占用激增
- 数据库服务器压力激增
- 数据库崩溃
- 出现原因:
- Redis中大面积出现未命中
- 出现非正常URL访问
- 解决方案:
- 缓存null,对查询结果为null的数据进行缓存(长期使用,定期清理),设定短时限,例如30-60秒,最高5分钟
- 白名单策略:1. 提前预热各种分类数据id对应的bitmaps,id作为bitmaps的offset,相当于设置了数据白名单。当加载正常数据时,放行,加载异常数据时直接拦截(效率偏低)。 2. 使用布隆过滤器(有关布隆过滤器的命中问题对当前状况可以忽略)
- 实施监控:实时监控redis命中率(业务正常范围时,通常会有一个波动值)与null数据的占比
3.1 非活动时段波动:通常检测3-5倍,超过5倍纳入重点排查对象
3.2 活动时段波动:通常检测10-50倍,超过50倍纳入重点排查对象
根据倍数不同,启动不同的排查流程。然后使用黑名单进行防控(运营) - key加密:问题出现后,临时启动防灾业务key,对key进行业务层传输加密服务,设定校验程序,过来的key校验,例如每天随机分配60个加密串,挑选2到3个,混淆到页面数据id中,发现访问key不满足规则,驳回数据访问
- 总结:
缓存击穿访问了不存在的数据,跳过了合法数据的redis数据缓存阶段,每次访问数据库,导致对数据库服务器造成压力。通常此类数据的出现量是一个较低的值,当出现此类情况以毒攻毒,并及时报警。应对策略应该在临时预案防范方面多做文章。无论是黑名单还是白名单,都是对整体系统的压力,警报解除后尽快移除。
- 出现场景:
-
性能监控指标
- 性能指标:Performance
name Description latency Redis响应一个请求的时间 instantaneous_ops_per_sec 平均每秒处理请求总数 hit rate(calculated) 缓存命中率(通过计算) - 内存指标:Memory
name Description used_memory 已使用内存 mem_fragmentation_ratio 内存碎片率 evicted_keys 由于最大内存限制被移除的key的数量 blocked_clients 由于BLPOP,BRPOP,or BRPOPLPUSH而被阻塞的客户端 - 基本活动指标:Basic activity
name Description connected_clients 客户端连接数 connected_slaves Slave数量 master_last_io_seconds_ago 最近一次主从交互之后的秒数 keyspace 数据库中的key值总数 - 持久性指标:Persistence
name Description rdb_last_save_time 最后一次持久化到磁盘的时间戳 rdb_changes_since_last_save 自最后一次持久化以来数据库的更改数 - 错误指标:Error
name Description rejected_connections 由于达到maxclient现在而拒绝的连接数 keyspace_miss key值查找失败(没有命中的次数) master_link_down_since_second 主从断开的持续时间
- 性能指标:Performance
-
性能监控方式:
- 工具
- Cloud Insight Redis
- Prometheus
- Redis-stat
- Redis-faina
- RedisLive
- zabbix
- 命令
- benchmark
- redis cli
- monitor
- showlog
- benchmark
使用介绍 - monitor
# 打印服务器调试信息,客户端命令 monitor - showlong
showlong [operator] # get :获取慢查询日志 # len :获取慢查询日志条目数 # reset :重置慢查询日志- 相关配置
- slowlog-log-slower-than 1000 #设置慢查询的时间下线,单位:微妙
- slowlog-max-len 100 #设置慢查询命令对应的日志显示长度,单位:命令数
- 相关配置
- 工具

