
虚拟化的发展历程和实现方式
2016-03-31 23:18 云物互联 阅读(133) 评论(0) 收藏 举报目录
前言
现在市场上最常见的虚拟化软件有VMWare workstation(VMWare)、VirtualBox(Oracle)、Hyper-V(Microsoft)、KVM(Redhat)、Xen等,这些软件统称之为VMM(Virtual Machine Monitor),使用不同的虚拟化实现。而这些虚拟化实现的方式可以分为全虚拟化、半虚拟化、硬件虚拟化等,本篇主要是理解这些虚拟化实现的原理。
虚拟化
虚拟化的诞生与实现:
1961年 — IBM709机实现了分时系统,将CPU占用切分为多个极短(1/100sec)时间片,每一个时间片都执行着不同的任务。通过对这些时间片的轮询,这样就可以将一个CPU虚拟化或者伪装成为多个CPU,并且让每一颗虚拟CPU看起来都是在同时运行,这就是虚拟机的雏形。后来的system360机都支持分时系统。
1972年 — IBM正式将system370机的分时系统命名为虚拟机。
1990年 — IBM推出的system390机支持逻辑分区,即将一个cpu分为若干份(最多10份),而且每份cpu都是独立的,也就是一个物理cpu可以逻辑的分为10个cpu。
直到IBM将分时系统开源后,个人PC终于临来了虚拟化的开端,后来才有了上述的虚拟机软件的发展。所以至今为止仍然有一部分虚拟机软件应用来了分时系统作为虚拟化的基础实现。
虚拟化的目的:使用逻辑来表示资源,从而摆脱物理限制的约束。提高物理资源的利用率。
虚拟化的原理:在OS中加入一个虚拟化层(VMM),虚拟化层可以对下层(HostOS)硬件资源(物理CPU、内存、磁盘、网卡、显卡等)进行封装、隔离,抽象为另一种形式的逻辑资源,再提供给上层(GuestOS)使用。所以你可以理解VMM其实就是联系HostOS和GuestOS的一个中间件,当然虚拟化可以将一份资源抽象为多份,也可以将多份资源抽象为一份。
通过虚拟化技术实现的虚拟机一般被称之为GuestOS(客户),而作为GuestOS载体的物理主机称之为HostOS(宿主)。
虚拟机Virtual Machine
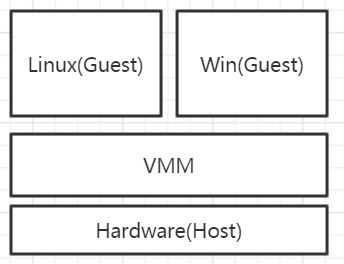
- 由VMM提供的高效(>80%)、独立的计算机系统
- 拥有自己的虚拟硬件(CPU、内存、网络设备、存储设备)
- 对于上层软件,虚拟机就是真实的机器
- Virtual Machine Monitor
满足上面几个条件的OS就是虚拟机。
VM的特性
同质:VM的本质与物理机的本质相同,e.g. CPU的ISA(指令集架构 Instruction Set Architecture)相同
高效:性能与物理机接近,在VM上执行的大多数指令应该有权限和能力直接在硬件上执行,只有少数的敏感指令由VMM来处理。对于VM的性能效率在上一篇
资源可控:VMM对物理机和虚拟机的资源都是绝对可控的
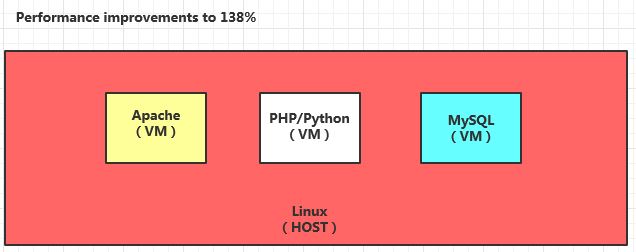
Redhat曾经测试过一些应用服务在虚拟机上运行的效率。一部分的报告如下:
| IBM DB2 | SAP | ORACLE | JAVA | LAMP |
|---|---|---|---|---|
| VM=HOST * 90% | VM=HOST * 90% | VM=HOST * 90% | VM=HOST * 94% | VM=HOST * 138% |
NOTE:LAMP在VM上运行的效率之所以能够提高是因为将Apache、PHP/Python、MySQL 3个应用服务拆分到3个不同的VM中运行。
虚拟化的分类
在虚拟化发展的早期主要以全虚拟化和半虚拟化两大流派为主,两者各有优缺点。如果能适当的将其应用不同的环境中,就能充分的发挥两者的特性以获得更高的收益。随着这两大流派的分歧和竞争愈演愈烈,由Intel领衔的硬件厂商也纷纷加入到虚拟化的浪潮中,开启了(大航海时代)硬件虚拟化的时代,从此全虚拟化和半虚拟化前进的道路逐渐有了靠拢的趋势。再到后来的 第二代的内存虚拟化、第三代的总线虚拟化 的出现和兴起,当下虚拟化市场已经不再以单纯卖卖虚拟化软件为主要盈利手段,而是将虚拟化技术整合在更大、更完善的虚拟化平台解决方案中。其中包括Redhat的RHEV、VMWare的vSphere等。
x86 CPU架构与虚拟化的关系
在理解各种虚拟化的实现之前,首先需要了解一般x86 CPU的架构。
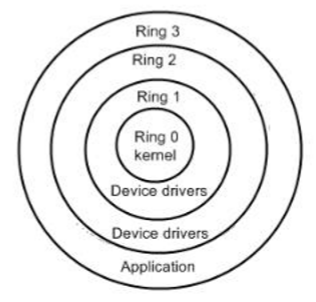
注意:CPU为了保证程序代码执行的安全性、多用户的独立性、保护OS的正常运行,提出了CPU执行状态的概念。这样能够限制不同程序之间的访问能力,避免一个程序获取另一个程序的内存数据造成数据混乱,同时也避免了程序错误的操作物理硬件。一般CPU都会划分为 用户态 和 内核态 ,x86的CPU架构更是细分为了Ring3~0四种状态。
Ring3 用户态(User Mode):运行在用户态的程序代码需要受到CPU的检查,用户态程序代码只能访问 内存页表项中 规定能被用户态程序代码访问的页面虚拟地址(受限的内存访问),而且还只能访问 TSS中的I/O Permission Bitmap 中规定能被用户态程序代码访问的端口。甚至不能直接访问外围硬件设备、不能抢占CPU。所有的应用程序(Application)都运行在用户态上。——当运行在用户态的Application需要调用只能被核心态代码直接访问的硬件设备时,CPU会通过特别的接口去调用核心态的代码,以此来实现Application对硬件设备的调用。 如果用户态的Application直接调用硬件设备时,就会被Host OS捕捉到并触发异常,弹出警告窗口。
Ring0 核心态(Kernel Mode):是Host OS Kernel运行的模式,运行在核心态的代码可以无限制的对系统内存、设备驱动程序、网卡接口、显卡接口等外围硬件设备进行访问。只有Host OS能够无限制的访问磁盘、键盘等外围硬件设备的数据,但是首先需要在Host OS上安装驱动程序。
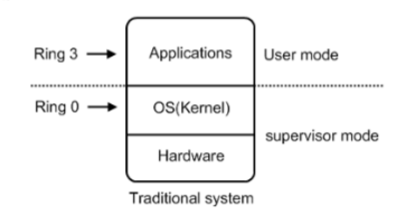
虚拟化实现图:
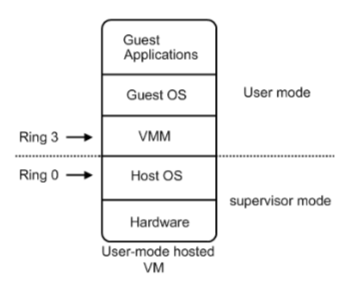
粗略而言,GuestOS和VMM都属于运行在Ring3上的应用程序,GuestOS操作硬件设备时并执行操作指令时,VMM会将该操作指令监控、捕获、检测后将指令传递给HostOS,HostOS会将GuestOS发出的运行于用户态的操作指令模拟为核心态指令。
注意:当上述的流程是非常简略的,在与全虚拟化和半虚拟化的实现过程集合时,就会变得非常复杂。
全虚拟化 Full virtualization
GuestOS可以直接在全虚拟化VMM上运行而不需要对GuestOS本身的核心代码做任何修改,全虚拟化的GuestOS具有完全的物理机特性。既VMM会为GuestOS抽象模拟出它所需要的包括CPU、磁盘、内存、网卡、显卡等抽象硬件资源,所以全虚拟化的GuestOS并不会知道自己其实是一台虚拟机。
结合上述的虚拟化实现图来看:当我们使用GuestOS的时候,不可避免的会调用GuestOS中的 虚拟设备驱动程序 和 核心调度程序 来操作硬件设备。与HostOS的不同在于,HostOS运行在CPU的核心态中,这就表示HostOS可以直接对硬件设备进行操作。但GuestOS作为一个运行在CPU用户态中应用程序,不能够直接的操作硬件设备。为了解决这个问题,VMM引用了两个机制——特权解除 & 陷入模拟。
特权解除:也称之为 翻译,当GuestOS需要调用运行在核心态的指令时,VMM就会动态的将核心态指令捕获并调用若干运行在非核心态的指令来模拟出期望得到的效果(GuestOS和VMM是运行在用户态上的应用程序),从而将核心态的特权解除。解除了核心态的特权后,就能够在GuestOS中执行大部分的核心态指令了。但是,这仍然不能完美的解决问题。因为在一个OS的指令集中还存在着一种敏感指令(可能是内核态,也可能是用户态)。此时就需要陷入模拟的实现。
陷入模拟:无论是HostOS还是GuestOS,只要是一个OS都必然会存在有敏感指令(reboot、shutdown等)。试想如果我们希望将GuestOS重启,并在GuestOS中执行了reboot指令,但是却将HostOS给重启了,这将会非常糟糕。VMM的陷入模拟机制就是为了解决这个问题。e.g. 在GuestOS中执行了敏感指令reboot时,VMM首先会将敏感指令reboot捕获、检测并判定其为敏感指令。此时VMM就会陷入模拟,将敏感指令reboot模拟成一个只针对GuestOS进行操作的、非敏感的、并且运行在非核心态上的"reboot"指令,最后CPU执行虚拟机的重启操作。
由于全虚拟化VMM会频繁的捕获这些核心态的和敏感的指令,将这些指令进行转换之后,再交给CPU执行。所以 经过了两重转换,导致其效率会比半虚拟化更低,但全虚拟化VMM应用程序的好处在于其不需要对GuestOS的核心源码做修改,所以全虚拟化的VMM可以安装绝大部分的OS(暂时来说只有已Linux、open soralis、BSD等几种OS开源了内核代码)。典型的全虚拟化软件有 —— VMWare、Hyper-V、KVM-x86(复杂指令集)。
全虚拟化的两种实现方式:
1). 基于二进制翻译的全虚拟化
2). 基于扫描和修补的全虚拟化
半虚拟化 Paravirtualization
半虚拟化是需要GuestOS协助的虚拟化。因为在半虚拟化VVMM中运行的GuestOS,都需要将其内核源码进行都进过了特别的修改。半虚拟化VMM在处理敏感指令和内核态指令的流程上相对更简单一些。在半虚拟化VMM上运行的GuestOS都需要修改内核代码,主要是修改GuestOS指令集中的敏感指令和核心态指令。让HostOS在捕抓到没有经过半虚拟化VMM模拟和翻译处理的GuestOS内核态指令或敏感指令时,HostOS也能够准确的判断出该指令是否属于GuestOS(GuestOS知道自己是虚拟机)。这样就可以高效的避免了上述问题。典型的半虚拟化软件有——Xen、KVM-PowerPC(简易指令集)
半虚拟化除了修改内核外还有另外一种实现方法——在每一个GuestOS中安装半虚拟化软件,e.g. VMTools、RHEVTools。
注意:若使用KVM运行Windows时,一定要安装半虚拟化驱动Tools,否则无法工作。现在主流的半虚拟化驱动是由IBM和redhat联合开发一个通用半虚拟机驱动virtio 。
硬件辅助虚拟化 HVM
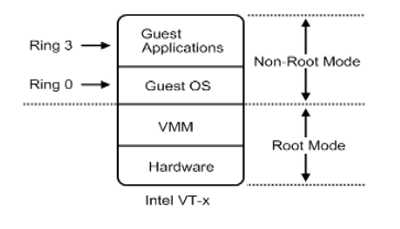
2005年 — Intel提出并开发了由CPU直接支持的虚拟化技术。这种虚拟化技术引入新的CPU运行模式和新的指令集,使得VMM和GuestOS运行于不同的模式下(VMM=Root Mode;GuestOS=Non-Root Mode),GuestOS运行于受控模式,原来的一些敏感指令在受控模式下会全部陷入VMM,由VMM来实现模拟,这样就解决了部分非内核态敏感指令的陷入——模拟难题,而且模式切换时上下文的保存恢复由硬件来完成,这样就大大提高了陷入——模拟时上下文切换的效率 。该技术的引入使x86 CPU可以很容易地实现完全虚拟化。故皆被几乎所有之前分歧的各大流派所采用,包括KVM-x86,VMWare ESX Server 3,Xen 3.0 。
HVM的分类:
1). Intel –> VT-X
2). AMD –> AMD-V
内存虚拟化
原来的GuestOS使用的是虚拟内存,不可以缺少虚拟内存到物理内存的翻译,影响了虚拟机的效率。后来Intel EPT AMD RVI表示支持内存虚拟化。
内存虚拟化的映射实现*
A –> 虚拟地址(VA),指GuestOS提供给其应用程序使用的线性地址空间。
B –> 物理地址(PA),经VMM抽象的,虚拟机看到的伪物理地址
C –> 机器地址(MA),真是的机器物理地址,即地址总线上出现的地址信号
内存地址的映射关系::
GuestOS:PA = f(VA) #GuestOS维护着一套页表,负责VA到PA的映射
VMM:MA = g(PA) #VMM维护着一套页表,负责PA到MA的映射
通过转换方法实现了从虚拟地址到机器地址的映射。实际运行时,用户程序访问VA1,经过GuestOS的页表转换得到PA1,再由VMM介入并使用VMM的页表将PA1转换为MA1 。
总线虚拟化
分类:
1). Intel –> VT/d
2). AMD –> iommu
总线虚拟化可以实现将一块网卡分给若干个GuestOS使用,每个虚拟机1/N,性能高,接近真机。
从软件的角度出发,IO设备就是一堆状态寄存器,控制寄存器,中断并与其交互
主要的虚拟化方式:设备接口完全模拟、前端-后端模拟(Xen)
直接划分:直接把物理设备划分给Guest OS,无须经过VMM。Intel VT-d
内存虚拟化和总线虚拟化进一步的拉近了GuestOS和HostOS的运行性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号