
计算机组成原理 — 指令系统
2019-07-18 16:30 云物互联 阅读(1572) 评论(0) 编辑 收藏 举报目录
文章目录
前文列表
《计算机组成的基本硬件设备》
《计算机组成原理 — 冯诺依曼体系结构》
《计算机组成原理 — 中央处理器》
指令系统
指令系统
指令系统决定了计算机的基本功能。计算机的性能与它所设置的指令系统有很大的关系,而指令系统的设置又与机器的硬件结构密切相关。指令系统的改进主要围绕缩小指令与高级语言的语义差异以及有利于操作系统的优化而进行的,例如:高级语言中经常用到的 if 语句、do 语句,所以设置了功能较强的条件跳转指令;为了操作系统的实现和优化,设置了有控制系统状态的特权指令、管理多道程序和多处理机系统的专用指令。
然后指令系统太过于复杂并不完全是好事,在大多数场景中实际上只有算术逻辑运算、数据传输、跳转和程序调用等几十条指令会被频繁的使用到,而需要大量硬件支持的大多数复杂的指令却并不常用,由此会造成硬件资源的浪费。为了解决这个问题,指令系统被分为 精简指令系统计算机(RISC) 和 复杂指令系统计算机(CISC)。
计算机指令集与程序指令
计算机指令集是 CPU 提供的可执行指令的集合;而程序所描述的指令是程序员希望在 CPU 上执行的指令,这些指令的范围不会超出计算机指令集的范围。不同类型的 CPU 能够理解不同的 “语言”,即具有不同的计算机指令集(Instruction Set)。同一个程序可以在相同型号的 CPU 中运行,反之则无法运行。
CPU 运行一个计算机程序的本质就是运行这个程序所描述的指令,有如我们在 Linux 操作系统上执行指令一般,只是前者由 CPU 硬件支持。一个计算机程序通常由成千上万条指令组成,CPU 显然不能存放所有的指令,而是将这些指令存放在存储器中,只有在运行时才会被 CPU 读取。又因为现代计算机被设计为可以运行多种程序,存储器被各种各样的程序共享着,所以存储器也不会持久化的保存它们。而是当我们要运行(启动)某个程序时,才会将其加载到存储器中,最终再由 CPU 从存储器中逐一读取其指令。我们常见的内部存储器多为 RAM(随机存储器),这是一种被设计成掉电就会自动重置的存储设备。
以上就是冯·诺依曼机的典型特性,所以又称之为 “存储程序计算机”。冯·诺依曼体系结构解决了计算机实现领域的一个重要难题:如何能够动态加载程序指令。解决了这个问题,“计算器” 才得以成为 “计算机”,我们今天才得以在计算机上运行各种各样的应用程序。
注:计算器的 “程序” 是焊死在主板上的。
指令格式
计算机是通过执行指令来处理各种数据的,为了了解数据的来源、操作结果的去向及所执行的操作类型,一条计算机指令一般包含以下信息。
- 操作码:说明操作的性质和功能(e.g. 加减乘除、数据传输),长度有指令系统的指令条数决定(e.g. 256 条指令,则操作码需要 8 位长度)。
- 操作数的地址:CPU 通过该地址读取到所需要的操作数,可能是存储器的地址,也可能是寄存器的地址。
- 操作结果的储存地址:保存操作结果数据的地址。
- 下一条指令的地址:当程序顺序执行时,下一条指令的地址又程序计数器(PC)给出,仅当改变程序的执行顺序时(e.g. 跳转、函数调用),下一条指令的支持才会有指令本身给出。
综上,指令格式主要有 操作码 和 地址码 组成。需要注意的是,在指令字长较长的计算机中,操作码的长度一般是固定的,并且由指令集的数量决定。但在指令字较短的计算机中,为了能够充分利用指令字的位数,在有限的长度中实现更多的指令集数目,所以其操作码长度被设计成是可变的,即把它们的操作码在必要的时候扩充到地址码字段。这就是所谓的 指令操作码扩展技术。指令字的长度与 CPU 的位数密切相关。
指令类型
日常使用的 Intel CPU 大概有 2000 多条 CPU 指令。可以分为以下 5 大类型:
- 算术类指令:加减乘除。
- 数据传输类指令:变量赋值、读写内存数据。
- 逻辑类指令:与或非。
- 条件分支类指令:条件判断语句。
- 无条件跳转指令:方法、函数的调用跳转。

继续细分的话,具有如下指令类型:
- 算术逻辑运算指令
- 移位操作指令
- 算术移位
- 逻辑移位
- 循环移位
- 矢量运算指令(矩阵运算)
- 浮点运算指令
- 十进制运算指令
- 字符串处理指令
- 字符串传送
- 字符串比较
- 字符串查询
- 字符串转换
- 数据传输指令
- 寄存器与寄存器传输
- 寄存器与主存储器单元传输
- 存储器单元与存储器单元传输
- 数据交换(源操作数与目的操作下互换)
- 转移指令
- 条件转移
- 无条件转移
- 过程调用与返回
- 陷阱
- 堆栈及堆栈操作指令
- I/O 指令
- 特权指令
- 多处理机指令(在多处理器系统中保证共享数据的一致性等)
- 控制指令
指令寻址
指令寻址,即是根据指令字的地址码来获取到实际的数据,寻址的方式跟硬件关系密切,不同的计算机有不同的寻址方式。有的计算机寻址方式种类少,所以会直接在操作码上表示寻址方式;有些计算机的寻址方式种类多,就会在指令字中添加一个特别用于标记寻址方式的字段,例如:假设该字段具有 3 位,那么就可以表示 8 种寻址方式。
NOTE:寻址方式与 CPU 内的寄存器设计密切相关。
直接寻址:指令字的地址码直接给出了操作数在存储器中的地址,是最简单的寻址方式。
间接寻址:指令字的地址码所指向的寄存器或存储器的内容并不是真实的操作数,而是操作数的地址。间接寻址常用于跳转指令,只要修改寄存器或存储器的地址就可以实现跳转到不同的操作数上。
相对寻址:把程序计数器(PC)的内容,即当前执行指令的地址与地址码部分给出的偏移量(Disp)之和作为操作数的地址。这种寻址方式同样常用于跳转(转移)指令,当程序执行到本条指令后,跳转到 PC+Disp。
立即数寻址:即地址码本身就是一个操作数的寻址方式,该方式的特点就是数据块(因为实际上没有寻址),但操作数固定。常用于为某个寄存器或存储器单元赋初值,或提供一个常数。
通用寄存器寻址:CPU 中大概会有几个到几十个通用寄存器用于临时储存操作数、操作数的地址或中间结果,指令字的地址码可以指向这些寄存器。通用寄存器具有地址短,存取速度快的特性,所以地址码指向通用寄存器的指令的长度也会更短,节省存储空间,执行效率更快。常被用于执行速度要求严格的指令中。
基址寄存器寻址:基址,即基础地址,基址寄存器就是存放基址的寄存器,可以是一个专用寄存器,也可以使用通用寄存器来充当基址寄存器。执行指令时,需要将基址与指令字的地址码结合得到完成的地址,此时的地址码充当着偏移量(位移量)的角色。当存储器容量较大时,直接寻址方式是无法存取到所有存储单元的,所以通常会采用 分段 或 分页 的内存管理方式。此时,段或页的首地址就会存放于基址寄存器中,而指令字的地址码就作为段或页的长度,这样只要修改基址寄存器的内容就可以访问到存储器的任意单元了。这种寻址方式常被用于为程序或数据分配存储区,与虚拟地址实现密切相关。基址寄存器寻址方式解决了程序在存储器中的定位存储单元和扩大 CPU 寻址空间的问题。
变址寄存器寻址:变址寄存器内的地址与指令字地址之和得到了实际的有效地址,如果 CPU 中存在基址寄存器,那么就还得加上基址地址。这种寻址方式常用于处理需要循环执行的程序,例如:循环处理数组,此时变址寄存器所改变的就是数组的下标了。
堆栈寻址:堆栈是有若干个连续的存储器单元组成的先进后出(FILO)存储区。堆栈是用于提供操作数和保存运算结果的主要存储区,同时还主要用于暂存中断和子程序调用时的线程数据及返回地址。
通过 MIPS 感受指令字的设计
MIPS(Millions of Instructions Per Second)是一种最简单的精简指令集架构,由 MIPS 科技公司设计。MIPS 指令具有 32 位(最新版本为 64 位),高 6 位为操作码(OPCODE),描述了指令的操作类型。其余 26 位具有 3 种格式:R、I 和 J。不同的指令类型和操作码组合能够完成多种功能实现,如下:

加法算数指令 add $t0,$s2,$s1 的指令字及其对应的机器码如下:

- opcode:0
- rs:代表第一个寄存器 s1 的地址是 17
- rt:代表第二个寄存器 s2 的地址是 18
- rd:代表目标临时寄存器 t0 的地址是 8
- shamt:0,表示不位移
最终加法算数指令 add $t0,$s2,$s1 的二进制机器码表示为 000000 10001 10010 01000 00000 1000000(0X02324020)。可以看见,机器码中没有保存任何实际的程序数据,而是保存了程序数据的储存的地址,这也算是存储程序计算机指令集设计的一大特点。
将高级语言翻译成汇编代码
为什么要保留汇编语言
汇编语言是与机器语言最接近的高级编程语言(或称为中级编程语言),汇编语言基本上与机器语言对应,即汇编指令和计算机指令是相对匹配的。虽然汇编语言具有与硬件的关系密切,占用内存小,运行速度快等优点,但也具有可读性低、可重用性差,开发效率低下等问题。高级语言的出现是为了解决这些问题,让软件开发变得更加简单高效,易于协作。但高级语言也存在自己的缺陷,例如:难以编写直接操作硬件设备的程序等。
所以为了权衡上述的问题,最终汇编语言被作为中间的状态保留了下来。一些高级语言(e.g. C 语言)提供了与汇编语言之间的调用接口,汇编程序可作为高级语言的外部过程或函数,利用堆栈在两者之间传递参数或参数的访问地址。两者的源程序通过编译或汇编生成目标文件(OBJ)之后再利用连接程序(linker)把它们连接成为可执行文件便可在计算机上运行了。保留汇编语言还为程序员提供一种调优的手段,无论是 C 程序还是 Python 程序,当我们要进行代码性能优化时,了解程序的汇编代码是一个不错的切入点。
顺序程序流
计算机指令是一种逻辑上的抽象设计,而机器码则是计算机指令的物理表现。机器码(Machine Code),又称为机器语言,本质是由 0 和 1 组成的数字序列。一条机器码就是一条计算机指令。程序由指令组成,但让人类使用机器码来编写程序显然是不人道的,所以逐步发展了对人类更加友好的高级编程语言。这里我们需要了解计算机是如何将高级编程语言编译为机器码的。
Step 1. 编写高级语言程序。
// test.c
int main()
{
int a = 1;
int b = 2;
a = a + b;
}
Step 2. 编译(Compile),将高级语言编译成汇编语言(ASM)程序。
$ gcc -g -c test.c
Step 3. 使用 objdump 命令反汇编目标文件,输出可阅读的二进制信息。下述左侧的一堆数字序列就是一条条机器码,右侧 push、mov、add、pop 一类的就是汇编代码。
$ objdump -d -M intel -S test.o
test.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
int main()
{
0: 55 push rbp
1: 48 89 e5 mov rbp,rsp
int a = 1;
4: c7 45 fc 01 00 00 00 mov DWORD PTR [rbp-0x4],0x1
int b = 2;
b: c7 45 f8 02 00 00 00 mov DWORD PTR [rbp-0x8],0x2
a = a + b;
12: 8b 45 f8 mov eax,DWORD PTR [rbp-0x8]
15: 01 45 fc add DWORD PTR [rbp-0x4],eax
}
18: 5d pop rbp
19: c3 ret
NOTE:这里的程序入口是 main() 函数,而不是第 0 条汇编代码。

条件程序流
值得注意的是,某些特殊的指令,比如跳转指令,会主动修改 PC 的内容,此时下一条地址就不是从存储器中顺序加载的了,而是到特定的位置加载指令内容。这就是 if…else 条件语句,while/for 循环语句的底层支撑原理。
Step 1. 编写高级语言程序。
// test.c
#include <time.h>
#include <stdlib.h>
int main()
{
srand(time(NULL));
int r = rand() % 2;
int a = 10;
if (r == 0)
{
a = 1;
} else {
a = 2;
}
}
Step 2. 编译(Compile),将高级语言编译成汇编语言。
$ gcc -g -c test.c
Step 3. 使用 objdump 命令反汇编目标文件,输出可阅读的二进制信息。我们主要分析 if…else 语句。
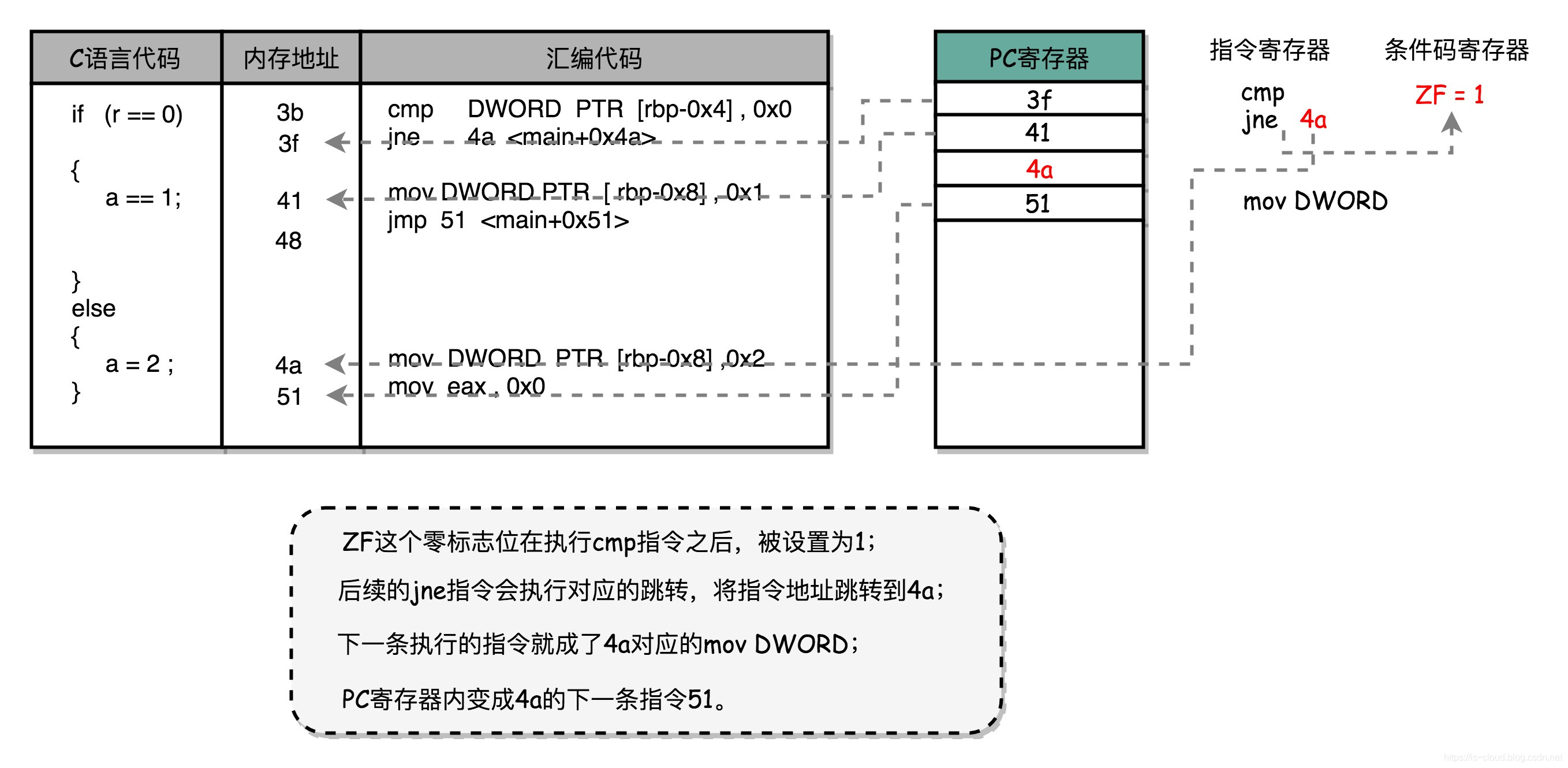
if (r == 0)
33: 83 7d fc 00 cmp DWORD PTR [rbp-0x4],0x0
37: 75 09 jne 42 <main+0x42>
{
a = 1;
39: c7 45 f8 01 00 00 00 mov DWORD PTR [rbp-0x8],0x1
40: eb 07 jmp 49 <main+0x49>
} else {
a = 2;
42: c7 45 f8 02 00 00 00 mov DWORD PTR [rbp-0x8],0x2
}
首先进入条件判断,汇编代码为 cmp 比较指令,比较数 1:DWORD PTR [rbp-0x4] 表示变量 r 是一个 32 位整数,数据在寄存器 [rbp-0x4] 中;比较数 2:0x0 表示常量 0 的十六进制。比较的结果会存入到 条件码寄存器,等待被其他指令读取。当判断条件为 True 时,ZF 设置为 1,反正设置为 0。
条件码寄存器(Condition Code)是一种单个位寄存器,它们的值只能为 0 或者 1。当有算术与逻辑操作发生时,这些条件码寄存器当中的值就随之发生变化。后续的指令通过检测这些条件码寄存器来执行条件分支指令。常用的条件码类型如下:
- CF:进位标志寄存器。最近的操作是最高位产生了进位。它可以记录无符号操作的溢出,当溢出时会被设为 1。
- ZF:零标志寄存器,最近的操作得出的结果为 0。当计算结果为 0 时将会被设为 1。
- SF:符号标志寄存器,最近的操作得到的结果为负数。当计算结果为负数时会被设为 1。
- OF:溢出标志寄存器,最近的操作导致一个补码溢出(正溢出或负溢出)。当计算结果导致了补码溢出时,会被设为 1。
回到正题,PC 继续自增,执行下一条 jnp 指令。jnp(jump if not equal)会查看 ZF 的内容,若为 0 则跳转到地址 42 <main+0x42>(42 表示汇编代码的行号)。前文提到,当 CPU 执行跳转类指令时,PC 就不再通过自增的方式来获得下一条指令的地址,而是直接被设置了 42 行对应的地址。由此,CPU 会继续将 42 对应的指令读取到 IR 中并执行下去。
42 行执行的是 mov 指令,表示将操作数 2:0x2 移入到 操作数 1:DWORD PTR [rbp-0x8] 中。就是一个赋值语句的底层实现支撑。接下来 PC 恢复如常,继续以自增的方式获取下一条指令的地址。
循环程序流
- C 语言代码
// test.c
int main()
{
int a = 0;
int i;
for (i = 0; i < 3; i++)
{
a += i;
}
}
- 计算机指令与汇编代码
for (i = 0; i < 3; i++)
b: c7 45 f8 00 00 00 00 mov DWORD PTR [rbp-0x8],0x0
12: eb 0a jmp 1e <main+0x1e>
{
a += i;
14: 8b 45 f8 mov eax,DWORD PTR [rbp-0x8]
17: 01 45 fc add DWORD PTR [rbp-0x4],eax
for (i = 0; i < 3; i++)
1a: 83 45 f8 01 add DWORD PTR [rbp-0x8],0x1
1e: 83 7d f8 02 cmp DWORD PTR [rbp-0x8],0x2
22: 7e f0 jle 14 <main+0x14>
}

函数调用栈的工作原理
与普通的跳转程序(e.g. if…else、while/for)不同,函数调用的特点在于具有回归(return)的特点,在调用的函数执行完之后会再次回到执行调用的 call 指令的位置,继续往下执行。能够实现这个效果,完全依赖堆栈(Stack)存储区的特性。 首先我们需要了解几个概念。
-
堆栈(Stack):是有若干个连续的存储器单元组成的先进后出(FILO)存储区,用于提供操作数、保存运算结果、暂存中断和子程序调用时的线程数据及返回地址。通过执行堆栈的 Push(压栈)和 Pop(出栈)操作可以将指定的数据在堆栈中放入和取出。堆栈具有栈顶和栈底之分,栈顶的地址最低,而栈底的地址最高。堆栈的 FILO 的特性非常适用于函数调用的场景:父函数调用子函数,父函数在前,子函数在后;返回时,子函数先返回,父函数后返回。
-
栈帧(Stack Frame):是堆栈中的逻辑空间,每次函数调用都会在堆栈中生成一个栈帧,对应着一个未运行完的函数。从逻辑上讲,栈帧就是一个函数执行的环境,保存了函数的参数、函数的局部变量以及函数执行完后返回到哪里的返回地址等等。栈帧的本质是两个指针寄存器: EBP(基址指针,又称帧指针)和 ESP(栈指针)。其中 EBP 指向帧底,而 ESP 指向栈顶。当程序运行时,ESP 是可以移动的,大多数信息的访问都通过移动 ESP 来完成,而 EBP 会一直处于帧低。EBP ~ ESP 之间的地址空间,就是当前执行函数的地址空间。
NOTE:EBP 指向当前位于系统栈最上边一个栈帧的底部,而不是指向系统栈的底部。严格说来,“栈帧底部” 和 “系统栈底部” 不是同一个概念,而 ESP 所指的栈帧顶部和系统栈顶部是同一个位置。
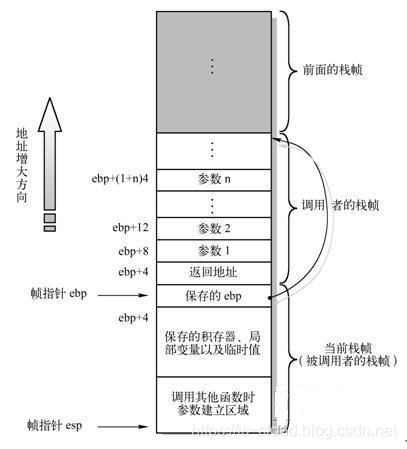
简单概括一下函数调用的堆栈行为,ESP 随着当前函数的压栈和出栈会不断的移动,但由于 EBP 的存在,所以当前执行函数栈帧的边界是始终清晰的。当一个当前的子函数调用完成之后,EBP 就会跳到父函数栈帧的底部,而 ESP 也会随其自然的来到父函数栈帧的头部。所以,理解函数调用堆栈的运作原理,主要要掌握 EBP 和 ESP 的动向。下面以一个例子来说明。
NOTE:我们习惯将将父函数(调用函数的函数)称为 “调用者(Caller)”,将子函数(被调用的函数)称为 “被调用者(Callee)”。
- C 程序代码
#include <stdio.h>
int add(int a, int b) {
int result = 0;
result = a + b;
return result;
}
int main(int argc, char *argv[]) {
int result = 0;
result = add(1, 2);
printf("result = %d \r\n", result);
return 0;
}
- 使用gcc编译,然后gdb反汇编main函数,看看它是如何调用add函数的
(gdb) disassemble main
Dump of assembler code for function main:
0x08048439 <+0>: push %ebp
0x0804843a <+1>: mov %esp,%ebp
0x0804843c <+3>: and $0xfffffff0,%esp
0x0804843f <+6>: sub $0x20,%esp
0x08048442 <+9>: movl $0x0,0x1c(%esp) # 给 result 变量赋 0 值
0x0804844a <+17>: movl $0x2,0x4(%esp) # 将第 2 个参数 argv 压栈(该参数偏移为esp+0x04)
0x08048452 <+25>: movl $0x1,(%esp) # 将第 1 个参数 argc 压栈(该参数偏移为esp+0x00)
0x08048459 <+32>: call 0x804841c <add> # 调用 add 函数
0x0804845e <+37>: mov %eax,0x1c(%esp) # 将 add 函数的返回值地址赋给 result 变量,作为子函数调用完之后的回归点
0x08048462 <+41>: mov 0x1c(%esp),%eax
0x08048466 <+45>: mov %eax,0x4(%esp)
0x0804846a <+49>: movl $0x8048510,(%esp)
0x08048471 <+56>: call 0x80482f0 <printf@plt>
0x08048476 <+61>: mov $0x0,%eax
0x0804847b <+66>: leave
0x0804847c <+67>: ret
End of assembler dump.
(gdb) disassemble add
Dump of assembler code for function add:
0x0804841c <+0>: push %ebp # 将 ebp 压栈(保存函数调用者的栈帧基址)
0x0804841d <+1>: mov %esp,%ebp # 将 ebp 指向栈顶 esp(设置当前被调用函数的栈帧基址)
0x0804841f <+3>: sub $0x10,%esp # 分配栈空间(栈向低地址方向生长)
0x08048422 <+6>: movl $0x0,-0x4(%ebp) # 给 result 变量赋 0 值(该变量偏移为ebp-0x04)
0x08048429 <+13>: mov 0xc(%ebp),%eax # 将第 2 个参数的值赋给 eax 寄存器(准备运算)
0x0804842c <+16>: mov 0x8(%ebp),%edx # 将第 1 个参数的值赋给 edx 寄存器(准备运算)
0x0804842f <+19>: add %edx,%eax # 运算器执行加法运算 (edx+eax),结果保存在 eax 寄存器中
0x08048431 <+21>: mov %eax,-0x4(%ebp) # 将运算结果 eax 赋给 result 变量
0x08048434 <+24>: mov -0x4(%ebp),%eax # 将 result 变量的值赋给 eax 寄存器(eax 的地址将作为函数返回值)
0x08048437 <+27>: leave # 恢复函数调用者的栈帧基址(pop %ebp)
0x08048438 <+28>: ret # 返回(准备执行下条指令)
End of assembler dump.
- 示意图

可见,每一次函数调用,都会对调用者的栈帧基址 EBP 进行压栈操作(为了调用回归),并且由于子函数的栈帧基址 EBP 来自于栈指针 ESP 而来(生成新的子函数的栈帧),所以各层函数的栈帧基址很巧妙的构成了一个链,即当前的栈帧基址指向下一层函数栈帧基址所在的位置。

由此当子函数执行完成时,ESP 依旧在栈顶,但 EBP 就跳转到父函数的栈帧底部了,并且堆栈下一个弹出的就是子函数的调用回归点,最终程序流回到调用点并继续往下执行。
通过函数调用堆栈的工作原理我们可以看出,无论程序中具有多少层的函数调用,或递归调用,只需要维护好每个栈帧的 EBP 和 ESP 就可以管理还函数之间的跳转。但堆栈也是由容量限制的,如果函数调用的层级太多就会出现栈溢出的错误(Stack Overflow)。
程序在操作系统中的装载与运行
一个程序在操作系统上运行需要经历以下阶段:
第一阶段:得到可执行文件
- 编译(Compile)
- 汇编(Assemble)
- 链接(Link)
第二阶段:装载运行
- 装载器(Loader)将可执行文件载入到内存
- CPU 从内存中可执行文件的程序入口开始读取指令和数据,开始真正执行程序。

编译和汇编的过程在上文中已经提到了,下面再继续介绍链接的过程。
- 子程序
// add_lib.c
int add(int a, int b)
{
return a+b;
}
- 主函数
// link_example.c
#include <stdio.h>
int main()
{
int a = 10;
int b = 5;
int c = add(a, b);
printf("c = %d\n", c);
}
- 编译 C 程序得到 Object 文件
$ gcc -g -c add_lib.c link_example.c
- 链接上述两个 Object 文件得到一个可执行文件
$ gcc -o link-example add_lib.o link_example.o
$ ./link-example
c = 15
区别于 Object 文件,真正的可执行文件的内容如下:
$ objdump -d -M intel -S link-example
link-example: file format elf64-x86-64
Disassembly of section .init:
00000000004003c8 <_init>:
4003c8: 48 83 ec 08 sub rsp,0x8
4003cc: 48 8b 05 25 0c 20 00 mov rax,QWORD PTR [rip+0x200c25] # 600ff8 <__gmon_start__>
4003d3: 48 85 c0 test rax,rax
4003d6: 74 05 je 4003dd <_init+0x15>
4003d8: e8 43 00 00 00 call 400420 <.plt.got>
4003dd: 48 83 c4 08 add rsp,0x8
4003e1: c3 ret
Disassembly of section .plt:
00000000004003f0 <.plt>:
4003f0: ff 35 12 0c 20 00 push QWORD PTR [rip+0x200c12] # 601008 <_GLOBAL_OFFSET_TABLE_+0x8>
4003f6: ff 25 14 0c 20 00 jmp QWORD PTR [rip+0x200c14] # 601010 <_GLOBAL_OFFSET_TABLE_+0x10>
4003fc: 0f 1f 40 00 nop DWORD PTR [rax+0x0]
0000000000400400 <printf@plt>:
400400: ff 25 12 0c 20 00 jmp QWORD PTR [rip+0x200c12] # 601018 <printf@GLIBC_2.2.5>
400406: 68 00 00 00 00 push 0x0
40040b: e9 e0 ff ff ff jmp 4003f0 <.plt>
0000000000400410 <__libc_start_main@plt>:
400410: ff 25 0a 0c 20 00 jmp QWORD PTR [rip+0x200c0a] # 601020 <__libc_start_main@GLIBC_2.2.5>
400416: 68 01 00 00 00 push 0x1
40041b: e9 d0 ff ff ff jmp 4003f0 <.plt>
Disassembly of section .plt.got:
0000000000400420 <.plt.got>:
400420: ff 25 d2 0b 20 00 jmp QWORD PTR [rip+0x200bd2] # 600ff8 <__gmon_start__>
400426: 66 90 xchg ax,ax
Disassembly of section .text:
0000000000400430 <_start>:
400430: 31 ed xor ebp,ebp
400432: 49 89 d1 mov r9,rdx
400435: 5e pop rsi
400436: 48 89 e2 mov rdx,rsp
400439: 48 83 e4 f0 and rsp,0xfffffffffffffff0
40043d: 50 push rax
40043e: 54 push rsp
40043f: 49 c7 c0 f0 05 40 00 mov r8,0x4005f0
400446: 48 c7 c1 80 05 40 00 mov rcx,0x400580
40044d: 48 c7 c7 31 05 40 00 mov rdi,0x400531
400454: e8 b7 ff ff ff call 400410 <__libc_start_main@plt>
400459: f4 hlt
40045a: 66 0f 1f 44 00 00 nop WORD PTR [rax+rax*1+0x0]
0000000000400460 <deregister_tm_clones>:
400460: b8 37 10 60 00 mov eax,0x601037
400465: 55 push rbp
400466: 48 2d 30 10 60 00 sub rax,0x601030
40046c: 48 83 f8 0e cmp rax,0xe
400470: 48 89 e5 mov rbp,rsp
400473: 77 02 ja 400477 <deregister_tm_clones+0x17>
400475: 5d pop rbp
400476: c3 ret
400477: b8 00 00 00 00 mov eax,0x0
40047c: 48 85 c0 test rax,rax
40047f: 74 f4 je 400475 <deregister_tm_clones+0x15>
400481: 5d pop rbp
400482: bf 30 10 60 00 mov edi,0x601030
400487: ff e0 jmp rax
400489: 0f 1f 80 00 00 00 00 nop DWORD PTR [rax+0x0]
0000000000400490 <register_tm_clones>:
400490: b8 30 10 60 00 mov eax,0x601030
400495: 55 push rbp
400496: 48 2d 30 10 60 00 sub rax,0x601030
40049c: 48 c1 f8 03 sar rax,0x3
4004a0: 48 89 e5 mov rbp,rsp
4004a3: 48 89 c2 mov rdx,rax
4004a6: 48 c1 ea 3f shr rdx,0x3f
4004aa: 48 01 d0 add rax,rdx
4004ad: 48 d1 f8 sar rax,1
4004b0: 75 02 jne 4004b4 <register_tm_clones+0x24>
4004b2: 5d pop rbp
4004b3: c3 ret
4004b4: ba 00 00 00 00 mov edx,0x0
4004b9: 48 85 d2 test rdx,rdx
4004bc: 74 f4 je 4004b2 <register_tm_clones+0x22>
4004be: 5d pop rbp
4004bf: 48 89 c6 mov rsi,rax
4004c2: bf 30 10 60 00 mov edi,0x601030
4004c7: ff e2 jmp rdx
4004c9: 0f 1f 80 00 00 00 00 nop DWORD PTR [rax+0x0]
00000000004004d0 <__do_global_dtors_aux>:
4004d0: 80 3d 55 0b 20 00 00 cmp BYTE PTR [rip+0x200b55],0x0 # 60102c <_edata>
4004d7: 75 11 jne 4004ea <__do_global_dtors_aux+0x1a>
4004d9: 55 push rbp
4004da: 48 89 e5 mov rbp,rsp
4004dd: e8 7e ff ff ff call 400460 <deregister_tm_clones>
4004e2: 5d pop rbp
4004e3: c6 05 42 0b 20 00 01 mov BYTE PTR [rip+0x200b42],0x1 # 60102c <_edata>
4004ea: f3 c3 repz ret
4004ec: 0f 1f 40 00 nop DWORD PTR [rax+0x0]
00000000004004f0 <frame_dummy>:
4004f0: 48 83 3d 28 09 20 00 cmp QWORD PTR [rip+0x200928],0x0 # 600e20 <__JCR_END__>
4004f7: 00
4004f8: 74 1e je 400518 <frame_dummy+0x28>
4004fa: b8 00 00 00 00 mov eax,0x0
4004ff: 48 85 c0 test rax,rax
400502: 74 14 je 400518 <frame_dummy+0x28>
400504: 55 push rbp
400505: bf 20 0e 60 00 mov edi,0x600e20
40050a: 48 89 e5 mov rbp,rsp
40050d: ff d0 call rax
40050f: 5d pop rbp
400510: e9 7b ff ff ff jmp 400490 <register_tm_clones>
400515: 0f 1f 00 nop DWORD PTR [rax]
400518: e9 73 ff ff ff jmp 400490 <register_tm_clones>
000000000040051d <add>:
// add_lib.c
int add(int a, int b)
{
40051d: 55 push rbp
40051e: 48 89 e5 mov rbp,rsp
400521: 89 7d fc mov DWORD PTR [rbp-0x4],edi
400524: 89 75 f8 mov DWORD PTR [rbp-0x8],esi
return a+b;
400527: 8b 45 f8 mov eax,DWORD PTR [rbp-0x8]
40052a: 8b 55 fc mov edx,DWORD PTR [rbp-0x4]
40052d: 01 d0 add eax,edx
}
40052f: 5d pop rbp
400530: c3 ret
0000000000400531 <main>:
// link_example.c
#include <stdio.h>
int main()
{
400531: 55 push rbp
400532: 48 89 e5 mov rbp,rsp
400535: 48 83 ec 10 sub rsp,0x10
int a = 10;
400539: c7 45 fc 0a 00 00 00 mov DWORD PTR [rbp-0x4],0xa
int b = 5;
400540: c7 45 f8 05 00 00 00 mov DWORD PTR [rbp-0x8],0x5
int c = add(a, b);
400547: 8b 55 f8 mov edx,DWORD PTR [rbp-0x8]
40054a: 8b 45 fc mov eax,DWORD PTR [rbp-0x4]
40054d: 89 d6 mov esi,edx
40054f: 89 c7 mov edi,eax
400551: b8 00 00 00 00 mov eax,0x0
400556: e8 c2 ff ff ff call 40051d <add>
40055b: 89 45 f4 mov DWORD PTR [rbp-0xc],eax
printf("c = %d\n", c);
40055e: 8b 45 f4 mov eax,DWORD PTR [rbp-0xc]
400561: 89 c6 mov esi,eax
400563: bf 10 06 40 00 mov edi,0x400610
400568: b8 00 00 00 00 mov eax,0x0
40056d: e8 8e fe ff ff call 400400 <printf@plt>
}
400572: c9 leave
400573: c3 ret
400574: 66 2e 0f 1f 84 00 00 nop WORD PTR cs:[rax+rax*1+0x0]
40057b: 00 00 00
40057e: 66 90 xchg ax,ax
0000000000400580 <__libc_csu_init>:
400580: 41 57 push r15
400582: 41 89 ff mov r15d,edi
400585: 41 56 push r14
400587: 49 89 f6 mov r14,rsi
40058a: 41 55 push r13
40058c: 49 89 d5 mov r13,rdx
40058f: 41 54 push r12
400591: 4c 8d 25 78 08 20 00 lea r12,[rip+0x200878] # 600e10 <__frame_dummy_init_array_entry>
400598: 55 push rbp
400599: 48 8d 2d 78 08 20 00 lea rbp,[rip+0x200878] # 600e18 <__init_array_end>
4005a0: 53 push rbx
4005a1: 4c 29 e5 sub rbp,r12
4005a4: 31 db xor ebx,ebx
4005a6: 48 c1 fd 03 sar rbp,0x3
4005aa: 48 83 ec 08 sub rsp,0x8
4005ae: e8 15 fe ff ff call 4003c8 <_init>
4005b3: 48 85 ed test rbp,rbp
4005b6: 74 1e je 4005d6 <__libc_csu_init+0x56>
4005b8: 0f 1f 84 00 00 00 00 nop DWORD PTR [rax+rax*1+0x0]
4005bf: 00
4005c0: 4c 89 ea mov rdx,r13
4005c3: 4c 89 f6 mov rsi,r14
4005c6: 44 89 ff mov edi,r15d
4005c9: 41 ff 14 dc call QWORD PTR [r12+rbx*8]
4005cd: 48 83 c3 01 add rbx,0x1
4005d1: 48 39 eb cmp rbx,rbp
4005d4: 75 ea jne 4005c0 <__libc_csu_init+0x40>
4005d6: 48 83 c4 08 add rsp,0x8
4005da: 5b pop rbx
4005db: 5d pop rbp
4005dc: 41 5c pop r12
4005de: 41 5d pop r13
4005e0: 41 5e pop r14
4005e2: 41 5f pop r15
4005e4: c3 ret
4005e5: 90 nop
4005e6: 66 2e 0f 1f 84 00 00 nop WORD PTR cs:[rax+rax*1+0x0]
4005ed: 00 00 00
00000000004005f0 <__libc_csu_fini>:
4005f0: f3 c3 repz ret
Disassembly of section .fini:
00000000004005f4 <_fini>:
4005f4: 48 83 ec 08 sub rsp,0x8
4005f8: 48 83 c4 08 add rsp,0x8
4005fc: c3 ret
可见,链接(Link) 不仅仅是单纯的将多个 Object 文件拼凑起来而已,而是将程序真正的转换为一个可以在操作系统上执行的文件格式,且这个文件中还包含了整个程序所有 Object 文件的内容。在 Linux 上,这个文件格式就是 ELF(Execuatable and Linkable File Format,可执行与可链接文件格式)。
ELF 文件格式:是一种用于二进制文件、可执行文件、目标代码、共享库和核心转储格式文件。ELF 文件由 4 部分组成,分别是 ELF header、程序头表(Program Header Table)、节(Section)和节头表(Section Header Table)。

在链接器把程序转换为 ELF 格式的可执行文件之后,装载器再去处理就会容易得多。因为装载器不再需要考虑地址跳转的问题,只需要解析 ELF 文件,把对应的指令和数据加载到内存里面供 CPU 执行就可以了。
同样,Windows 也有自己的可执行文件格式 PE(Portable Executable Format)。因为 Linux 和 Windows 的可执行文件格式不同,所以也就不能够 “一次编译,跨平台执行” 了。那么换句话说:是不是只要在 Linux 上运行可以解析 PE 文件的装载器就可以解决这个问题呢?答案是肯定的,Linux 著名的开源软件 Wine 正是此类装载器,国内很多 Linux Desktop 发行版都是基于 Wine 实现了 Windows 常用软件的移植。

