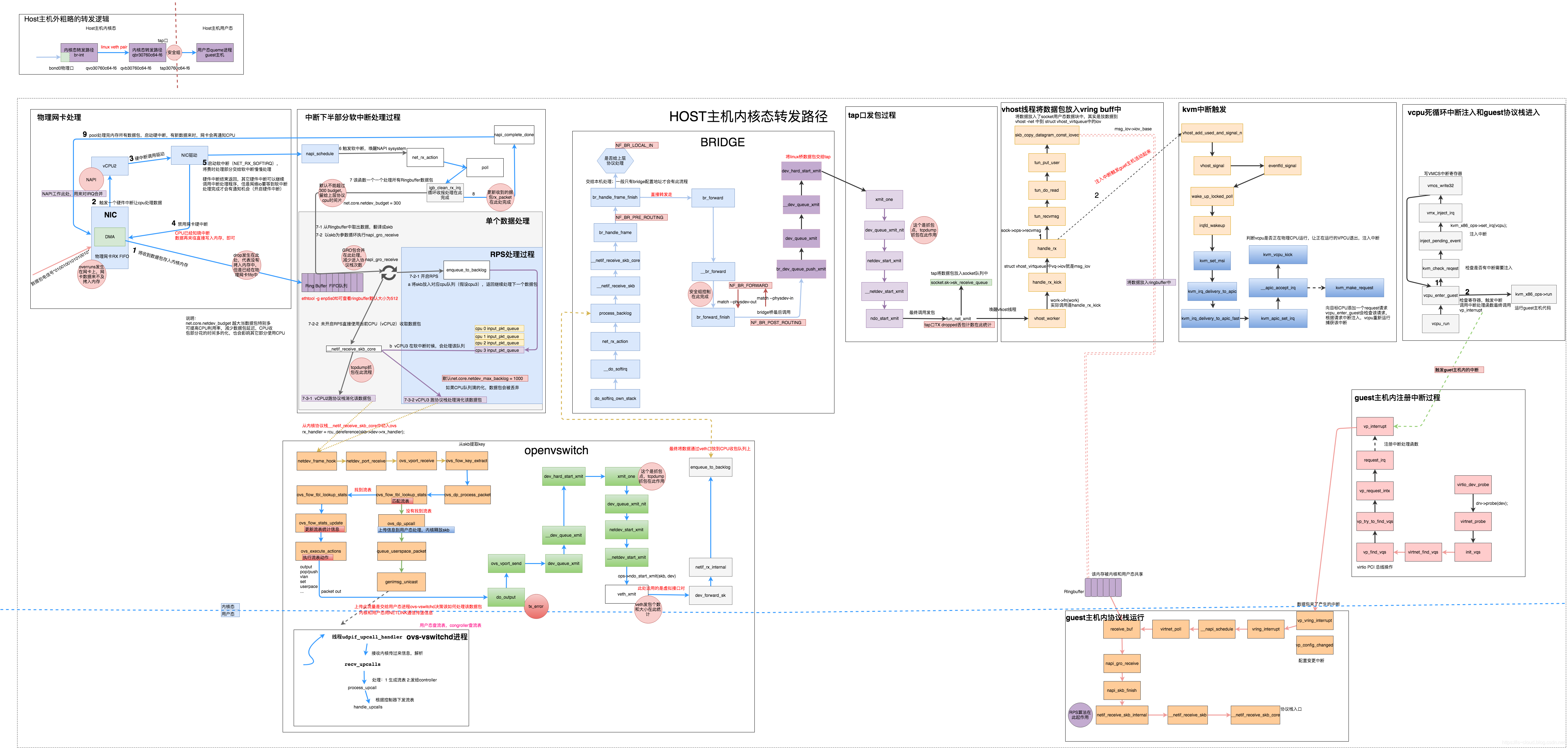
数据包从物理网卡流经 Open vSwitch 进入 OpenStack 云主机的流程
2019-08-09 18:55 云物互联 阅读(2771) 评论(0) 编辑 收藏 举报目录
文章目录
前言
无意中翻阅到这篇文章,如获至宝,就将文章转载至此。感谢原作者的辛勤付出,细致入微的整理。我在原文的基础上做了一些文字的整理和内容补充,推荐阅读原文。
数据包从物理网卡进入虚拟机的流程
- 顶层视角
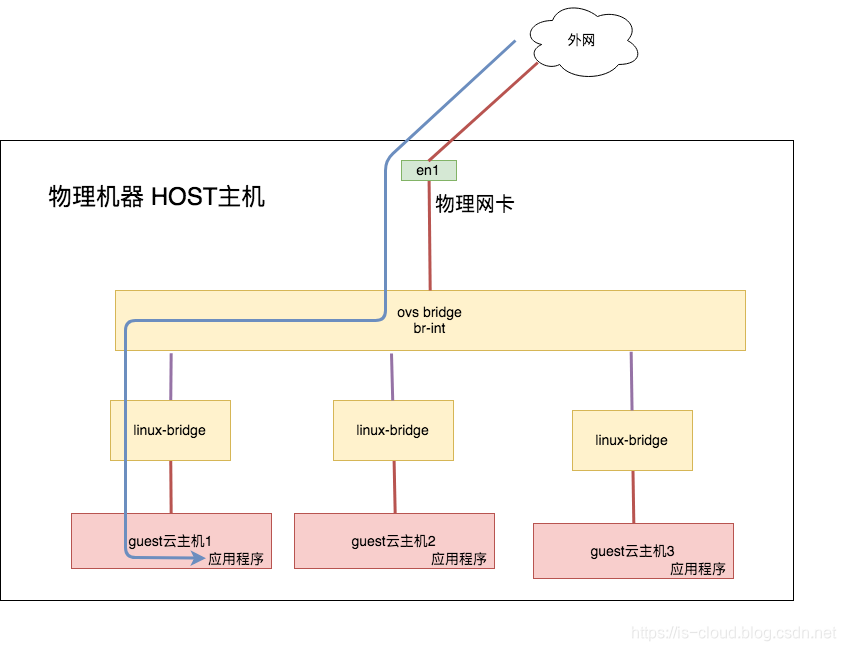
- 中层视角

- 微观视角
- 物理网卡处理
- 中断下半部分软中断处理
- 将数据包交给内核的 OvS Bridge 处理
- 将数据包交给 Linux Bridge 处理
- 将数据包送入虚拟机 tap 口
物理网卡处理
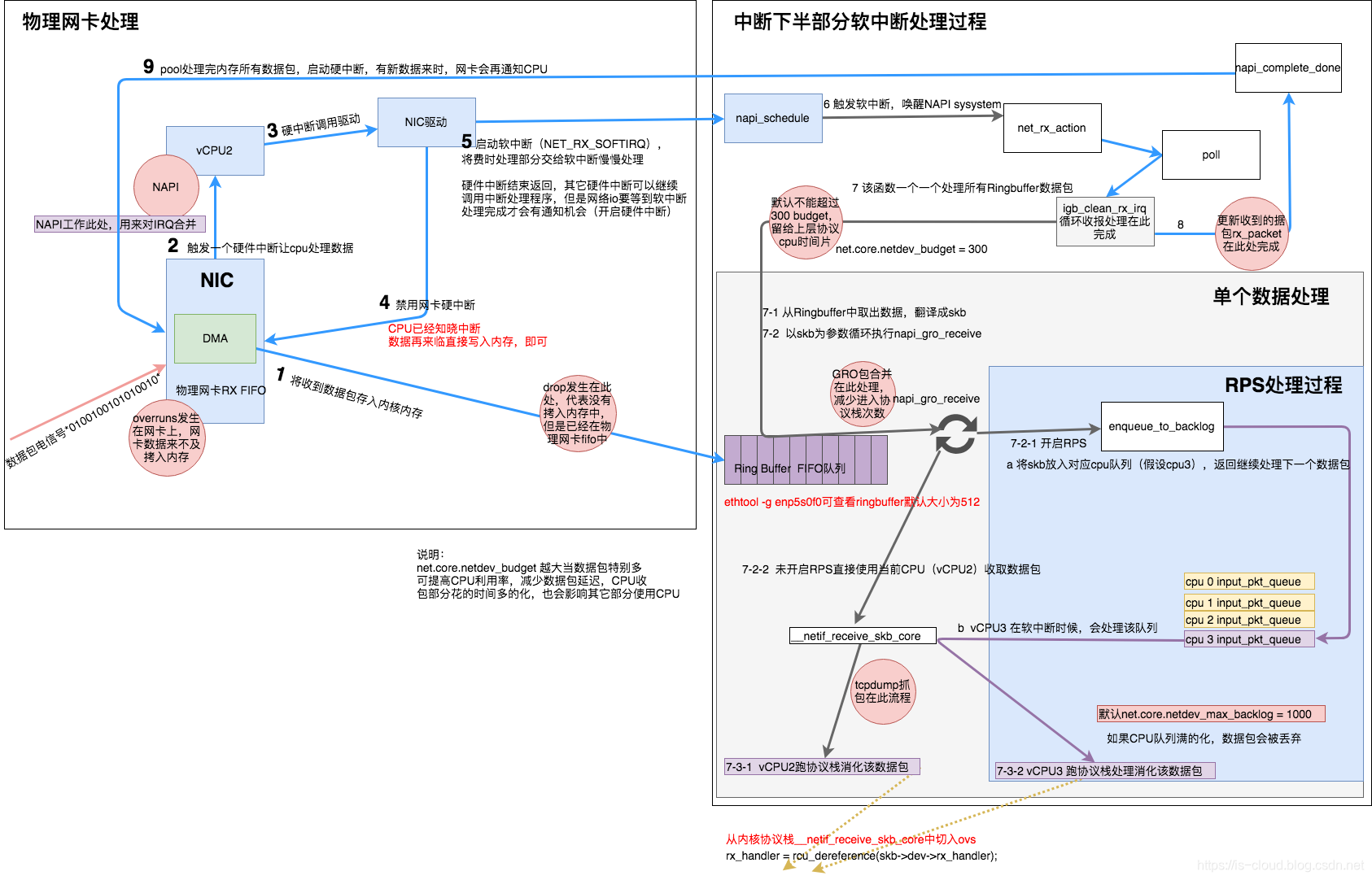
- NIC 收到数据包,会先将高低电信号转换到网卡 FIFO 存储器。NIC 首先申请 Ring buffer 的描述,根据描述找到具体的物理地址,NIC 会使用 DMA 将数据包从 FIFO 队列写到该物理地址指向的空间,其实就是 skb_buffer 中。
- 此时数据包已经被转移到 skb_buffer 中,因为是 DMA 写入,所以内核并没有监控数据包写入情况,这时候 NIC 触发一个硬中断,每一个硬件中断会对应一个中断号,且指定一个 vCPU 来处理。如:上图 vcpu2 收到了该硬件中断。
- 硬件中断的中断处理程序,通过调用 NIC 驱动程序来完成。
- 硬中断触发的驱动程序首先会禁用 NIC 硬中断,意思是告诉 NIC 再来数据就先不要触发硬中断了,把数据包通过 DMA 拷入系统内存即可。
- 硬中断触发的驱动程序继续启动软中断,启用软中断目的是将数据包的后续处理流程交给软中断异步的慢慢处理。此时 NIC 驱动程序就退出硬件中断了,其他的外部设备可以继续调用硬件中断。但网络 I/O 相关的硬中断,是需要等到软中断处理完成并再次开启硬中断后,才能被再次触发。
- 软中断唤醒 NAPI,触发
napi()系统调用。 - 逐一消耗 Ring Buffer 指向的 skb_buffer 中的数据包。
- NAPI 循环处理 Ring Buffer 中的数据。
- 开启网络 I/O 硬件中断,有新数据到来时可以继续触发硬件中断,继续通知特定的 CPU 来消耗数据包。
简单总结一下上述流程:
- 物理网卡接收到数据包首先将数据包缓存在设备控制器的 Ring Buffer 上。
- 然后物理网卡 CPU 发送一个硬中断,硬中断调用网卡驱动程序,网卡驱动程序在触发一个软中断。
- 软中断处理程序轮询的从 Ring Buffer 上读取数据包并翻译成标准的 skb 数据结构,并将 skb 挂到 CPU 的处理队列中。
- CPU 从队列中接收到 skb 之后就会执行指令,让内核协议栈处理该 skb 对应的数据包。
关键在于:网卡和内核协议栈其实是标准的生产者/消费者模型,网卡生产,内核协议栈消费,生产者需要通知消费者进行消费。所以,当生产/消费供给不平衡时,就会产生丢包。在高流量压力情况下,单纯的优化生产者是不行的,还要考量消费能力是否跟得上。由此,丢包未必就是网卡的问题,也可能是内核协议栈消费得太慢了。
如何将网卡收到的数据写入到内核内存?
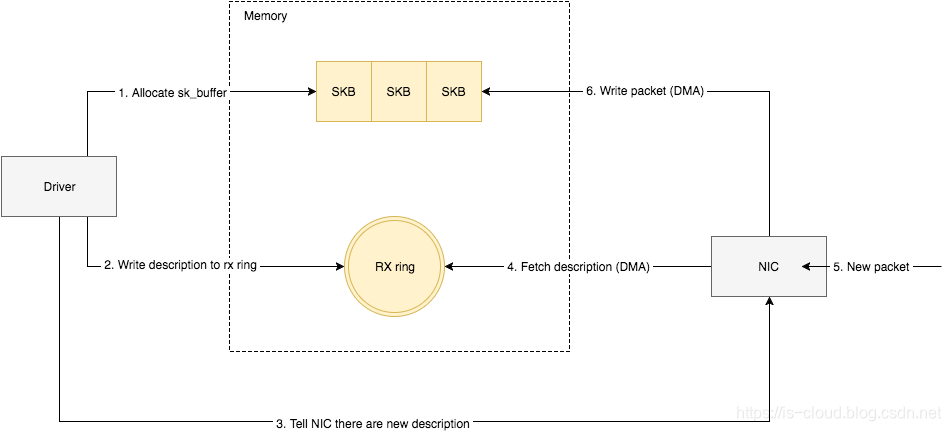
NIC 在接收到数据包之后,首先需要将数据同步到内核中,这中间的桥梁是 rx ring buffer。它是由 NIC 和驱动程序共享的一片区域,事实上,rx ring buffer 存储的并不是实际的数据包,而是一个描述符,这个描述符指向了它真正的存储地址,具体流程如下:
- NIC 驱动程序在内存中分配一片缓冲区用来接收数据包,叫做 skb_buffer。
- 将 skb_buffer 的接收描述符(包含物理地址和大小),加入到 rx ring buffer,描述符中的缓冲区地址是 DMA 使用的物理地址。
- 驱动通知网卡有一个新的描述符。
- 网卡从 rx ring buffer 中取出描述符,从而获知缓冲区的地址和大小。
- 网卡收到新的数据包。
- 网卡将新数据包通过 DMA 直接写到 sk_buffer 中。
当 NIC 驱动程序的处理速度跟不上网卡收包速度时,驱动来不及分配缓冲区,NIC 接收到的数据包无法及时写到 sk_buffer,就会产生堆积,当 NIC 内部缓冲区写满后,就会丢弃部分数据,引起丢包。这部分丢包为 rx_fifo_errors,在 /proc/net/dev 中体现为 FIFO 字段增长,在 ifconfig 中体现为 overruns 指标增长。
中断下半部分软中断处理
-
7.1 因为 igb_ckean_rx_irq 会循环消耗数据包,但存在循环有次数限制,否则 CPU 会一直停留在处理部分。循环次数限制对应的内核参数为
net.core.netdev_budget = 300。 -
7.2 取出 skb,调用 napi_gro_receive,这个函数先做一些 GRO 包合并动作,然后根据是否开启 RPS 执行如下流程。
- 7.2.1 开启了 RPS,将数据包放至 HASH 到的 vCPU 队列中,数据包挂入这个队列后,本次处理就结束了,继续处理下一个包。队列长度由内核参数
net.core.netdev_max_backlog = 1000决定,也就是当数据包超过 1000 个时,就会被丢弃。所以用户态消耗要跟上才行。后续就由队列的 vCPU 取出数据包并调用__netif_receive_skb_core来处理。 - 7.2.2 如果没有开启 RPS,则直接使用 vCPU2 继续调用
__netif_receive_skb_core来处理该数据包。
- 7.2.1 开启了 RPS,将数据包放至 HASH 到的 vCPU 队列中,数据包挂入这个队列后,本次处理就结束了,继续处理下一个包。队列长度由内核参数
NOTE:由上述描述可知,开启 RPS 后,下半步软中断的数据包可以直接挂到其它 vCPU 队列上,这样就能减少 vCPU2 的压力,vCPU2 就能处理更大的流量。可见,RPS 适合单网卡队列,多 vCPU 的使用场景。
NOTE:__netif_receive_skb_core 是内核协议栈处理数据包的入口函数,使用 tcpdump 抓包就是在此处起了作用,也就是说如果 tcpdump 能数据包就代表数据包已经到达内核协议栈入口了。
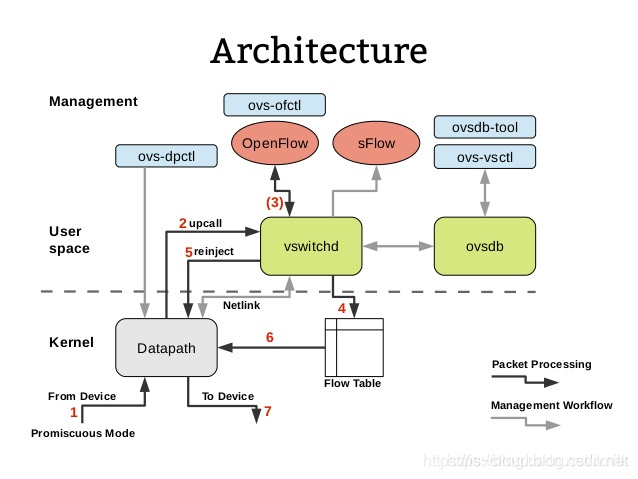
数据包在内核态 OvS Bridge(Datapath)中的处理
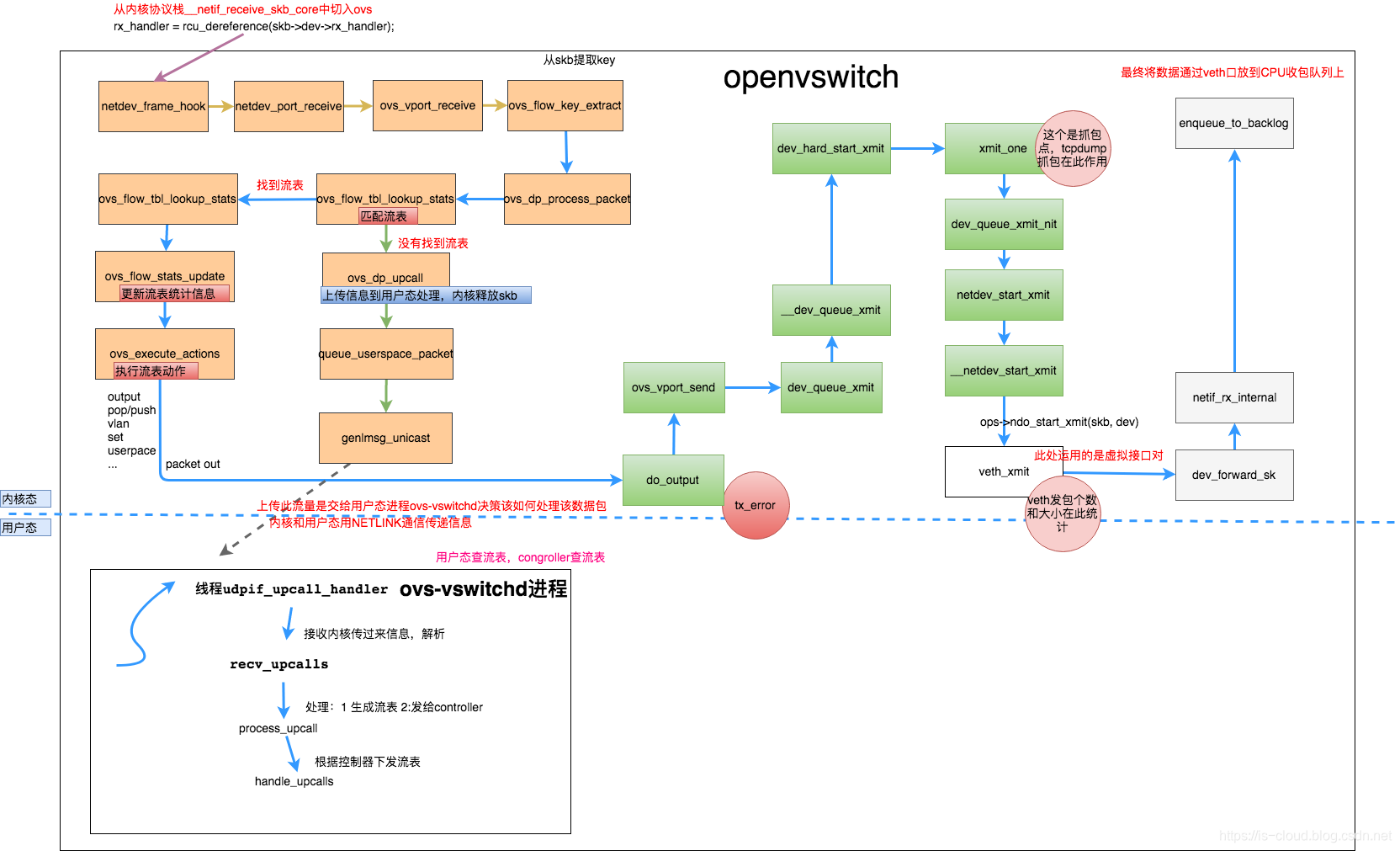
上图所示是数据包在 Open vSwitch 内部转发的流程,其中 netdev_frame_hook 是 OvS Bridge(Datapath)的入口,被 __netif_receive_skb_core 调用来处理接收到的数据包。
数据流量进入 OvS Bridge 之后根据数据包的各类头部信息(五元组)查找流表,并进行过滤或转发处理。
主要有下列两种处理情况,而判断的依据就是是否能够根据五元组匹配到流表。
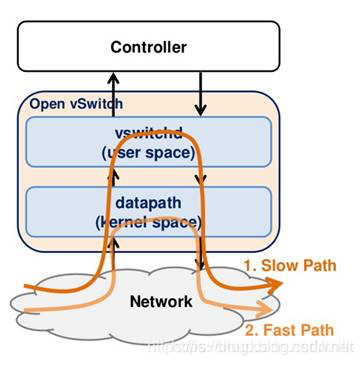
- Slow Path:流量转发给在用户态的控制器(ovs-vswitchd 和 ovs-db)。内核流量通过 netlink 将数据包传给用户态的 ovs-vswitchd 进程,ovs-vswitchd 会对流量解析,根据解析和 OpenFlow vSwitch 定义的 Proactive/Reactive 模式进行处理,一般是下发流表。
- Fast Path:流量在内核态直接转发。根据流表的动作执行转发动作,最终会调用
dev_hard_star_xmit、xmit_one,最后调用ndo_start_xmit(skb, dev)发送数据包。
由于当前采用的是 Linux 虚拟 “网线” 设备(veth),所以 ndo_start_xmit(skb, dev) 调用了 veth_xmit,所以虚拟端口发包计数的统计工作也在 veth_xmit 完成。
veth pair 的工作原理
虚拟“网线”(veth pair):不是一个设备,而是一对设备,用于连接两个虚拟以太端口。veth pair 的本质是反转通讯数据的方向,需要发送的数据会被转换成需要收到的数据重新送入内核协议栈进行处理,从而间接的完成数据的注入。veth pair 的工作原理就相当于当连接 Linux Bridge 的口收到了数据包,内核协议栈会反转将该数据包重新发送给 Linux Bridge。
继续上述的流程:
veth_xmit将数据包发出。- 调用
dev_forward_sk,然后dev_forward_sk调用内核协议栈收包入口netif_rx_internal,最终netif_rx_internal将数据包放入 CPU 收包队列。如此,该数据包就被注入了内核协议栈。 - veth pair 设备的一端在软中断触发时,会立刻处理该 CPU 队列的数据包,并将数据包重新注入内核协议栈,最终数据包作为待接收数据被被 veth pair 设备的另一端接收。
将数据包交给 Linux Bridge 处理

在本文的网络模型中。Linux Bridge 作为安全层,虚拟机的 tap 口通过 veth pair 虚拟设备接入 Linux Bridge。由上文可知,数据包会经过 veth pair 注入到内核协议栈,内核协议栈会再次调用 _netif_reveive_skb 处理该数据包。而因该函数是 veth 口收到的数据,该接口连接的是Linux Bridge,所以协议栈会调用 br_handle_frame 处理该数据包。Linux Bridge 处理数据包会经过以下几个情况:
- 协议栈收到该数据包会先经过
NF_BR_PRE_ROUTING钩子,该钩子 处理的就是之前通过 iptables 添加的 PRE ROUTING 策略。 - 经过
NF_BR_PRE_ROUTING钩子后,会判断是将该数据包当成本机数据包处理,还是继续转发(后文以转发为例进行说明)。 - 若进行数据转发,那么数据包转发时会经过
NF_BR_FORWARD钩子函数,所有转发的数据包都会经过该函数,安全组策略就是在此钩子中进行的。 - 转发数据包处理完后,最后调用
br_forward_finish将数据包发出去,NF_BR_POST_ROUTING钩子存在此处,作为数据包发出前最后的处理。 - 最后会调用
dev_hard_start_xmit函数将数据包发出。
将数据包送入虚拟机 tap 口
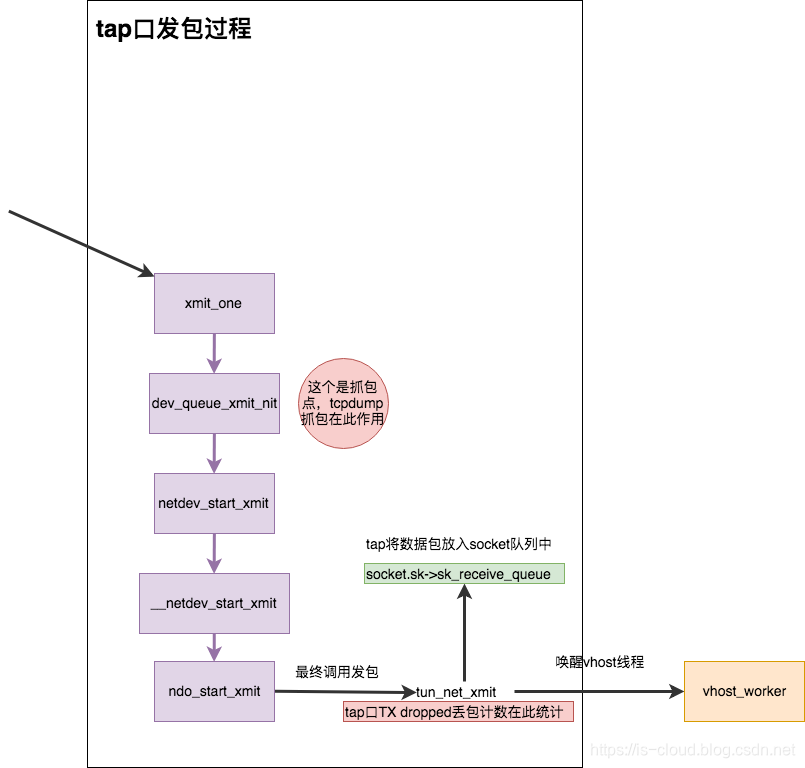
Linux Bridge 将数据包交给 tap 口,最终是将数据包将给用户态进程 KVM-QEMU 的虚拟机进行消耗。所以需要将数据包从内核态转发到用户态,且触发中断告知虚拟机数据包来了。显然,tap 口自己完成不了这样的工作,tap 口仅能处理数据包,而内核态、用户态的运行模式切换以及中断触发,就需要通过另一个层级的内核线程驱动了。本文场景中使用的是 vhost-net 技术。也就是说,实际上是通过 tap 口和 vhost 的配合来完成了将数据包交给虚拟机。
tap 口的数据包处理流程

上文提到,Linux Bridge 最后调用了 dev_hard_start_xmit 将数据包交给 tap 口,所以会调用 tap 口的 xmit_one 将数据包送到其入口函数。最后调用 tun_net_xmit 把将数据包发出,tun_net_xmit 这个函数很重要,承载了 tap 数据的逻辑:
- 发包统计、drop 丢包统计都在此进行
- 将数据包放入
socket.sk->sk_receive_queue,即 Socket 队列。Socket 队列有长度限制,默认为 tap 口的tx_queuelen,通常是 1000 个数据包,如果长度大于 1000 则会丢弃数据包。遇到这种情况,说明虚拟机处理较慢,应该想办法优化虚拟机的处理速度。 - 数据包放入 Socket 队列后,需要唤醒 vhost 线程开始工作。
e.g. txqueuelen:1000 为 tap 口 Socket 队列的长度,单位是包个数
root@compute-001:~# ifconfig tapc3072bad-18
tapc3072bad-18 Link encap:Ethernet HWaddr fe:16:3e:09:6f:46
inet6 addr: fe80::fc16:3eff:fe09:6f46/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1450 Metric:1
RX packets:3569 errors:0 dropped:0 overruns:0 frame:0
TX packets:372 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:294046 (294.0 KB) TX bytes:26034 (26.0 KB)
vhost 线程的工作流程
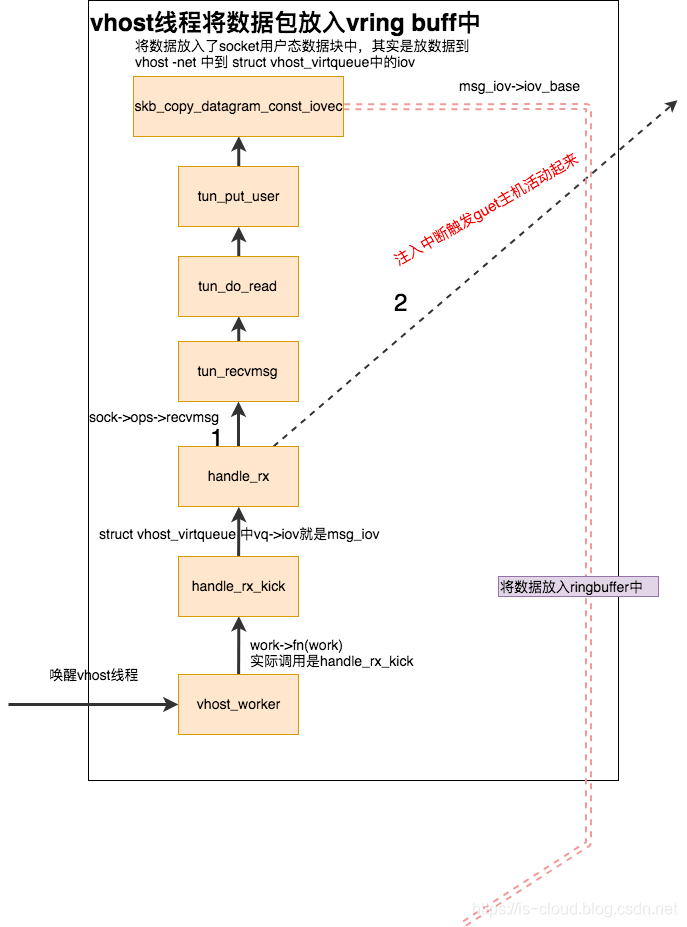
tap 口通过 tun_net_xmit 唤醒 vhost worker 之后,vhost 线程就会将数据包拷贝到虚拟机的 Ring Buffer 中,且触发中断告诉虚拟机数据包已到,虚拟机继而消费这些数据包。
vhost 线程,是创建虚拟机时一并启动的线程,线程名称 vhost-<qemu_PID>。vhost 线程是个死循环,它被唤醒后循环着干两件事情:
- 注入中断触发激活 GuestOS
- 循环从 tap 口的 Socket 队列中取出数据,直接将数据包拷用户态虚拟机进程的 Ring Buffer 中,注意此处的 Ring Buffer 是 vhost 线程内核与用户态共享的内存。
KVM 如何中断触发虚拟机的内核协议栈?
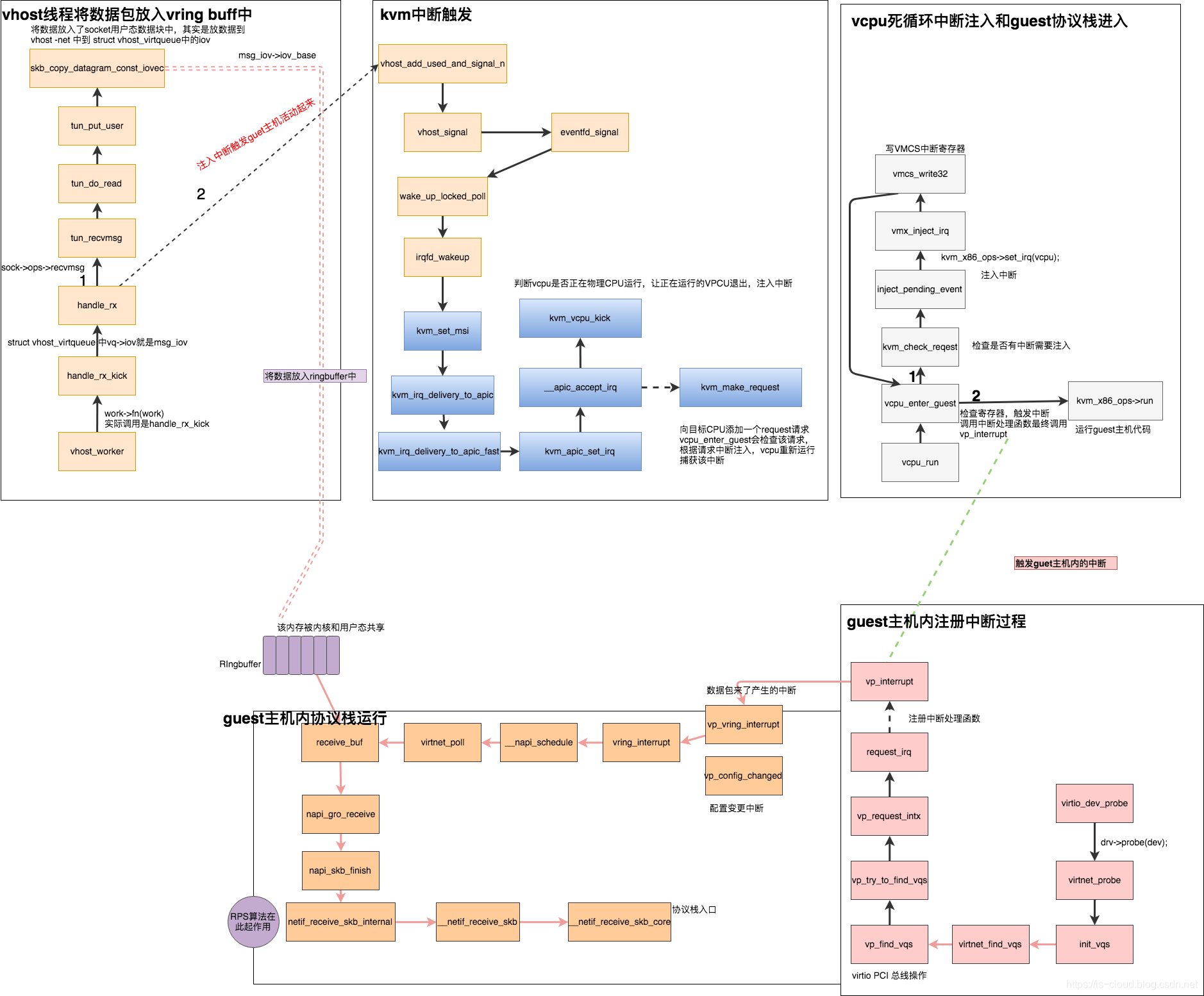
如图,vhost 线程会调用 KVM 的接口来触发中断,主要做了两件事情:
- 判断 pCPU 是否运行中,是,则让 pCPU 先退出运行,为了有机会注入中断。
- 向目标 vCPU 添加一个请求,这个请求 vCPU 会死循环的监听, 若发现,则真正注入中断。
也就是说,这两件事情其实只是让 pCPU 退出,方便注入中断请求,和提前注入中断标记。此外,还需要 vCPU 死循环来完成,在循环体中,会有检查中断注入标记的环节,如果发现该标记就调用 kvm_x86_ops->run 立即触发中断。该触发会最终调用中断处理函数 vp_interrupt -> vp_ring_interrupt-> 最终触发内核协议栈 的运行,让协议栈调用 __netif_receive_core 处理数据包。
往后,虚拟机对数据包的处理流程就与宿主机大同小异了。
最后
最后贴出一张流程汇总图,再次感谢原作者的付出,推荐阅读原文。