Flink on YARN执行流程
前置:
YARN客户端需要访问Hadoop的配置文件,从而能够连接到YARN资源管理器和HDFS。主要使用以下方式确定Hadoop的配置文件:
测试是否按顺序配置了YARN_CONF_DIR,HADOOP_CONF_DIR或HADOOP_CONF_PATH。如果配置了其中一个变量,则会读取该配置文件。
如果上述方式失败(在正确的YARN设置中不应该这样),则客户端会使用HADOOP_HOME环境变量。如果配置了该环境变量,则客户端尝试访问$HADOOP_HOME/etc/hadoop(Hadoop 2)和$HADOOP_HOME/conf(Hadoop 1)。
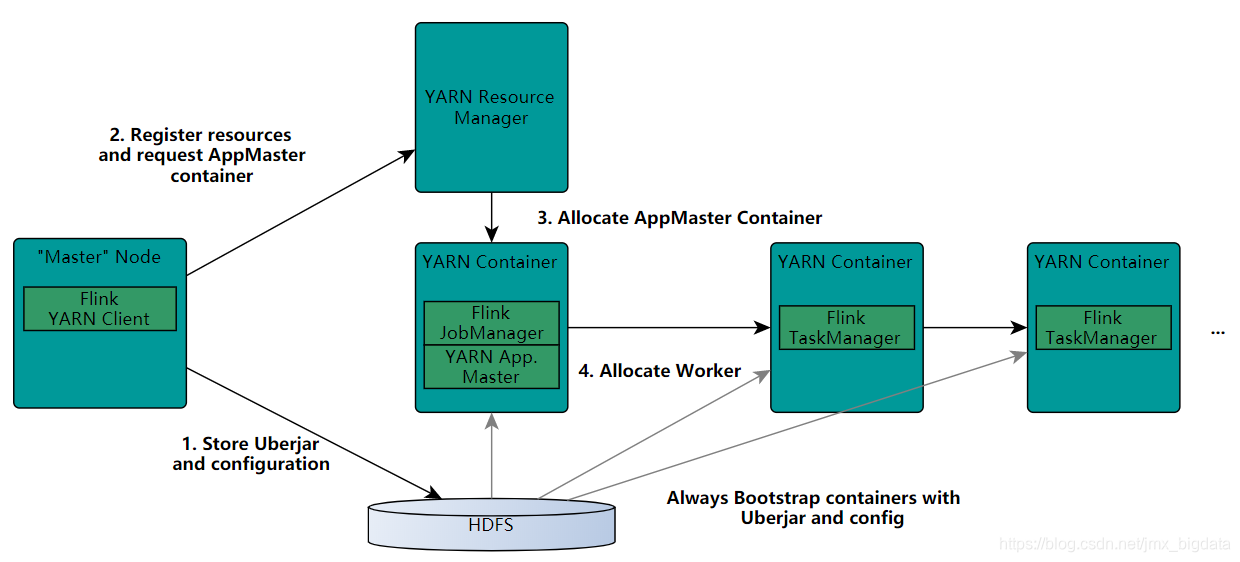
step1:启动新的FlinkYARN会话时,客户端首先检查所请求的资源(用于启动ApplicationMaster的内存和vcores)是否可用。然后,它将包含Flink 程序和配置文件的jar包上传到HDFS。
step2:客户端请求一个YARN的容器(container)用来启动ApplicationMaster。
step3:分配一个ApplicationMaster容器(container),并启动ApplicationMaster。由于客户端将配置文件和jar文件注册为容器的资源,因此NodeManager将负责准备容器(例如,下载文件)。完成后,将启动ApplicationMaster(AM)。该JobManager和AM在同一容器中运行,一旦成功启动,AM就知道JobManager的地址。
然后会为TaskManagers生成一个新的Flink配置文件(以便它们可以连接到JobManager),该文件会被上传到HDFS。此外,AM容器还提供Flink的Web界面。YARN代码分配的所有端口都是临时端口。这允许用户并行执行多个Flink YARN会话。
stop4:AM开始为Flink的TaskManagers分配容器,将从HDFS下载jar文件和修改后的配置。完成这些步骤后,可以接受jobs。
参考:https://ci.apache.org/projects/flink/flink-docs-release-1.8/ops/deployment/yarn_setup.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号