Hive的架构剖析
本文主要介绍Hive的架构和以及HQL的查询阶段,主要内容包括:
- Hive的架构
- 架构中的相关组件介绍
- HQL的查询阶段
Hive的架构
hive的基本架构图如下图所示:
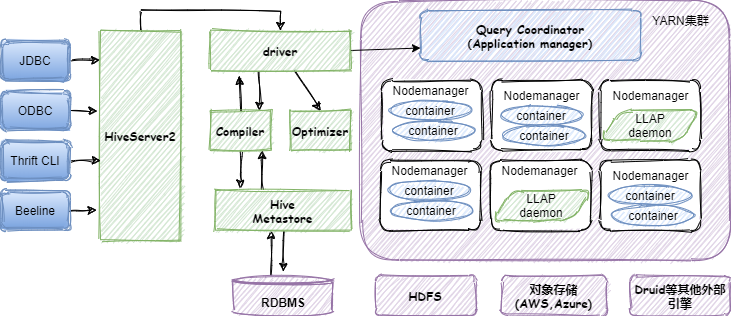
相关组件介绍
- 数据存储
Hive中的数据可以存储在任意与Hadoop兼容的文件系统,其最常见的存储文件格式主要有ORC和Parquet。除了HDFS之外,也支持一些商用的云对象存储,比如AWS S3等。另外,Hive可以读入并写入数据到其他的独立处理系统,比如Druid、HBase等。
- Data catalog
Hive使用Hive Metastore(HMS)存储元数据信息,使用关系型数据库来持久化存储这些信息,其依赖于DataNucleus(提供了标准的接口(JDO, JPA)来访问各种类型的数据库资源 ),用于简化操作各种关系型数据库。为了请求低延迟,HMS会直接通过DataNucleus直接查询关系型数据库。HMS的API支持多种编程语言。
- 执行引擎
最初版本的Hive支持MapReduce作为执行引擎,后来又支持
Tez和Spark作为执行引擎,这些执行引擎都可以运行在YARN上。
- 查询服务
Hiveserver2(HS2)允许用户执行SQL查询,Hiveserver2允许多个客户端提交请求到Hive并返回执行结果,HS2支持本地和远程JDBC和ODBC连接,另外Hive的发布版中包括一个JDBC的客户端,称之为Beeline。
- Hive客户端
Hive支持多种客户端,比如Python, Java, C++, Ruby等,可以使用JDBC、ODBC和Thrift drivers连接Hive,Hive的客户端主要归为3类:
(1)Thrift Clients
Hive的Server是基于Apache Thrift的,所以支持thrift客户端的查询请求
(2)JDBC Client
允许使用Java通过JDBC driver连接Hive,JDBC driver使用Thrift与Hive进行通信的
(3)ODBC Client
Hive的ODBC driver允许使用基于ODBC协议的应用来连接Hive,与JDBC driver类似,ODBC driver也是通过Thrift与Hive server进行通信的
- Hive Driver
Hive Driver接收来自客户端提交的HQL语句,创建session handles,并将查询发送到Compiler(编译器)。
- Hive Compiler
Hive的Compiler解析查询语句,编译器会借助Hive的metastore存储的元数据信息,对不同的查询块和查询表达式执行语义分析和类型检查,然后生成执行计划。
编译器生成的执行计划就是DAG,每个Stage可能代表一个MR作业。
- Optimizer(优化器)
比如列裁剪、谓词下推等优化,提升查询效率
执行过程
-
Step1:执行查询
通过客户端提交查询
-
Step2:获取执行计划
dirver接收到查询,会创建session handle,并将该查询传递给编译器,生成执行计划
-
Step3:获取元数据
编译器会向metastore发送获取元数据的请求
-
Step4:发送元数据
metastore向编译器发送元数据,编译器使用元数据执行类型检查和语义分析。编译器会生成执行计划(DAG),对于MapReduce作业而言,执行计划包括map operator trees
和reduce operator tree
-
Step5:发送执行计划
编译器向Driver发送生成的执行计划
-
Step6:执行查询计划
从编译器那里获取执行计划之后,Driver会向执行引擎发送执行计划
-
Step7:提交MR作业
-
Step8:返回查询结果
将查询结果通过Driver返回个查询客户端
HQL的查询阶段
Hive的查询阶段如下图所示,具体分析如下:

如上图所示,
- 1.用户提交查询到HS2
- 2.该查询被Driver处理,由编译器会解析该查询语句并从AST中生成一个Calcite逻辑计划
- 3.优化逻辑计划,HS2会访问关于HMS的元数据信息,用来达到验证和优化的目的
- 4.优化的逻辑计划被转换为物理执行计划
- 5.向量化的执行计划
- 6.生成具体的task,可以是mr或者spark、Tez,并通过Driver提交任务到YARN
- 7.执行结束后将结果返回给用户
总结
本文首先介绍了Hive的架构,并对每个组件进行了描述。然后阐述了Hive的具体执行过程,最后对HQL的执行阶段进行了说明。
公众号『大数据技术与数仓』,回复『资料』领取大数据资料包

 浙公网安备 33010602011771号
浙公网安备 33010602011771号