Spark的五种JOIN策略解析
JOIN操作是非常常见的数据处理操作,Spark作为一个统一的大数据处理引擎,提供了非常丰富的JOIN场景。本文分享将介绍Spark所提供的5种JOIN策略,希望对你有所帮助。本文主要包括以下内容:
- 影响JOIN操作的因素
- Spark中JOIN执行的5种策略
- Spark是如何选择JOIN策略的
影响JOIN操作的因素
数据集的大小
参与JOIN的数据集的大小会直接影响Join操作的执行效率。同样,也会影响JOIN机制的选择和JOIN的执行效率。
JOIN的条件
JOIN的条件会涉及字段之间的逻辑比较。根据JOIN的条件,JOIN可分为两大类:等值连接和非等值连接。等值连接会涉及一个或多个需要同时满足的相等条件。在两个输入数据集的属性之间应用每个等值条件。当使用其他运算符(运算连接符不为**=**)时,称之为非等值连接。
JOIN的类型
在输入数据集的记录之间应用连接条件之后,JOIN类型会影响JOIN操作的结果。主要有以下几种JOIN类型:
- 内连接(Inner Join):仅从输入数据集中输出匹配连接条件的记录。
- 外连接(Outer Join):又分为左外连接、右外链接和全外连接。
- 半连接(Semi Join):右表只用于过滤左表的数据而不出现在结果集中。
- 交叉连接(Cross Join):交叉联接返回左表中的所有行,左表中的每一行与右表中的所有行组合。交叉联接也称作笛卡尔积。
Spark中JOIN执行的5种策略
Spark提供了5种JOIN机制来执行具体的JOIN操作。该5种JOIN机制如下所示:
- Shuffle Hash Join
- Broadcast Hash Join
- Sort Merge Join
- Cartesian Join
- Broadcast Nested Loop Join
Shuffle Hash Join
简介
当要JOIN的表数据量比较大时,可以选择Shuffle Hash Join。这样可以将大表进行按照JOIN的key进行重分区,保证每个相同的JOIN key都发送到同一个分区中。如下图示:
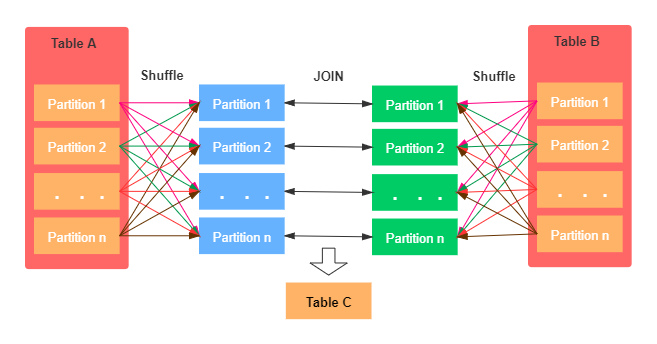
如上图所示:Shuffle Hash Join的基本步骤主要有以下两点:
- 首先,对于两张参与JOIN的表,分别按照join key进行重分区,该过程会涉及Shuffle,其目的是将相同join key的数据发送到同一个分区,方便分区内进行join。
- 其次,对于每个Shuffle之后的分区,会将小表的分区数据构建成一个Hash table,然后根据join key与大表的分区数据记录进行匹配。
条件与特点
- 仅支持等值连接,join key不需要排序
- 支持除了全外连接(full outer joins)之外的所有join类型
- 需要对小表构建Hash map,属于内存密集型的操作,如果构建Hash表的一侧数据比较大,可能会造成OOM
- 将参数*spark.sql.join.prefersortmergeJoin (default true)*置为false
Broadcast Hash Join
简介
也称之为Map端JOIN。当有一张表较小时,我们通常选择Broadcast Hash Join,这样可以避免Shuffle带来的开销,从而提高性能。比如事实表与维表进行JOIN时,由于维表的数据通常会很小,所以可以使用Broadcast Hash Join将维表进行Broadcast。这样可以避免数据的Shuffle(在Spark中Shuffle操作是很耗时的),从而提高JOIN的效率。在进行 Broadcast Join 之前,Spark 需要把处于 Executor 端的数据先发送到 Driver 端,然后 Driver 端再把数据广播到 Executor 端。如果我们需要广播的数据比较多,会造成 Driver 端出现 OOM。具体如下图示:
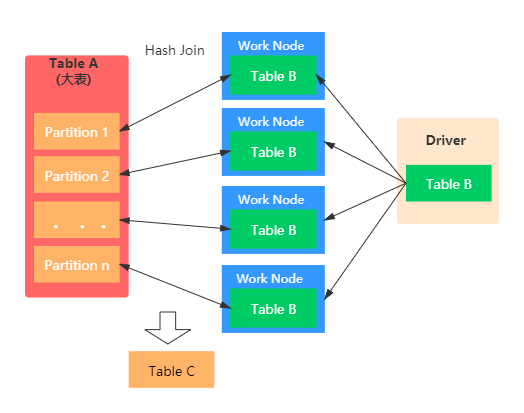
Broadcast Hash Join主要包括两个阶段:
- Broadcast阶段 :小表被缓存在executor中
- Hash Join阶段:在每个 executor中执行Hash Join
条件与特点
- 仅支持等值连接,join key不需要排序
- 支持除了全外连接(full outer joins)之外的所有join类型
- Broadcast Hash Join相比其他的JOIN机制而言,效率更高。但是,Broadcast Hash Join属于网络密集型的操作(数据冗余传输),除此之外,需要在Driver端缓存数据,所以当小表的数据量较大时,会出现OOM的情况
- 被广播的小表的数据量要小于spark.sql.autoBroadcastJoinThreshold值,默认是10MB(10485760)
- 被广播表的大小阈值不能超过8GB,spark2.4源码如下:BroadcastExchangeExec.scala
longMetric("dataSize") += dataSize
if (dataSize >= (8L << 30)) {
throw new SparkException(
s"Cannot broadcast the table that is larger than 8GB: ${dataSize >> 30} GB")
}
- 基表不能被broadcast,比如左连接时,只能将右表进行广播。形如:fact_table.join(broadcast(dimension_table),可以不使用broadcast提示,当满足条件时会自动转为该JOIN方式。
Sort Merge Join
简介
该JOIN机制是Spark默认的,可以通过参数spark.sql.join.preferSortMergeJoin进行配置,默认是true,即优先使用Sort Merge Join。一般在两张大表进行JOIN时,使用该方式。Sort Merge Join可以减少集群中的数据传输,该方式不会先加载所有数据的到内存,然后进行hashjoin,但是在JOIN之前需要对join key进行排序。具体图示:
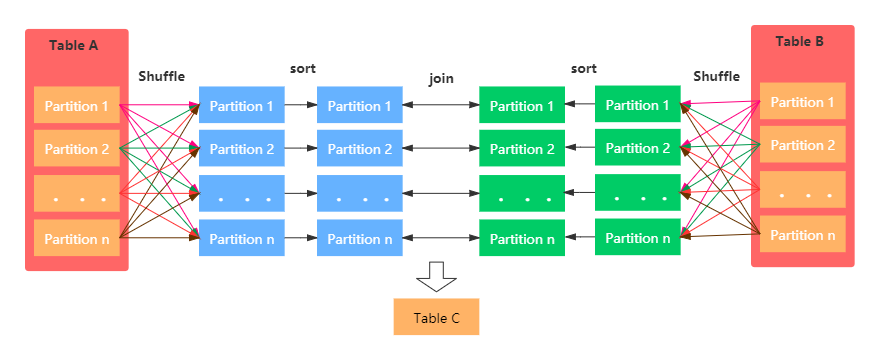
Sort Merge Join主要包括三个阶段:
- Shuffle Phase : 两张大表根据Join key进行Shuffle重分区
- Sort Phase: 每个分区内的数据进行排序
- Merge Phase: 对来自不同表的排序好的分区数据进行JOIN,通过遍历元素,连接具有相同Join key值的行来合并数据集
条件与特点
- 仅支持等值连接
- 支持所有join类型
- Join Keys是排序的
- 参数**spark.sql.join.prefersortmergeJoin (默认true)**设定为true
Cartesian Join
简介
如果 Spark 中两张参与 Join 的表没指定join key(ON 条件)那么会产生 Cartesian product join,这个 Join 得到的结果其实就是两张行数的乘积。
条件
- 仅支持内连接
- 支持等值和不等值连接
- 开启参数spark.sql.crossJoin.enabled=true
Broadcast Nested Loop Join
简介
该方式是在没有合适的JOIN机制可供选择时,最终会选择该种join策略。优先级为:Broadcast Hash Join > Sort Merge Join > Shuffle Hash Join > cartesian Join > Broadcast Nested Loop Join.
在Cartesian 与Broadcast Nested Loop Join之间,如果是内连接,或者非等值连接,则优先选择Broadcast Nested Loop策略,当时非等值连接并且一张表可以被广播时,会选择Cartesian Join。
条件与特点
- 支持等值和非等值连接
- 支持所有的JOIN类型,主要优化点如下:
- 当右外连接时要广播左表
- 当左外连接时要广播右表
- 当内连接时,要广播左右两张表
Spark是如何选择JOIN策略的
等值连接的情况
有join提示(hints)的情况,按照下面的顺序
- 1.Broadcast Hint:如果join类型支持,则选择broadcast hash join
- 2.Sort merge hint:如果join key是排序的,则选择 sort-merge join
- 3.shuffle hash hint:如果join类型支持, 选择 shuffle hash join
- 4.shuffle replicate NL hint: 如果是内连接,选择笛卡尔积方式
没有join提示(hints)的情况,则逐个对照下面的规则
- 1.如果join类型支持,并且其中一张表能够被广播(spark.sql.autoBroadcastJoinThreshold值,默认是10MB),则选择 broadcast hash join
- 2.如果参数spark.sql.join.preferSortMergeJoin设定为false,且一张表足够小(可以构建一个hash map) ,则选择shuffle hash join
- 3.如果join keys 是排序的,则选择sort-merge join
- 4.如果是内连接,选择 cartesian join
- 5.如果可能会发生OOM或者没有可以选择的执行策略,则最终选择broadcast nested loop join
非等值连接情况
有join提示(hints),按照下面的顺序
- 1.broadcast hint:选择broadcast nested loop join.
- 2.shuffle replicate NL hint: 如果是内连接,则选择cartesian product join
没有join提示(hints),则逐个对照下面的规则
- 1.如果一张表足够小(可以被广播),则选择 broadcast nested loop join
- 2.如果是内连接,则选择cartesian product join
- 3.如果可能会发生OOM或者没有可以选择的执行策略,则最终选择broadcast nested loop join
join策略选择的源码片段
object JoinSelection extends Strategy
with PredicateHelper
with JoinSelectionHelper {
def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {
case j @ ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, nonEquiCond, left, right, hint) =>
def createBroadcastHashJoin(onlyLookingAtHint: Boolean) = {
getBroadcastBuildSide(left, right, joinType, hint, onlyLookingAtHint, conf).map {
buildSide =>
Seq(joins.BroadcastHashJoinExec(
leftKeys,
rightKeys,
joinType,
buildSide,
nonEquiCond,
planLater(left),
planLater(right)))
}
}
def createShuffleHashJoin(onlyLookingAtHint: Boolean) = {
getShuffleHashJoinBuildSide(left, right, joinType, hint, onlyLookingAtHint, conf).map {
buildSide =>
Seq(joins.ShuffledHashJoinExec(
leftKeys,
rightKeys,
joinType,
buildSide,
nonEquiCond,
planLater(left),
planLater(right)))
}
}
def createSortMergeJoin() = {
if (RowOrdering.isOrderable(leftKeys)) {
Some(Seq(joins.SortMergeJoinExec(
leftKeys, rightKeys, joinType, nonEquiCond, planLater(left), planLater(right))))
} else {
None
}
}
def createCartesianProduct() = {
if (joinType.isInstanceOf[InnerLike]) {
Some(Seq(joins.CartesianProductExec(planLater(left), planLater(right), j.condition)))
} else {
None
}
}
def createJoinWithoutHint() = {
createBroadcastHashJoin(false)
.orElse {
if (!conf.preferSortMergeJoin) {
createShuffleHashJoin(false)
} else {
None
}
}
.orElse(createSortMergeJoin())
.orElse(createCartesianProduct())
.getOrElse {
val buildSide = getSmallerSide(left, right)
Seq(joins.BroadcastNestedLoopJoinExec(
planLater(left), planLater(right), buildSide, joinType, nonEquiCond))
}
}
createBroadcastHashJoin(true)
.orElse { if (hintToSortMergeJoin(hint)) createSortMergeJoin() else None }
.orElse(createShuffleHashJoin(true))
.orElse { if (hintToShuffleReplicateNL(hint)) createCartesianProduct() else None }
.getOrElse(createJoinWithoutHint())
if (canBuildLeft(joinType)) BuildLeft else BuildRight
}
def createBroadcastNLJoin(buildLeft: Boolean, buildRight: Boolean) = {
val maybeBuildSide = if (buildLeft && buildRight) {
Some(desiredBuildSide)
} else if (buildLeft) {
Some(BuildLeft)
} else if (buildRight) {
Some(BuildRight)
} else {
None
}
maybeBuildSide.map { buildSide =>
Seq(joins.BroadcastNestedLoopJoinExec(
planLater(left), planLater(right), buildSide, joinType, condition))
}
}
def createCartesianProduct() = {
if (joinType.isInstanceOf[InnerLike]) {
Some(Seq(joins.CartesianProductExec(planLater(left), planLater(right), condition)))
} else {
None
}
}
def createJoinWithoutHint() = {
createBroadcastNLJoin(canBroadcastBySize(left, conf), canBroadcastBySize(right, conf))
.orElse(createCartesianProduct())
.getOrElse {
Seq(joins.BroadcastNestedLoopJoinExec(
planLater(left), planLater(right), desiredBuildSide, joinType, condition))
}
}
createBroadcastNLJoin(hintToBroadcastLeft(hint), hintToBroadcastRight(hint))
.orElse { if (hintToShuffleReplicateNL(hint)) createCartesianProduct() else None }
.getOrElse(createJoinWithoutHint())
case _ => Nil
}
}
总结
本文主要介绍了Spark提供的5种JOIN策略,并对三种比较重要的JOIN策略进行了图示解析。首先对影响JOIN的因素进行了梳理,然后介绍了5种Spark的JOIN策略,并对每种JOIN策略的具体含义和触发条件进行了阐述,最后给出了JOIN策略选择对应的源码片段。希望本文能够对你有所帮助。
公众号『大数据技术与数仓』,回复『资料』领取大数据资料包

 浙公网安备 33010602011771号
浙公网安备 33010602011771号