Spark SQL的数据源(Spark2.3.2)
版权声明:本文为博主原创(翻译)文章,未经博主允许不得转载。https://blog.csdn.net/jmx_bigdata/article/details/83619838
目录
一、 普通的Load/Save方式
其中最简单的一种方式是默认的数据源(parquet)
val usersDF = spark.read.load("examples/src/main/resources/users.parquet")
usersDF.select("name", "favorite_color").write.save("namesAndFavColors.parquet")1. 手动指定文件格式
可以手动指定数据源的格式,对于内置的数据源而言,可以不使用全限定名(org.apache.spark.sql.parquet)),直接使用短名称(json, parquet, jdbc, orc, libsvm, csv, text)).
加载JSON格式文件:
val peopleDF = spark.read.format("json").load("examples/src/main/resources/people.json")
peopleDF.select("name", "age").write.format("parquet").save("namesAndAges.parquet")加载CSV格式文件:
val peopleDFCsv = spark.read.format("csv")
.option("sep", ";")
.option("inferSchema", "true")
.option("header", "true")
.load("examples/src/main/resources/people.csv")2.使用SQL直接查询文件
val sqlDF = spark.sql("SELECT * FROM parquet.`examples/src/main/resources/users.parquet`")3.保存模式
保存操作可以选择使用saveMode的参数,该saveMode主要是指定在保存数据存在的情况下,以什么方式处理保存的数据。

val df = spark.read.json("file:///e:/employees.json")
df.write.format("json").mode(SaveMode.Append).save("e:/employees")4.保存为永久的表
使用 saveAsTable可以将DataFrame持久化为Hive中的表,对于基于文件的数据源( text, parquet, json等),在保存的时候可以指定一个具体的路径,比如 df.write.option("path", "/some/path").saveAsTable("t")(存储在指定路径下的文件格式为parquet)。当表被删除时,自定义的表的路径和表数据不会被移除。如果没有指定具体的路径,spark默认的是warehouse的目录(/user/hive/warehouse),当表被删除时,默认的表路径也会被删除。
从Spark 2.1开始,持久化数据源表会将每个分区元数据存储在Hive Metastore中。这带来了几个好处
(1)由于Metastore只返回查询所需要的分区,因此不再需要扫描所有分区。
(2)Hive 的DDL操作(比如 ALTER TABLE PARTITION ... SET LOCATION)可被用于使用Datasource API创建表。
请注意,在创建外部数据源表(带有path选项的表)时,默认情况下不会收集分区信息。要同步Metastore中的分区信息,可以调用MSCK REPAIR TABLE 表名 ,比如MSCK REPAIR TABLE people。
val df = spark.read.json("spark_data/people.json")
df.write.option("path","/user/root/spark_data/people").saveAsTable("people")5. 分桶、排序与分区
对于基于文件类型的数据源( text, parquet, json等) ,可以将保存的结果进行分桶、排序和分区。分桶和排序仅仅适用于输出为持久化表的情况 。
peopleDF.write.bucketBy(42, "name").sortBy("age").saveAsTable("people_bucketed")当使用DataSet的API时,对于save和saveAsTable而言,都可以使用分区 ,下面的第一条代码会在HDFS上的当前用户路径下产生一个文件夹namesPartByColor.parquet,里面包含了两个分区文件夹。第二条代码会在/user/hive/warehouse/namespartbycolor产生一个分区表。(下面两幅图为hue中的截图)
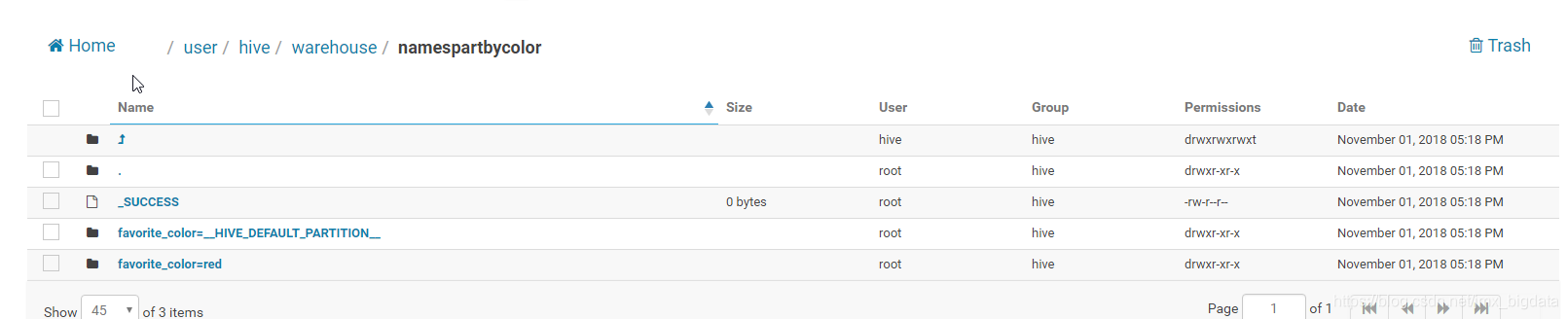

usersDF.write.partitionBy("favorite_color").format("parquet").save("namesPartByColor.parquet")
userDF.write.partitionBy("favorite_color").format("parquet").saveAsTable("namesPartByColor")
对于单独的一个表,可以同时使用分区和分桶
usersDF
.write
.partitionBy("favorite_color")
.bucketBy(42, "name")
.saveAsTable("users_partitioned_bucketed")二、Parquet文件
parquet是一种列存储格式的文件,支持许多的数据处理系统。Spark SQL 支持Parquet文件的读和写,当读取Parquet格式文件时,会自动保留原始文件的schema,当向Parquet文件写数据时,考虑到兼容性的原因,所有的列会自动被转为可以为null的类型。
1.编程的方式加载数据
val peopleDF = spark.read.json("examples/src/main/resources/people.json")
// DataFrames can be saved as Parquet files, maintaining the schema information
peopleDF.write.parquet("people.parquet")
// Read in the parquet file created above
// Parquet files are self-describing so the schema is preserved
// The result of loading a Parquet file is also a DataFrame
val parquetFileDF = spark.read.parquet("people.parquet")
// Parquet files can also be used to create a temporary view and then used in SQL statements
parquetFileDF.createOrReplaceTempView("parquetFile")
val namesDF = spark.sql("SELECT name FROM parquetFile WHERE age BETWEEN 13 AND 19")
namesDF.map(attributes => "Name: " + attributes(0)).show()
2.自动识别分区
表分区是Hive等系统中常用的优化方法。在分区表中,数据通常存储在不同的目录中。。所有内置文件源(包括Text / CSV / JSON / ORC / Parquet)都能够自动发现和推断分区信息。例如,我们可以使用以下目录结构将所有上面使用的数据存储到分区表中,使用两个额外的列,gender并country作为分区列:
path
└── to
└── table
├── gender=male
│ ├── ...
│ │
│ ├── country=US
│ │ └── data.parquet
│ ├── country=CN
│ │ └── data.parquet
│ └── ...
└── gender=female
├── ...
│
├── country=US
│ └── data.parquet
├── country=CN
│ └── data.parquet
└── ...通过传递path/to/table给SparkSession.read.parquet或者SparkSession.read.load,Spark SQL将自动从路径中提取分区信息。现在返回的DataFrame的schema为:
root
|-- name: string (nullable = true)
|-- age: long (nullable = true)
|-- gender: string (nullable = true)
|-- country: string (nullable = true)请注意,分区列的数据类型是自动推断的。目前仅支持numeric, date, timestamp 和String类型。有时,用户可能不希望自动推断分区列的数据类型。对于这些用例,可以配置自动类型推断spark.sql.sources.partitionColumnTypeInference.enabled,默认为true。禁用类型推断时,string类型将用于分区列。
从Spark 1.6.0开始,分区发现默认只查找给定路径下的分区。对于上面的示例,如果用户传递path/to/table/gender=male给 SparkSession.read.parquet或者SparkSession.read.load,gender则不会将其视为分区列。如果用户需要指定分区发现的起始基本路径,则可以在数据源选项中进行设置basePath。例如,当设置path/to/table/gender=male是数据的路径时,用户应当设置的basePath路径为path/to/table/,这样gender将是一个分区列。
3. 模式合并
与ProtocolBuffer,Avro和Thrift一样,Parquet也支持模式演化。用户可以从简单模式开始,并根据需要逐渐向模式添加更多列。通过这种方式,用户可能最终得到具有不同但相互兼容的模式的多个Parquet文件。Parquet数据源现在能够自动检测这种情况并合并所有这些文件的模式。
由于模式合并是一种相对耗费的操作,并且在大多数情况下不是必需的,因此默认从1.5.0开始关闭它。可以通过下面两种方式启用它:
(1)当读取Parquet文件时,设置数据源选项(option)的mergeSchema为true,或
(2)设置全局SQL选项(option),即将spark.sql.parquet.mergeSchema设置为true。
package com.company.sparksql
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.SparkSession
object ParquetSchemaMerging {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName("ParquetSchemaMerging")
.master("local")
.getOrCreate()
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
Logger.getLogger("org.apache.hadoop").setLevel(Level.OFF)
runParquetSchemaMergingExample(spark)
}
private def runParquetSchemaMergingExample(spark: SparkSession): Unit = {
// 导入隐式转换,用于将RDD转化为DataFrame.
import spark.implicits._
// 创建一个简单的 DataFrame,将其存储在一个分区目录里
val squaresDF = spark.sparkContext.makeRDD(1 to 5).map(i => (i, i * i)).toDF("value", "square")
//打印squaresDF的schema
squaresDF.printSchema()
// root
// |-- value: integer (nullable = false)
// |-- square: integer (nullable = false)
//将squaresDF保存在一个分区键为 key = 1的分区里
squaresDF.write.parquet("file:///e:/data/test_table/key=1")
// 在;另外一个分区目录里,创建一个简单的 DataFrame
// 新的DataFrame的列为value和cube,与上面的DataFrame相比,增加了cube列,删除了squarelie
val cubesDF = spark.sparkContext.makeRDD(6 to 10).map(i => (i, i * i * i)).toDF("value", "cube")
//打印cubesDF的schema
cubesDF.printSchema()
//将cubesDF保存在一个分区键为 key = 2的分区里
cubesDF.write.parquet("file:///e:/data/test_table/key=2")
// root
// |-- value: integer (nullable = false)
// |-- cube: integer (nullable = false)
// 读取分区目录里的文件,会自动识别分区,
// 其中option("mergeSchema", "true")的作用是开启模式合并
val mergedDF = spark.read.option("mergeSchema", "true").parquet("file:///e:/data/test_table")
mergedDF.printSchema()
//最终的schema由Parquet文件里的3列和分区列组成
// root
// |-- value: int (nullable = true)
// |-- square: int (nullable = true)
// |-- cube: int (nullable = true)
// |-- key: int (nullable = true)
}
}
查看存储的目录,会出现:

4.Hive中Parquet表的元数据转变
在读取和写入Hive 中的Parquet表时,为了获得更好的性能,park SQL将尝试使用自己的Parquet支持而不是Hive的 SerDe(序列化和反序列化)来获得更好的性能。此行为由spark.sql.hive.convertMetastoreParquet配置控制 ,默认情况下处于打开状态。
4.1Hive的Parquet表与Spark SQL的Parquet表的schema一致性协调
从表schema处理的角度来看,Hive和Parquet之间存在两个主要区别:
(1)Hive不区分大小写,而Parquet则不是
(2)Hive认为所有列都可以为空,而Parquet中的字段的可空性(nullability)更加的显著
由于这个原因,在将Hive Metastore Parquet表转换为Spark SQL Parquet表时,我们必须将Hive Metastore模式与Parquet模式进行协调一致。协调的规则是:
(1)不管字段是否为null,两个模式中具有相同名称的字段必须具有相同的数据类型。需要协调一致的字段应保持Parquet端的数据类型,以便遵循可空性(nullability)。
(2)需要被协调一致的schema包含了仅仅在Hive Metastore的schema中定义的字段(即,如果一些字段仅仅在Hive Metastore的schema中定义,那么这个schema就是需要被协调一致的schema)
a.任何仅出现在Parquet模式中的字段都将放在已协调一致的模式中。
b.任何仅出现在Hive Metastore模式中的字段都将在协调一致的模式中添加为可空字段。
4.2元数据刷新
Spark SQL缓存Parquet元数据以获得更好的性能。启用Hive Metastore Parquet表转换后,还会缓存这些转换表的元数据。如果这些表由Hive或其他外部工具更新,则需要手动刷新它们以确保元数据一致。
// spark is an existing SparkSession
spark.catalog.refreshTable("my_table")5.配置
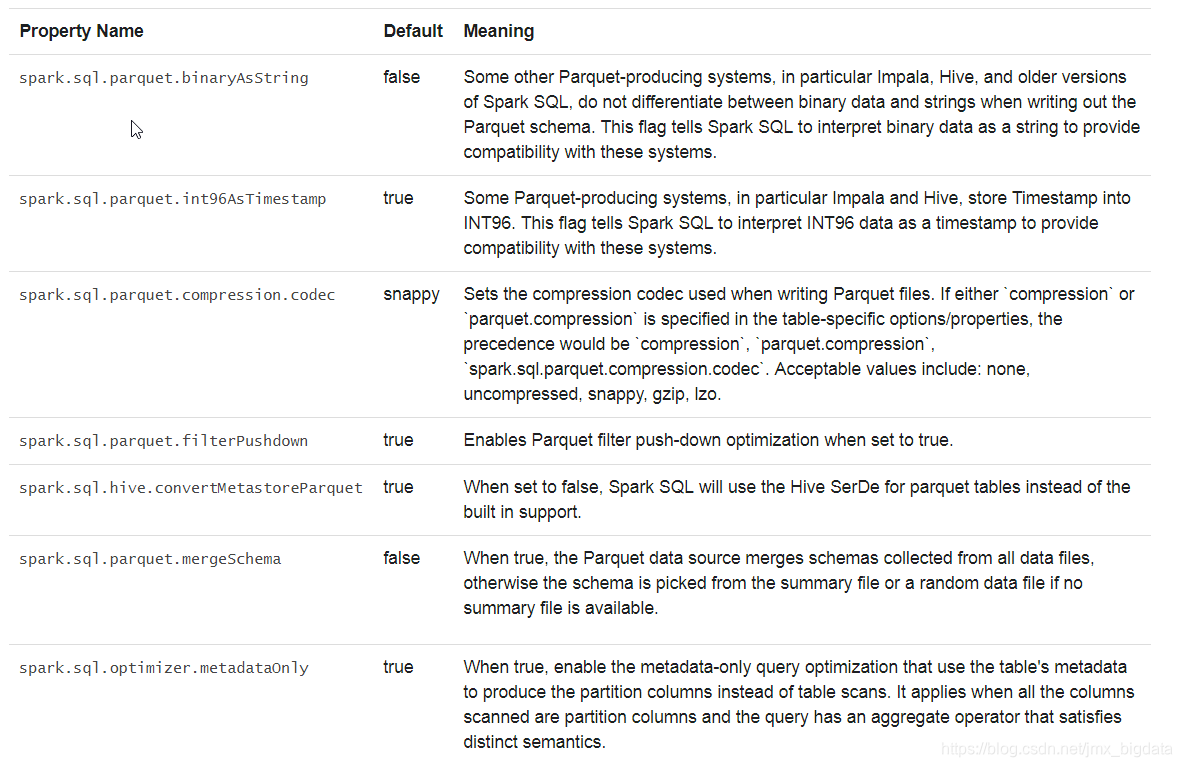
可以使用SparkSession的setConf方法或者通过SQL命令行设置SET key=value来配置Parquet
三、 ORC 文件
从Spark 2.3开始,Spark支持向量化的ORC读取器(Reader),该读取器对ORC文件而言,具有一个新的ORC文件格式。为了达到这种效果,需要添加以下新的配置。当spark.sql.orc.impl 设置为native和spark.sql.orc.enableVectorizedReader设置为true时,向量化的读取器可用于本地ORC表(例如,使用USING ORC子句创建的表)。对于Hive ORC serde表(例如,使用子句USING HIVE OPTIONS (fileFormat 'ORC')创建的表),当spark.sql.hive.convertMetastoreOrc也设置为true时,向量化读取器才可以被使用。

四、JSON 数据集
Spark SQL可以自动识别JSON数据集的schema,将其作为Dataset[Row]类型进行加载。在Dataset[String]或者JSON文件上使用SparkSession.read.json() ,也可以实现此功能。
package com.company.sparksql
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.SparkSession
object JSONSchema {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName("JSONSchema")
.master("local")
.getOrCreate()
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
Logger.getLogger("org.apache.hadoop").setLevel(Level.OFF)
runJsonDatasetExample(spark)
}
private def runJsonDatasetExample(spark: SparkSession): Unit = {
//当创建DataSet时,导入下面的隐式转换,
// 可以支持原始类型(Int, String, etc)以及Product类型 (case classes)编码器(encoders)
import spark.implicits._
//存储JSON文件的路径
//该路径可以是一个单独的文件,也可以是一个包含多个文件的目录
val path = "file:///e:/people.json"
val peopleDF = spark.read.json(path)
// 使用printSchema()方法打印peopleDF的schema
peopleDF.printSchema()
// root
// |-- age: long (nullable = true)
// |-- name: string (nullable = true)
// 使用DataFrame创建一个临时的视图,视图的名称为“people”
peopleDF.createOrReplaceTempView("people")
// 通过sql的方法运行SQL语句
val teenagerNamesDF = spark.sql("SELECT name FROM people WHERE age BETWEEN 13 AND 19")
teenagerNamesDF.show()
// +------+
// | name|
// +------+
// |Justin|
// +------+
val otherPeopleDataset = spark.createDataset(
"""{"name":"Yin","address":{"city":"Columbus","state":"Ohio"}}""" :: Nil)
val otherPeople = spark.read.json(otherPeopleDataset)
otherPeople.show()
// +---------------+----+
// | address|name|
// +---------------+----+
// |[Columbus,Ohio]| Yin|
// +---------------+----+
}
}
五、Hive 表
Spark SQL还支持读取和写入存储在Apache Hive中的数据。但是,由于Hive具有大量依赖项,因此这些依赖项不包含在默认的Spark发布包中。如果可以在类路径上找到Hive依赖项,Spark将自动加载它们。请注意,这些Hive依赖项也必须存在于所有工作节点(worker nodes)上,因为它们需要访问Hive序列化和反序列化库(SerDes)才能访问存储在Hive中的数据。
将hive-site.xml,core-site.xml(安全性配置),以及hdfs-site.xml(对于HDFS配置)文件放在conf/.下
在使用Hive时,必须实例化一个支持Hive的SparkSession,包括连接到持久性Hive Metastore,支持Hive 的序列化、反序列化(serdes)和Hive用户定义函数。没有部署Hive的用户仍可以启用Hive支持。如果未配置hive-site.xml,则上下文(context)会在当前目录中自动创建metastore_db,并且会创建一个由spark.sql.warehouse.dir配置的目录,其默认目录为spark-warehouse,位于启动Spark应用程序的当前目录中。请注意,自Spark 2.0.0以来,该在hive-site.xml中的hive.metastore.warehouse.dir属性已被标记过时(deprecated)。使用spark.sql.warehouse.dir用于指定warehouse中的默认位置。您可能需要向启动Spark应用程序的用户授予写入的权限。
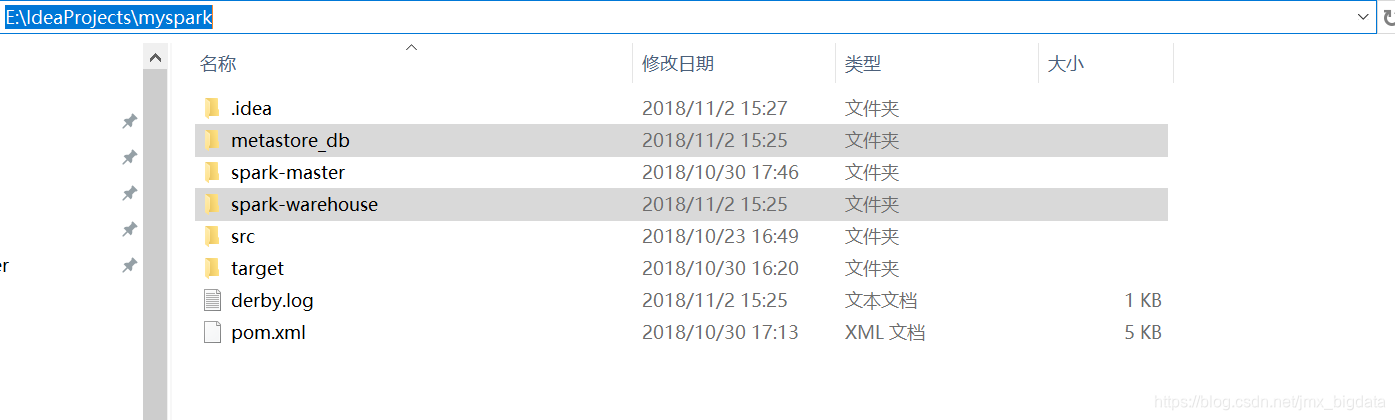
下面的案例为在本地运行(为了方便查看打印的结果),运行结束之后会发现在项目的目录下E:\IdeaProjects\myspark创建了spark-warehouse和metastore_db的文件夹。可以看出没有部署Hive的用户仍可以启用Hive支持,同时也可以将代码打包,放在集群上运行。
package com.company.sparksql
import java.io.File
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.{Row, SaveMode, SparkSession}
object SparkHiveExample {
case class Record(key: Int, value: String)
def main(args: Array[String]) {
// warehouse的默认位置
val warehouseLocation = new File("spark-warehouse").getAbsolutePath
val spark = SparkSession
.builder()
.appName("Spark Hive Example")
.config("spark.sql.warehouse.dir", warehouseLocation)
.master("local")//设置为本地运行
.enableHiveSupport()
.getOrCreate()
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
Logger.getLogger("org.apache.hadoop").setLevel(Level.OFF)
import spark.implicits._
import spark.sql
//使用Spark SQL 的语法创建Hive中的表
sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING) USING hive")
sql("LOAD DATA LOCAL INPATH 'file:///e:/kv1.txt' INTO TABLE src")
// 使用HiveQL查询
sql("SELECT * FROM src").show()
// +---+-------+
// |key| value|
// +---+-------+
// |238|val_238|
// | 86| val_86|
// |311|val_311|
// ...
// 支持使用聚合函数
sql("SELECT COUNT(*) FROM src").show()
// +--------+
// |count(1)|
// +--------+
// | 500 |
// +--------+
// SQL查询的结果是一个DataFrame,支持使用所有的常规的函数
val sqlDF = sql("SELECT key, value FROM src WHERE key < 10 ORDER BY key")
// DataFrames是Row类型的, 允许你按顺序访问列.
val stringsDS = sqlDF.map {
case Row(key: Int, value: String) => s"Key: $key, Value: $value"
}
stringsDS.show()
// +--------------------+
// | value|
// +--------------------+
// |Key: 0, Value: val_0|
// |Key: 0, Value: val_0|
// |Key: 0, Value: val_0|
// ...
//可以通过SparkSession使用DataFrame创建一个临时视图
val recordsDF = spark.createDataFrame((1 to 100).map(i => Record(i, s"val_$i")))
recordsDF.createOrReplaceTempView("records")
//可以用DataFrame与Hive中的表进行join查询
sql("SELECT * FROM records r JOIN src s ON r.key = s.key").show()
// +---+------+---+------+
// |key| value|key| value|
// +---+------+---+------+
// | 2| val_2| 2| val_2|
// | 4| val_4| 4| val_4|
// | 5| val_5| 5| val_5|
// ...
//创建一个Parquet格式的hive托管表,使用的是HQL语法,没有使用Spark SQL的语法("USING hive")
sql("CREATE TABLE hive_records(key int, value string) STORED AS PARQUET")
//读取Hive中的表,转换成了DataFrame
val df = spark.table("src")
//将该DataFrame保存为Hive中的表,使用的模式(mode)为复写模式(Overwrite)
//即如果保存的表已经存在,则会覆盖掉原来表中的内容
df.write.mode(SaveMode.Overwrite).saveAsTable("hive_records")
// 查询表中的数据
sql("SELECT * FROM hive_records").show()
// +---+-------+
// |key| value|
// +---+-------+
// |238|val_238|
// | 86| val_86|
// |311|val_311|
// ...
// 设置Parquet数据文件路径
val dataDir = "/tmp/parquet_data"
//spark.range(10)返回的是DataSet[Long]
//将该DataSet直接写入parquet文件
spark.range(10).write.parquet(dataDir)
// 在Hive中创建一个Parquet格式的外部表
sql(s"CREATE EXTERNAL TABLE hive_ints(key int) STORED AS PARQUET LOCATION '$dataDir'")
// 查询上面创建的表
sql("SELECT * FROM hive_ints").show()
// +---+
// |key|
// +---+
// | 0|
// | 1|
// | 2|
// ...
// 开启Hive动态分区
spark.sqlContext.setConf("hive.exec.dynamic.partition", "true")
spark.sqlContext.setConf("hive.exec.dynamic.partition.mode", "nonstrict")
// 使用DataFrame API创建Hive的分区表
df.write.partitionBy("key").format("hive").saveAsTable("hive_part_tbl")
//分区键‘key’将会在最终的schema中被移除
sql("SELECT * FROM hive_part_tbl").show()
// +-------+---+
// | value|key|
// +-------+---+
// |val_238|238|
// | val_86| 86|
// |val_311|311|
// ...
spark.stop()
}
}
1.指定Hive表的存储格式
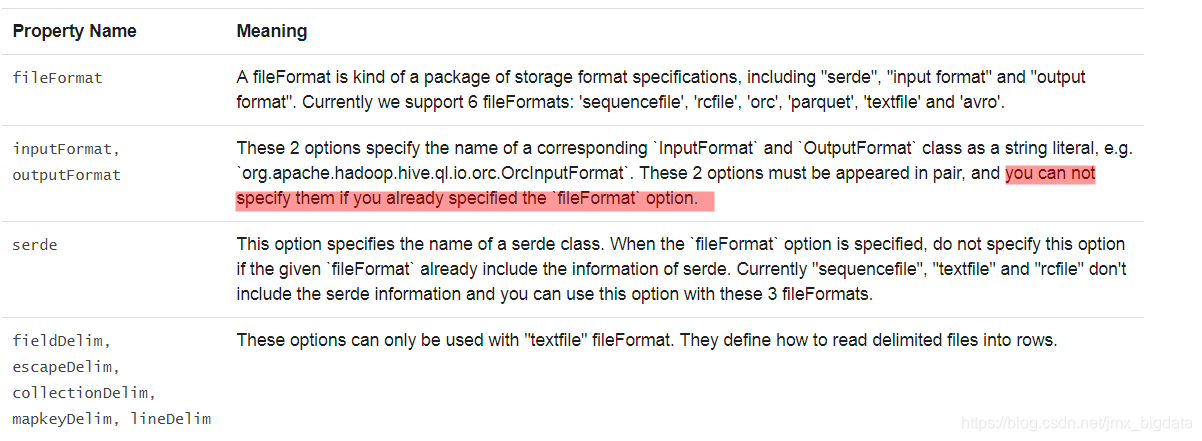
创建Hive表时,需要定义此表应如何从文件系统读取数据以及如何向文件系统中写入数据,即“输入格式”和“输出格式”。您还需要定义此表如何将数据反序列化为row,或将row序列化为数据,即“serde”(序列化和反序列化)。以下选项可用于指定存储格式( “serde”, “input format”, “output format”),例如CREATE TABLE src(id int) USING hive OPTIONS(fileFormat 'parquet')。默认情况下,我们将表文件作为纯文本读取。请注意,spark创建表时不支持Hive的存储处理程序(storage handler),您可以通过Hive使用Hive的存储处理程序(storage handler)创建表,并使用Spark SQL读取它。
2.与不同版本的Hive Metastore交互
Spark SQL的Hive支持最重要的部分之一是与Hive Metastore的交互,这使得Spark SQL能够访问Hive表的元数据。从Spark 1.4.0开始,可以使用单个二进制构建的Spark SQL来查询不同版本的Hive Metastores,使用下面描述的配置。请注意,独立于用于与Metastore通信的Hive版本,内部Spark SQL将针对Hive 1.2.1进行编译,并使用这些类进行内部执行(serdes,UDF,UDAF等)。
以下选项可用于配置用于检索元数据的Hive版本:

六、JDBC 方式
Spark SQL还包括一个可以使用JDBC从其他数据库读取数据的数据源。与使用JdbcRDD相比,此功能应该更受欢迎。这是因为结果作为DataFrame返回,它们可以在Spark SQL中轻松处理或与其他数据源连接。JDBC数据源也更易于使用Java或Python,因为它不需要用户提供ClassTag。(请注意,这与Spark SQL JDBC服务器不同,后者允许其他应用程序使用Spark SQL运行查询)。
可以使用Data Sources API将远程数据库中的表加载为DataFrame或Spark SQL临时视图。用户可以在数据源选项中指定JDBC连接属性。 user并且password通常作为用于登录数据源的连接属性提供。除连接属性外,Spark还支持以下不区分大小写的选项:


package com.company.sparksql
import java.util.Properties
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.{SaveMode, SparkSession}
object JdbcDatasetExample {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName("JdbcDatasetExample")
.master("local") //设置为本地运行
.getOrCreate()
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
Logger.getLogger("org.apache.hadoop").setLevel(Level.OFF)
runJdbcDatasetExample(spark)
}
private def runJdbcDatasetExample(spark: SparkSession): Unit = {
//注意:从JDBC源加载数据
val jdbcDF = spark.read
.format("jdbc")
.option("url", "jdbc:mysql://localhost/mydb")
.option("dbtable", "person")
.option("user", "root")
.option("password", "920724")
.load()
//打印jdbcDF的schema
jdbcDF.printSchema()
//打印数据
jdbcDF.show()
val connectionProperties = new Properties()
connectionProperties.put("user", "root")
connectionProperties.put("password", "920724")
//通过.jdbc的方式加载数据
val jdbcDF2 = spark.read
.jdbc("jdbc:mysql://localhost/mydb", "student", connectionProperties)
//打印jdbcDF的schema
jdbcDF2.printSchema()
//打印数据
jdbcDF2.show()
// 保存数据到JDBC源
jdbcDF.write
.format("jdbc")
.option("url", "jdbc:mysql://localhost/mydb")
.option("dbtable", "person2")
.option("user", "root")
.option("password", "920724")
.mode(SaveMode.Append)
.save()
jdbcDF2.write.mode(SaveMode.Append)
.jdbc("jdbc:mysql://localhost/mydb", "student2", connectionProperties)
}
}

全文完
参考:http://spark.apachecn.org/docs/cn/2.2.0/sql-programming-guide.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号