
OpenStack Nova 高性能虚拟机之 CPU 绑定
2018-07-29 22:32 云物互联 阅读(3994) 评论(0) 收藏 举报目录
前文列表
OpenStack Nova 高性能虚拟机之 NUMA 架构亲和
多进程、多线程与多处理器计算平台的性能问题
KVM
KVM(Kernel-based Virtual Machine 基于内核的虚拟机)是可嵌入 Linux Kernel 的内核功能模块,与 QEMU、Libvirt 等用户态应用程序协同组成一套完整的 Linux 全虚拟化解决方案。
由 KVM 提供 CPU 和内核虚拟化,并通过 /dev/kvm 设备暴露出创建 vCPU、分配虚拟内存地址空间、读写 vCPU 寄存器等 Hypervisor 功能调用接口。但只有 vCPU 和虚拟内存不足以构成虚拟机,还需要依赖于由 QEMU 模拟出来的各类 I/O 设备共同组成。KVM 提供的核心虚拟化能力弥补了原生 QEMU 需要通过模拟 CPU 来进行指令翻译所产生的性能损耗。在较新的 QEMU 发行版(1.3 及以上)中,已经合并了 KVM 的适配代码实现,在执行 qemu 指令时通过选项 --enable-kvm 即可启用。

简单来说,KVM 运行在内核态,负责 CPU 和内存的虚拟化。QEMU 运行在用户态,负责模拟和管理各类虚拟硬件设备。QEMU 通过 ioctl() 调用 /dev/kvm 接口,将 CPU 指令翻译的部分交由 KVM 完成。

为了追求更好的虚拟机性能,后续还为该方案追加了一些具有直通(Pass-through)特性的半虚拟化设备和驱动程序(e.g. virtio_blk、virtio_net ),用于替代 QEMU 对一些关键设备(e.g. 磁盘、网卡)的模拟,进一步提升了性能,用户可以根据实际需要来选择是否启用。

除了上述的 QEMU + KVM 虚拟化实现之外,还需要为用户提供友好的操作入口才能算是一套完整的解决方案。Libvirt 就充当着这个入口,为用户提供 GUI、CLI、API 等工具集。

为了方便描述,在下文中,我们将这一套 Linux 全虚拟化解决方案,简称为 KVM。
KVM 的功能列表
- 支持 SMP 体系结构亲和
- 支持 NUMA 体系结构亲和
- 支持 CPU 亲和性
- 支持 CPU 和内存超分(Overcommit)
- 支持 PCI 直通设备和 SR-IOV
- 支持半虚拟化 I/O 设备和驱动(VirtIO)
- 支持热插拔 CPU,DISK,NIC 等虚拟硬件设备
- 支持热迁移(Live Migration)
- 支持内核内存共享技术(KSM,Kernel Shared Memory)
KVM 工具集
- virsh:命令行工具(CLI)
- virt-manager:图形界面工具(GUI)
- virt-viewer:虚拟机远程桌面连接工具
- virt-v2v:虚拟机迁移工具
- virt-install:虚拟机创建命令行工具
- virt-clone:虚拟机克隆工具
- virt-top:虚拟机性能监控工具
- sVirt:虚拟机安全工具
KVM 虚拟机的本质是什么
KVM 虚拟机,常用 Guest 表述,由 vCPU、虚拟内存、虚拟 I/O 设备以及 GuestOS 组成:
- Guest 的本质是一个 QEMU 进程
- Guest 的一个 vCPU 就是一个 QEMU 进程内的线程
- Guest 的虚拟内存就是分配给 QEMU 进程的内存地址空间的一部分
- GuestOS 可以继承 HostOS 内核中的 NUMA 和 大页内存特性
vCPU、QEMU 进程、物理 CPU 及系统调度器之间的逻辑关系:

而 GuestOS 的物理表现实际上就是一个 XML 文件,描述了 GuestOS 的特征信息。
vCPU 的调度与性能问题
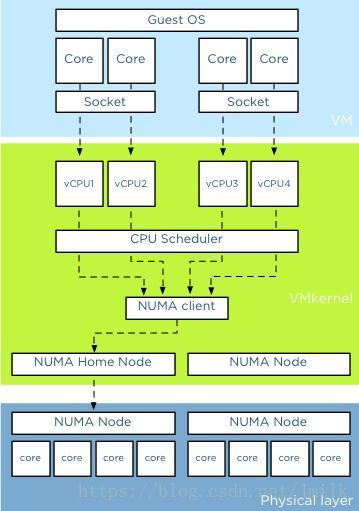
注:上图为 vSphere 的 vCPU 调度示意图,与 KVM 大同小异,可以用作参考。
既然 HostOS 将 vCPU 当普通线程来进行调度,那么 vCPU 的调度与性能问题实际上就是 Linux 线程在多处理器计算平台中的调度与性能问题。关于这个问题我们曾经在《多进程、多线程与多处理器计算平台的性能问题》一文中讨论过,这里不再赘述。简单来说,提高虚拟机 vCPU 的性能,需要贯彻三点原则:
- 减少多线程上下文切换的性能损耗
- 减少用户线程模式切换的性能损耗
- 提高高速缓存的命中率
而实现这些原则的手段大致上有两种:
- 规划出给 Guest 专用的 pCPU s,并且 vCPUs 和 pCPUs 所拥有的 Cores 数量相近
- 将 vCPU 绑定到指定的 pCPU 上运行
KVM 本身就支持 CPU 绑定的相关功能,使用非常简单:
root@devstack:~# virsh help
...
vcpucount domain vcpu counts
vcpuinfo detailed domain vcpu information
vcpupin control or query domain vcpu affinity
# 将 guest 21 的第 0 个 vCPU 绑定到 pCPU 1 上
root@devstack:~# virsh vcpupin 21 0 1
Nova 支持的 vCPU 绑定
vcpu_pin_set 配置项
vcpu_pin_set 是 compute node 上的 nova.conf 配置项,是 OpenStack 最早设计用于限定 Guest 可以使用 compute node 上的 pCPUs 的范围,解决了下述问题:
currently the instances can use all of the pcpu of compute node, the host may become slowly when vcpus of instances are busy, so we need to pin vcpus to the specific pcpus of host instead of all pcpus. the vcpu xml conf of libvirt will change to like this:
<vcpu cpuset="4-12,^8,15">1</vcpu>
简单来说,就是为了让用户一方面可以划分出 Guest 专用的 pCPUs 以保证性能,另一方面也是为了防止 Guest 过分争抢 Host 进程的 CPU 资源,为 Host 适当的留下一些 CPU 以保证正常运作。
NOTE:如果指定的 CPU 范围超出了宿主机原有的 CPU 范围则会触发异常。
CPU 绑定策略
CPU 绑定策略机制经常会结合 NUMA topology 一起使用,在《OpenStack Nova 高性能虚拟机之 NUMA 架构亲和》一文中我们已经介绍过,这里也不再赘述。
openstack flavor set FLAVOR-NAME \
--property hw:cpu_policy=CPU-POLICY \
--property hw:cpu_thread_policy=CPU-THREAD-POLICY
-
CPU-POLICY:
- shared (default):不独占 pCPU 策略,允许 vCPUs 在不同的 pCPUs 间浮动,尽管 vCPUs 受到 NUMA node 的限制也是如此。
- dedicated:独占 pCPU 策略,Guest 的 vCPUs 将会严格的 pinned 到 pCPUs 的集合中。在没有明确配置 Guest NUMA Topology 的情况下,Nova 会将每个 vCPU 都作为一个 Socket 中的一个 Core;如果已经明确的配置了 Guest NUMA Topology 的话,那么虚拟机就会严格按照 Guest NUMA Topology 和 Host NUMA Topology 的映射关系将 vCPUs pinned to pCPUs,pCPUs 可能是一个 Core 或是一个 Thread,根据 Host 实际的处理器体系结构以及 CPU-THREAD-POLICY 来共同决定。此时的 CPU overcommit ratio 为 1.0(不支持 CPU 超配),避免 vCPU 的数量大于 Core 的数量导致的线程上下文切换损耗。
-
CPU-THREAD-POLICY:
- prefer (default):如果 Host 开启了超线程,则 vCPU 优先选择在 Siblings Thread 中运行,即所有的 vCPU 都只会考虑 siblings。例如:4 个逻辑核属于同一 NUMA,其中 CPU1 和 CPU2 属于相同物理核,CPU3 和 CPU4 属于不同的物理核,若此时创建一个 Flavor vCPU 为 4 的云主机会创建失败,因为 siblings 只有 [set([1, 2])];否则,vCPU 优先选择在 Core 上运行。
- isolate(vCPU 性能最好):vCPU 必须绑定到 Core 上。如果 Host 没有开启超线程,则理所当然会将 vCPU 绑定到 Core 上;相反,如果 Host 开启了超线程,则 vCPU 会被绑定到 Siblings Thread 的一个 Thread 中,并且其他的 vCPU 不会再被分配到该 Core 上,相当于 vCPU 独占一个 Core,避免 Siblings Thread 竞争。
- require(vCPU 数量最多):vCPU 必须绑定到 Thread 上。Host 必须开启超线程,每个 vCPU 都会被绑定到 Thread 上,直到 Thread 用完为止。如果没有开启的话,那么该 Host 不会出现在 Nova Scheduler 的调度名单中。
NOTE 1:只有设定 hw:cpu_policy=dedicated 时,hw:cpu_thread_policy 才会生效。后者设定的是 vCPU pinning to pCPU 的策略。
NOTE 2:如果 pinned(isolate) 和 unpinned 的虚拟机运行在同一个 compute node,则会发生 CPU 竞争,因为 unpinned 的虚拟机不会考虑到 pinned 虚拟机的资源需求,由于 Cache 的影响,这将会严重的影响进行了 CPU 绑定的虚拟机的性能,尤其当两者同处一个 NUMA 节点时。所以,应该使用 Host Aggregate 来区分开 pinned 和 unpinned 的虚拟机,退一步来说,最起码也应该让两者运行在不同的 NUMA 节点上。而且如果一个 compute node 上运行的全是 pinned 虚拟机,那么这个 compute node 不建议配置超配比。
NOTE 3:如果 cpu_thread_policy=prefer | require 时,Nova 的 Thread 分配策略是尽量先占满一个 Core,然后再使用下一个 Core 上的 Thread,尽量避免 Thread/Core 碎片影响到后面创建的虚拟机。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号