
Flink运行架构剖析 转





Flink Runtime作业执行流程分析
整体架构图
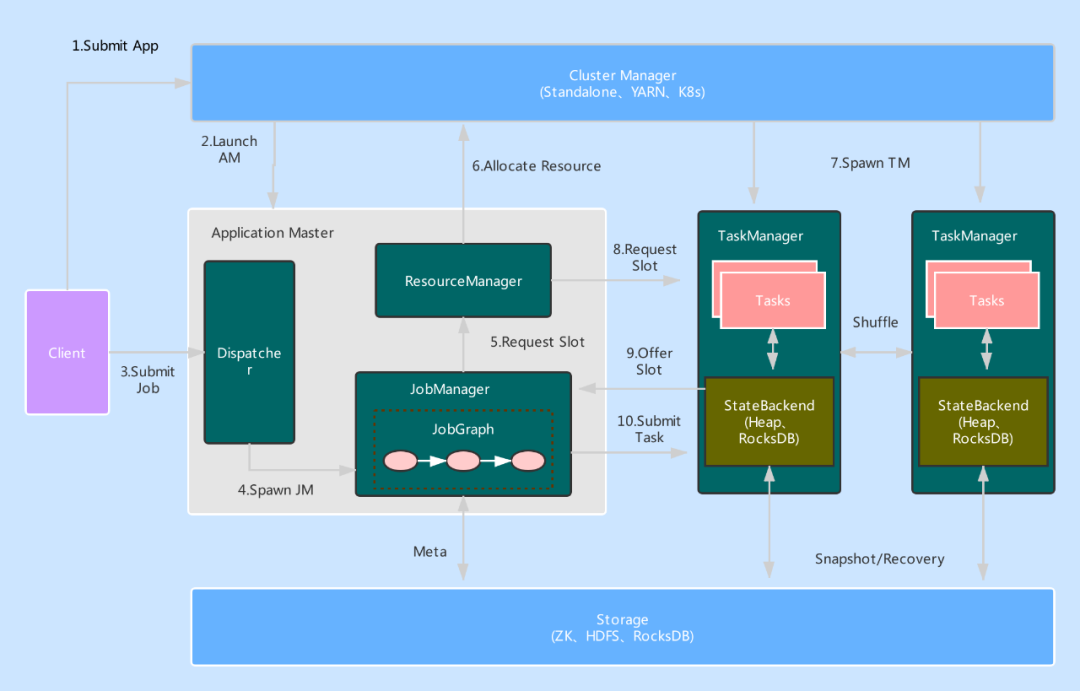
执行流程分析
组件介绍
流程分析
1.当用户提交作业的时候,提交脚本会首先启动一个 Client进程负责作业的编译与提交。它首先将用户编写的代码编译为一个 JobGraph,在这个过程,它还会进行一些检查或优化等工作,例如判断哪些 Operator 可以 Chain 到同一个 Task 中。然后,Client 将产生的 JobGraph 提交到集群中执行。此时有两种情况,一种是类似于 Standalone 这种 Session 模式,AM 会预先启动,此时 Client 直接与 Dispatcher 建立连接并提交作业即可。另一种是 Per-Job 模式,AM 不会预先启动,此时 Client 将首先向资源管理系统 (如Yarn、K8S)申请资源来启动 AM,然后再向 AM 中的 Dispatcher 提交作业。
2.当作业到 Dispatcher 后,Dispatcher 会首先启动一个 JobManager 组件,然后 JobManager 会向 ResourceManager 申请资源来启动作业中具体的任务。如果是Session模式,则TaskManager已经启动了,就可以直接分配资源。如果是per-Job模式,ResourceManager 也需要首先向外部资源管理系统申请资源来启动 TaskExecutor,然后等待 TaskExecutor 注册相应资源后再继续选择空闲资源进程分配,JobManager 收到 TaskExecutor 注册上来的 Slot 后,就可以实际提交 Task 了。
3.TaskExecutor 收到 JobManager 提交的 Task 之后,会启动一个新的线程来执行该 Task。Task 启动后就会开始进行预先指定的计算,并通过数据 Shuffle 模块互相交换数据。
Flink Standalone运行架构
Flink Standalone运行架构如下图所示:
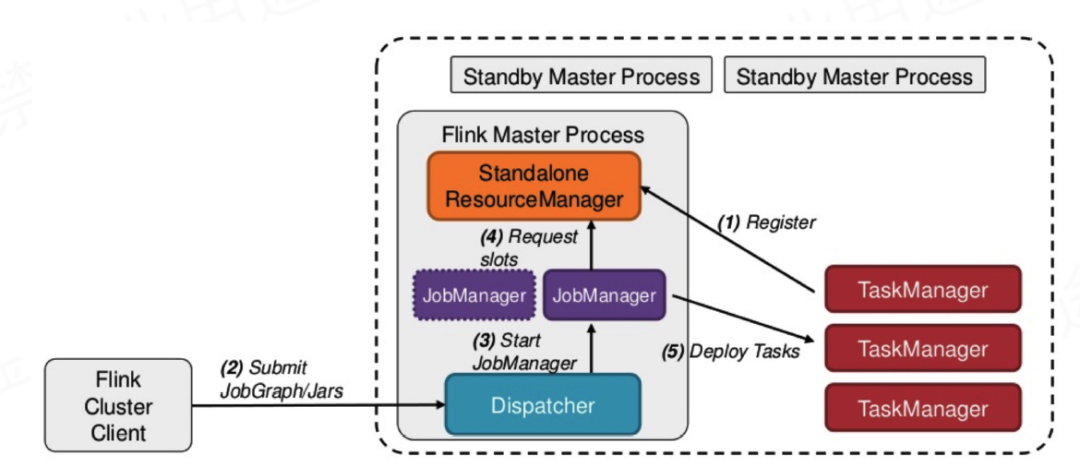
Standalone模式需要先启动Jobmanager和TaskManager进程,每一个作业都是自己的JobManager。 Client:任务提交,生成JobGraph
JobManager:调度Job,协调Task,通信,申请资源
TaskManager:具体任务执行,请求资源
Flink On YARN运行架构
关于YARN的基本架构原理,详见另一篇我的另一篇文章YARN架构原理
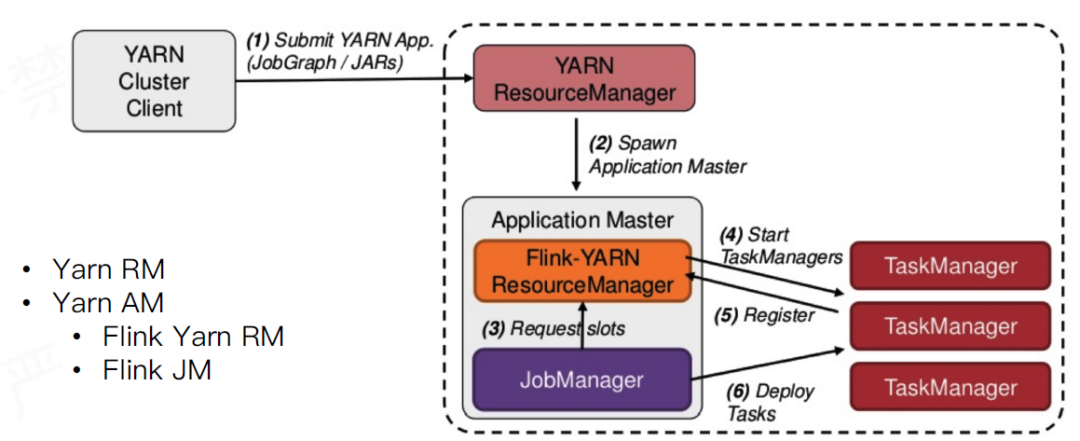
Per-Job模式
Per-job 模式下整个 Flink 集群只执行单个作业,即每个作业会独享 Dispatcher 和 ResourceManager 组件。此外,Per-job 模式下 AppMaster 和 TaskExecutor 都是按需申请的。因此,Per-job 模式更适合运行执行时间较长的大作业,这些作业对稳定性要求较高,并且对申请资源的时间不敏感。
1.独享Dispatcher与ResourceManager
2.按需申请资源(TaskExecutor)
3.适合执行时间较长的大作业
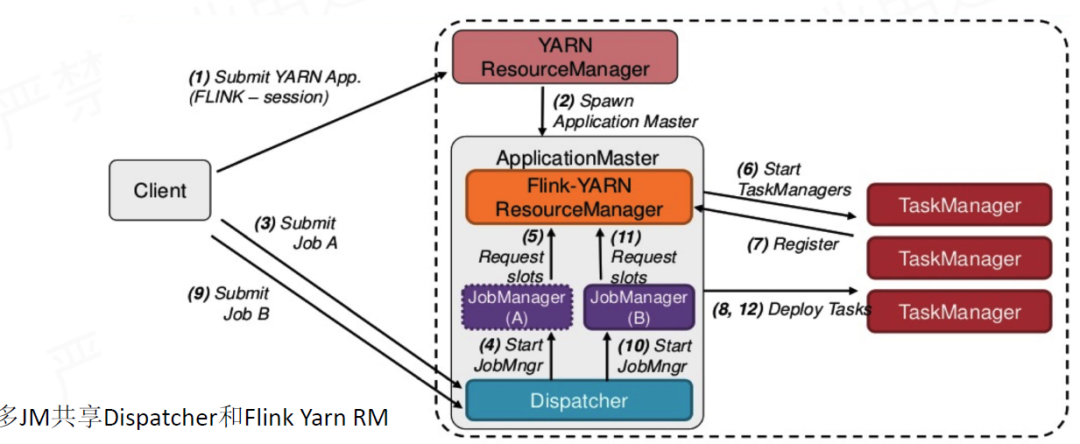
Session模式
在 Session 模式下,Flink 预先启动 AppMaster 以及一组 TaskExecutor,然后在整个集群的生命周期中会执行多个作业。可以看出,Session 模式更适合规模小,执行时间短的作业。
1.共享Dispatcher与ResourceManager
2.共享资源
3.适合小规模,执行时间较短的作业

完

本文分享自微信公众号 - 大数据技术与数仓(gh_95306769522d)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号