
用户态网络协议栈还是内核协议栈?
2019-11-14 22:53 云物互联 阅读(1901) 评论(0) 编辑 收藏 举报目录
前文列表
《Linux 内核网络协议栈》
《DPDK 网络加速在 NFV 中的应用》
内核协议栈存在的意义
关于内核协议栈的功能与原理我们在《Linux 内核网络协议栈》一文中已有讨论,这里我们主要思考内核协议栈存在的意义。要回答这个问题,我希望从操作系统聊起。
一个正在运行的程序会做一件非常简单的事情:执行指令。CPU 从内存中获取一条指令,对其进行解码、然后执行它应该做的事情,例如:相加算数、访问内存、检查条件、跳转到函数等等。
实际上,有一类软件负责让这些程序的运行变得简单,运行程序间共享内存,让程序能够与设备交互,这类软件就是操作系统。现在被我们称之为 “操作系统” 的软件其实最早的称谓是 Supervisor,往后还被叫过一段时间的 Master Control Program(主控程序),但最终 Operating System 胜出了。它们负责确保系统即易于使用又能正确高效的运行,为此,操作系统实现了以下两点需求:
- 操作系统带来了硬件的独立性和容易使用的 API(系统调用),让上层应用程序的运行更加简单。
- 操作系统应用(CPU、内存)虚拟化技术添加了一个时间分享的层,让多个上层应用程序的运行更加简单。
写到这里不仅感叹 Unix 操作系统与 C 语言的出现,以及贝尔实验室排除万难使用 C 语言重写了 Unix 的壮举。从此,上层应用程序与计算机硬件的世界被解耦,黑客文化与思潮得以诞生,正是这群软件世界的叛逆者捍卫了代码的自由,开源运动才得以启动。
回到主题,从操作系统的启发,我们大概能够理解内核协议栈的意义,它是为了让种类多如繁星的网络协议能够在计算机上运行得更加简单。但世上本不存在所谓的 “万金油”,计算机的世界从来都是时间与空间的博弈。看似万能的内核协议栈,其实充满妥协 —— Linux 内核协议栈存在严重的 Scalable(可伸展性)问题。
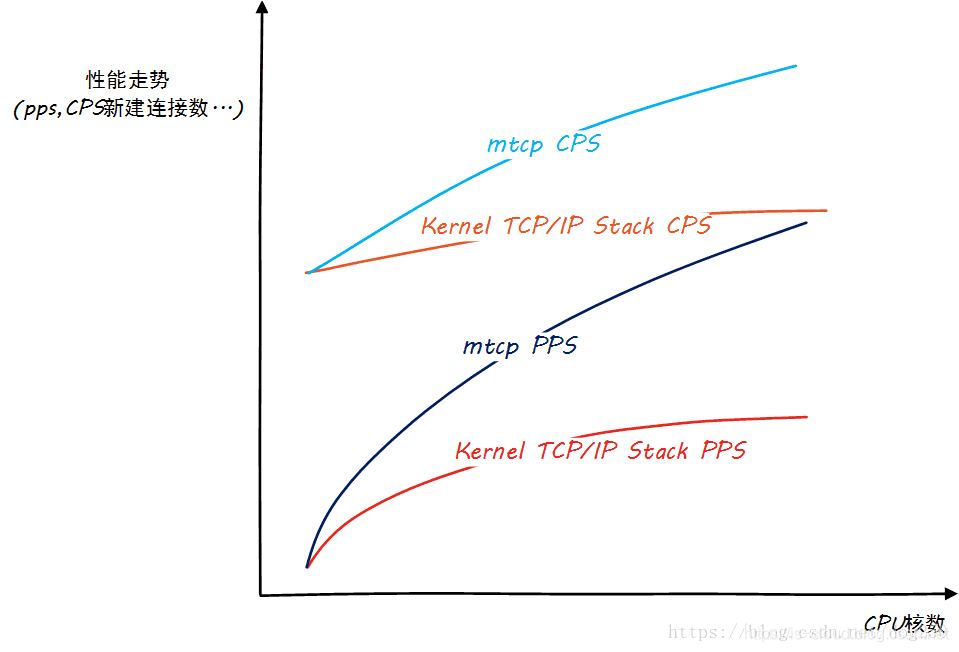
NOTE:
- BPS(Bit Per Second):比特每秒,表示每秒钟传输多少位信息,即带宽。例如:常说的 1M 带宽的意思是 1Mbps(兆比特每秒)。
- CPS(Connect Per Second):TCP 每秒新建连接数。
- PPS(Packet Per Second):包转发率,即能够同时转发的数据包的数量,表示转发数据包能力的大小。
从上图可以看见,内核协议栈的 CPS、PPS 以及 CPU 数量的关系远没有达到线性提升,甚至远没有用户态协议栈来的优秀。据经验,在C1(8 Core)上运行应用程序每 1W 包处理需要消耗 1% 软中断 CPU,这意味着单机的上限是 100W PPS。假设,要跑满 10GE 网卡,每个包 64 字节,就需要 2000W PPS(注:实际上以太网万兆网卡速度上限是 1488W PPS,因为最小数据帧的大小为 84B),100G 就是 2亿 PPS,即每个包的处理耗时不能超过 50 纳秒。而一次 Cache Miss,不管 Miss 的是 TLB、数据 Cache 还是指令 Cache,回内存读取都需要大约为 65 纳秒,而且在 NUMA 架构体系下的跨 Node 通讯大约还需要额外多加 40 纳秒。
所以,内核协议栈一秒钟能处理的数据包是有限的。当达到上限的时候,所有的 CPU 都开始忙于接收数据包。在这种情形下,数据包要么被丢弃,要么会导致应用 CPU 匮乏( starve of CPU)。诚然,这并非内核协议栈所愿,但现实如此,受限于操作系统和硬件设备的实现细节,内核协议栈选择了向空间(满足大部分常规使用场景)“妥协”。
对此,笔者曾在《DPDK 网络加速在 NFV 中的应用》一文中详细谈到 Linux 内核协议栈存在的问题,这里不再赘述,简单总结为几点:
- 上下文切换开销大
- 内存拷贝昂贵
- Cache Miss 高
- 中断处理频繁
- 系统调用开销
再回过头来看,我们可以明显的感受到网速一直在提升,网络技术的发展从 1GE/10GE/25GE/40GE/100GE 演变,这也为计算机网络 I/O 能力提出了挑战。如何跟上网速的发展?这是一个宽泛的命题,我们只看其中的一个方法 —— 用户态网络协议栈。
用户态网络协议栈简述
用户态网络协议栈,即在 Linux 用户态上实现的网络协议栈处理程序,底层支撑技术被称为内核旁路技术,又可细分为完全内核旁路及部分内核旁路。其思路大抵是绕过内核,直接将网络硬件设备交给运行在用户态的应用程序使用,常见的内核旁路技术实现有 PF_RING、Snabbswitch、Netmap 以及 DPDK。
有了内核旁路技术,开发者得以编写自己的网络协议栈,让协议栈功能变得更加灵活,专注于某些高级特性,并且针对性能进行优化。可见,用户态网络协议栈最大的特点就是 “自定义”,针对特定的业务需求来实现数据流量转发控制以及性能提升。当然了,这也需要付出代价 —— 每一张网卡只能用于一个进程,此时的网卡不再具备 “常规意义上” 的网卡功能。例如:Linux 的 netstat、tcpdump 等工具可能会停止工作。
对于部分内核旁路技术,内核仍然保留对网卡的拥有权,并且能让用户态应用程序只在一个单独的接收队列(Rx Queue)上执行旁路,典型的部分内核旁路技术实现有 Linux 社区开源的 Netmap,官方数据是 10G 网卡 1400W PPS,已经比较接近 1488W 的极限了,但是 Netmap 没又得到广泛使用。其原因有几个:
- Netmap 需要网卡驱动的支持,即受制于网卡厂商。
- Netmap 仍然依赖中断通知机制,没完全解决瓶颈。
- Netmap 更像是几个系统调用,实现用户态直接收发包,功能太过原始,没形成依赖的网络开发框架,社区不完善。
但鉴于目前还没有稳定的开源部分内核旁路技术方案,我们希望 Netmap 能抢占这个商机。毕竟现在常见的 DPDK 与 Intel 的关系实在过于紧密。
用户态网络协议栈的应用场景:
- 软件定义的交换机或者路由器,例如 OvS、vRouter。该场景中希望将网卡交由应用程序来管理,以及处理原始的数据包并且完全绕开内核。
- 专用的负载均衡器。类似的,如果该机器只用来做数据包的随机处理(Packet Shuffling),那绕过内核就是合理的。
- 对于选定的高吞吐/低延迟的应用进行部分旁路。例如:DDoS 缓解系统中。
- 在高频交易(High Frequency Trading)场景中使用,因为用户态协议可以很好的降低延迟。
用户态网络协议栈面临的挑战:
- Linux 内核协议栈有很多重要的特性和优秀的调试能力。需要花费长期的时间才可能挑战这个丰富的生态系统。
用户态协议栈如何解决这个问题?
解决问题,首先要提出问题。这里的问题是:如何提高收包吞吐?
以 DPDK 为例,笔者《DPDK 网络加速在 NFV 中的应用》一文中也有过阐述,这里不再赘述。
参考文档
https://www.cnblogs.com/huangfuyuan/p/9238437.html
https://cloud.tencent.com/developer/article/1198333
https://blog.csdn.net/dog250/article/details/80532754

