

数据仓库性能测试方法论与工具集
2023-07-04 10:21 云物互联 阅读(534) 评论(0) 编辑 收藏 举报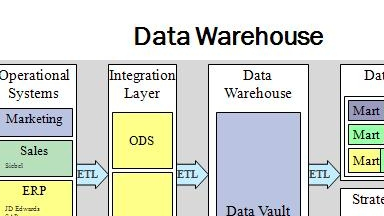 数据仓库是数据库的下一代产品形态 —— 如何对数字化转型过程中涌现的数据集合进行有效的存储、分析和利用,继而帮忙企业进行运营决策优化甚至创造出新的获客模式和商业模式形成竞争力,是企业主们亟需解决的问题。在数据价值爆发的时代背景中,数据仓库在千行百业中都有着相应的应用场景。
数据仓库是数据库的下一代产品形态 —— 如何对数字化转型过程中涌现的数据集合进行有效的存储、分析和利用,继而帮忙企业进行运营决策优化甚至创造出新的获客模式和商业模式形成竞争力,是企业主们亟需解决的问题。在数据价值爆发的时代背景中,数据仓库在千行百业中都有着相应的应用场景。
目录
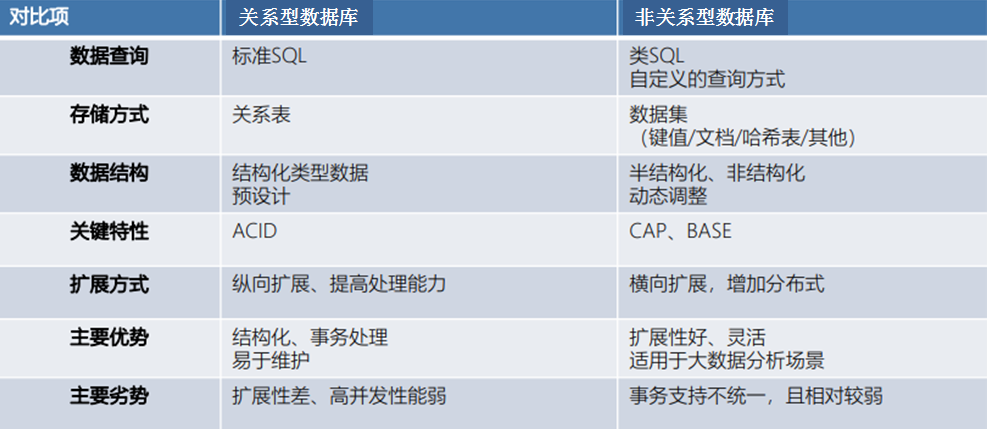
数据仓库 v.s. 传统数据库
随着 5G 网络和 IoT 技术的兴起,以及越来越复杂多变的企业经营环境,都在促使着包括工业制造、能源、交通、教育和医疗在内的传统行业纷纷开启了数字化转型之路。由于长尾效应的存在,千行百业的数字化转型过程中必然会释放出比以往任何时候都要庞大的海量数据。那么如何对这些涌现的数据集合进行有效的存储、分析和利用,继而帮忙企业进行运营决策优化甚至创造出新的获客模式和商业模式形成竞争力,就成为了摆在企业主面前亟需解决的问题。
在这样的需求背景下,我们也观察到近年来市场上正在出现越来越多的数据仓库产品。数据仓库(Data Warehouse)是一种用于集成、存储和分析大规模结构化数据与非结构化数据的数据管理系统。相对于传统的仅用于数据存储的数据库(Database)而言,数据仓库更是一种专门设计的 “数据存储 + 数据分析 + 数据管理" 一体化解决方案,强调数据的易用性、可分析性和可管理性,提供了包括:数据清洗、整合、转换、复杂查询、报表生成和数据分析等功能,用于帮助企业实现基于数据的决策制定和数字化运营场景。
更具体而言,下列表格中从技术层面更细致的对比了两者的区别:
| 对比项 | 传统数据库 | 云原生数据仓库 |
|---|---|---|
| 需求面向 | 面向数据存储,主要用于支持事务处理以满足业务操作的需求。 | 面向大规模数据存储与高效能数据分析,主要用于数据分析和决策支持和,以满足企业的报表、分析和数据挖掘需求。 |
| 数据结构和组织方式 | 通常以表格的形式组织数据,采用关系型数据模型,通过 SQL 语句进行数据操作。 | 采用星型或雪花型的结构,将数据组织成事实表和维度表,通过复杂的查询和分析操作进行数据处理。 |
| 数据处理复杂性 | 通常处理相对较小规模和实时的数据。 | 处理的数据量通常很大,并且涉及到多个源系统的数据集成和转换,需要处理复杂的查询和分析操作,同时兼容 SQL 语句。 |
| 可扩展性 | 从分析到方案制定再到落地实施,周期较长。 | 在线水平扩展,分钟级扩展。 |
| 数据量级 | 一般处理 TB 左右以下性能良好,随着数据量增加维护难度增加。 | 支持 TB 至 PB 量级,通过平台管理功能进行运维实例管理和监控。 |
| DBA 维护成本 | 工作量较大,中间件,SQL 优化性能分析要求 DBA 有丰富的技术经验。 | 平台化运维管理,功能模块化处理,DBA 工作更便捷高效。 |
| 数据分片 | 引用中间件层需要手动维护分片规则,制定不当容易出现数据倾斜。 | 分布式数据库自身具有路由分片算法,分布相对均匀可按需调整。 |
可见,在数据价值爆发的时代背景中,数据仓库在千行百业中都有着相应的应用场景,例如:
- 金融和银行业:应用数据仓库平台对大量的金融数据进行分析和建模,继而支持风险评估、交易分析和决策制定。
- 零售和电子商务行业:应用数据仓库平台完成销售分析、供应链分析、客户行为分析等,帮助零售商了解产品销售情况、优化库存策略、提升客户满意度,并进行个性化推荐和营销活动。
- 市场营销和广告行业:应用数据仓库平台整合不同渠道的市场数据和客户行为数据,帮助企业了解客户需求,支持目标市场分析、广告效果评估、客户细分等工作。

基于以上原因,我们也希望能够与时俱进地去考察市场上的数据仓库产品的特性,并以此支撑公司技术选型工作。技术选型是一项系统且严谨的工作内容,需要从功能、性能、成熟度、可控性、成本等多个方面进行考虑,本文则主要关注在性能方面,尝试探讨一种可复用的性能测试方案,包括:性能指标、方法论和工具集这 3 个方面的内容。
数据仓库性能测试案例
性能指标
数据仓库的性能指标需要根据具体的应用场景来设定,但通常的会包括以下几个方面:
- 读写性能:衡量数据仓库在读取和写入数据方面的性能表现。包括:吞吐量(每秒处理的请求数量)、延迟(请求的响应时间)、并发性(同时处理的请求数量)等。
- 水平扩展性:衡量数据仓库在大规模系统中的水平扩展能力,能够随着客户端的并发增长而进行弹性扩展,并获得线性的性能提升。
- 数据一致性:测试数据仓库在分布式环境中的数据一致性保证程度。根据应用场景的不同,对数据强一致性、弱一致性、最终一致性会有不同的侧重。
- 故障恢复和高可用性:测试数据仓库在面对故障时的恢复能力和高可用性。可以模拟节点故障或网络分区等场景,评估数据仓库的故障转移和数据恢复性能。
- 数据安全性:评估数据仓库在数据保护方面的性能。包括:数据的备份和恢复速度、数据加密和访问控制等。
- 集群管理和资源利用率:评估数据仓库在集群管理和资源利用方面的性能。包括:节点的动态扩缩容、负载均衡、资源利用率等。
- 数据库管理工具性能:评估数据仓库管理工具在配置、监控、诊断和优化等方面的性能表现。
在本文中主要关注读写性能方面的操作实践。
测试方案
为了进一步完善测试流程,以及对国产数据仓库大趋势的倾向性,所以本文采用了相对方便获取且同样都是采用了 Hadoop 作为底层分布式文件系统支撑的两款国产数据仓库产品进行测试:
- Cloudwave 4.0(2023 年 5 月发版)是一款由北京翰云时代数据技术有限公司推出的国产商业云原生数据仓库产品。
- StarRocks 3.0(2023 年 4 月发版)是一款使用 Elastic License 2.0 协议的国产开源数据仓库产品,
另外,这两款产品的安装部署和操作手册的文档都非常详尽,请大家自行查阅,下文中主要记录了测试操作步骤,并不赘述基本安装部署的步骤。
- Cloudwave:https://github.com/CloudwaveDatabase/cloudwave
- StarRocks:https://github.com/StarRocks/starrocks
测试场景
在本文中首先关注应用场景更加广泛的结构化数据的 SQL 读写场景。
测试数据集
测试数据集则采用了常见的 SSB1000 国际标准测试数据集,该数据集的主要内容如下表所示:
| 表名 | 表行数(单位:行) | 描述 |
|---|---|---|
| lineorder | 60 亿 | SSB 商品订单表 |
| customer | 3000 万 | SSB 客户表 |
| part | 200 万 | SSB 零部件表 |
| supplier | 200 万 | SSB 供应商表 |
| dates | 2556 | 日期表 |
测试用例
- TestCase 1. 执行 13 条标准 SQL 测试语句。
use ssb1000;
# 1
select sum(lo_revenue) as revenue from lineorder,dates where lo_orderdate = d_datekey and d_year = 1993 and lo_discount between 1 and 3 and lo_quantity < 25;
# 2
select sum(lo_revenue) as revenue from lineorder,dates where lo_orderdate = d_datekey and d_yearmonthnum = 199401 and lo_discount between 4 and 6 and lo_quantity between 26 and 35;
# 3
select sum(lo_revenue) as revenue from lineorder,dates where lo_orderdate = d_datekey and d_weeknuminyear = 6 and d_year = 1994 and lo_discount between 5 and 7 and lo_quantity between 26 and 35;
# 4
select sum(lo_revenue) as lo_revenue, d_year, p_brand from lineorder ,dates,part,supplier where lo_orderdate = d_datekey and lo_partkey = p_partkey and lo_suppkey = s_suppkey and p_category = 'MFGR#12' and s_region = 'AMERICA' group by d_year, p_brand order by d_year, p_brand;
# 5
select sum(lo_revenue) as lo_revenue, d_year, p_brand from lineorder,dates,part,supplier where lo_orderdate = d_datekey and lo_partkey = p_partkey and lo_suppkey = s_suppkey and p_brand between 'MFGR#2221' and 'MFGR#2228' and s_region = 'ASIA' group by d_year, p_brand order by d_year, p_brand;
# 6
select sum(lo_revenue) as lo_revenue, d_year, p_brand from lineorder,dates,part,supplier where lo_orderdate = d_datekey and lo_partkey = p_partkey and lo_suppkey = s_suppkey and p_brand = 'MFGR#2239' and s_region = 'EUROPE' group by d_year, p_brand order by d_year, p_brand;
# 7
select c_nation, s_nation, d_year, sum(lo_revenue) as lo_revenue from lineorder,dates,customer,supplier where lo_orderdate = d_datekey and lo_custkey = c_custkey and lo_suppkey = s_suppkey and c_region = 'ASIA' and s_region = 'ASIA'and d_year >= 1992 and d_year <= 1997 group by c_nation, s_nation, d_year order by d_year asc, lo_revenue desc;
# 8
select c_city, s_city, d_year, sum(lo_revenue) as lo_revenue from lineorder,dates,customer,supplier where lo_orderdate = d_datekey and lo_custkey = c_custkey and lo_suppkey = s_suppkey and c_nation = 'UNITED STATES' and s_nation = 'UNITED STATES' and d_year >= 1992 and d_year <= 1997 group by c_city, s_city, d_year order by d_year asc, lo_revenue desc;
# 9
select c_city, s_city, d_year, sum(lo_revenue) as lo_revenue from lineorder,dates,customer,supplier where lo_orderdate = d_datekey and lo_custkey = c_custkey and lo_suppkey = s_suppkey and (c_city='UNITED KI1' or c_city='UNITED KI5') and (s_city='UNITED KI1' or s_city='UNITED KI5') and d_year >= 1992 and d_year <= 1997 group by c_city, s_city, d_year order by d_year asc, lo_revenue desc;
# 10
select c_city, s_city, d_year, sum(lo_revenue) as lo_revenue from lineorder,dates,customer,supplier where lo_orderdate = d_datekey and lo_custkey = c_custkey and lo_suppkey = s_suppkey and (c_city='UNITED KI1' or c_city='UNITED KI5') and (s_city='UNITED KI1' or s_city='UNITED KI5') and d_yearmonth = 'Dec1997' group by c_city, s_city, d_year order by d_year asc, lo_revenue desc;
# 11
select d_year, c_nation, sum(lo_revenue) - sum(lo_supplycost) as profit from lineorder,dates,customer,supplier,part where lo_orderdate = d_datekey and lo_custkey = c_custkey and lo_suppkey = s_suppkey and lo_partkey = p_partkey and c_region = 'AMERICA' and s_region = 'AMERICA' and (p_mfgr = 'MFGR#1' or p_mfgr = 'MFGR#2') group by d_year, c_nation order by d_year, c_nation;
# 12
select d_year, s_nation, p_category, sum(lo_revenue) - sum(lo_supplycost) as profit from lineorder,dates,customer,supplier,part where lo_orderdate = d_datekey and lo_custkey = c_custkey and lo_suppkey = s_suppkey and lo_partkey = p_partkey and c_region = 'AMERICA'and s_region = 'AMERICA' and (d_year = 1997 or d_year = 1998) and (p_mfgr = 'MFGR#1' or p_mfgr = 'MFGR#2') group by d_year, s_nation, p_category order by d_year, s_nation, p_category;
# 13
select d_year, s_city, p_brand, sum(lo_revenue) - sum(lo_supplycost) as profit from lineorder,dates,customer,supplier,part where lo_orderdate = d_datekey and lo_custkey = c_custkey and lo_suppkey = s_suppkey and lo_partkey = p_partkey and c_region = 'AMERICA'and s_nation = 'UNITED STATES' and (d_year = 1997 or d_year = 1998) and p_category = 'MFGR#14' group by d_year, s_city, p_brand order by d_year, s_city, p_brand;
- TestCase 2. 执行多表联合 join 拓展 SQL1 测试语句。
select count(*) from lineorder,customer where lo_custkey = c_custkey;
- TestCase 3. 执行多表联合 join 拓展 SQL2 测试语句。
select count(*) from lineorder,customer,supplier where lo_custkey = c_custkey and lo_suppkey = s_suppkey;
性能指标
这里设定 2 个最常见的性能指标:
- 最大 CPU 资源占用数据;
- 最大 TestCase 执行耗时数据。
并且为了对测试结果进行 “去噪“,每个 TestCases 都会执行 19 轮 SQL 测试脚本。值得注意的是,还需要额外的去除掉第 1 轮的测试数据,因为第 1 次查询性能数据会收到系统 I/O 的变量因素影响。所以应该对余下的 18 轮测试数据做平均计算,以此获得更加准确的 SQL 执行平均耗时数据。
测试脚本工具
- Cloudwave 测试脚本:
#!/bin/bash
# Program:
# test ssb
# History:
# 2023/03/17 junfenghe.cloud@qq.com version:0.0.1
rm -rf ./n*txt
for ((i=1; i<20; i++))
do
cat sql_ssb.sql |./cplus.sh > n${i}.txt
done
- StarRocks 测试脚本:
#!/bin/bash
# Program:
# test ssb
# History:
# 2023/03/17 junfenghe.cloud@qq.com version:0.0.1
rm -rf ./n*txt
for ((i=1; i<20; i++))
do
cat sql_ssb.sql | mysql -uroot -P 9030 -h 127.0.0.1 -v -vv -vvv >n${i}.txt
done
- 结果分析脚本:
#!/bin/bash
# Program:
# analysis cloudwave/starrocks logs of base compute
# History:
# 2023/02/20 junfenghe.cloud@qq.com version:0.0.1
path=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/sbin:/usr/local/bin:~/bin
export path
suff="(s)#####"
if [ -z "${1}" ]
then
echo "Please input database'name"
exit -1
fi
if [ -z "$2" ]
then
echo "Please input times of scanner"
exit -f
fi
if [ -n "${3}" ]
then
suff=${3}
fi
for current in ${2}
do
result_time=""
if [ "${1}" == "starrocks" ]
then
for time in $( cat ${current} | grep sec | awk -F '(' '{print $2}' | awk -F ' ' '{print $1}' )
do
result_time="${result_time}${time}${suff}"
done
elif [ "${1}" == "cloudwave" ]
then
for time in $( cat ${current} | grep Elapsed | awk '{print $2}'| sed 's/:/*60+/g'| sed 's/+00\*60//g ; s/+0\*60//g ; s/^0\*60+//g' )
do
result_time="${result_time}${time}${suff}"
done
fi
echo ${result_time%${suff}*}
done
exit 0
- sql_ssb.sql 文件:用于保存不同 TestCases 中的 SQL 测试语句,然后被测试脚本读取。
基准环境准备
硬件环境
为了方便测试环境的准备和节省成本,同时尽量靠近分布式的常规部署方式。所以测试的硬件环境采用了阿里云上的 4 台 64 Core 和 256G Memory 的云主机来组成分布式集群,同时为了进一步避免磁盘 I/O 成为了性能瓶颈,所以也都挂载了 ESSD pl1 高性能云盘。

软件环境
-
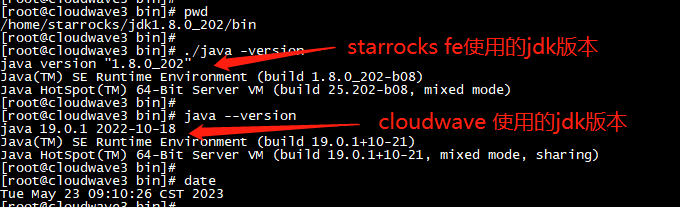
JDK 19:Cloudwave 4.0 依赖
-
JDK 8:StarRocks 3.0 依赖
-
MySQL 8:作为 StarRocks FE(前端)

-
Hadoop 3.2.2:作为 Cloudwave 和 StarRocks 的分布式存储,并设定文件副本数为 2。

测试操作步骤
Cloudwave 执行步骤
导入数据集
- 查看为 Hadoop 准备的存储空间。
$ ./sync_scripts.sh 'df -h' | grep home

- 格式化 Hadoop 存储空间。
$ hdfs namenode -format
- 启动 HDFS,并查看服务状态。
$ start-dfs.sh
$ ./sync_scripts.sh 'jps'
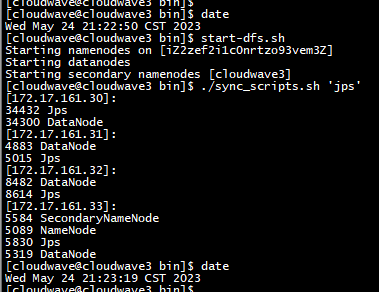
- 创建 SSB1000 数据集的上传目录。
$ hdfs dfs -mkdir /cloudwave
$ hdfs dfs -mkdir /cloudwave/uploads
$ hdfs dfs -put ssb1000 /cloudwave/uploads/

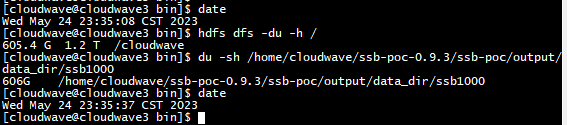
- 检查数据上传结果,可以看到 SSB1000 数据集,占用了 606GB 的存储空间。
$ hdfs dfs -du -h /
$ du -sh /home/cloudwave/ssb-poc-0.9.3/ssb-poc/output/data_dir/ssb1000
- 启动 Cloudwave。
$ ./start-all-server.sh
- 导入 SSB1000 数据集。
$ ./cplus_go.bin -s 'loaddata ssb1000'
-
因为数据集非常大所以导入的时间较长,大概 58 分钟。
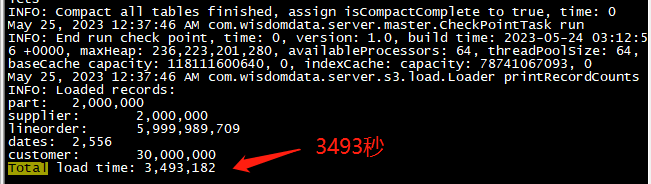
-
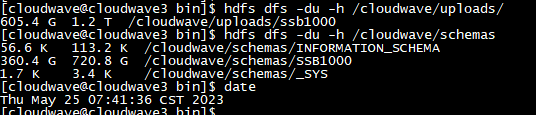
通过执行 HDFS 的命令,可以看到 Cloudwave 对数据集同步进行了数据压缩,这也是 Cloudwave 的特性功能之一。SSB1000 的原始大小是 606G,导入后被压缩到到了 360G。下图中的 720G 表示 HDFS 中 2 个数据副本的总大小,压缩比达到了可观的 59%。
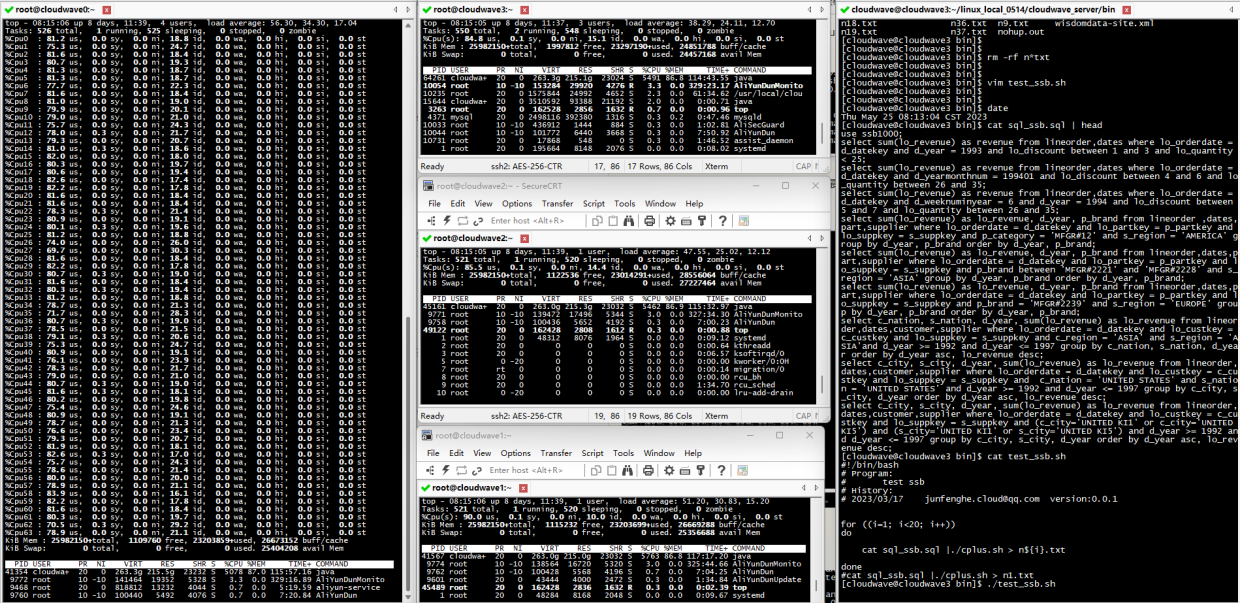
TestCase 1. 执行 13 条标准 SQL 测试语句
将 TestCase 1 的 13 条标准 SQL 测试语句写入到 sql_ssb.sql 文件中,然后执行 Cloudwave 测试脚本,同时监控记录 CPU 资源的使用率数据。
$ ./test_ssb.sh
结果如下图所示。在 TestCase 1 中,4 节点的 Cloudwave 集群的最大 CPU 使用率平均为 5763% / 6400% = 90%(注:64 Core CPU 总量为 6400%)。
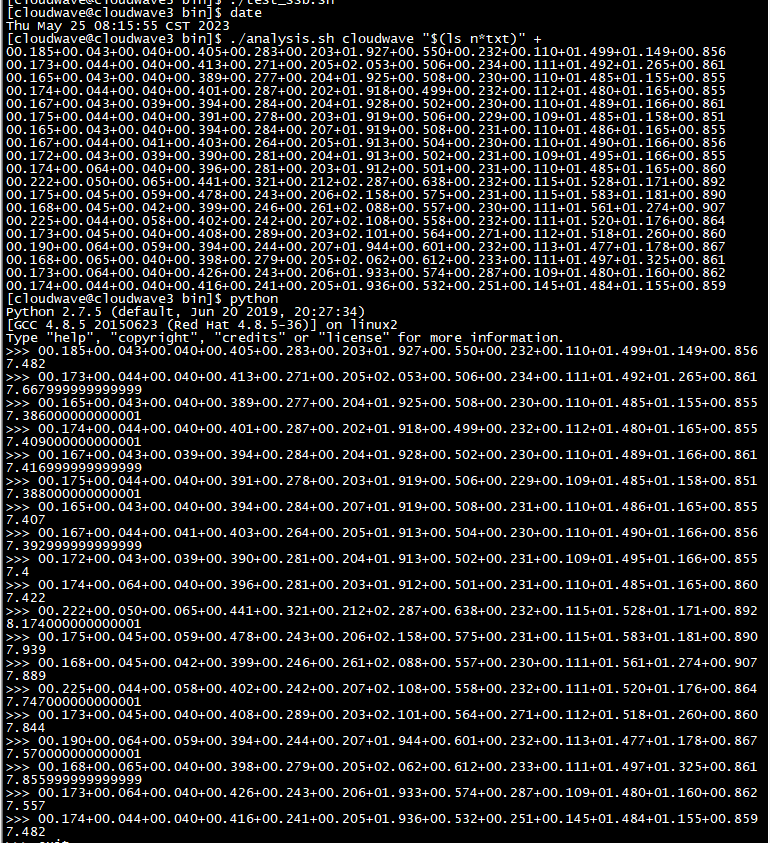
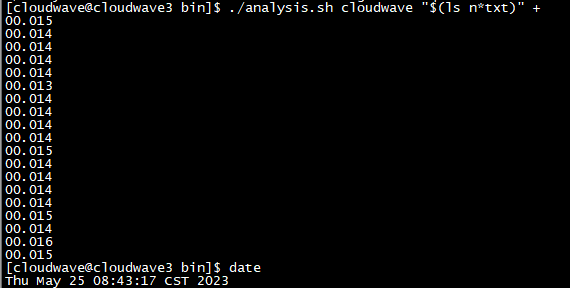
如下图所示,执行分析脚本程序来计算 TestCase 1 的平均耗时为 7.6s。
$ ./analysis.sh cloudwave "$(ls n*txt)" +
TestCase 2. 执行多表联合 join 拓展 SQL1 测试语句
将 TestCase 2 的 多表联合 join 拓展 SQL1 测试语句写入到 sql_ssb.sql 文件中,然后执行 Cloudwave 测试脚本,同时监控记录 CPU 资源的使用率数据。
$ ./test_ex.sh
结果如下图所示。在 TestCase 2 中,4 节点的 Cloudwave 集群的最大 CPU 使用率平均为 0.0935%(6% / 6400%)。
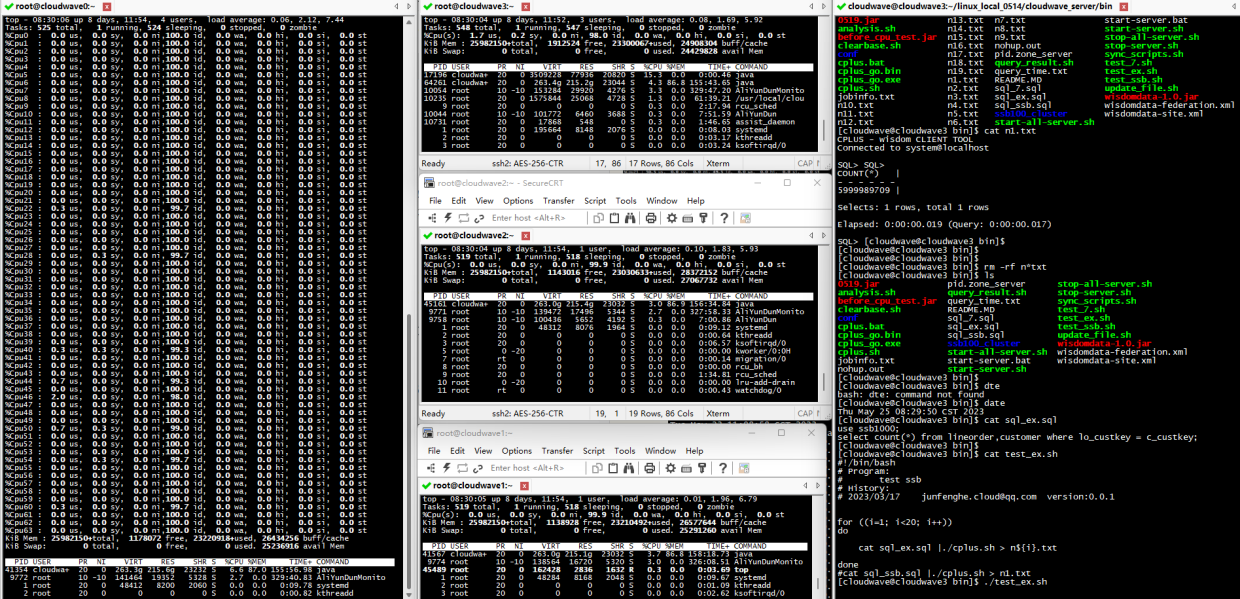
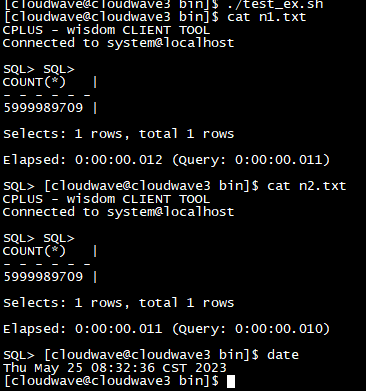
如下图所示,执行分析脚本程序来计算 TestCase 2 的平均耗时为 12ms。
$ ./analysis.sh cloudwave "$(ls n*txt)" +
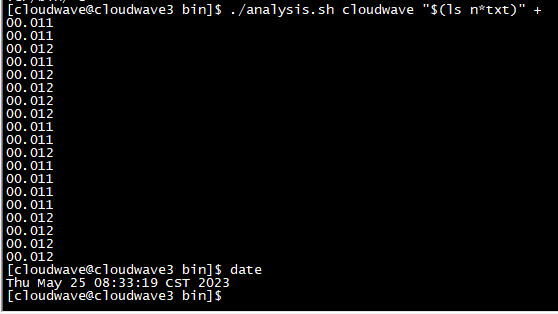
TestCase 3. 执行多表联合 join 拓展 SQL2 测试语句
将 TestCase 2 的 多表联合 join 拓展 SQL2 测试语句写入到 sql_ssb.sql 文件中,然后执行 Cloudwave 测试脚本,同时监控记录 CPU 资源的使用率数据。
$ ./test_ex.sh
结果如下图所示。在 TestCase 2 中,4 节点的 Cloudwave 集群的最大 CPU 使用率平均为 0.118%(7.6% / 6400%)。
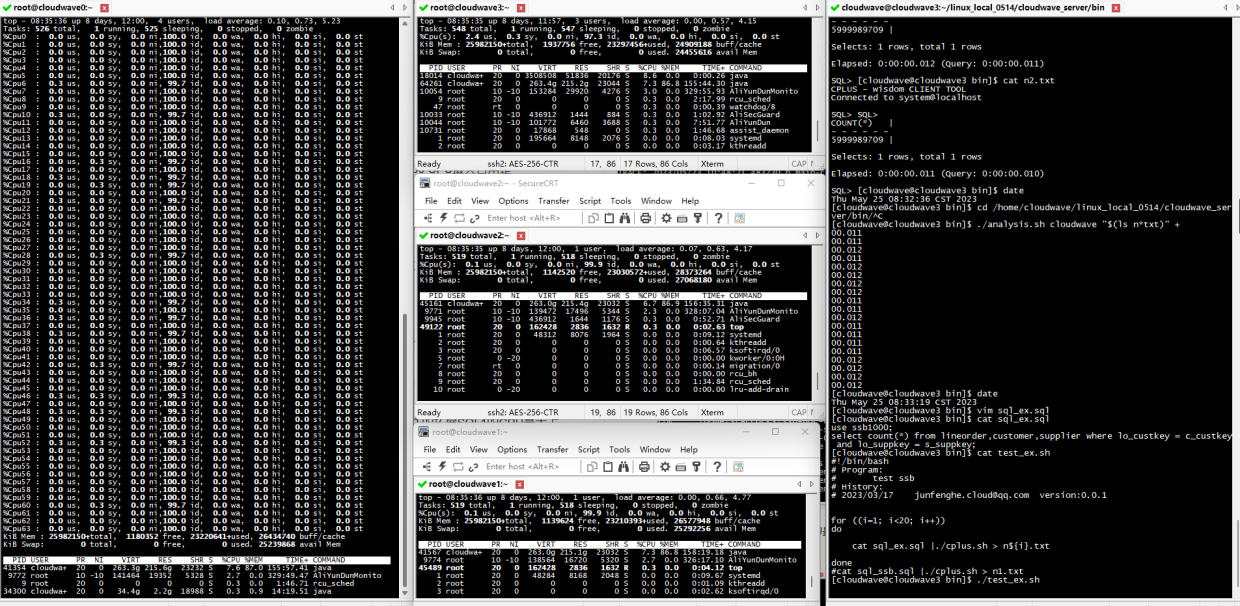
如下图所示,执行分析脚本程序来计算 TestCase 3 的平均耗时为 14ms。
$ ./analysis.sh cloudwave "$(ls n*txt)" +
StarRocks 执行步骤
导入数据集
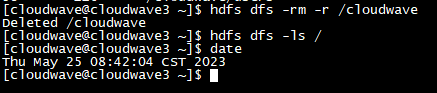
- 清空 HDFS 存储。
$ hdfs dfs -rm -r /cloudwave
$ hdfs dfs -ls /
- 启动 StarRocks FE(前端)守护进程。
$ ./fe/bin/start_fe.sh --daemon

- 添加 StarRocks BE(后端)单元。
$ mysql -uroot -h127.0.0.1 -P9030
$ ALTER SYSTEM ADD BACKEND "172.17.161.33:9050";
$ ALTER SYSTEM ADD BACKEND "172.17.161.32:9050";
$ ALTER SYSTEM ADD BACKEND "172.17.161.31:9050";
$ ALTER SYSTEM ADD BACKEND "172.17.161.30:9050";
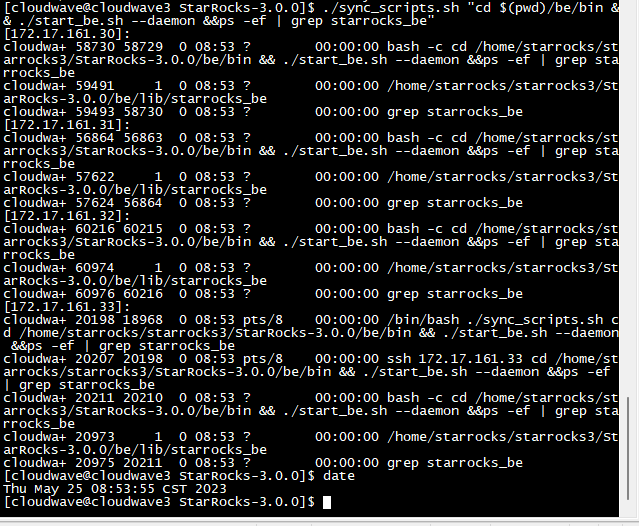
- 启动 StarRocks BE 守护进程。
$ ./sync_scripts.sh "cd $(pwd)/be/bin && ./start_be.sh --daemon &&ps -ef | grep starrocks_be"
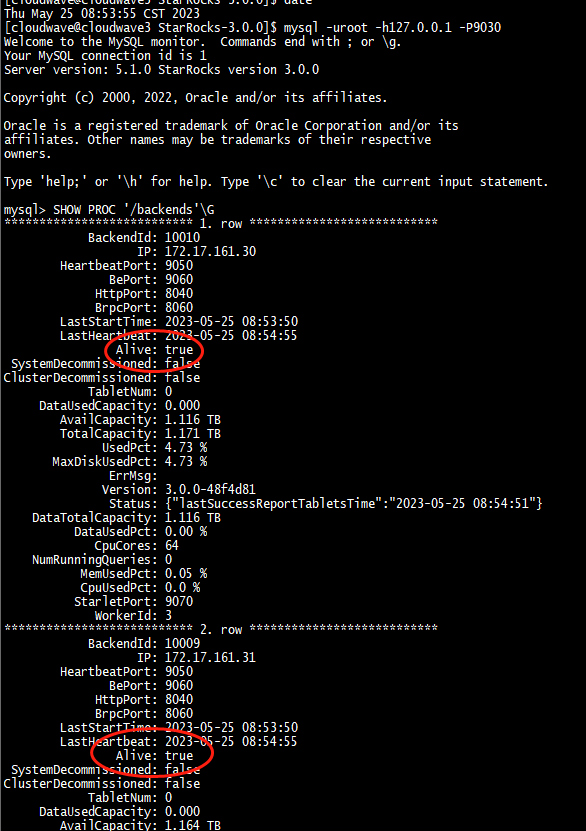
-
验证 StarRocks 集群状态,依次查看 4 个节点都 Alive=true 了。
-
创建表。

-
开始导入数据,SSB1000 的导入时间总计为 112 分钟。
$ date && ./bin/stream_load.sh data_dir/ssb100 && date
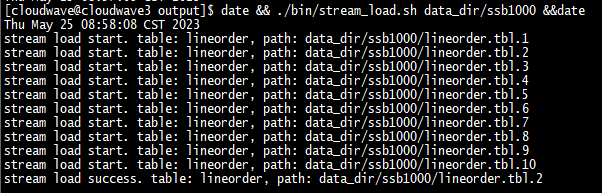
导入过程中可以发现虽然设置了 HDFS 的副本数为 2,但 StarRocks 将副本数自动修改为了 3。
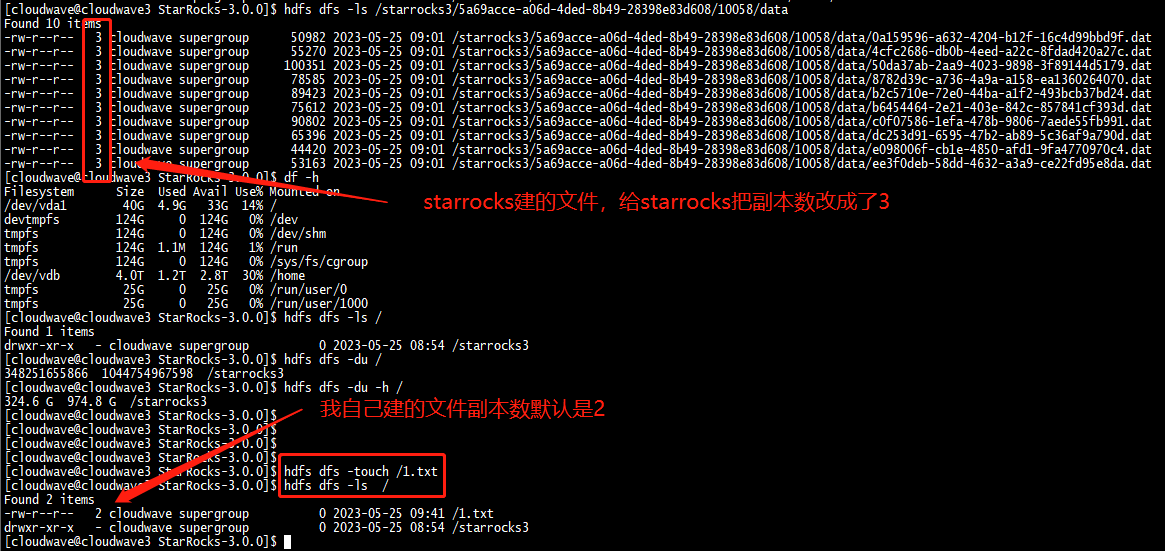
另外在导入数据集时,发现 StarRocks 似乎没有进行数据压缩,占用了 1T 的存储空间,所以导入时间也相应的变得更长。

TestCase 1. 执行 13 条标准 SQL 测试语句
将 TestCase 1 的 13 条标准 SQL 测试语句写入到 sql_ssb.sql 文件中,然后执行 StarRocks 测试脚本,同时监控记录 CPU 资源的使用率数据。
$ ./test_ssb.sh
结果如下图所示。在 TestCase 1 中,4 节点的 StarRocks 集群的最大 CPU 使用率平均为 67%(4266% / 6400%)。
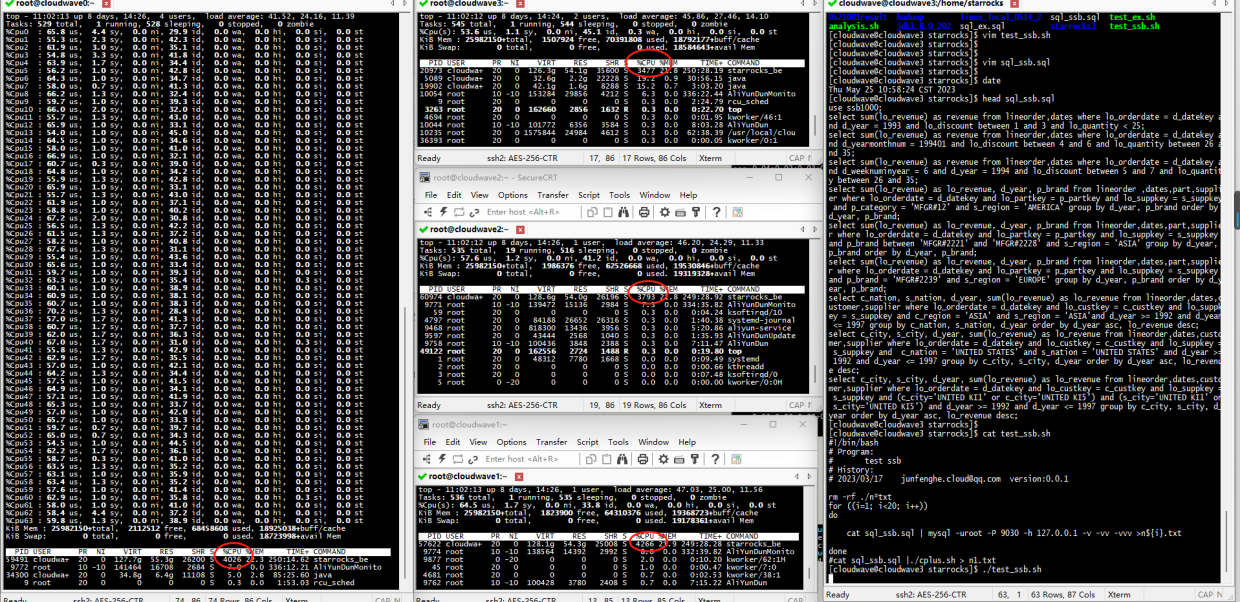
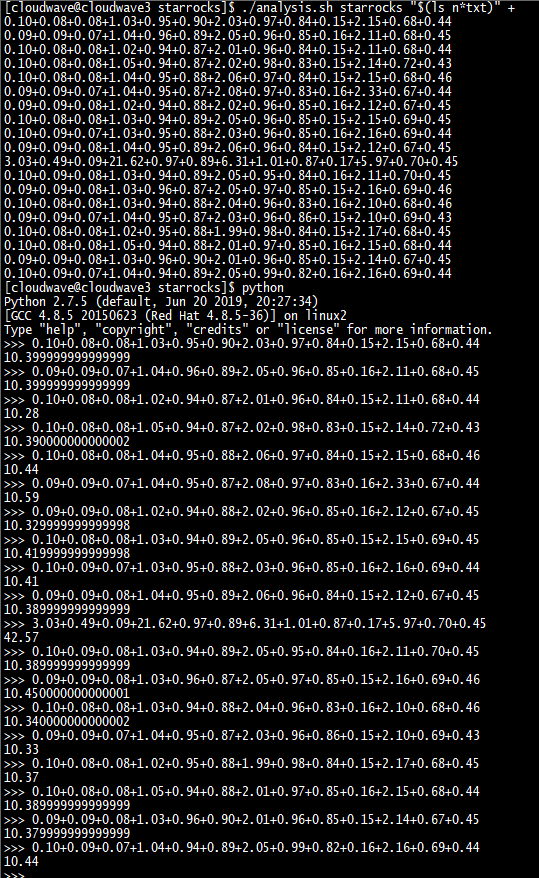
如下图所示,执行分析脚本程序来计算 TestCase 1 的平均耗时为 10.39s。
$ ./analysis.sh cloudwave "$(ls n*txt)" +
TestCase 2. 执行多表联合 join 拓展 SQL1 测试语句
将 TestCase 2 的 多表联合 join 拓展 SQL1 测试语句写入到 sql_ssb.sql 文件中,然后执行 StarRocks 测试脚本,同时监控记录 CPU 资源的使用率数据。
$ ./test_ex.sh
结果如下图所示。在 TestCase 2 中,4 节点的 StarRocks 集群的最大 CPU 使用率平均为 78.7%(5037% / 6400%)。
如下图所示,执行分析脚本程序来计算 TestCase 2 的平均耗时为 2.79s。
$ ./analysis.sh cloudwave "$(ls n*txt)" +
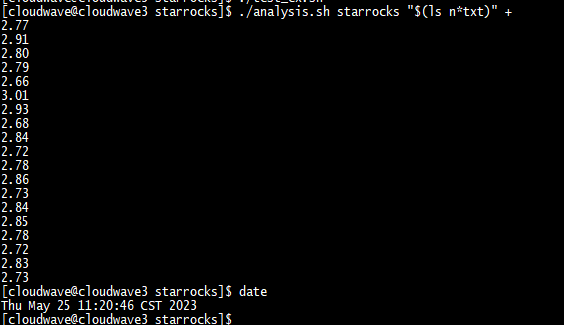
TestCase 3. 执行多表联合 join 拓展 SQL2 测试语句
将 TestCase 2 的 多表联合 join 拓展 SQL2 测试语句写入到 sql_ssb.sql 文件中,然后执行 StarRocks 测试脚本,同时监控记录 CPU 资源的使用率数据。
$ ./test_ex.sh
结果如下图所示。在 TestCase 2 中,4 节点的 Cloudwave 集群的最大 CPU 使用率平均为 90.5%(5797% / 6400%)。
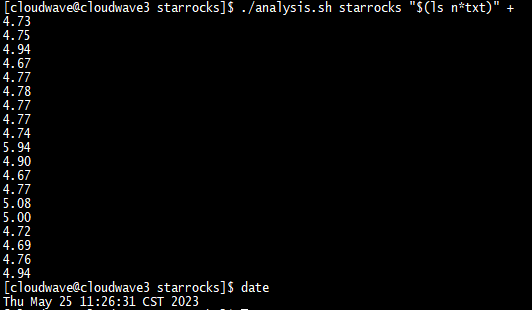
如下图所示,执行分析脚本程序来计算 TestCase 3 的平均耗时为 4.8s。
$ ./analysis.sh cloudwave "$(ls n*txt)" +
测试结果分析
- 13 条标准 SQL 测试语句结果统计:
| 数据仓库 | 数据集 | 响应时间(s) | CPU 最大占用率 | 存储压缩比 | 数据导入时间 |
|---|---|---|---|---|---|
| Cloudwave 4.0 | ssb1000 | 7.602 | 90%(5763%/6400%) | 59%(360G/606G) | 58分钟 |
| StarRocks 3.0 | ssb1000 | 10.397 | 66.6%(4266%/6400%) | 169%(1024G/606G) | 112分钟 |
- 2 条多表联合 join 扩展 SQL 测试语句结果统计:
| 数据仓库 | 数据集 | 拓展SQL1响应时间(s) | 拓展SQL1 CPU 最大占用率 | 拓展SQL2响应时间(s) | 拓展SQL2 CPU 最大占用率 |
|---|---|---|---|---|---|
| Cloudwave 4.0 | ssb1000 | 0.012 | 0.0935%(6%/6400) | 0.014 | 0.118%(7.6%/6400) |
| StarRocks 3.0 | ssb1000 | 2.79 | 78.7%(5037%/6400) | 4.8 | 90.5%(5797%/6400) |
从上述测试结果中可以看出 Cloudwave 云原生数据仓库的性能表现是非常突出的,尤其在在多表联合 join 扩展 SQL 场景下,Cloudwave 4.0版本的 CPU 资源占有率非常低的同时执行速度也非常快。
当然,数据仓库性能优化和测试是一门复杂的系统工程,由于文档篇幅的限制上文中也只是选取了比较有限的测试场景和性能指标,主要是为了学习研究和交流之用,实际上还有很多值得优化和扩展的细节。
从数据仓库到云原生数据仓库
最后在记录下一些学习心得。从前提到数据库(Database)我会认为它们单纯就是一个用于存放结构化数据或非结构化数据的 DBMS(Database Management System)应用软件。但随着数据挖掘的价值体系被越来越多用户所认可,以及越来越多的用户需求将数据应用于提升实际的生产效率上。使得单纯面向数据存储的数据库逐渐被堆叠了越来越多的业务应用功能,进而演变成一个面向数据分析的数据仓库(Data Warehouse)。
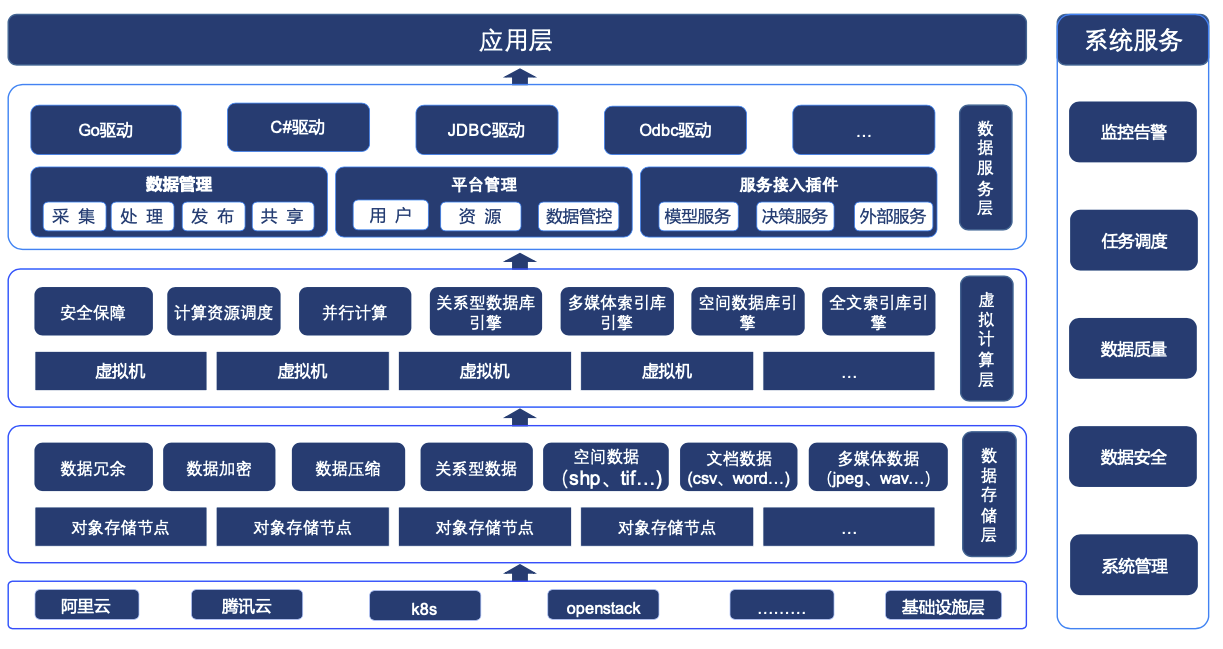
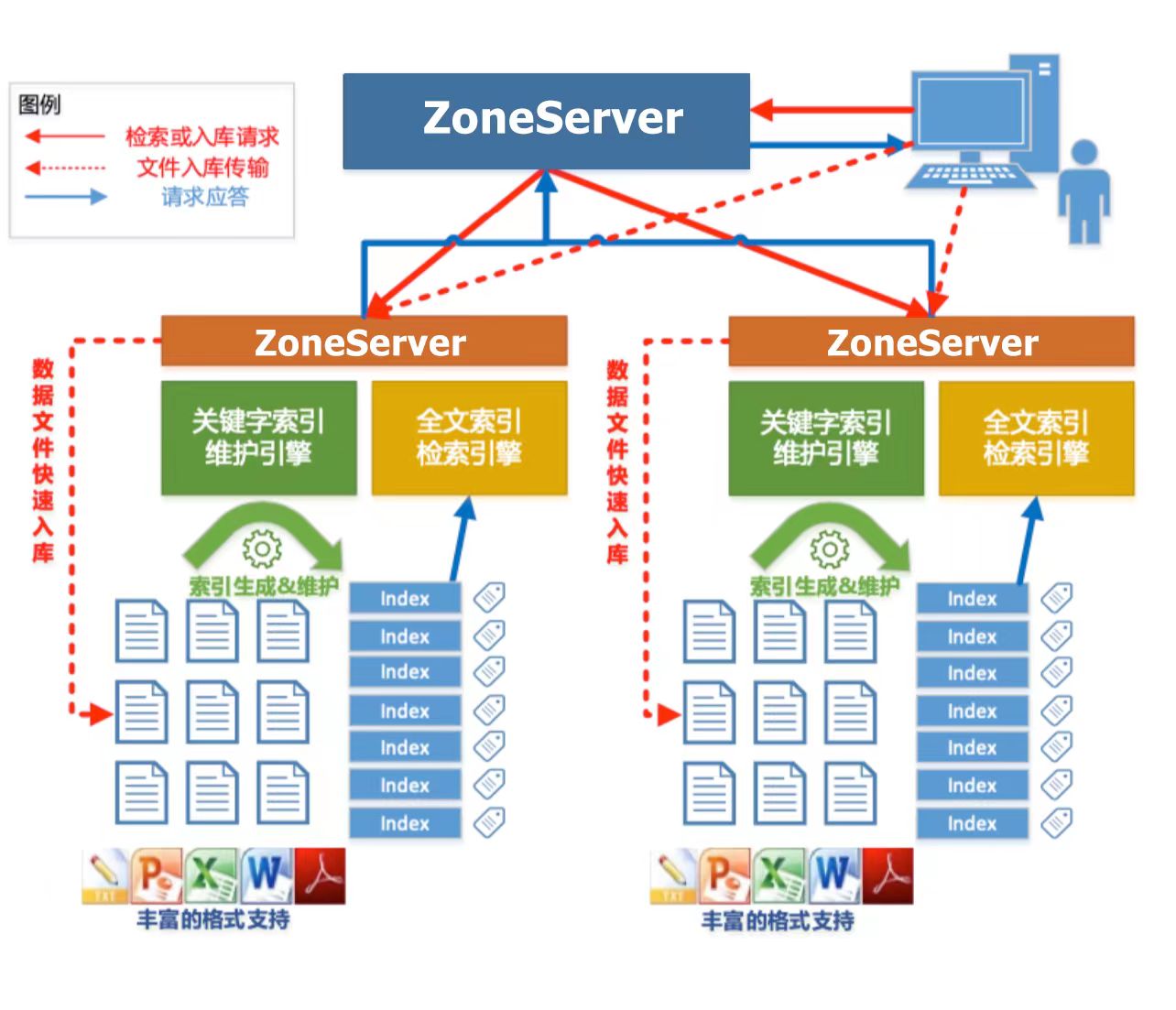
以基于云原生架构的 Cloudwave 4.0 数据仓库的为例,从下图的产品架构可以看出,Cloudwave 除了支持常规的结构化数据和非结构化数据存储功能之外,还具有面向顶层应用程序的数据服务层,以多样化的 SDK 驱动程序向应用程序提供数据存储、数据管理、平台管理、服务接入插件等能力。
尤其是 Cloudwave 所支持的并行全文检索功能令我印象深刻,这个功能在文本信息处理场景中非常必要。下面引用了《翰云数据库技术白皮书》中的一段介绍。更多的技术细节也推荐阅读这本技术白皮书。
Cloudwave 能够对 CLOB 大文本字段以及 Bfile 文件(e.g. 常用的 PDF、Word、 Excel、PPT、Txt 以及 Html 等)实现全文索引功能,实现了基于 HDFS 的 Lucene 索引存储,保证了索引数据的安全性,并对 Lucene 索引数据进行自动分段,由多服务器均衡管理。全文检索时,多服务器对索引段并行检索,这样就提高了查询效率。处理 Bfile 类型的文件时,利用现有的解析类库,从不同格式的文档中侦测和提取出元数据和结构化内容。
此外,Cloudwave 云原生数据仓库还集成了云原生架构技术体系,带来了更多的集群化管理优势,例如:
- 弹性扩展性:支持根据需求进行弹性扩展,根据数据量和工作负载的变化自动调整资源。这使得数据仓库能够处理大规模数据集和高并发查询,并满足不断增长的业务需求。
- 灵活性和敏捷性:可以快速适应业务变化和新的数据分析需求,支持与多种云原生平台上多种分析工具和技术的无缝集成。
- 强大的生态系统支持:便于与其他云服务和工具进行集成,例如:机器学习平台、可视化平台等等。它与云提供商的生态系统紧密结合,能够快速获取最新的技术和功能更新,并获得强大的支持和服务。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏
· Manus爆火,是硬核还是营销?
2019-07-04 Nova 实现的 Fit Instance NUMA to Host NUMA 算法