
计算机网络基础 — 虚拟网络
2020-02-27 13:31 云物互联 阅读(1124) 评论(0) 收藏 举报目录
文章目录
前文列表
《计算机网络基础 — 以太网》
《计算机网络基础 — 物理网络》
《计算机网络基础 — TCP/IP 网络模型》
《计算机网络基础 — Linux 内核网络协议栈》
Linux 命名空间(Linux Namespace)
Linux Namespace(命名空间)是一种操作系统层级的资源隔离技术,能够将 Linux 的全局资源,划分为 namespace 范围内的资源,而且不同 namespace 间的资源彼此透明,不同 namespace 里的进程无法感知到其它 namespace 里面的进程和资源。
Linux namespace 实现了 6 项资源隔离,基本上涵盖了一个小型操作系统的运行要素,包括主机名、用户权限、文件系统、网络、进程号、进程间通信。Linux Namespace 是操作系统虚拟化技术(e.g. 容器)的底层实现支撑。
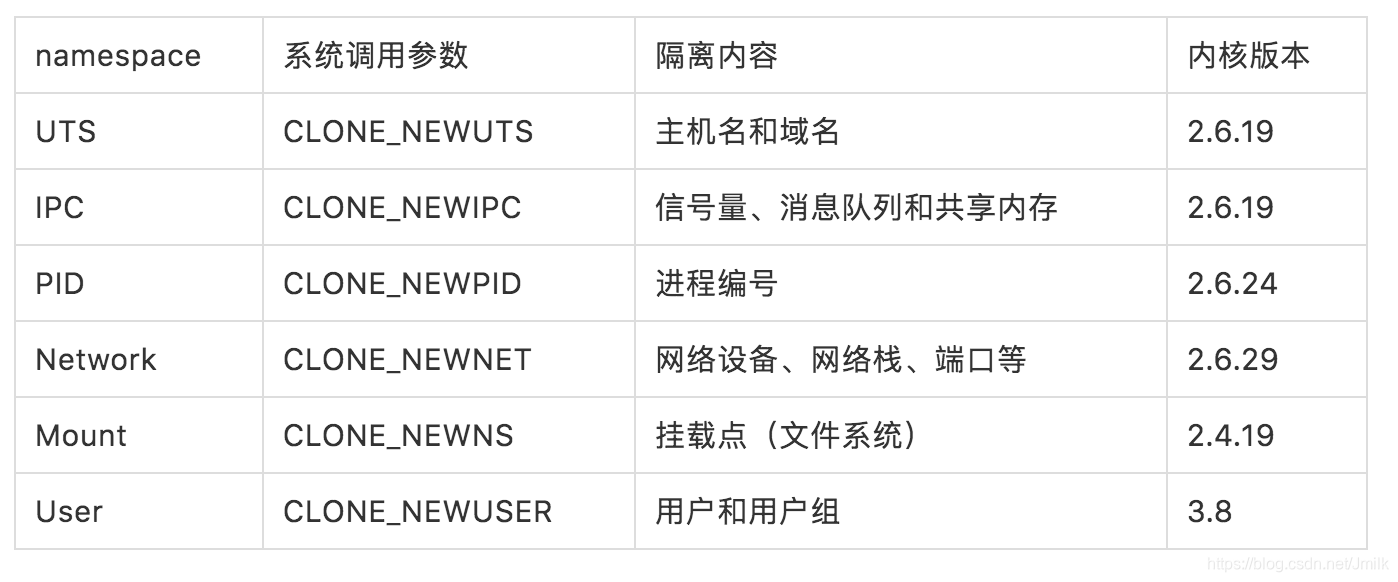
这 6 项资源隔离分别对应 6 种系统调用,将这些系统调用传输传入 clone 函数就可以建立一个容器了。一个容器进程还可以再 clone 出一个容器进程,完成容器的嵌套。
int clone(int (*child_func)(void *), void *child_stack, int flags, void *arg);
通过文件 文件 /proc/[pid]/ns 可以查看指定进程运行在哪些 namespace 中:
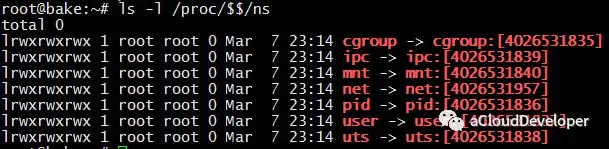
可以看到,每项 namespace 都具有一个唯一标识,如果两个进程指向的同一个 namespace,则表示它们同在该 namespace 下。
-
UTS namespace 提供了主机名和域名的隔离,这样每个容器就拥有独立的主机名和域名了,在网络上就可以被视为一个独立的节点,在容器中对 hostname 的命名不会对宿主机造成任何影响。
-
PID namespace 完成的是进程号的隔离。
-
IPC namespace 实现了进程间通信的隔离,包括常见的几种进程间通信机制,例如:信号量,消息队列和共享内存。我们知道,要完成 IPC,需要申请一个全局唯一的标识符,即 IPC 标识符,所以 IPC 资源隔离主要完成的就是隔离 IPC 标识符。
-
Mount namespace 通过隔离文件系统的挂载点来达到对文件系统的隔离。
-
Network namespace 实现了操作系统层面的网络资源隔离,包括网络设备接口、IPv4 和 IPv6 协议栈,IP 路由表,防火墙,/proc/net 目录,/sys/class/net 目录,Sockets 套接字等资源。同一个网络设备只能位于一个 Network namespace 中,不同 namespace 中的网络设备可以利用 veth pair 进行桥接。
-
User namespace 主要隔离了安全相关的标识符和属性,包括 User ID、User Group ID、root 目录、key 以及特殊权限。
虚拟网卡与虚拟网线
虚拟网线(Veth-pair)
Veth-pair 不是一个设备,而是一对设备,作为虚拟网线用于连接两个虚拟网络设备。veth pair 是根据数据链路层的 MAC 地址对网络数据包进行转发的过程来实现的,本质是反转通讯数据的方向,需要发送的数据会被转换成需要收到的数据重新送入内核网络层进行处理,从而间接的完成数据的注入。
veth pair 在虚拟网络设备中是作为 “网线” 的存在,将 tap 之间,tap 与 Bridge 之间连接起来。veth pair 通常还与 Network namespace 一起配合,实现不同 Network namespace 中的网络设备传输。
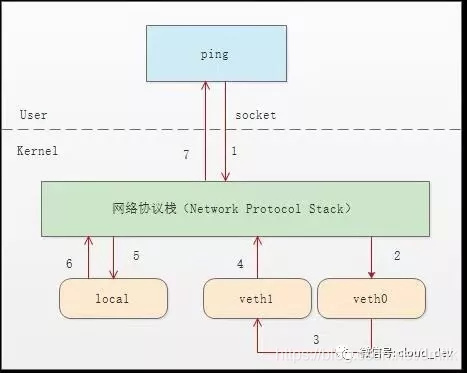
如上图:
- 首先 ping 程序构造 ICMP echo request,通过 Socket API 发给内核网络协议栈。
- 由于 ping 指定了走 veth0 口,如果是第一次,则需要发 ARP 请求,否则协议栈直接将数据包交给 veth0。
- 由于 veth0 连着 veth1,所以 ICMP request 直接发给 veth1。
- veth1 收到请求后,交给另一端的协议栈。
- 协议栈看本地有 10.1.1.3 这个 IP,于是构造 ICMP reply 包,查看路由表,发现回给 10.1.1.0 网段的数据包应该走 lo 口,于是将 reply 包交给 lo 口(会优先查看路由表的 0 号表,ip route show table 0 查看)。
- lo 收到协议栈的 reply 包后,啥都没干,转手又回给协议栈。
- 协议栈收到 reply 包之后,发现有 Socket 在等待包,于是将包给 socket。
- 等待在用户态的 ping 程序发现 Socket 返回,于是就收到 ICMP 的 reply 包。
虚拟二层网卡(Tap)与虚拟三层隧道网卡(Tun)
tap/tun 是 Linux 内核 2.4.x 版本之后加入的虚拟网络设备,不同于物理网卡靠硬件网路板卡的实现方式,tap/tun 虚拟网卡完全由内核软件来实现的,是一种让用户态程序向内核协议栈注入数据的设备。tap 工作在二层(数据链路层)而 tun 工作在三层(网络层)。功能和硬件实现完全没有差别,它们都属于网络设备,都可以配置 IP,都归 Linux 网络设备管理模块统一管理。
- tap 工作在数据链路层:只能处理二层的以太网数据帧,与其中的以太网(Ethernet)协议对应,所以 tap 有时也称为 “虚拟以太网设备” 。
![]()
- tun 工作在网络层:是一个点对点(Peer To Peer)的网络层设备,只能处理 IP 数据包,通常用于建立 IP 层隧道(Tunnel)。
![在这里插入图片描述]()

作为网络设备,tap/tun 也需要配套相应的驱动程序才能工作。tap/tun 驱动程序包括两个部分:
- 字符设备驱动:负责数据包在内核空间和用户空间的传送。
- 网卡驱动:负责数据包在内核网络协议栈上的传输和处理。
tap/tun 作为用户空间与内核空间的数据传输通道
在 Linux 中,用户空间和内核空间的数据传输有多种方式,字符设备就是其中的一种。tap/tun 通过驱动程序和一个与之关联的字符设备文件,来实现用户空间和内核空间的通信接口。
在 Linux 内核 2.6.x 之后的版本中,tap/tun 对应的字符设备文件分别为:
- tap:/dev/tap0
- tun:/dev/net/tun
字符设备文件即充当了用户空间和内核空间通信的接口。当应用程序打开设备文件时,驱动程序就会创建并注册相应的虚拟设备接口,一般以 tunX 或 tapX 命名。当应用程序关闭文件时,驱动也会自动删除 tunX 和 tapX 设备,还会删除已经建立起来的路由等信息。
tap/tun 设备文件就像一个管道,一端连接着用户空间,一端连接着内核空间。当用户程序向文件 /dev/net/tun 或 /dev/tap0 写数据时,内核就可以从对应的 tunX 或 tapX 接口读到数据,反之,内核可以通过相反的方式向用户程序发送数据。
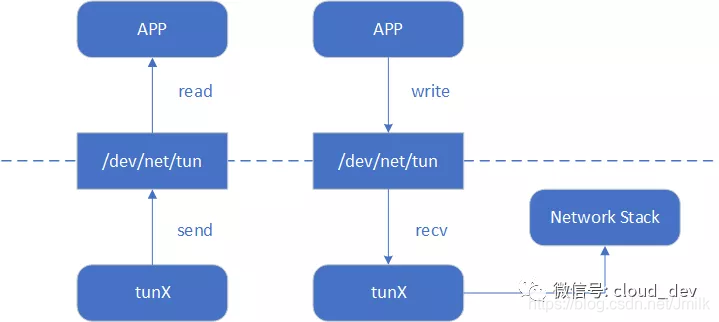
tap/tun 与内核网络协议栈的数据传输
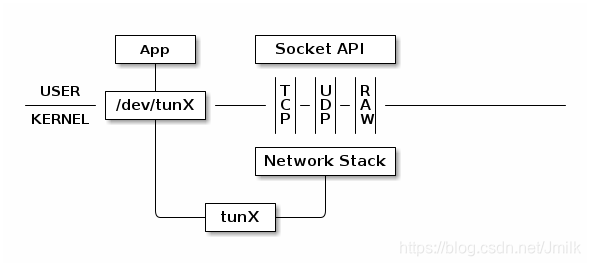
tap/tun 通过实现相应的网卡驱动程序来和 TCP/IP 网络协议栈通信。一般的流程和物理网卡和协议栈的交互流程是一样的,不同的是物理网卡一端是连接物理网络,而 tap/tun 虚拟网卡一般连接到用户空间。
首先看看物理网卡是如何工作的,物理网卡时收到数据包之后就会交给内核网络协议栈处理,然后通过 Socket API 通知给用户程序。
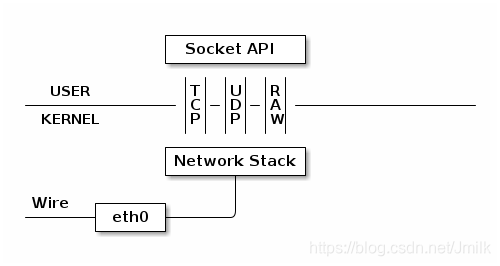
下面看看 tun 的工作方式,物理网卡通过网线收发数据包,但是 tun 设备通过一个字符设备文件收发数据包。
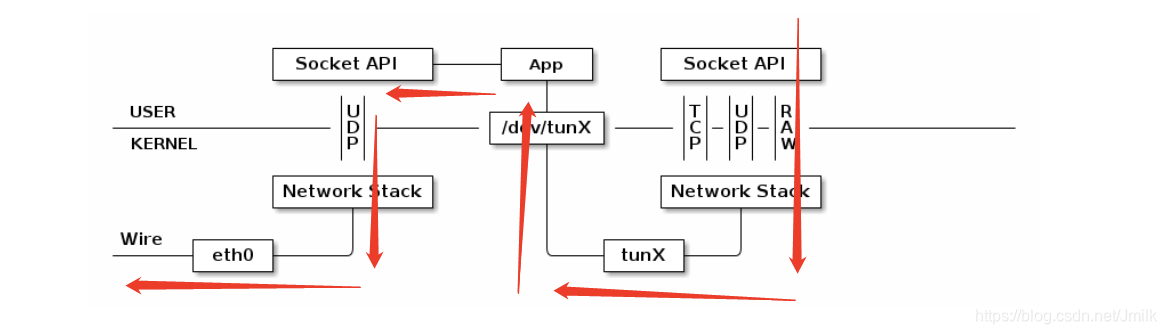
如果使用 tun 设备搭建一个基于 UDP VPN,那么整个处理过程就是这样:数据包会通过内核网络协议栈两次,在经过 VPN App 的处理后,数据包可能已经加密,并且原有的 IP Header 被封装在 UDP 内部,所以网络包在第二次通过内核网络栈时看到的是截然不同的网络包。
再举一个例子,我们有两个应用程序 A、B,物理网卡 eth0 和虚拟网卡 tun0 分别配置 IP:10.1.1.11 和 192.168.1.11,程序 A 希望构造数据包发往 192.168.1.0/24 网段的主机 192.168.1.1。
+----------------------------------------------------------------+
| |
| +--------------------+ +--------------------+ |
| | User Application A | | User Application B |<-----+ |
| +--------------------+ +--------------------+ | |
| | 1 | 5 | |
|...............|......................|...................|.....|
| ↓ ↓ | |
| +----------+ +----------+ | |
| | socket A | | socket B | | |
| +----------+ +----------+ | |
| | 2 | 6 | |
|.................|.................|......................|.....|
| ↓ ↓ | |
| +------------------------+ 4 | |
| | Newwork Protocol Stack | | |
| +------------------------+ | |
| | 7 | 3 | |
|................|...................|.....................|.....|
| ↓ ↓ | |
| +----------------+ +----------------+ | |
| | eth0 | | tun0 | | |
| +----------------+ +----------------+ | |
| 10.32.0.11 | | 192.168.3.11 | |
| | 8 +---------------------+ |
| | |
+----------------|-----------------------------------------------+
↓
Physical Network
- 应用程序 A 构造数据包,目的 IP 是 192.168.1.1,通过 socket A 将这个数据包发给协议栈。
- 协议栈根据数据包的目的 IP 地址,匹配路由规则,发现要从 tun0 出去。
- tun0 发现自己的另一端已经被应用程序 B 打开,于是将数据发给程序 B。
- 程序 B 收到数据后,做一些跟业务相关的操作,然后构造一个新的数据包,源 IP 是 eth0 的 IP,目的 IP 是 10.1.1.0/24 的网关 10.1.1.1,封装原来的数据的数据包,重新发给协议栈。
- 协议栈再根据本地路由,将这个数据包从 eth0 发出。
后续步骤,当 10.1.1.1 收到数据包后,会进行解封装,读取里面的原始数据包,继而转发给本地的主机 192.168.1.1。当接收回包时,也遵循同样的流程。在这个流程中,应用程序 B 的作用其实是利用 tun0 对数据包做了一层隧道封装。
tap 设备与 tun 设备工作方式完全相同,区别在于:tun 设备的 /dev/tunX 文件收发的是 IP 层数据包,只能工作在 IP 层,无法与物理网卡做 bridge,但是可以通过三层交换(e.g. ip_forward)与物理网卡连通;而 tap 设备的 /dev/tapX 文件收发的是 MAC 层数据包,拥有 MAC 层功能,可以与物理网卡做 bridge,支持二层广播。
物理网卡的虚拟化(MACVLAN 和 MACVTAP)
MACVLAN
有时候我们可能会需求一块物理网卡能够绑定多个 IP 以及多个 MAC 地址,绑定多个 IP 很容易,但是这些 IP 会共享物理网卡的 MAC 地址,可能无法满足我们的设计需求,所以就有了物理网卡虚拟化技术 —— macvlan 设备。
macvlan 是 Linux kernel v3.9-3.19 和 4.0+ 版本的新特性,比较稳定的版本推荐 4.0+,它一般以内核模块的形式存在。
# modprobe macvlan
# lsmod | grep macvlan
macvlan 24576 0
macvlan 这种技术听起来有点像 VLAN,但它们的实现机制是完全不一样的。macvlan 子接口和原来的主接口是完全独立的,可以单独配置 MAC 地址和 IP 地址,而 VLAN 子接口和主接口共用相同的 MAC 地址。VLAN 用来划分广播域,而 macvlan 共享同一个广播域。
其工作方式如下:
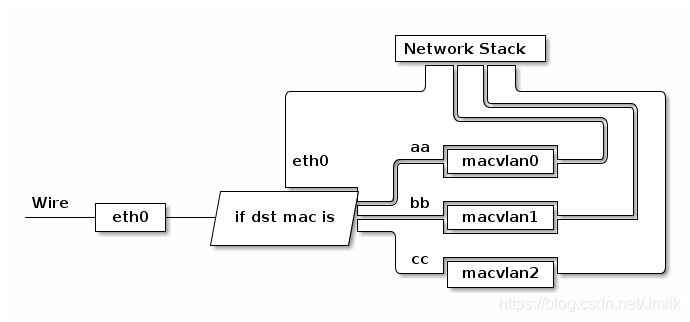
通过不同的子接口,macvlan 做到了流量的隔离。macvlan 会根据数据帧的目的 MAC 地址来判断这个帧需要交给哪张虚拟网卡,虚拟网卡再把包交给上层的内协议栈处理。
根据 macvlan 子接口之间的通信模式,macvlan 有四种网络模式:
- private 模式
- vepa(virtual ethernet port aggregator,虚拟以太网端口聚合器)模式
- bridge 模式
- passthru 模式
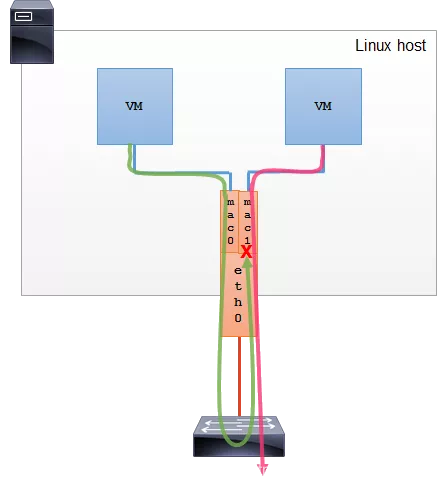
Private 模式
这种模式下,同一主接口下的子接口之间彼此隔离,不能通信。即使从外部的物理交换机导流,也会被无情地丢掉。
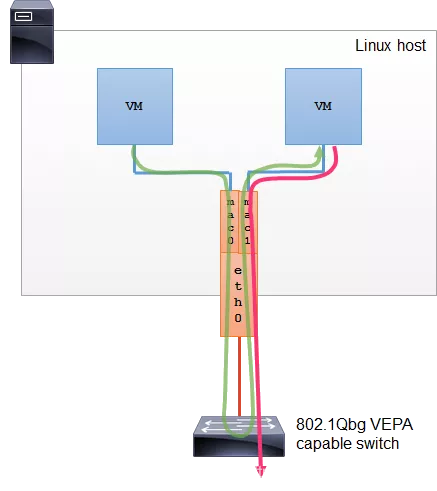
VEPA 模式
这种模式下,子接口之间的通信流量需要导到外部支持 802.1Qbg/VPEA 功能的交换机上(可以是物理的或者虚拟的),经由外部交换机转发,再绕回来。
注: 802.1Qbg/VPEA 功能简单说就是交换机要支持发夹(Hairpin) 功能,也就是数据包从一个接口上收上来之后还能再扔回去。
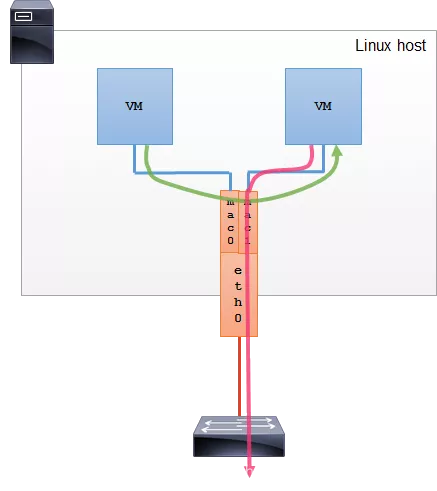
Bridge 模式
这种模式下,模拟的是 Linux bridge 的功能,但比 bridge 要好的一点是每个接口的 MAC 地址是已知的,不用学习。所以,这种模式下,子接口之间就是直接可以通信的。
Passthru 模式
这种模式,只允许单个子接口连接主接口,且必须设置成混杂模式,一般用于子接口桥接和创建 VLAN 子接口的场景。
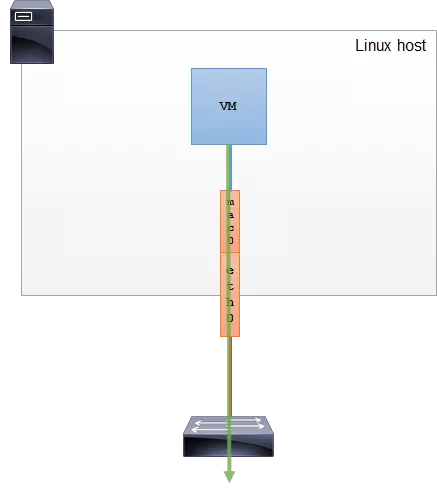
MACVTAP
macvtap 是对 macvlan 的改进,把 macvlan 与 tap 特点结合了,使用 macvlan 的方式收发数据包,但是收到的包不交给内核网络协议栈处理,而是直接交个 tap 的 /dev/tapX 字符设备文件,再进入特定的 APP 处理。由于 macvlan 是工作在 MAC 层的,所以 macvtap 也只能工作在 MAC 层,不会有 macvtun 这样的设备。
macvtap 结合 Network namespace 使用可以构建这样的网络:
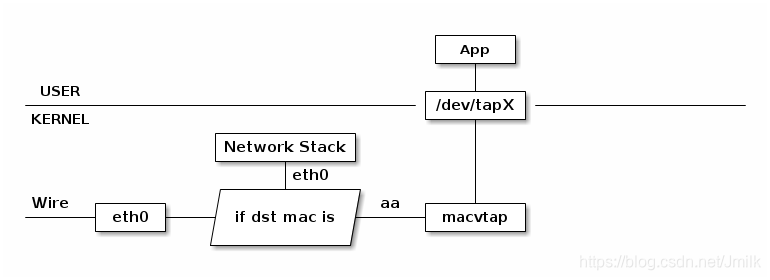
由于 macvlan 与 eth0 处于不同的 Network namespace,它们拥有不同的内核网络协议栈,这样就不需要 bridge 也能在 namespace 里面使用网络了。
虚拟网桥(Linux Bridge)
在 Linux 的语境中,Bridge(网桥)和 Switch(交换机)具有近似的定义。Linux Bridge 就是 Linux 操作系统中用来做二层数据帧交换的虚拟网桥设备。Bridge 可以与上述的 RAW Ethernet 设备(e.g. tap、veth pair)连接,类似于将一台主机通过网线接入到物理交换机。当接收到数据时,Bridge 就会根据数据帧中的 MAC 地址进行广播、转发或过滤处理。

Bridge 的功能主要在 Linux Kernet 里实现。当一个从设备被 attach 到 Bridge 上时,内核程序的 netdev_rx_handler_register() 被调用,一个用于接受数据的回调函数被注册。以后每当这个从设备收到数据时都会调用这个函数可以把数据转发到 Bridge 上。当 Bridge 接收到此数据时,br_handle_frame() 被调用,进行一个和物理交换机类似的处理过程:判断包的类别(广播 or 单播),查找内部 MAC-Port 映射表,定位 Bridge 目标端口,将数据转发到目标端口或者丢弃,同事自动更新内部 MAC-Port 映射表完成自适应或自学习。
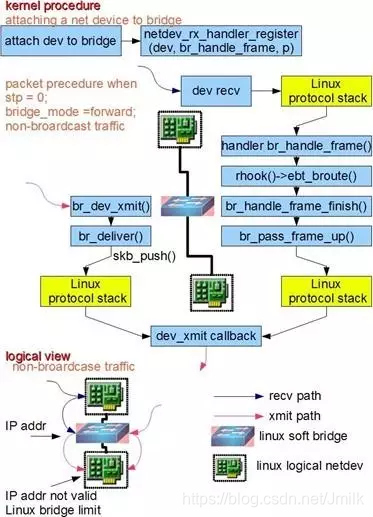
Bridge 和物理交换机有一个区别,数据帧是被直接发送到 Bridge 上的,而不像物理交换机从某个端口接受到数据帧。这是因为 Bridge 具有缺省 MAC 的特性,可以主动发送报文,也就可以为 Bridge 设置 IP 地址。Linux 上的程序可以直接从这个端口向 Bridge 上的其他端口发数据。所以当 attach 一个从设备(e.g. eth0)到 Bridge 之后,Bridge 就拥有了两个有效 MAC 地址,一个是 Bridge 自身的,一个是 eth0 的,他们之间可以通讯。
通常来说 IP 地址是三层协议的内容,不应该出现在二层 Bridge 上。但实际上,由于 Bridge 是一种 Linux Kernel 对通用网络设备的抽象,对于 Kernel 而言只要是网络设备就能够设定 IP 地址。Bridge 的 IP 地址就类似于物理交换机的管理 IP 地址,当 br0 拥有 IP 后,Linux 就可以通过路由表在网络层定位到 br0。就相当于 Linux 拥有了一张 “隐藏的网卡” 和 Bridge 的 “隐藏端口” 相连,两者组成了一张 “Linux 网卡” 可用于收发 IP 数据包。当 IP 数据包到达 Bridge 时,内核协议栈就认为收到了一个数据包,此时 Bridge 可以通过 Socket 接收到它。
Bridge 的实现当前有一个限制:当一个从设备被 attach 到 Bridge 上后,这个从设备的 IP 地址就会失效,此时应该把 IP 地址赋予 Bridge。
还要一点需要注意的,对于一个被 attach 到 Bridge 上的从设备来说,只有在收到数据报文时,此数据报文才会被转发到 Bridge 进而完成查 MAC-Port 地址表和进行广播等后续操作。但是当从设备的请求是发送类型时,数据报文是不会被经过 Bridge 上的,它会寻找下一个发送出口。用户在配置网络时经常会忽略这一点从而造成网络故障。
虚拟局域网(Linux VLAN device for 802.1.q)
VLAN 的种类很多,按照协议原理一般分为:MACVLAN、802.1.q VLAN、802.1.qbg VLAN、802.1.qbh VLAN。其中出现较早,应用广泛并且成熟的是 802.1.q VLAN。
1999 年,IEEE(Institute of Electrical and Electronics Engineers,电气电子工程师学会)颁布了 VLAN 802.1Q 协议标准草案,VLAN 协议可将大型网络划分为多个小型局域网络,有效避免了广播风暴和提升了网络间的安全性。
802.1.q VLAN 的基本原理是在二层协议里插入额外的 VLAN 协议数据(称为 802.1.q VLAN Tag),同时保持和传统二层设备的兼容性。Linux 里的 VLAN 设备是对 802.1.q 协议的一种内部软件实现,模拟现实世界中的 802.1.q 交换机。
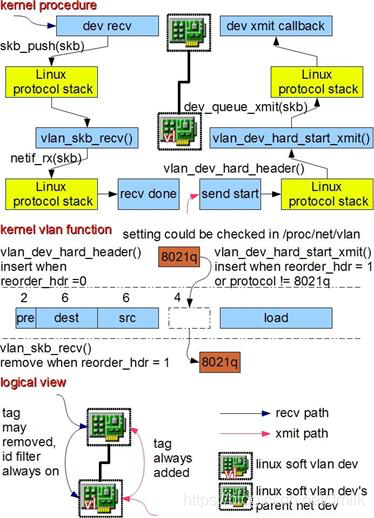
如上图所示,Linux 的 802.1.q VLAN 设备是以 “母子关系” 成对出现的,母设备相当于现实世界中的交换机 Trunk 口,用于连接上级网络,子设备相当于普通 Access 口用于连接下级网络。当数据在母子设备间传递时,内核将会根据 802.1.q VLAN Tag 进行对应的操作。母子设备之间是一对多的关系。
当一个子设备有数据包需要发送时,数据报文将被打上 VLAN Tag 然后从母设备发送出去。当母设备收到数据包时,它会分析其中的 VLAN Tag,如果有对应的子设备存在,则把数据报文转发到那个子设备上并根据设置移除 VLAN Tag,否则丢弃该数据。在某些设置下,VLAN Tag 可以不被移除以满足某些监听程序的需要,如 DHCP 服务程序。
举例说明如下:eth0 作为母设备创建一个 ID 为 100 的子设备(子网卡) eth0.100。此时如果有程序要求从 eth0.100 发送数据包,数据报文将被打上 VLAN 100 的 Tag 从 eth0 发送出去。如果 eth0 收到一个数据包,VLAN Tag 是 100,数据将被转发到 eth0.100 上,并根据设置决定是否移除 VLAN Tag。如果 eth0 收到一个包含 VLAN Tag 101 的数据,则将其丢弃。
上述过程隐含以下事实:对于宿主 Linux 操作系统来说,母设备只能用来收数据,子设备只能用来发送数据。和 Bridge 一样,母子设备的数据也是有方向的,子设备收到的数据不会进入母设备,同样母设备上请求发送的数据不会被转到子设备上。可以把 VLAN 母子设备作为一个整体想象为现实世界中的 802.1.q 交换机,下级接口通过子设备连接到宿主 Linux 系统网络里,上级接口同过主设备连接到上级网络,当母设备是物理网卡时上级网络是外界真实网络,当母设备是另外一个 Linux 虚拟网络设备时上级网络仍然是宿主 Linux 系统网络。
需要注意的是母子 VLAN 设备拥有相同的 MAC 地址,可以把它当成现实世界中 802.1.q 交换机的 MAC,因此多个 VLAN 设备会共享一个 MAC。当一个母设备拥有多个 VLAN 子设备时,子设备之间是隔离的,不存在 Bridge 那样的交换转发关系,原因如下:802.1.q VLAN 协议的主要目的是从逻辑上隔离子网。现实世界中的 802.1.q 交换机存在多个 VLAN,每个 VLAN 拥有多个端口,同一 VLAN 端口之间可以交换转发,不同 VLAN 端口之间隔离。
所以交换机包含了两层功能:交换与隔离。Linux VLAN device 实现的是隔离功能,没有交换功能。一个 VLAN 母设备不可能拥有两个相同 ID 的 VLAN 子设备,因此也就不可能出现数据交换情况。如果想让一个 VLAN 里接多个设备,就需要交换功能。在 Linux 里 Bridge 专门实现交换功能,因此将 VLAN 子设备 attach 到一个 Bridge 上就能完成后续的交换功能。总结起来,Bridge 加 VLAN device 能在功能层面完整模拟现实世界里的 802.1.q 交换机。
Linux 虚拟交换机 = Linux Bridge + VLAN
NOTE:Linux 支持 VLAN 硬件加速,在安装有特定硬件情况下,图中所述内核处理过程可以被放到物理设备上完成。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号