项目实践|基于Flink的用户行为日志分析系统
用户行为日志分析是实时数据处理很常见的一个应用场景,比如常见的PV、UV统计。本文将基于Flink从0到1构建一个用户行为日志分析系统,包括架构设计与代码实现。本文分享将完整呈现日志分析系统的数据处理链路,通过本文,你可以了解到:
- 基于discuz搭建一个论坛平台
- Flume日志收集系统使用方式
- Apache日志格式分析
- Flume与Kafka集成
- 日志分析处理流程
- 架构设计与完整的代码实现
项目简介
本文分享会从0到1基于Flink实现一个实时的用户行为日志分析系统,基本架构图如下:
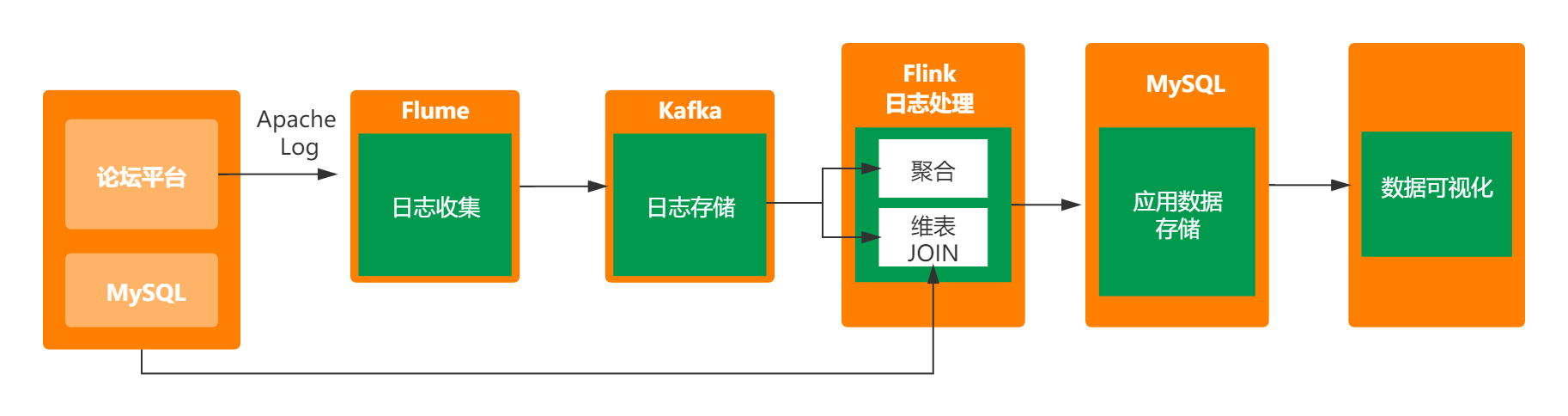
首先会先搭建一个论坛平台,对论坛平台产生的用户点击日志进行分析。然后使用Flume日志收集系统对产生的Apache日志进行收集,并将其推送到Kafka。接着我们使用Flink对日志进行实时分析处理,将处理之后的结果写入MySQL供前端应用可视化展示。本文主要实现以下三个指标计算:
- 统计热门板块,即访问量最高的板块
- 统计热门文章,即访问量最高的帖子文章
- 统计不同客户端对版块和文章的总访问量
基于discuz搭建一个论坛平台
安装XAMPP
- 下载
wget https://www.apachefriends.org/xampp-files/5.6.33/xampp-linux-x64-5.6.33-0-installer.run
- 安装
# 赋予文件执行权限
chmod u+x xampp-linux-x64-5.6.33-0-installer.run
# 运行安装文件
./xampp-linux-x64-5.6.33-0-installer.run
-
配置环境变量
将以下内容加入到 ~/.bash_profile
export XAMPP=/opt/lampp/
export PATH=$PATH:$XAMPP:$XAMPP/bin
- 刷新环境变量
source ~/.bash_profile
- 启动XAMPP
xampp restart
- MySQL的root用户密码和权限修改
#修改root用户密码为123qwe
update mysql.user set password=PASSWORD('123qwe') where user='root';
flush privileges;
#赋予root用户远程登录权限
grant all privileges on *.* to 'root'@'%' identified by '123qwe' with grant option;
flush privileges;
安装Discuz
- 下载discuz
wget http://download.comsenz.com/DiscuzX/3.2/Discuz_X3.2_SC_UTF8.zip
- 安装
#删除原有的web应用
rm -rf /opt/lampp/htdocs/*
unzip Discuz_X3.2_SC_UTF8.zip –d /opt/lampp/htdocs/
cd /opt/lampp/htdocs/
mv upload/*
#修改目录权限
chmod 777 -R /opt/lampp/htdocs/config/
chmod 777 -R /opt/lampp/htdocs/data/
chmod 777 -R /opt/lampp/htdocs/uc_client/
chmod 777 -R /opt/lampp/htdocs/uc_server/
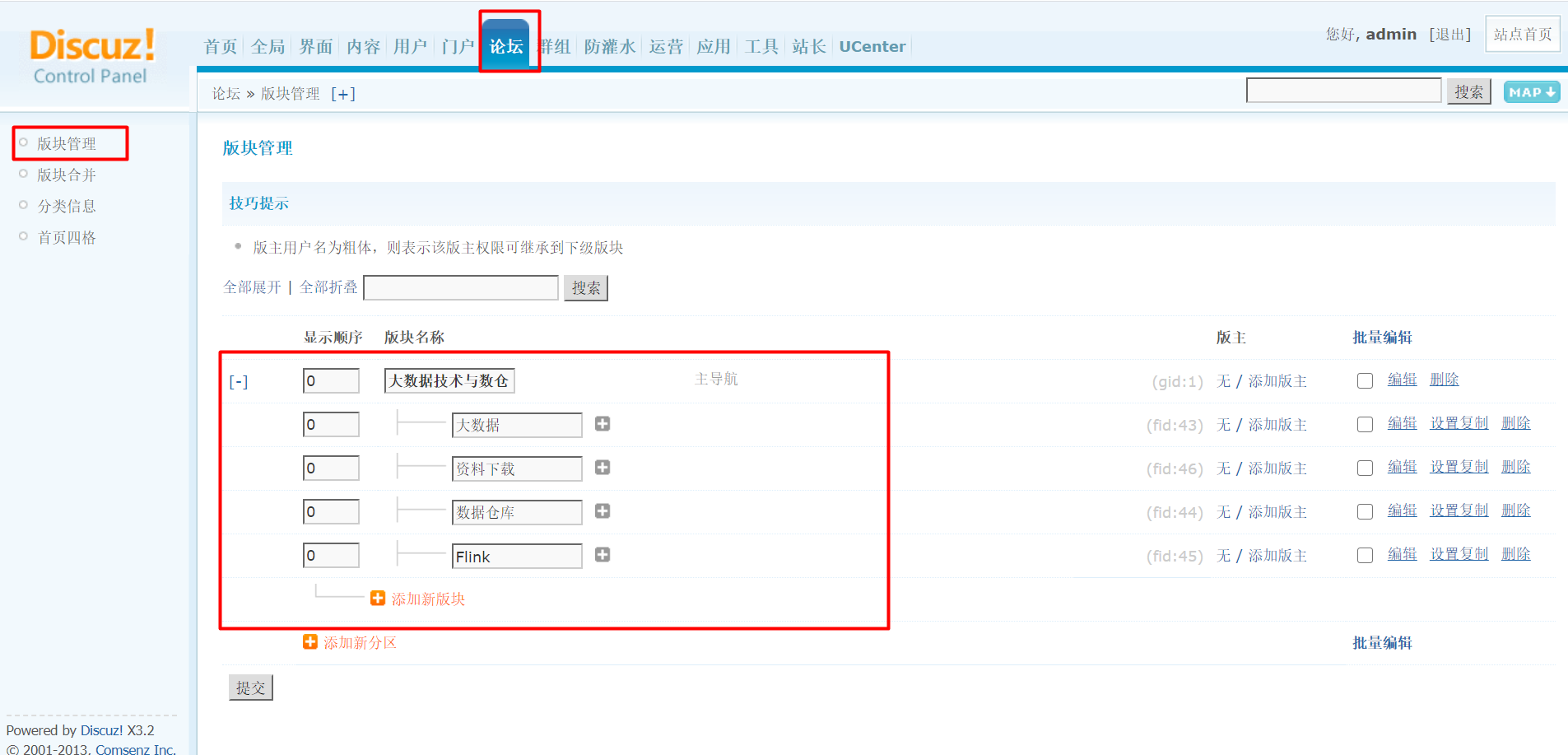
Discuz基本操作
- 自定义版块
- 进入discuz后台:http://kms-4/admin.php
- 点击顶部的论坛菜单
- 按照页面提示创建所需版本,可以创建父子版块
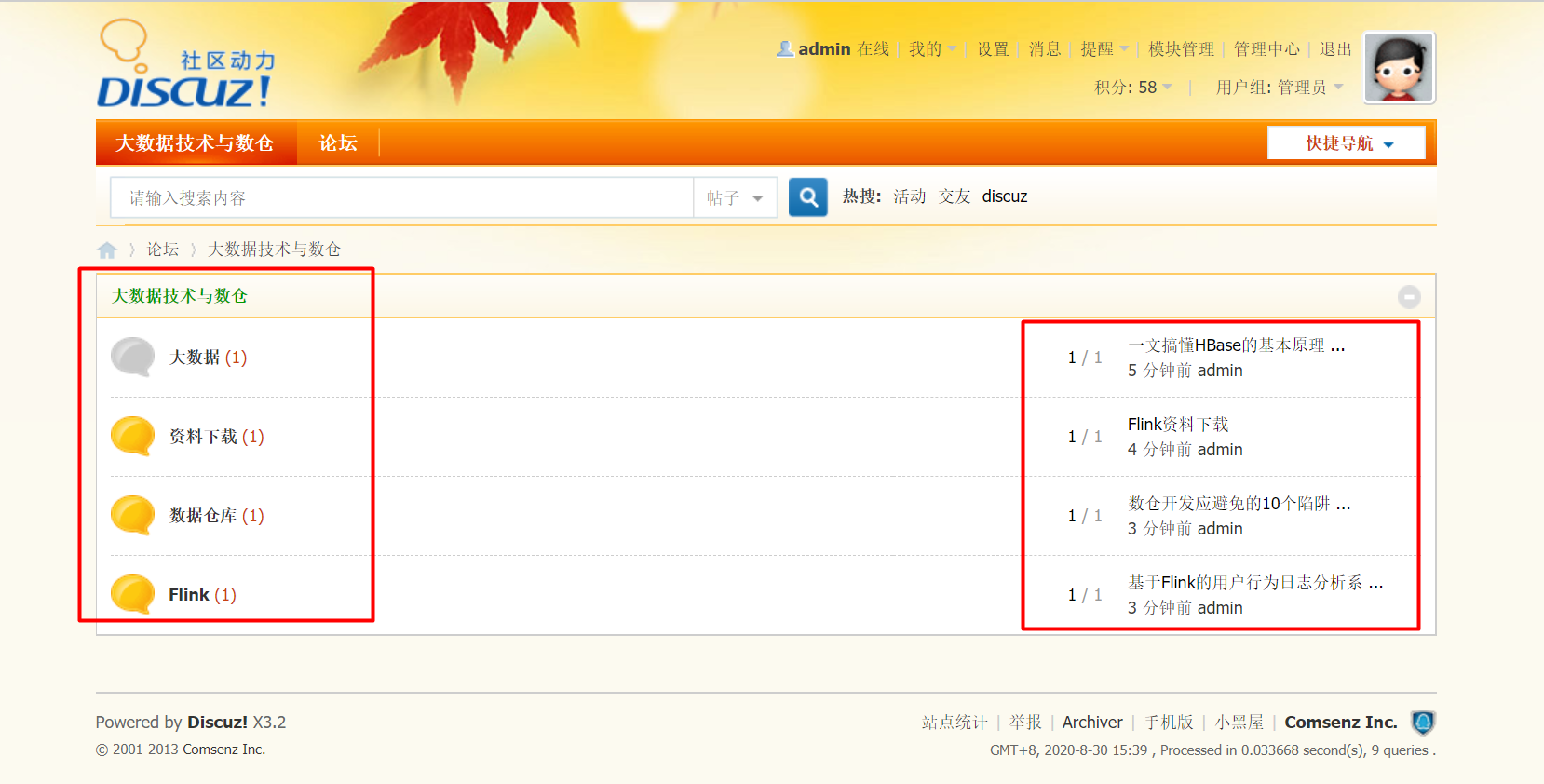
Discuz帖子/版块存储数据库表介
-- 登录ultrax数据库
mysql -uroot -p123 ultrax
-- 查看包含帖子id及标题对应关系的表
-- tid, subject(文章id、标题)
select tid, subject from pre_forum_post limit 10;
-- fid, name(版块id、标题)
select fid, name from pre_forum_forum limit 40;
当我们在各个板块添加帖子之后,如下所示:
修改日志格式
- 查看访问日志
# 日志默认地址
/opt/lampp/logs/access_log
# 实时查看日志命令
tail –f /opt/lampp/logs/access_log
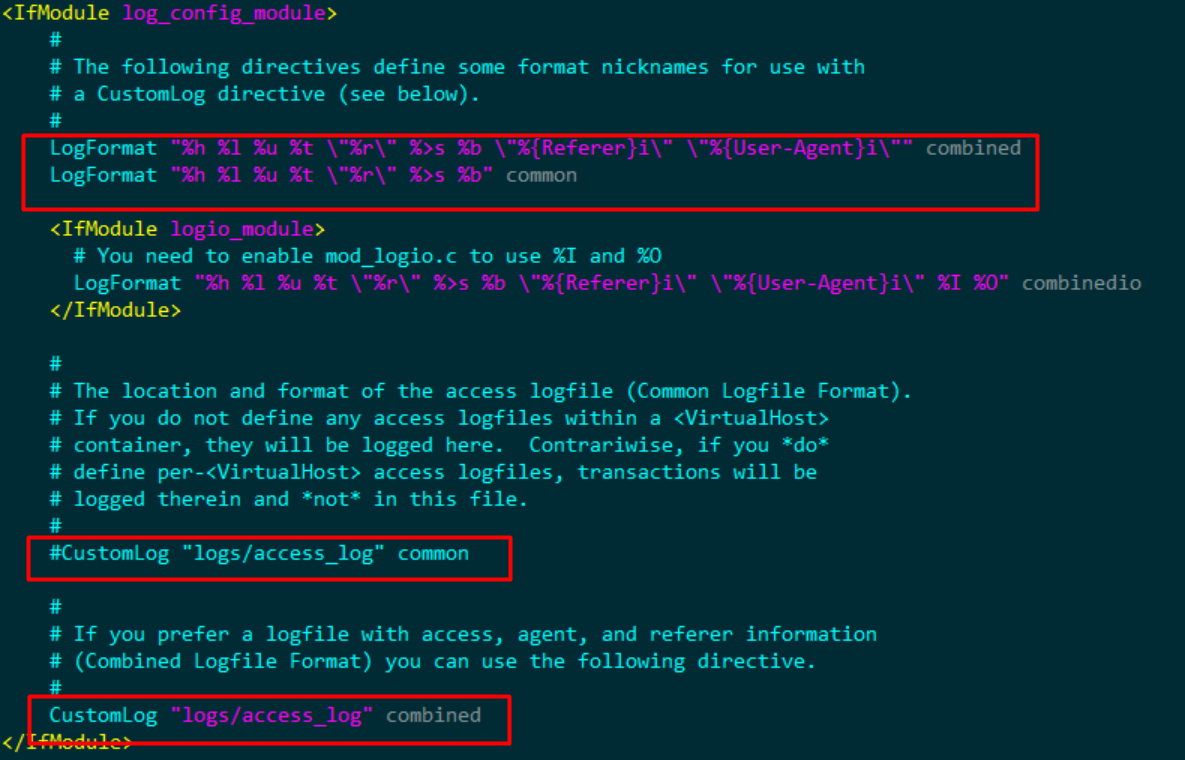
- 修改日志格式
Apache配置文件名称为httpd.conf,完整路径为/opt/lampp/etc/httpd.conf。由于默认的日志类型为common类型,总共有7个字段。为了获取更多的日志信息,我们需要将其格式修改为combined格式,该日志格式共有9个字段。修改方式如下:
# 启用组合日志文件
CustomLog "logs/access_log" combined
- 重新加载配置文件
xampp reload
Apache日志格式介绍
192.168.10.1 - - [30/Aug/2020:15:53:15 +0800] "GET /forum.php?mod=forumdisplay&fid=43 HTTP/1.1" 200 30647 "http://kms-4/forum.php" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.135 Safari/537.36"
上面的日志格式共有9个字段,分别用空格隔开。每个字段的具体含义如下:
192.168.10.1 ##(1)客户端的IP地址
- ## (2)客户端identity标识,该字段为"-"
- ## (3)客户端userid标识,该字段为"-"
[30/Aug/2020:15:53:15 +0800] ## (4)服务器完成请求处理时的时间
"GET /forum.php?mod=forumdisplay&fid=43 HTTP/1.1" ## (5)请求类型 请求的资源 使用的协议
200 ## (6)服务器返回给客户端的状态码,200表示成功
30647 ## (7)返回给客户端不包括响应头的字节数,如果没有信息返回,则此项应该是"-"
"http://kms-4/forum.php" ## (8)Referer请求头
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.135 Safari/537.36" ## (9)客户端的浏览器信息
关于上面的日志格式,可以使用正则表达式进行匹配:
(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}) (\S+) (\S+) (\[.+?\]) (\"(.*?)\") (\d{3}) (\S+) (\"(.*?)\") (\"(.*?)\")
Flume与Kafka集成
本文使用Flume对产生的Apache日志进行收集,然后推送至Kafka。需要启动Flume agent对日志进行收集,对应的配置文件如下:
# agent的名称为a1
a1.sources = source1
a1.channels = channel1
a1.sinks = sink1
# set source
a1.sources.source1.type = TAILDIR
a1.sources.source1.filegroups = f1
a1.sources.source1.filegroups.f1 = /opt/lampp/logs/access_log
a1sources.source1.fileHeader = flase
# 配置sink
a1.sinks.sink1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.sink1.brokerList=kms-2:9092,kms-3:9092,kms-4:9092
a1.sinks.sink1.topic= user_access_logs
a1.sinks.sink1.kafka.flumeBatchSize = 20
a1.sinks.sink1.kafka.producer.acks = 1
a1.sinks.sink1.kafka.producer.linger.ms = 1
a1.sinks.sink1.kafka.producer.compression.type = snappy
# 配置channel
a1.channels.channel1.type = file
a1.channels.channel1.checkpointDir = /home/kms/data/flume_data/checkpoint
a1.channels.channel1.dataDirs= /home/kms/data/flume_data/data
# 配置bind
a1.sources.source1.channels = channel1
a1.sinks.sink1.channel = channel1
知识点:
Taildir Source相比Exec Source、Spooling Directory Source的优势是什么?
TailDir Source:断点续传、多目录。Flume1.6以前需要自己自定义Source记录每次读取文件位置,实现断点续传
Exec Source:可以实时收集数据,但是在Flume不运行或者Shell命令出错的情况下,数据将会丢失
Spooling Directory Source:监控目录,不支持断点续传
值得注意的是,上面的配置是直接将原始日志push到Kafka。除此之外,我们还可以自定义Flume的拦截器对原始日志先进行过滤处理,同时也可以实现将不同的日志push到Kafka的不同Topic中。
启动Flume Agent
将启动Agent的命令封装成shell脚本:**start-log-collection.sh **,脚本内容如下:
#!/bin/bash
echo "start log agent !!!"
/opt/modules/apache-flume-1.9.0-bin/bin/flume-ng agent --conf-file /opt/modules/apache-flume-1.9.0-bin/conf/log_collection.conf --name a1 -Dflume.root.logger=INFO,console
查看push到Kafka的日志数据
将控制台消费者命令封装成shell脚本:kafka-consumer.sh,脚本内容如下:
#!/bin/bash
echo "kafka consumer "
bin/kafka-console-consumer.sh --bootstrap-server kms-2.apache.com:9092,kms-3.apache.com:9092,kms-4.apache.com:9092 --topic $1 --from-beginning
使用下面命令消费Kafka中的数据:
[kms@kms-2 kafka_2.11-2.1.0]$ ./kafka-consumer.sh user_access_logs
日志分析处理流程
为了方便解释,下面会对重要代码进行讲解,完整代码移步github:https://github.com/jiamx/flink-log-analysis
创建MySQL数据库和目标表
-- 客户端访问量统计
CREATE TABLE `client_ip_access` (
`client_ip` char(50) NOT NULL COMMENT '客户端ip',
`client_access_cnt` bigint(20) NOT NULL COMMENT '访问次数',
`statistic_time` text NOT NULL COMMENT '统计时间',
PRIMARY KEY (`client_ip`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 热门文章统计
CREATE TABLE `hot_article` (
`article_id` int(10) NOT NULL COMMENT '文章id',
`subject` varchar(80) NOT NULL COMMENT '文章标题',
`article_pv` bigint(20) NOT NULL COMMENT '访问次数',
`statistic_time` text NOT NULL COMMENT '统计时间',
PRIMARY KEY (`article_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 热门板块统计
CREATE TABLE `hot_section` (
`section_id` int(10) NOT NULL COMMENT '版块id',
`name` char(50) NOT NULL COMMENT '版块标题',
`section_pv` bigint(20) NOT NULL COMMENT '访问次数',
`statistic_time` text NOT NULL COMMENT '统计时间',
PRIMARY KEY (`section_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
AccessLogRecord类
该类封装了日志所包含的字段数据,共有9个字段。
/**
* 使用lombok
* 原始日志封装类
*/
@Data
public class AccessLogRecord {
public String clientIpAddress; // 客户端ip地址
public String clientIdentity; // 客户端身份标识,该字段为 `-`
public String remoteUser; // 用户标识,该字段为 `-`
public String dateTime; //日期,格式为[day/month/yearhourminutesecond zone]
public String request; // url请求,如:`GET /foo ...`
public String httpStatusCode; // 状态码,如:200; 404.
public String bytesSent; // 传输的字节数,有可能是 `-`
public String referer; // 参考链接,即来源页
public String userAgent; // 浏览器和操作系统类型
}
LogParse类
该类是日志解析类,通过正则表达式对日志进行匹配,对匹配上的日志进行按照字段解析。
public class LogParse implements Serializable {
//构建正则表达式
private String regex = "(\\d{1,3}\\.\\d{1,3}\\.\\d{1,3}\\.\\d{1,3}) (\\S+) (\\S+) (\\[.+?\\]) (\\\"(.*?)\\\") (\\d{3}) (\\S+) (\\\"(.*?)\\\") (\\\"(.*?)\\\")";
private Pattern p = Pattern.compile(regex);
/*
*构造访问日志的封装类对象
* */
public AccessLogRecord buildAccessLogRecord(Matcher matcher) {
AccessLogRecord record = new AccessLogRecord();
record.setClientIpAddress(matcher.group(1));
record.setClientIdentity(matcher.group(2));
record.setRemoteUser(matcher.group(3));
record.setDateTime(matcher.group(4));
record.setRequest(matcher.group(5));
record.setHttpStatusCode(matcher.group(6));
record.setBytesSent(matcher.group(7));
record.setReferer(matcher.group(8));
record.setUserAgent(matcher.group(9));
return record;
}
/**
* @param record:record表示一条apache combined 日志
* @return 解析日志记录,将解析的日志封装成一个AccessLogRecord类
*/
public AccessLogRecord parseRecord(String record) {
Matcher matcher = p.matcher(record);
if (matcher.find()) {
return buildAccessLogRecord(matcher);
}
return null;
}
/**
* @param request url请求,类型为字符串,类似于 "GET /the-uri-here HTTP/1.1"
* @return 一个三元组(requestType, uri, httpVersion). requestType表示请求类型,如GET, POST等
*/
public Tuple3<String, String, String> parseRequestField(String request) {
//请求的字符串格式为:“GET /test.php HTTP/1.1”,用空格切割
String[] arr = request.split(" ");
if (arr.length == 3) {
return Tuple3.of(arr[0], arr[1], arr[2]);
} else {
return null;
}
}
/**
* 将apache日志中的英文日期转化为指定格式的中文日期
*
* @param dateTime 传入的apache日志中的日期字符串,"[21/Jul/2009:02:48:13 -0700]"
* @return
*/
public String parseDateField(String dateTime) throws ParseException {
// 输入的英文日期格式
String inputFormat = "dd/MMM/yyyy:HH:mm:ss";
// 输出的日期格式
String outPutFormat = "yyyy-MM-dd HH:mm:ss";
String dateRegex = "\\[(.*?) .+]";
Pattern datePattern = Pattern.compile(dateRegex);
Matcher dateMatcher = datePattern.matcher(dateTime);
if (dateMatcher.find()) {
String dateString = dateMatcher.group(1);
SimpleDateFormat dateInputFormat = new SimpleDateFormat(inputFormat, Locale.ENGLISH);
Date date = dateInputFormat.parse(dateString);
SimpleDateFormat dateOutFormat = new SimpleDateFormat(outPutFormat);
String formatDate = dateOutFormat.format(date);
return formatDate;
} else {
return "";
}
}
/**
* 解析request,即访问页面的url信息解析
* "GET /about/forum.php?mod=viewthread&tid=5&extra=page%3D1 HTTP/1.1"
* 匹配出访问的fid:版本id
* 以及tid:文章id
* @param request
* @return
*/
public Tuple2<String, String> parseSectionIdAndArticleId(String request) {
// 匹配出前面是"forumdisplay&fid="的数字记为版块id
String sectionIdRegex = "(\\?mod=forumdisplay&fid=)(\\d+)";
Pattern sectionPattern = Pattern.compile(sectionIdRegex);
// 匹配出前面是"tid="的数字记为文章id
String articleIdRegex = "(\\?mod=viewthread&tid=)(\\d+)";
Pattern articlePattern = Pattern.compile(articleIdRegex);
String[] arr = request.split(" ");
String sectionId = "";
String articleId = "";
if (arr.length == 3) {
Matcher sectionMatcher = sectionPattern.matcher(arr[1]);
Matcher articleMatcher = articlePattern.matcher(arr[1]);
sectionId = (sectionMatcher.find()) ? sectionMatcher.group(2) : "";
articleId = (articleMatcher.find()) ? articleMatcher.group(2) : "";
}
return Tuple2.of(sectionId, articleId);
}
}
LogAnalysis类
该类是日志处理的基本逻辑
public class LogAnalysis {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment senv = StreamExecutionEnvironment.getExecutionEnvironment();
// 开启checkpoint,时间间隔为毫秒
senv.enableCheckpointing(5000L);
// 选择状态后端
// 本地测试
// senv.setStateBackend(new FsStateBackend("file:///E://checkpoint"));
// 集群运行
senv.setStateBackend(new FsStateBackend("hdfs://kms-1:8020/flink-checkpoints"));
// 重启策略
senv.setRestartStrategy(
RestartStrategies.fixedDelayRestart(3, Time.of(2, TimeUnit.SECONDS) ));
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(senv, settings);
// kafka参数配置
Properties props = new Properties();
// kafka broker地址
props.put("bootstrap.servers", "kms-2:9092,kms-3:9092,kms-4:9092");
// 消费者组
props.put("group.id", "log_consumer");
// kafka 消息的key序列化器
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// kafka 消息的value序列化器
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset", "earliest");
FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<String>(
"user_access_logs",
new SimpleStringSchema(),
props);
DataStreamSource<String> logSource = senv.addSource(kafkaConsumer);
// 获取有效的日志数据
DataStream<AccessLogRecord> availableAccessLog = LogAnalysis.getAvailableAccessLog(logSource);
// 获取[clienIP,accessDate,sectionId,articleId]
DataStream<Tuple4<String, String, Integer, Integer>> fieldFromLog = LogAnalysis.getFieldFromLog(availableAccessLog);
//从DataStream中创建临时视图,名称为logs
// 添加一个计算字段:proctime,用于维表JOIN
tEnv.createTemporaryView("logs",
fieldFromLog,
$("clientIP"),
$("accessDate"),
$("sectionId"),
$("articleId"),
$("proctime").proctime());
// 需求1:统计热门板块
LogAnalysis.getHotSection(tEnv);
// 需求2:统计热门文章
LogAnalysis.getHotArticle(tEnv);
// 需求3:统计不同客户端ip对版块和文章的总访问量
LogAnalysis.getClientAccess(tEnv);
senv.execute("log-analysisi");
}
/**
* 统计不同客户端ip对版块和文章的总访问量
* @param tEnv
*/
private static void getClientAccess(StreamTableEnvironment tEnv) {
// sink表
// [client_ip,client_access_cnt,statistic_time]
// [客户端ip,访问次数,统计时间]
String client_ip_access_ddl = "" +
"CREATE TABLE client_ip_access (\n" +
" client_ip STRING ,\n" +
" client_access_cnt BIGINT,\n" +
" statistic_time STRING,\n" +
" PRIMARY KEY (client_ip) NOT ENFORCED\n" +
")WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:mysql://kms-4:3306/statistics?useUnicode=true&characterEncoding=utf-8',\n" +
" 'table-name' = 'client_ip_access', \n" +
" 'driver' = 'com.mysql.jdbc.Driver',\n" +
" 'username' = 'root',\n" +
" 'password' = '123qwe'\n" +
") ";
tEnv.executeSql(client_ip_access_ddl);
String client_ip_access_sql = "" +
"INSERT INTO client_ip_access\n" +
"SELECT\n" +
" clientIP,\n" +
" count(1) AS access_cnt,\n" +
" FROM_UNIXTIME(UNIX_TIMESTAMP()) AS statistic_time\n" +
"FROM\n" +
" logs \n" +
"WHERE\n" +
" articleId <> 0 \n" +
" OR sectionId <> 0 \n" +
"GROUP BY\n" +
" clientIP "
;
tEnv.executeSql(client_ip_access_sql);
}
/**
* 统计热门文章
* @param tEnv
*/
private static void getHotArticle(StreamTableEnvironment tEnv) {
// JDBC数据源
// 文章id及标题对应关系的表,[tid, subject]分别为:文章id和标题
String pre_forum_post_ddl = "" +
"CREATE TABLE pre_forum_post (\n" +
" tid INT,\n" +
" subject STRING,\n" +
" PRIMARY KEY (tid) NOT ENFORCED\n" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:mysql://kms-4:3306/ultrax',\n" +
" 'table-name' = 'pre_forum_post', \n" +
" 'driver' = 'com.mysql.jdbc.Driver',\n" +
" 'username' = 'root',\n" +
" 'password' = '123qwe'\n" +
")";
// 创建pre_forum_post数据源
tEnv.executeSql(pre_forum_post_ddl);
// 创建MySQL的sink表
// [article_id,subject,article_pv,statistic_time]
// [文章id,标题名称,访问次数,统计时间]
String hot_article_ddl = "" +
"CREATE TABLE hot_article (\n" +
" article_id INT,\n" +
" subject STRING,\n" +
" article_pv BIGINT ,\n" +
" statistic_time STRING,\n" +
" PRIMARY KEY (article_id) NOT ENFORCED\n" +
")WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:mysql://kms-4:3306/statistics?useUnicode=true&characterEncoding=utf-8',\n" +
" 'table-name' = 'hot_article', \n" +
" 'driver' = 'com.mysql.jdbc.Driver',\n" +
" 'username' = 'root',\n" +
" 'password' = '123qwe'\n" +
")";
tEnv.executeSql(hot_article_ddl);
// 向MySQL目标表insert数据
String hot_article_sql = "" +
"INSERT INTO hot_article\n" +
"SELECT \n" +
" a.articleId,\n" +
" b.subject,\n" +
" count(1) as article_pv,\n" +
" FROM_UNIXTIME(UNIX_TIMESTAMP()) AS statistic_time\n" +
"FROM logs a \n" +
" JOIN pre_forum_post FOR SYSTEM_TIME AS OF a.proctime as b ON a.articleId = b.tid\n" +
"WHERE a.articleId <> 0\n" +
"GROUP BY a.articleId,b.subject\n" +
"ORDER BY count(1) desc\n" +
"LIMIT 10";
tEnv.executeSql(hot_article_sql);
}
/**
* 统计热门板块
*
* @param tEnv
*/
public static void getHotSection(StreamTableEnvironment tEnv) {
// 板块id及其名称对应关系表,[fid, name]分别为:版块id和板块名称
String pre_forum_forum_ddl = "" +
"CREATE TABLE pre_forum_forum (\n" +
" fid INT,\n" +
" name STRING,\n" +
" PRIMARY KEY (fid) NOT ENFORCED\n" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:mysql://kms-4:3306/ultrax',\n" +
" 'table-name' = 'pre_forum_forum', \n" +
" 'driver' = 'com.mysql.jdbc.Driver',\n" +
" 'username' = 'root',\n" +
" 'password' = '123qwe',\n" +
" 'lookup.cache.ttl' = '10',\n" +
" 'lookup.cache.max-rows' = '1000'" +
")";
// 创建pre_forum_forum数据源
tEnv.executeSql(pre_forum_forum_ddl);
// 创建MySQL的sink表
// [section_id,name,section_pv,statistic_time]
// [板块id,板块名称,访问次数,统计时间]
String hot_section_ddl = "" +
"CREATE TABLE hot_section (\n" +
" section_id INT,\n" +
" name STRING ,\n" +
" section_pv BIGINT,\n" +
" statistic_time STRING,\n" +
" PRIMARY KEY (section_id) NOT ENFORCED \n" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:mysql://kms-4:3306/statistics?useUnicode=true&characterEncoding=utf-8',\n" +
" 'table-name' = 'hot_section', \n" +
" 'driver' = 'com.mysql.jdbc.Driver',\n" +
" 'username' = 'root',\n" +
" 'password' = '123qwe'\n" +
")";
// 创建sink表:hot_section
tEnv.executeSql(hot_section_ddl);
//统计热门板块
// 使用日志流与MySQL的维表数据进行JOIN
// 从而获取板块名称
String hot_section_sql = "" +
"INSERT INTO hot_section\n" +
"SELECT\n" +
" a.sectionId,\n" +
" b.name,\n" +
" count(1) as section_pv,\n" +
" FROM_UNIXTIME(UNIX_TIMESTAMP()) AS statistic_time \n" +
"FROM\n" +
" logs a\n" +
" JOIN pre_forum_forum FOR SYSTEM_TIME AS OF a.proctime as b ON a.sectionId = b.fid \n" +
"WHERE\n" +
" a.sectionId <> 0 \n" +
"GROUP BY a.sectionId, b.name\n" +
"ORDER BY count(1) desc\n" +
"LIMIT 10";
// 执行数据insert
tEnv.executeSql(hot_section_sql);
}
/**
* 获取[clienIP,accessDate,sectionId,articleId]
* 分别为客户端ip,访问日期,板块id,文章id
*
* @param logRecord
* @return
*/
public static DataStream<Tuple4<String, String, Integer, Integer>> getFieldFromLog(DataStream<AccessLogRecord> logRecord) {
DataStream<Tuple4<String, String, Integer, Integer>> fieldFromLog = logRecord.map(new MapFunction<AccessLogRecord, Tuple4<String, String, Integer, Integer>>() {
@Override
public Tuple4<String, String, Integer, Integer> map(AccessLogRecord accessLogRecord) throws Exception {
LogParse parse = new LogParse();
String clientIpAddress = accessLogRecord.getClientIpAddress();
String dateTime = accessLogRecord.getDateTime();
String request = accessLogRecord.getRequest();
String formatDate = parse.parseDateField(dateTime);
Tuple2<String, String> sectionIdAndArticleId = parse.parseSectionIdAndArticleId(request);
if (formatDate == "" || sectionIdAndArticleId == Tuple2.of("", "")) {
return new Tuple4<String, String, Integer, Integer>("0.0.0.0", "0000-00-00 00:00:00", 0, 0);
}
Integer sectionId = (sectionIdAndArticleId.f0 == "") ? 0 : Integer.parseInt(sectionIdAndArticleId.f0);
Integer articleId = (sectionIdAndArticleId.f1 == "") ? 0 : Integer.parseInt(sectionIdAndArticleId.f1);
return new Tuple4<>(clientIpAddress, formatDate, sectionId, articleId);
}
});
return fieldFromLog;
}
/**
* 筛选可用的日志记录
*
* @param accessLog
* @return
*/
public static DataStream<AccessLogRecord> getAvailableAccessLog(DataStream<String> accessLog) {
final LogParse logParse = new LogParse();
//解析原始日志,将其解析为AccessLogRecord格式
DataStream<AccessLogRecord> filterDS = accessLog.map(new MapFunction<String, AccessLogRecord>() {
@Override
public AccessLogRecord map(String log) throws Exception {
return logParse.parseRecord(log);
}
}).filter(new FilterFunction<AccessLogRecord>() {
//过滤掉无效日志
@Override
public boolean filter(AccessLogRecord accessLogRecord) throws Exception {
return !(accessLogRecord == null);
}
}).filter(new FilterFunction<AccessLogRecord>() {
//过滤掉状态码非200的记录,即保留请求成功的日志记录
@Override
public boolean filter(AccessLogRecord accessLogRecord) throws Exception {
return !accessLogRecord.getHttpStatusCode().equals("200");
}
});
return filterDS;
}
}
将上述代码打包上传到集群运行,在执行提交命令之前,需要先将Hadoop的依赖jar包放置在Flink安装目录下的lib文件下:flink-shaded-hadoop-2-uber-2.7.5-10.0.jar,因为我们配置了HDFS上的状态后端,而Flink的release包不含有Hadoop的依赖Jar包。

否则会报如下错误:
Caused by: org.apache.flink.core.fs.UnsupportedFileSystemSchemeException: Hadoop is not in the classpath/dependencies.
提交到集群
编写提交命令脚本
#!/bin/bash
/opt/modules/flink-1.11.1/bin/flink run -m kms-1:8081 \
-c com.jmx.analysis.LogAnalysis \
/opt/softwares/com.jmx-1.0-SNAPSHOT.jar
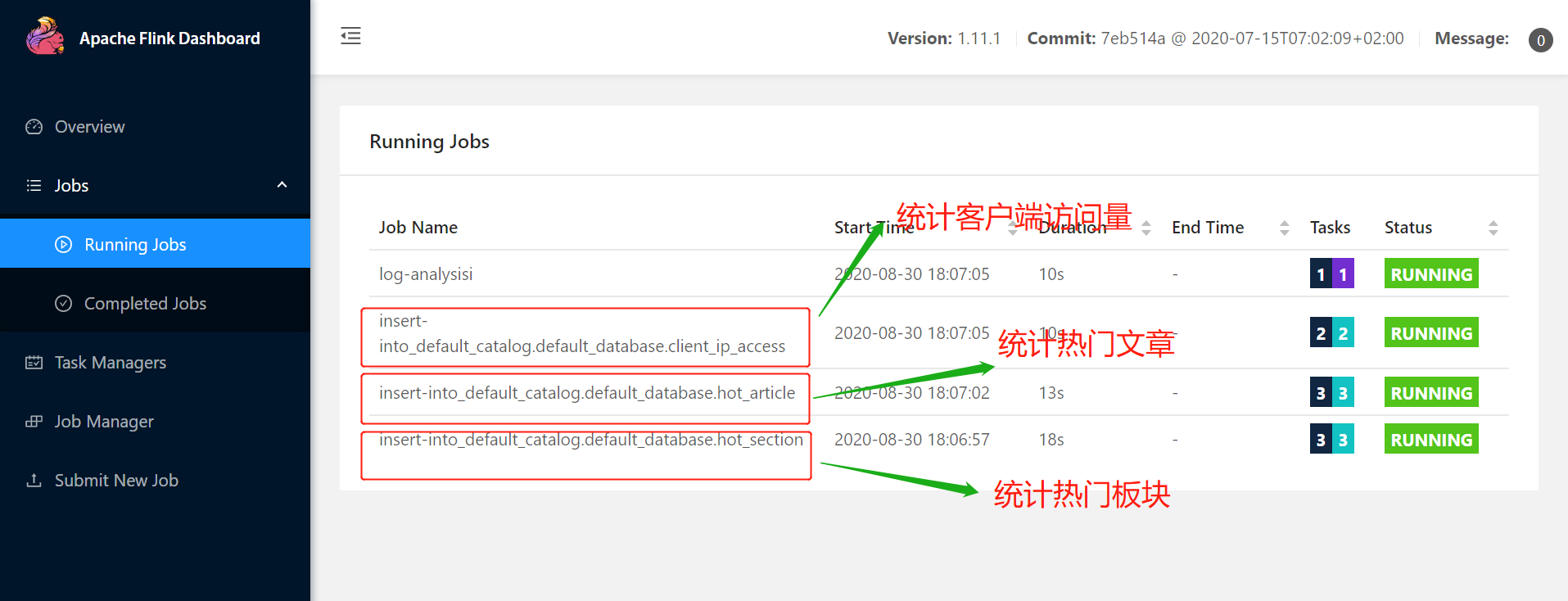
提交之后,访问Flink的Web界面,查看任务:
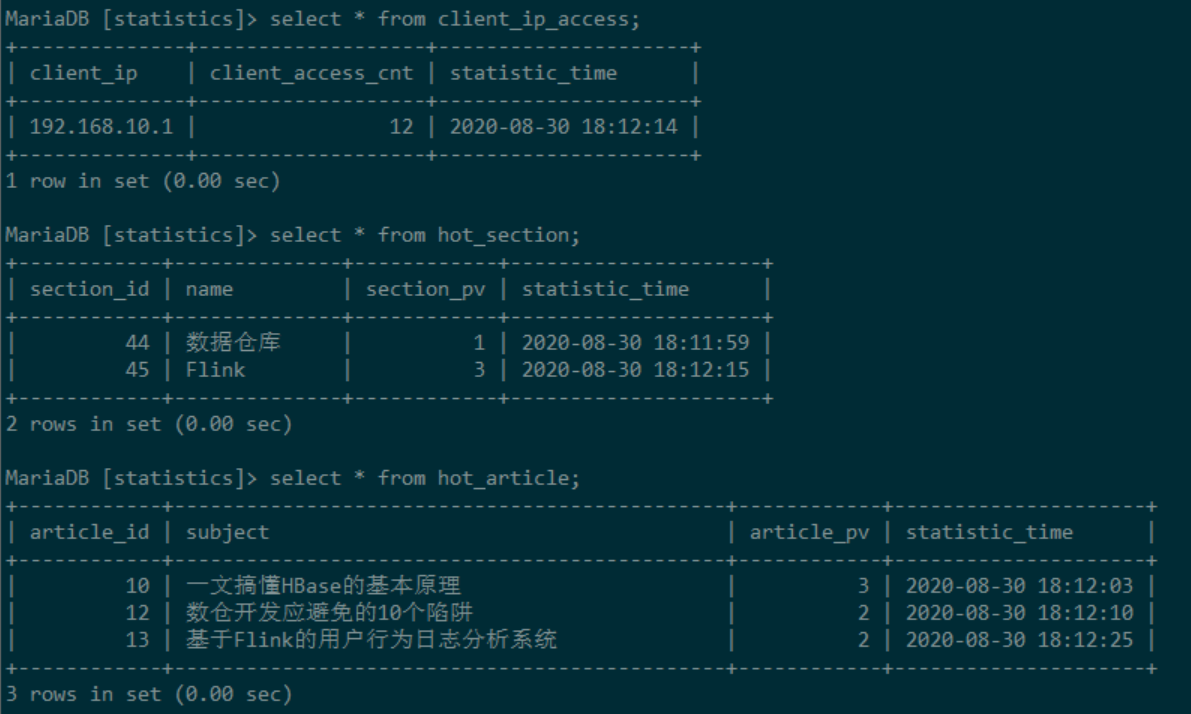
此时访问论坛,点击板块和帖子文章,观察数据库变化:
总结
本文主要分享了从0到1构建一个用户行为日志分析系统。首先,基于discuz搭建了论坛平台,针对论坛产生的日志,使用Flume进行收集并push到Kafka中;接着使用Flink对其进行分析处理;最后将处理结果写入MySQL供可视化展示使用。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号